AI Literacy: The Critical Distinction Between Latent Space and Output Space
 Gerard Sans
Gerard Sans
In the realm of artificial intelligence, particularly with large language models, there's a fundamental misconception that needs addressing: the relationship between an AI model's latent space and its output space. This distinction is crucial for understanding how AI models actually work and what their outputs truly represent.
The Misconception
Many people view AI outputs as direct windows into a model's "knowledge" or "understanding." This perspective is fundamentally flawed. What we see as outputs are actually projections - temporary constructions that emerge from a complex interplay between the model's architecture and our inputs. These projections are ephemeral, existing only in the moment of generation, unlike the more permanent structures within the latent space.
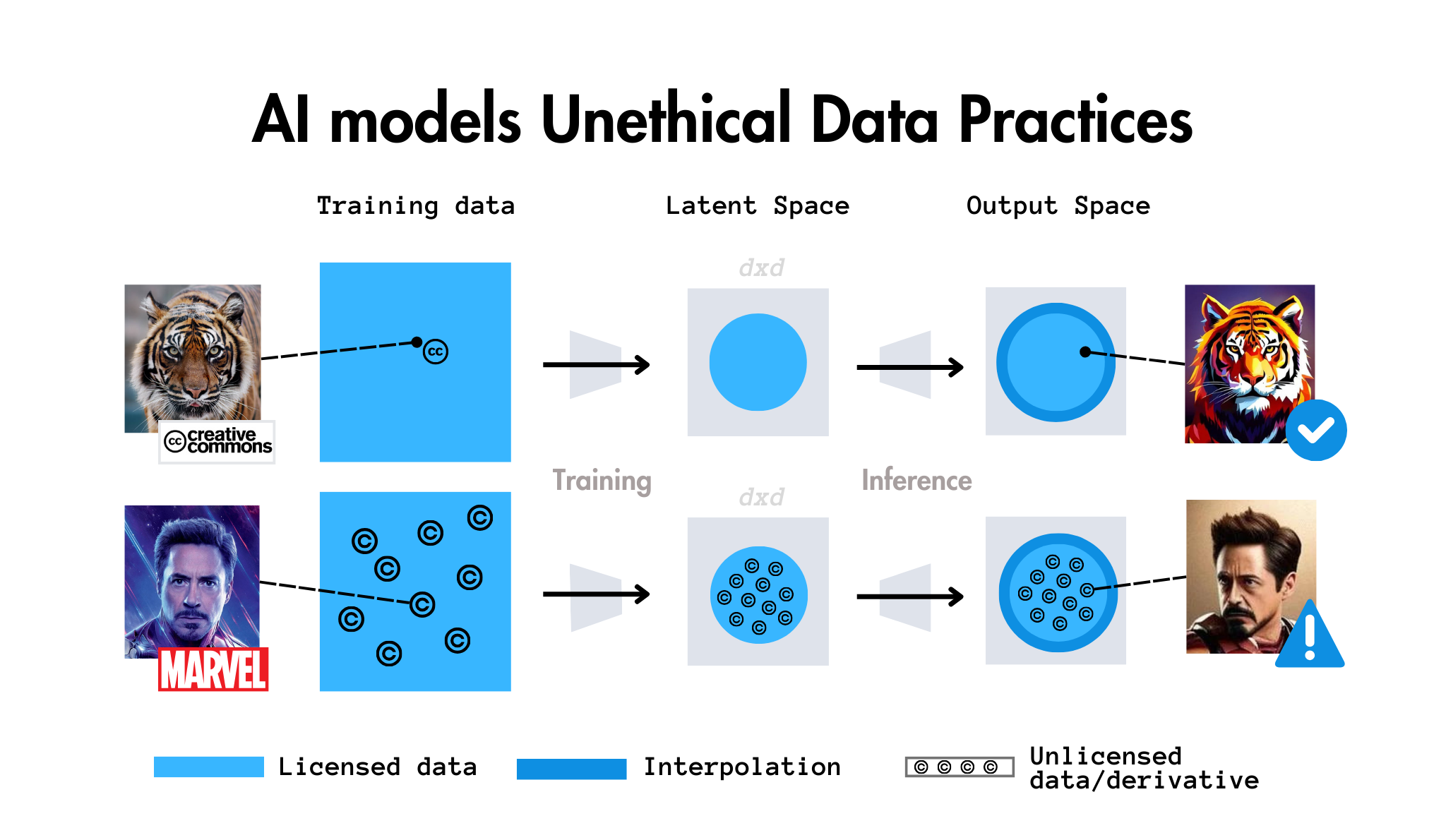
Understanding the Output Space
The output space can be thought of as an vast ocean of possibilities - every potential combination of tokens, words, and patterns that the model could potentially generate given:
The vocabulary it has access to
Contextual limitations
Available dimensional embeddings across the latent space
This space is incredibly vast, far larger than most people realize. It encompasses not just what the model "knows," but all possible combinations and permutations of that knowledge that could be expressed through its output mechanism.
The Nature of Latent Space
In contrast, the latent space is more like the model's "DNA" - it represents the fundamental patterns and relationships encoded during the training process. This space is:
Directly tied to the model's parameter count
Shaped primarily through pre-training
More stable and persistent than the output space
The foundation from which all outputs are generated
The Pre-training vs Fine-tuning Dynamic
One common misunderstanding revolves around the impact of fine-tuning on these spaces. Pre-training shapes the entire latent space, affecting all layers and parameters of the model. It's a deep, fundamental process that establishes the model's core capabilities.
Fine-tuning, however, is more like applying a light filter:
It affects primarily the outermost parameters
Represents a small percentage of the model's total learning
Generally doesn't fundamentally alter either the latent or output spaces
Acts more as a guidance system for existing capabilities rather than creating new ones
The Projection Process
When we interact with an AI model, we're not directly accessing its latent space. Instead, we're:
Providing input that the model processes
Triggering a one-time projection from the latent space
Receiving an output that exists only for that specific generation
This output, once generated, isn't stored or integrated back into the latent space. It's like a photograph - a momentary capture that exists independently of the camera that took it. To reuse or reference that output, it must be manually fed back into the model as new input.
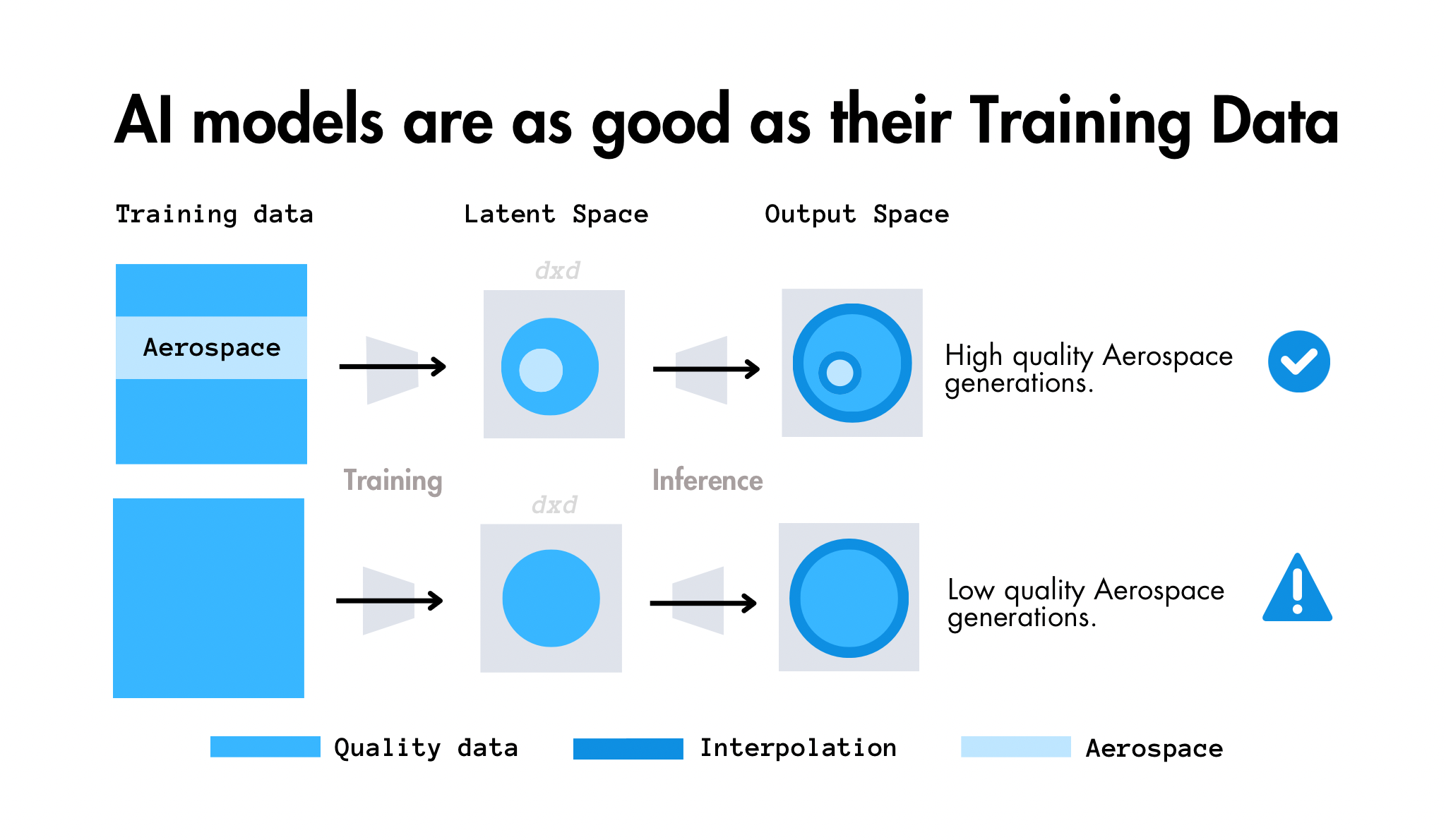
Practical Implications
Understanding this distinction has important practical implications:
We shouldn't assume model outputs represent permanent knowledge structures
Each generation is independent and may vary, even with identical inputs
The model's capabilities are defined by its latent space, not by any individual output
Fine-tuning should be viewed as guidance rather than fundamental transformation
A Practical Example: The Riddle-Solving Illusion
To understand these concepts in practice, let's examine a common scenario in AI discourse: the viral post showing an AI model brilliantly solving a complex riddle. Such demonstrations often lead to sweeping conclusions about the model's capabilities, but they perfectly illustrate the distinction between latent and output spaces we've been discussing.
When we see an AI system solve a challenging riddle, we're observing a single projection from its latent space into the output space. This successful solution, while impressive, is just one point in an enormous space of possible outputs. To understand why this matters, consider what happens when we:
Rephrase the same riddle slightly
Change the word order while maintaining meaning
Use synonyms for key terms
Present the same logical structure with different surface details
More often than not, these minor variations produce wildly different results. Sometimes the model solves the problem brilliantly; other times it fails completely. This inconsistency reveals that we're not seeing a reflection of stable knowledge in the latent space, but rather different projections into the output space, each existing only for that specific generation.
This example illustrates three crucial points about the latent space versus output space distinction:
The output space is vastly larger than the latent space, containing all possible combinations and permutations of the model's knowledge
Individual outputs, no matter how impressive, are ephemeral projections rather than stable representations of the model's capabilities
Success in one instance doesn't guarantee consistent performance across similar problems
This practical illustration helps explain why we can't judge a model's capabilities based on isolated outputs, no matter how impressive they might be. What we're seeing is not a window into the model's "understanding" but rather one possible projection from its latent space into its vast output space.
Moving Forward
As we continue to work with and develop AI systems, maintaining clarity about these distinctions becomes increasingly important. The output space is not a direct window into the model's "mind" - it's a dynamic, generative space where possibilities are temporarily constructed from the more fundamental patterns encoded in the latent space.
Understanding this helps us:
Set more realistic expectations for AI systems
Better understand model behavior and limitations
Make more informed decisions about model development and deployment
Avoid common misconceptions about AI capabilities
By maintaining this clear distinction between latent and output spaces, we can work more effectively with AI systems while avoiding the pitfalls of oversimplified mental models about how they function.
Subscribe to my newsletter
Read articles from Gerard Sans directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Gerard Sans
Gerard Sans
I help developers succeed in Artificial Intelligence and Web3; Former AWS Amplify Developer Advocate. I am very excited about the future of the Web and JavaScript. Always happy Computer Science Engineer and humble Google Developer Expert. I love sharing my knowledge by speaking, training and writing about cool technologies. I love running communities and meetups such as Web3 London, GraphQL London, GraphQL San Francisco, mentoring students and giving back to the community.