Build Scalable Machine Learning Training Pipelines with Amazon SageMaker
 Anshul Garg
Anshul GargIntroduction
Machine learning workflows often involve repetitive steps like preprocessing, training, and evaluation. Amazon SageMaker Pipelines simplifies this process by orchestrating these steps into automated, reproducible pipelines.
In this guide, we’ll explore how to set up and execute a SageMaker Training Pipeline, enabling efficient model development at scale. The complete source code and notebook for this project can be found in my GitHub repository—feel free to clone it and follow along!

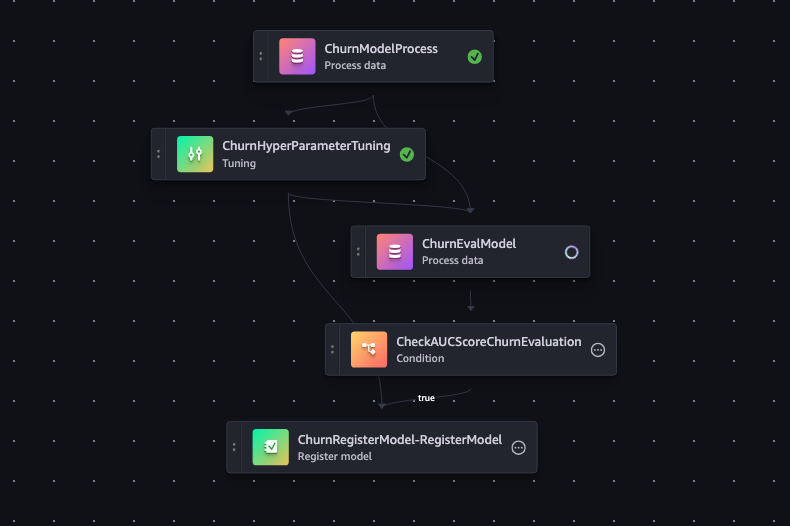
Snapshots of the Pipeline and Model Registry
Below are visual representations of the pipeline workflow and the model registry created during this process:
Pipeline Workflow
This snapshot shows the various steps in our SageMaker Pipeline, including data preprocessing, training, and evaluation.
Setting Up the Environment
Before creating a pipeline, ensure your SageMaker environment is ready:
Prerequisites:
Install the SageMaker Python SDK.
Set up an AWS account and configure necessary IAM roles.
Notebook Initialization:
Import required libraries:
import sagemaker from sagemaker.workflow.pipeline import Pipeline from sagemaker.workflow.steps import TrainingStepDefine your session and role:
import boto3 sagemaker_session = sagemaker.Session() role = sagemaker.get_execution_role()
Pipeline Design
A SageMaker Pipeline consists of a sequence of interconnected steps. Here’s how to define a training pipeline:
Data Preprocessing:
Prepare your dataset using the SageMaker Processing API:
from sagemaker.processing import ProcessingInput, ProcessingOutput, ScriptProcessor processor = ScriptProcessor(...) preprocessing_step = processor.run(...)
Training Step:
Specify an estimator for model training:
from sagemaker.estimator import Estimator estimator = Estimator(...) training_step = TrainingStep( name="ModelTrainingStep", estimator=estimator, inputs={"train": "s3://..."} )
Evaluation Step:
Add an evaluation script:
evaluation_step = ScriptProcessor(...).run(...)
Pipeline Definition:
Combine the steps:
from sagemaker.workflow.pipeline import Pipeline pipeline = Pipeline( name="MyTrainingPipeline", steps=[preprocessing_step, training_step, evaluation_step] )
Executing the Pipeline
Submit the Pipeline:
Start the execution:
pipeline.upsert(role_arn=role) execution = pipeline.start()
Monitor Progress:
Use the SageMaker Console or Python SDK to track execution:
execution.describe()
Retrieve Outputs:
- Access the trained model artifacts and evaluation metrics from your specified S3 bucket.
Conclusion
By automating repetitive tasks, SageMaker Pipelines enhances productivity and ensures consistency in machine learning workflows. Whether you’re building small-scale experiments or large-scale production systems, these pipelines provide a robust foundation for operationalizing machine learning models.
Explore the full code and examples in this GitHub repository.
Subscribe to my newsletter
Read articles from Anshul Garg directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by