The Secret to Google's Uninterrupted Service: Zero Downtime During Updates
 Lakshay Dhoundiyal
Lakshay Dhoundiyal
In today’s digital world, even a few minutes of downtime can cause significant revenue losses, reduce user trust, and damage a brand's reputation. For tech giants like Google, whose services support billions of users globally, maintaining 100% uptime is non-negotiable. But how does Google manage to deploy updates to its massive infrastructure without interrupting service? The answer lies in a combination of sophisticated technologies and best practices, such as load balancing, continuous integration and deployment (CI/CD), distributed systems, and redundancy. In this blog, we’ll explore the key strategies Google uses to achieve zero downtime during updates, supported by real-world case studies and numerical data.
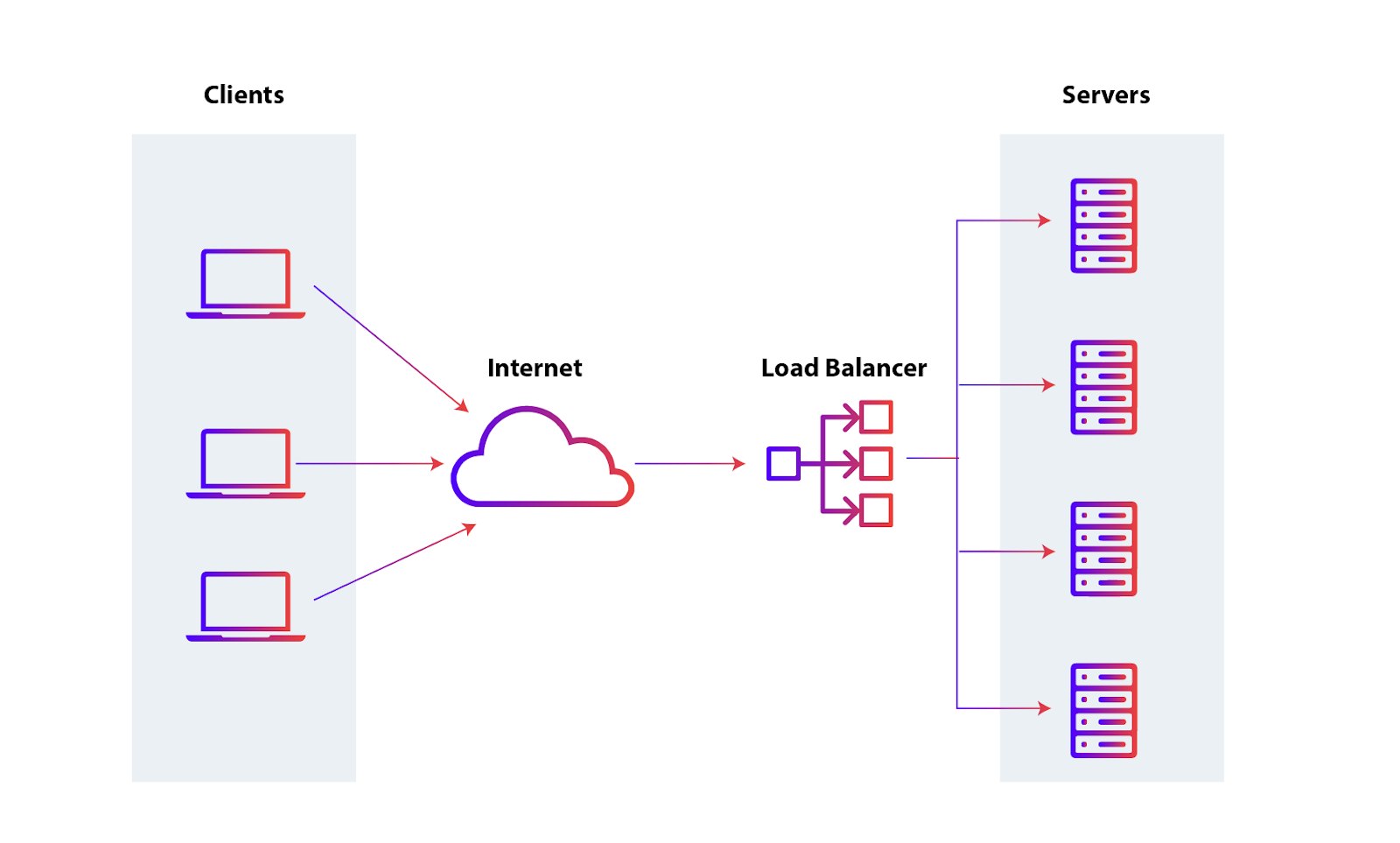
1. The Role of Load Balancing
Load balancing is one of the foundational strategies Google employs to ensure uninterrupted service during updates. With billions of users accessing Google’s services simultaneously, the ability to distribute incoming traffic evenly across multiple servers and data centers is critical.
How Load Balancing Works for Zero Downtime:
Global Load Balancing (GLB): Google uses global load balancing to distribute traffic across its global network of data centers. If one data center is taken offline for maintenance or updates, traffic is automatically rerouted to other active data centers.
Horizontal Scaling: Google scales its infrastructure horizontally (adding more servers), rather than vertically (upgrading existing servers), which ensures that there is always capacity to handle additional traffic during updates.
Real-World Case Study: Google Search Algorithm Update:
When Google deploys a core search algorithm update, which affects the way search results are ranked and presented, it requires updating data centers globally. Google ensures that users across the globe experience no downtime, even as updates are rolled out incrementally to different regions. In 2019, for example, during a BERT update, which affected 10% of all search queries, Google's load balancing system managed to distribute the load without any service interruptions, even as millions of queries were processed simultaneously.
Numerical Data:
- According to a Google Cloud blog, their global load balancer can handle over 3.5 billion queries per second and route traffic to multiple regions in milliseconds, ensuring near-instant failover.
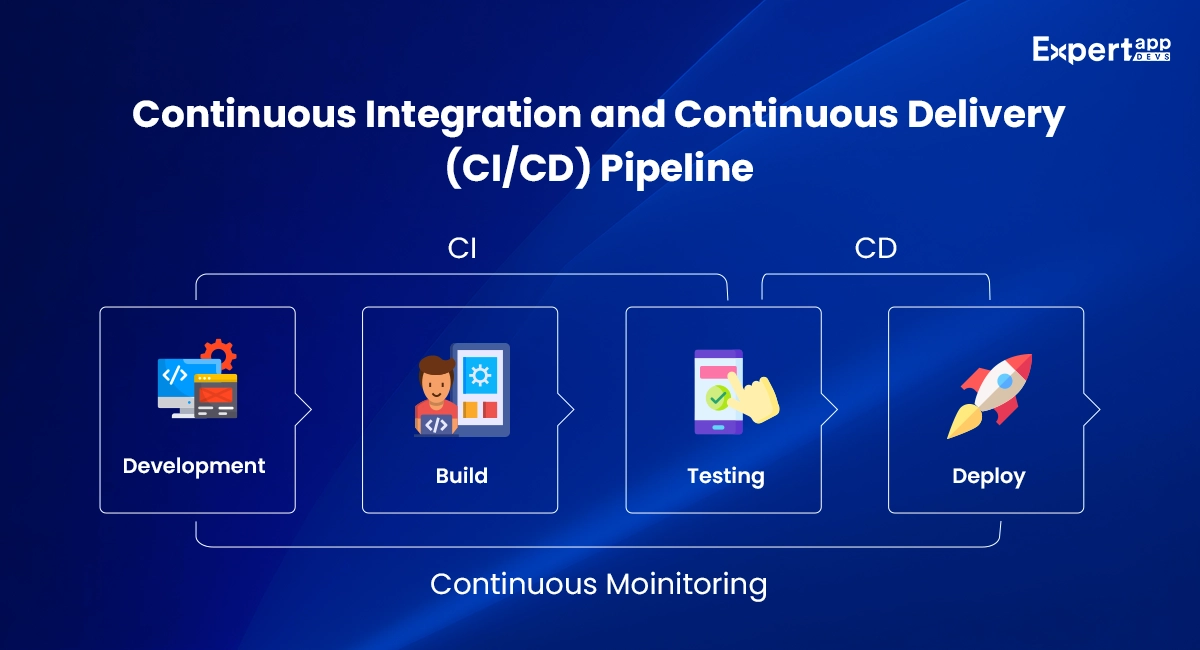
2. Continuous Integration and Deployment (CI/CD)
Google’s development process revolves around CI/CD, which enables the company to release updates frequently and incrementally without disrupting users. With automated testing and continuous deployment, Google ensures that each change to its infrastructure is vetted thoroughly before it is rolled out to production.
How CI/CD Ensures Zero Downtime:
Automated Testing: Google’s CI/CD pipeline integrates automated unit testing, integration testing, and performance testing to ensure that updates will not break services.
Canary Releases: Instead of rolling out updates to all users at once, Google uses canary releases—deploying changes to a small subset of users first to test the impact. If everything goes smoothly, the changes are gradually rolled out to all users.
Case Study: Gmail Feature Rollout
When Gmail introduced Smart Compose in 2018, it was deployed via a canary release. Initially, only a small portion of Gmail users were exposed to the new feature. Google continuously monitored user feedback and performance metrics before scaling the feature to 100% of users. This approach allowed Google to catch any issues early and avoid disrupting users.
Numerical Data:
- Google deploys new code to production approximately 30,000 times a day, according to Google Cloud Platform. The CI/CD system ensures these updates are automatically tested and deployed without causing downtime.
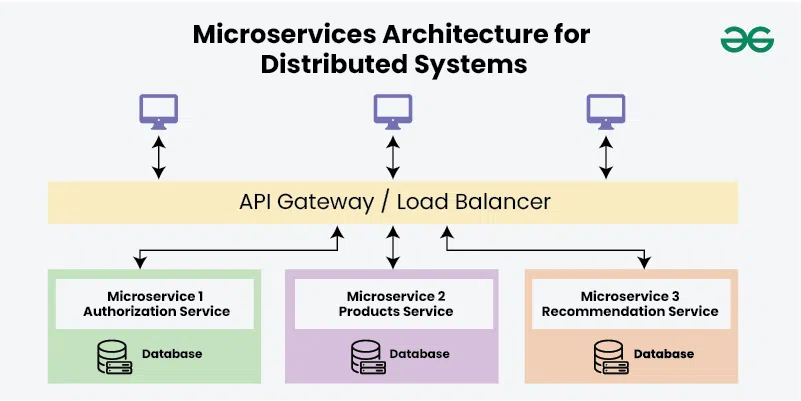
3. Distributed Systems and Microservices
Google's architecture is based on distributed systems and microservices, which means that the failure of one component does not affect the entire system. This decentralized structure plays a crucial role in ensuring high availability during updates.
Why Distributed Systems Work:
Redundancy: Google employs data replication and multi-region deployment to ensure that even if one data center is undergoing maintenance, other data centers can take over. This redundancy is critical for maintaining service availability.
Microservices: Google breaks its services into smaller, independent microservices, which can be updated individually without causing downtime to the entire platform.
Example: Google Cloud Spanner
Google’s Cloud Spanner, a globally distributed database service, operates across multiple data centers to provide high availability and low latency. When updates are required, Google can perform them in one region while other regions continue to serve requests, ensuring zero downtime.
Numerical Data:
- Cloud Spanner has 99.999% availability across regions, thanks to its distributed architecture, which allows updates to be applied without service disruption.
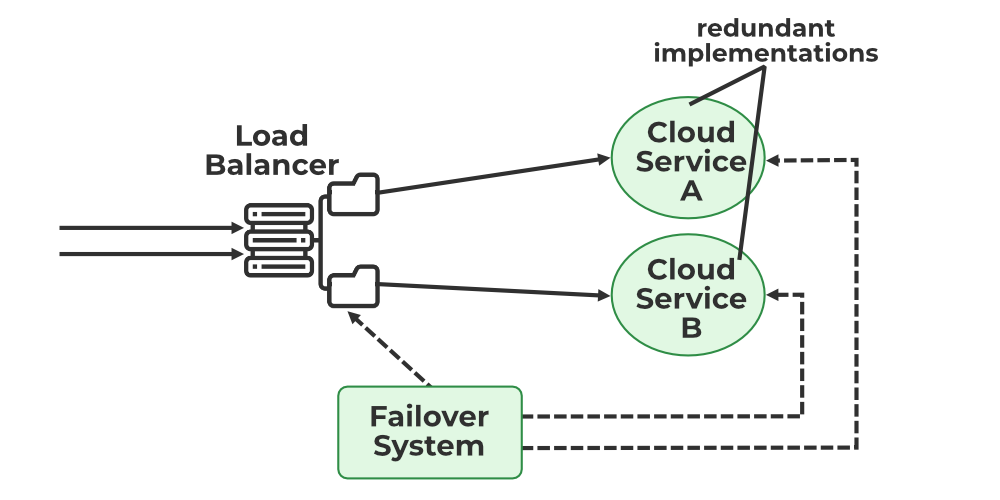
4. Redundancy and Failover Mechanisms
Google’s infrastructure is built to be redundant at every level—hardware, network, data, and services. This redundancy ensures that even if one component fails, there are backup systems in place to take over.
How Redundancy Ensures Zero Downtime:
Failover Mechanisms: Google employs intelligent failover systems that automatically reroute traffic to backup servers or data centers when a primary system fails during an update. This ensures that users experience no interruption in service.
Rolling Updates: Updates are rolled out across different instances of services to ensure that some are always available while others are being updated.
Case Study: Google Cloud Platform (GCP) Failover
Google Cloud’s Compute Engine employs automatic failover during updates. In one notable instance, when Google needed to update its underlying infrastructure in 2018, it did so without any downtime by performing rolling updates across different virtual machine instances.
Numerical Data:
- GCP boasts 99.99% uptime for its services, thanks to the failover and redundancy mechanisms in place, which are critical during updates.
5. Monitoring and Observability
Google’s monitoring and observability tools provide real-time insights into the health of its services, enabling engineers to detect issues before they impact users.
How Monitoring Helps Prevent Downtime:
Stackdriver Monitoring: Google uses Stackdriver, its monitoring and logging tool, to track system performance in real time. This allows engineers to quickly identify and resolve issues during an update.
Automatic Rollbacks: If an issue is detected during an update, Google has automated rollback systems in place that can revert to a stable version instantly, ensuring that users are not affected by errors introduced during updates.
Case Study: Google Maps Update Monitoring
During an update to Google Maps in 2020, automated monitoring detected an issue with map rendering on mobile devices. The system automatically rolled back the update within minutes, avoiding a potential outage for millions of users.
Numerical Data:
- Google performs millions of health checks per minute across its services, ensuring that even the slightest issue is addressed before it affects users.

Google’s ability to maintain zero downtime during updates is the result of a combination of cutting-edge technologies and best practices. From load balancing and CI/CD pipelines to distributed systems, redundancy, and real-time monitoring, Google’s infrastructure is designed to ensure continuous service availability. For businesses seeking to implement similar strategies, the practices used by Google can serve as a comprehensive blueprint for achieving zero downtime during critical updates. By prioritizing load balancing, continuous integration, redundancy, and automation, companies can maintain seamless service and uphold their customers’ trust, just like Google has done for years.
Subscribe to my newsletter
Read articles from Lakshay Dhoundiyal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Lakshay Dhoundiyal
Lakshay Dhoundiyal
Being an Electronics graduate and an India Book of Records holder, I bring a unique blend of expertise to the tech realm. My passion lies in full-stack development and ethical hacking, where I continuously strive to innovate and secure digital landscapes. At Hashnode, I aim to share my insights, experiences, and discoveries through tech blogs.