Mastering AWS Lambda with S3 Triggers: A Step-by-Step Guide to CSV File Processing
 Balaji
Balaji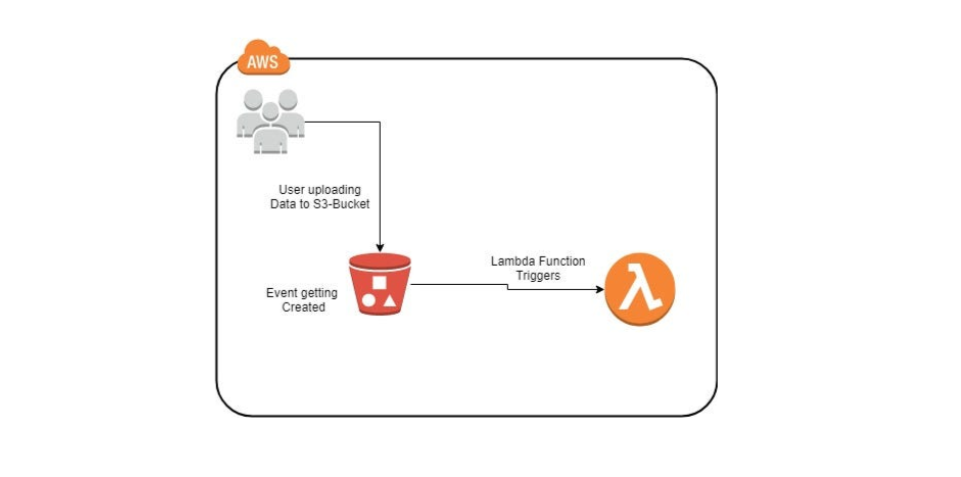
In this blog, we will explore how to set up a serverless solution using AWS Lambda and Amazon S3 to process CSV files automatically. By following this detailed, step-by-step guide, you'll create an efficient system for handling file uploads and processing, complete with event-based triggers and folder structuring.
Prerequisites
Before we begin, ensure you have the following:
Basic AWS Knowledge: Familiarity with Amazon S3, AWS Lambda, and Python.
AWS Account: An active AWS account with administrative access.
AWS CLI (Optional): Installed and configured for additional debugging or file uploads.
Python Knowledge: Basic understanding of Python for editing the Lambda function code.
Overview
Our task includes:
Creating an S3 bucket with the necessary folder structure.
Implementing an AWS Lambda function to process CSV files.
Modifying the function to handle new requirements.
Setting up an S3 event trigger for Lambda.
Testing the system by uploading a sample CSV file.
Step 1: Create an Amazon S3 Bucket
Navigate to the S3 Console:
Go to the AWS Management Console.
Search for S3 and open the S3 service.
Create a Bucket:
Click on "Create bucket".
Enter a unique bucket name (e.g.,
csv-processing-bucket).Choose your desired AWS region.
Leave the default settings or adjust based on your use case.
Click "Create bucket".
Step 2: Set Up the Folder Structure
Open your S3 bucket.
Click "Create folder" and name it
input.- This is where we will upload the CSV files to be processed.
Repeat the process to create a folder named
output.- This folder will store the processed files.
Step 3: Set Up the AWS Lambda Function
Navigate to the Lambda Console:
- Search for Lambda in the AWS Management Console.
Locate the Pre-existing Function:
- A pre-existing Lambda function named
s3-lambdais already provided.
- A pre-existing Lambda function named
Modify the Function Code:
- Replace the code with the following, updating the constants as required:
import io
import boto3
import string
import random
s3 = boto3.client("s3")
INPUT_PREFIX = "input"
OUTPUT_PREFIX = "output"
ID_LENGTH = 12
def random_id():
return "".join(random.choices(string.ascii_uppercase + string.digits, k=ID_LENGTH))
def separate_object(bucket, key):
body = s3.get_object(Bucket=bucket, Key=key)["Body"].read().decode("utf-8")
output = {}
for line in io.StringIO(body):
fields = line.split(",")
output.setdefault(fields[0], []).append(line)
return output
def write_objects(objects, bucket, key):
file_name = key.split("/")[-1]
for prefix in objects.keys():
identifier = random_id()
s3.put_object(
Body=",".join(objects[prefix]),
Key=f"{OUTPUT_PREFIX}/{prefix}/{identifier}-{file_name}",
Bucket=bucket,
)
def lambda_handler(event, context):
record = event["Records"][0]["s3"]
bucket = record["bucket"]["name"]
key = record["object"]["key"]
if key.startswith(INPUT_PREFIX):
objects = separate_object(bucket, key)
write_objects(objects, bucket, key)
return "OK"
Save and Deploy:
- Click "Deploy" to apply the changes.
Step 4: Create the S3 Event Trigger
Attach the Trigger:
Open the
s3-lambdafunction.Under the "Function overview" section, click "Add trigger".
Configure the Trigger:
Select S3 as the trigger source.
Choose your S3 bucket (
csv-processing-bucket).Set the event type to "All object create events".
Specify the prefix as
input/and suffix as.csv.Click "Add".
Step 5: Upload and Test
Upload the Sample CSV File:
Download the sample CSV file from the mission description:
high,data1,10 medium,data2,20 low,data3,30Upload this file to the
inputfolder in your S3 bucket.
Validate Processing:
Check the
outputfolder in your S3 bucket.You should see subfolders for each prefix (e.g.,
high,medium,low), each containing processed files with 12-character random identifiers.
Step 6: Verify and Troubleshoot
Validation Checks:
Ensure the random identifier length is 12 characters.
Confirm that files are correctly categorized into their respective folders (
high,medium,low).
Common Issues:
Trigger Not Working: Wait a few minutes for the S3 trigger to activate or recheck your prefix/suffix configuration.
File Not Processed: Verify that your CSV file is in the correct
input/folder and has a.csvextension.IAM Role Issues: Ensure your Lambda function's execution role has the
AmazonS3FullAccesspolicy attached.
Conclusion
Congratulations! You have successfully created a serverless solution using AWS Lambda and S3 to process CSV files. This system is scalable, cost-effective, and efficient, making it an excellent solution for handling large-scale file uploads in real-time.
By mastering this integration, you are one step closer to becoming proficient with AWS serverless technologies and event-driven architectures.
Future Enhancements
Implement logging using Amazon CloudWatch for monitoring and debugging.
Add error handling in the Lambda function for more robust processing.
Extend the system to handle other file formats or integrate with downstream AWS services like DynamoDB or Amazon SNS for notifications.
If you enjoyed this guide, don’t forget to share it with others who want to level up their AWS skills! 🌟
Subscribe to my newsletter
Read articles from Balaji directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Balaji
Balaji
👋 Hi there! I'm Balaji S, a passionate technologist with a focus on AWS, Linux, DevOps, and Kubernetes. 💼 As an experienced DevOps engineer, I specialize in designing, implementing, and optimizing cloud infrastructure on AWS. I have a deep understanding of various AWS services like EC2, S3, RDS, Lambda, and more, and I leverage my expertise to architect scalable and secure solutions. 🐧 With a strong background in Linux systems administration, I'm well-versed in managing and troubleshooting Linux-based environments. I enjoy working with open-source technologies and have a knack for maximizing performance and stability in Linux systems. ⚙️ DevOps is my passion, and I thrive in bridging the gap between development and operations teams. I automate processes, streamline CI/CD pipelines, and implement robust monitoring and logging solutions to ensure continuous delivery and high availability of applications. ☸️ Kubernetes is a key part of my toolkit, and I have hands-on experience in deploying and managing containerized applications in Kubernetes clusters. I'm skilled in creating Helm charts, optimizing resource utilization, and implementing effective scaling strategies for microservices architectures. 📝 On Hashnode, I share my insights, best practices, and tutorials on topics related to AWS, Linux, DevOps, and Kubernetes. Join me on my journey as we explore the latest trends and advancements in cloud-native technologies. ✨ Let's connect and dive into the world of AWS, Linux, DevOps, and Kubernetes together!