Cómo Estructuré la Arquitectura de mi Plataforma Web de Generación de Código
 Tomas Darquier
Tomas Darquier
📌 Nota 1: Recomiendo leer el primer blog de la serie para comprender en que consta el sistema y el porque de ciertas tecnologías utilizadas.
📌 Nota 2: Actualmente, el sistema ya está funcional y desarrollado casi en su totalidad. El código y un video de su ejecución y funcionamiento se pueden consultar en el siguiente repositorio: https://github.com/TomasDarquier/LPMG
Introducción
Al sentarme a diseñar la arquitectura de lo que sería mi trabajo final de grado, me encontré con un dilema. Comprendía que si quería hacer un sistema realmente eficiente, sencillo de mantener y programar, la respuesta estaba en una arquitectura monolítica, sin muchas complejidades, al puro estilo KISS. El problema de esto es que tenía en mente utilizar este espacio de diseño y programación para explorar conceptos ciertamente desconocidos para mí, usando de excusa la entrega del TFG y aprovechando que existía una fecha límite, obligándome a buscar alternativas en caso de que alguna situación me impidiera avanzar.
Es ese el motivo por el cual decidí acudir a una arquitectura mucho más compleja, con ciertos aspectos tal vez a priori ilógicos, pero que, sin duda, no tenía idea de cómo lo iba a llevar a cabo, y en cierto punto, esa era la idea…
Arquitectura
Si bien ya tenía experiencia con microservicios, había elementos que quería explorar más a fondo, como las Message Queues, la integración con APIs externas, especificaciones semánticas, el uso de caches y la gestión de archivos con herramientas como S3 o MinIO.
Esto me llevó a diseñar la arquitectura actual, cuyos componentes principales detallo a continuación:
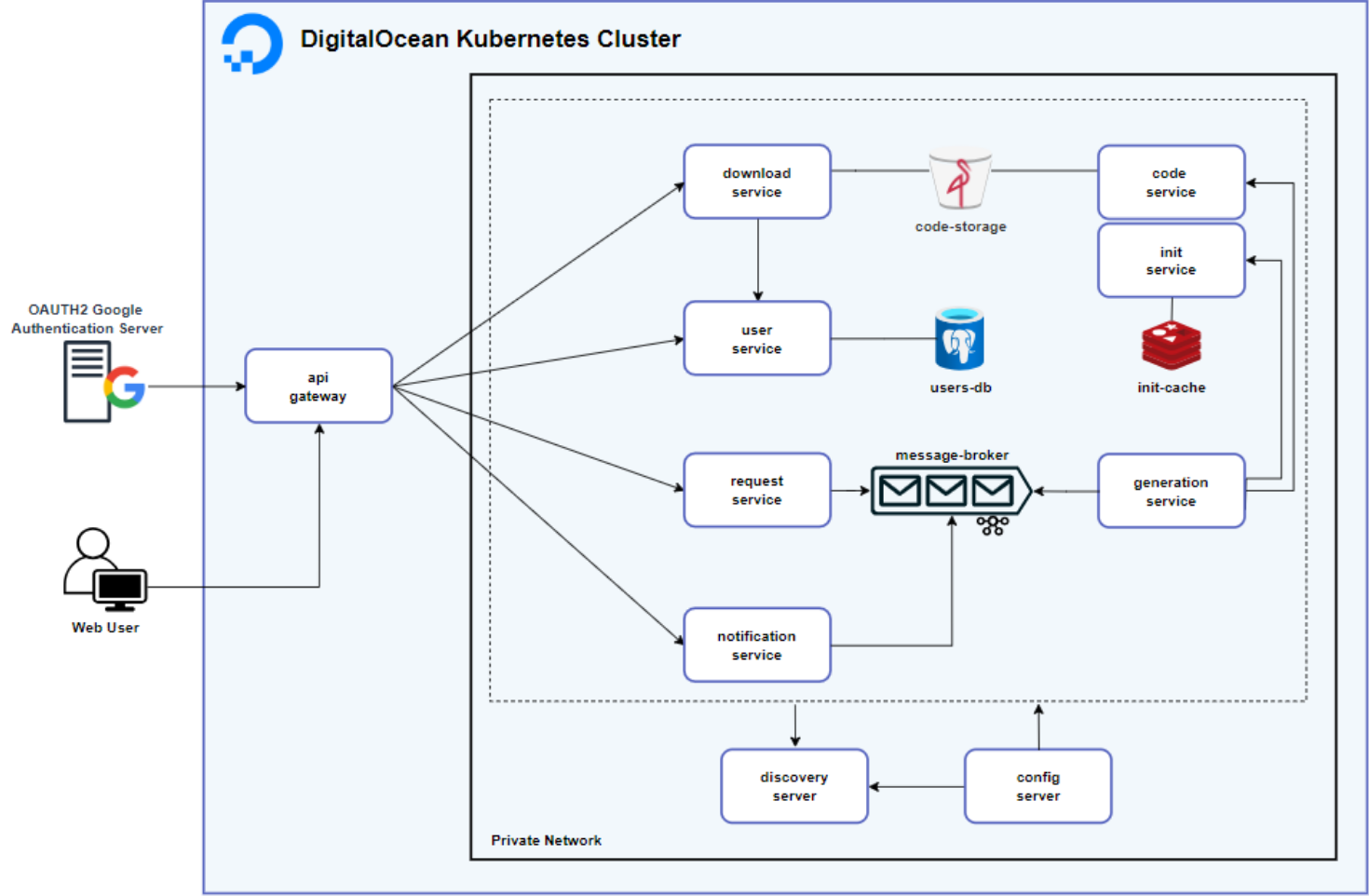
Gateway
El Gateway, en esta ocasión tiene mucho protagonismo, ya que no se trata de un simple API gateway. Al utilizar este componente como acceso directo entre el usuario y la plataforma, decidí aprovechar y alojar en él el frontend, haciendo uso de Thymeleaf. A su vez, como estoy implementando OAuth2 mediante Auth0, centralizar la seguridad en este punto es lo lógico, y es lo que decidí hacer.
Debido a la extensión que puede implicar el desarrollo del apartado de seguridad, en breve publicaré un blog enfocado específicamente en el tema. Cuando esté disponible, vas a poder acceder a él haciendo clic aquí.
User-Service
Al delegar el registro y almacenamiento de credenciales debido al uso de login exclusivamente vía Google, el User-Service solo se dedica a persistir tanto los datos de los usuarios registrados para identificarlos a lo largo de la plataforma, como un registro de sus actividades dentro de la misma, las cuales comprenden la generación de código, y la descarga de las arquitecturas producidas.
Request-Service
En el Request-Service, la aplicación recibe un JSON con la especificación de la arquitectura diseñada por el usuario en el frontend. Es aca donde el JSON es convertido mediante Apache Jena a RDF, para ser consultado luego por otros servicios quienes requieran información en relación a lo producido por el usuario en el canvas.
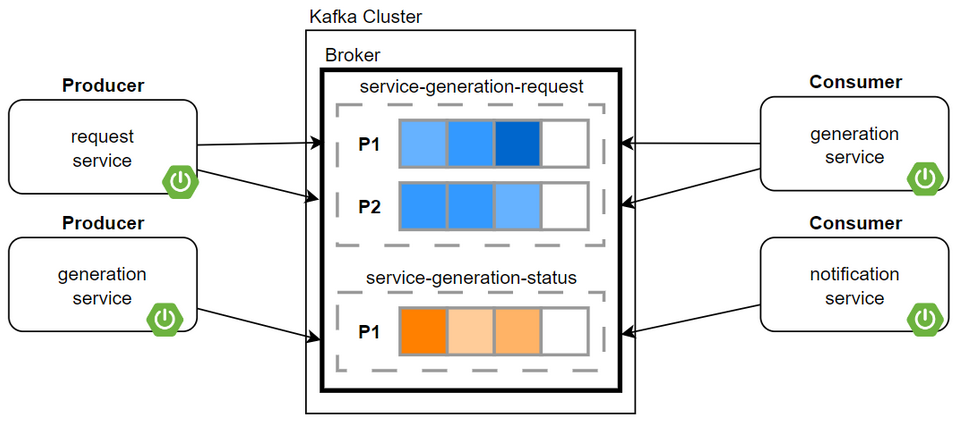
Finalmente, el RDF, en conjunto con el userId (que identifica el productor de la arquitectura), son enviados al topico service-generation-request en el Message Broker, en este caso implementado en Apache Kafka con 2 particiones, con el fin de permitir el procesamiento paralelo y proveer una mayor capacidad de respuesta en caso de una alta carga en el sistema.
Generation-Service
Este componente actúa como el eje central que guía la producción de las arquitecturas solicitadas por los usuarios. Su funcionalidad comienza consumiendo los mensajes provenientes de Kafka, producidos por el Request-Service en el tópico service-generation-request. A partir de los datos contenidos en el RDF, este servicio coordina el flujo:
Solicita a Init-Service los pom.xml necesarios.
Luego envía tanto estos poms como el modelo RDF a Code-Service para la generación del código.
Mientras este proceso avanza, el servicio se encarga de informar continuamente sobre el progreso al Message Broker, lo que permite al servicio de notificaciones mantener al usuario al tanto del estado de su petición. En esencia, el Generation-Service orquesta las solicitudes, guía las interacciones entre los componentes involucrados y asegura que todo el flujo de generación se desarrolle de manera ordenada.
La composición del broker Kafka mencionado se resume en el siguiente diagrama:
Init-Service
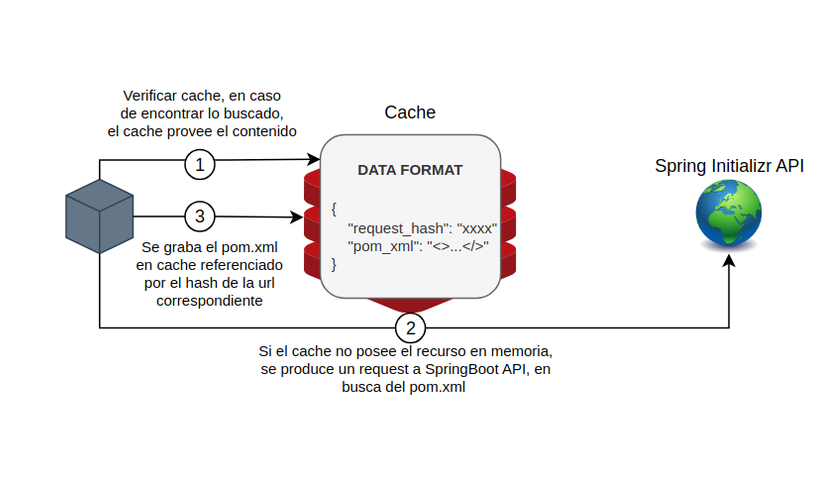
Este servicio no tiene mucho más labor que, en base al RDF recibido, hacer un request por cada servicio al API de Spring Initializr, filtrando la respuesta recibida para extraer únicamente el pom.xml. De esta forma, devuelve una lista de poms con las dependencias de cada servicio.
En caso de que recientemente se haya solicitado un pom.xml similar, este se obtiene desde Redis para evitar el costoso tiempo que implica una petición de este estilo. En el siguiente grafico se ejemplifica el proceso completo del sistema de cache:
Code-Service
Acá es donde la generación de código sucede. Con mucha lógica de negocio de por medio, se transforman las especificaciones del RDF y los poms en un conjunto de servicios Java totalmente funcionales y configurados para interactuar entre sí, o en su defecto, como el usuario lo haya definido en el canvas.
Dentro de Code-Service, se adapta cada componente a múltiples factores con la ayuda de plantillas a través de Apache Velocity. Por ejemplo, si el usuario solicitó la presencia de un config server, no solo se debe agregar la dependencia en el resto de componentes, sino que sus configuraciones deben alojarse en él. También ocurre algo similar con el API Gateway, que se adapta a los paths definidos por el usuario en cada servicio. También ocurren los correspondientes cambios en el caso de seleccionar autenticación vía JWT o modificar el servicio de persistencia, debiendo adaptar las configuraciones de los servicios y de sus Docker-Compose correspondientes, también generados de forma dinámica.
Estas son únicamente las configuraciones globales a las que se adapta cada componente, ya que también pueden comunicarse de forma particular entre sí, si el usuario así lo especificó, configurando su comunicación vía Feign y generando funcionalidades nuevas en los componentes conectados para enriquecer la lógica de negocio.
Download-Service
Este servicio permite al usuario descargar el código generado comprimido en un archivo ZIP. Además, desde el perfil del usuario se puede acceder al historial de arquitecturas, incluyendo detalles como la fecha de creación, tamaño del archivo y enlaces de descarga.
Desventajas e inconvenientes de la arquitectura
Como mencioné en un principio, hay muchas cosas que introduje en el flujo del sistema con el único fin de provocarme la necesidad de adentrarme en campos que no tengo tan pulidos. Una vez aclarado esto, las principales desventajas que encuentro en este sistema son:
Excesiva cantidad de servicios y componentes. Una arquitectura monolítica reduciría muchísimo el tiempo de desarrollo, la complejidad y los costos. Literalmente, hay más servicios que usuarios.
Dependencia total del API de Spring Initializr, ya que sin ella el sistema no es capaz de identificar y generar las dependencias de ningún componente.
Una actualización importante de alguna dependencia rompería el servicio, ya que al utilizar el API de Initializr para generar los poms, siempre se utiliza la última versión del mismo, estando expuestos a una actualización que, con un simple cambio en el nombre de paquetes, rompería las plantillas utilizadas para la generación dinámica de código.
Cómo lo habría manejado en un hipotético caso real
Teniendo en cuenta todo lo expuesto en el apartado anterior y que se trataría de una plataforma nueva, sin necesidad de una gran escalabilidad, habría optado por una solución monolítica, evitando la presencia de todos los componentes de configuración, cloud y mensajería, como lo son el Config Server, el Discovery Server, el API Gateway y el Message Broker.
Finalmente, también se podrían guardar los pom.xml de cada servicio en formato de plantilla, permitiendo que el pom resultante sea consecuente con la arquitectura específica, pero sin la necesidad de hacer múltiples peticiones a un API externa, evitando de esta forma la dependencia de la misma, y, ¿por qué no?, evitando también la presencia de Redis.
Conclusión
Si bien la arquitectura no es lo más eficiente ni lo más práctico, su elección, razonamiento y desarrollo consecuente fueron un proceso que me permitió profundizar en tecnologías que, aunque había probado antes, no había explorado a fondo.
Finalmente, después de mas de tres meses e incontables horas de trabajo, con el proyecto casi al 100%, puedo decir que diseñar desde cero un sistema de esta complejidad y verlo funcionando exactamente como lo especifique es muy gratificante. No solo pude poner a prueba mis habilidades técnicas, sino también aprender a tomar decisiones de diseño más informadas, a afrontar desafíos imprevistos y a valorar la importancia de una buena planificación.
En definitiva este proyecto me enseño mucho, permitiéndome aplicar gran parte de lo aprendido a lo largo de estos anos tanto en la carrera como de forma autodidacta. Sin duda, una muy valiosa experiencia.
Subscribe to my newsletter
Read articles from Tomas Darquier directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Tomas Darquier
Tomas Darquier
I'm fascinated by how things work, which drives my interest in back-end development. Based in Argentina, I'm currently completing my bachelor's degree in Computer Science.