Enhancing RAG Context Recall with a Custom Embedding Model: Step-by-Step Guide
 Spheron Network
Spheron NetworkTable of contents
- What is RAG and Why Does it Struggle in Production?
- Understanding Embedding Models
- Customizing the Embedding Model for Enhanced Context Recall
- Step 1: Preparing the Dataset
- Step 3: Setting Up the Information Retrieval Evaluator
- Step 4: Training the Model
- Results and Improvements
- Final Notes: Monitoring and Retraining

Retrieval-augmented generation (RAG) has become a go-to approach for integrating large language models (LLMs) into specialized business applications, allowing proprietary data to be directly infused into the model’s responses. However, as powerful as RAG is during the proof of concept (POC) phase, developers frequently encounter significant accuracy drops when deploying it into production. This issue is especially noticeable during the retrieval phase, where the goal is to accurately retrieve the most relevant context for a given query—a metric often referred to as context recall.
This guide focuses on how to improve context recall by customizing and fine-tuning an embedding model. We'll explore embedding models, how to prepare a dataset tailored to your needs, and specific steps for training and evaluating your model, all of which can significantly enhance RAG’s performance in production. Here’s how to refine your embedding model and boost your RAG context recall by over 95%.
What is RAG and Why Does it Struggle in Production?
RAG consists of two primary steps: retrieval and generation. During retrieval, the model fetches the most relevant context by converting the text into vectors, indexing, retrieving, and re-ranking these vectors to select the top matches. In the generation stage, this retrieved-context is combined with prompts, which are then sent to the LLM to generate responses. Unfortunately, the retrieval phase often fails to retrieve all relevant contexts, causing drops in context recall and leading to less accurate generation outputs.
One solution is adapting the embedding model—a neural network designed to understand the relationships between text data—so it produces embeddings that are highly specific to your dataset. This fine-tuning enables the model to create similar vectors for similar sentences, allowing it to retrieve contexts that are more relevant to the query.
Understanding Embedding Models
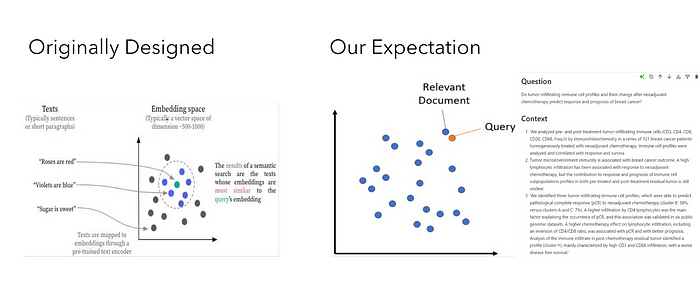
Embedding models extend beyond simple word vectors, offering sentence-level semantic understanding. For instance, embedding models trained with techniques such as masked language modeling learn to predict masked words within a sentence, giving them a deep understanding of language structure and context. These embeddings are often optimized using distance metrics like cosine similarity to prioritize and rank the most relevant contexts during retrieval.
For example, an embedding model might generate similar vectors for these sentences:
Sentence 1: "The sky is clear and blue."
Sentence 2: "The sea reflects the blue sky."
Even though they describe different things, they both relate to the theme of color and nature, so they are likely to have a high similarity score.
For RAG, high similarity between a query and relevant context ensures accurate retrieval. Let’s examine a practical case where we aim to improve this similarity for better results.
Customizing the Embedding Model for Enhanced Context Recall
To significantly improve context recall, we adapt the embedding model to our specific dataset, making it better suited to retrieve relevant contexts for any given query. Rather than training a new model from scratch, which is resource-intensive, we fine-tune an existing model on our proprietary data.
Why Not Train from Scratch?
Starting from scratch isn’t necessary because most embedding models are pre-trained on billions of tokens and have already learned a substantial amount about language structures. Fine-tuning such a model to make it domain-specific is far more efficient and ensures quicker, more accurate results.
Step 1: Preparing the Dataset
A customized embedding model requires a dataset that closely mirrors the kind of queries it will encounter in real use. Here’s a step-by-step breakdown:
Training Set Preparation
Mine Questions: Extract a wide range of questions related to your knowledge base using the LLM. If your knowledge base is extensive, consider chunking it and generating questions for each chunk.
Paraphrase for Variability: Paraphrase each question to expand your training dataset, helping the model generalize better across similar queries.
Organize by Relevance: Assign each question a corresponding context that directly addresses it. The aim is to ensure that during training, the model learns to associate specific queries with the most relevant information.
Testing Set Preparation
Sample and Refine: Create a smaller test set by sampling real user queries or questions that may come up in practice. This testing set helps ensure that your model performs well on unseen data.
Include Paraphrased Variations: Add slight paraphrases of the test questions to help the model handle different phrasings of similar queries.
For this example, we’ll use the “PubMedQA” dataset from Hugging Face, which contains unique publication IDs (pubid), questions, and contexts. Here’s a sample code snippet for loading and structuring this dataset:
from datasets import load_dataset
med_data = load_dataset("qiaojin/PubMedQA", "pqa_artificial", split="train")
# Convert and structure the dataset
med_data = med_data.remove_columns(['long_answer', 'final_decision'])
df = pd.DataFrame(med_data)
df['contexts'] = df['context'].apply(lambda x: x['contexts'])
expanded_df = df.explode('contexts')
expanded_df.reset_index(drop=True, inplace=True)
splitted_dataset = Dataset.from_pandas(expanded_df[['question', 'contexts']])

Step 2: Constructing the Evaluation Dataset
To assess the model’s performance during fine-tuning, we prepare an evaluation dataset. This dataset is derived from the training set but serves as a realistic representation of how well the model might perform in a live setting.
Generating Evaluation Data
From the PubMedQA dataset, select a sample of contexts, then use the LLM to generate realistic questions based on this context. For example, given a context on immune cell response in breast cancer, the LLM might generate questions like “How does immune cell profile affect breast cancer treatment outcomes?”
Each row of your evaluation dataset will thus include several context-question pairs that the model can use to assess its retrieval accuracy.
# Set up prompts to create evaluation questions
from openai import OpenAI
client = OpenAI(api_key="<YOUR_API_KEY>")
prompt = """Your task is to mine questions from the given context.
<Context> {context} </Context> <Example> {example_question} </Example>"""
questions = []
for row in eval_med_data_seed:
context = "\n\n".join(row["context"]["contexts"])
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt.format(context=context, example_question=row["question"])}
]
)
questions.append(completion.choices[0].message.content.split("|"))
Step 3: Setting Up the Information Retrieval Evaluator
To gauge model accuracy in the retrieval phase, use an Information Retrieval Evaluator. The evaluator retrieves and ranks contexts based on similarity scores and assesses them using metrics like Recall@k, Precision@k, Mean Reciprocal Rank (MRR), and Accuracy@k.
Define Corpus and Queries: Organize the corpus (context information) and queries (questions from your evaluation set) into dictionaries.
Set Relevance: Establish relevance by linking each query ID with a set of relevant context IDs, which represents the contexts that ideally should be retrieved.
Evaluate: The evaluator calculates metrics by comparing retrieved contexts against relevant ones. Recall@k is a critical metric here, as it indicates how well the retriever pulls relevant contexts from the database.
from sentence_transformers import InformationRetrievalEvaluator
# Set up evaluator
ir_evaluator = InformationRetrievalEvaluator(
queries=eval_queries,
corpus=eval_corpus,
relevant_docs=eval_relevant_docs,
name="med-eval-test",
)
Step 4: Training the Model
Now we’re ready to train our customized embedding model. Using the sentence-transformer library, we’ll configure the training parameters and utilize the MultipleNegativeRankingLoss function to optimize similarity scores between queries and positive contexts.
Training Configuration
Set the following training configurations:
Training Epochs: Number of training cycles.
Batch Size: Number of samples per training batch.
Evaluation Steps: Frequency of evaluation checkpoints.
Save Steps and Limits: Frequency and total limit for saving the model.
from sentence_transformers import SentenceTransformer, losses
model = SentenceTransformer("stsb-distilbert-base")
train_loss = losses.MultipleNegativesRankingLoss(model=model)
trainer = SentenceTransformerTrainer(
model=model, args=args,
train_dataset=splitted_dataset["train"],
eval_dataset=splitted_dataset["test"],
loss=train_loss,
evaluator=ir_evaluator
)
trainer.train()
Results and Improvements
After training, the fine-tuned model should display significant improvements, particularly in context recall. In testing, fine-tuning showed an increase in:
Recall@1: 78.8%
Recall@3: 137.9%
Recall@5: 116.4%
Recall@10: 95.1%
Such improvements mean that the retriever can pull more relevant contexts, leading to a substantial boost in RAG accuracy overall.
Final Notes: Monitoring and Retraining
Once deployed, monitor the model for data drift and periodically retrain as new data is added to the knowledge base. Regularly assessing context recall ensures that your embedding model continues to retrieve the most relevant information, maintaining RAG’s accuracy and reliability in real-world applications. By following these steps, you can achieve high RAG accuracy, making your
model robust and production-ready.
FAQs
What is RAG in machine learning?
RAG, or retrieval-augmented generation, is a method that retrieves specific information to answer queries, improving the accuracy of LLM outputs.Why does RAG fail in production?
RAG often struggles in production because the retrieval step may miss critical context, resulting in poor generation accuracy.How can embedding models improve RAG performance?
Fine-tuning embedding models to a specific dataset enhances retrieval accuracy, improving the relevance of retrieved contexts.What dataset structure is ideal for training embedding models?
A dataset with varied queries and relevant contexts that resemble real queries enhances model performance.How frequently should embedding models be retrained?
Embedding models should be retrained as new data becomes available or when significant accuracy dips are observed.
Subscribe to my newsletter
Read articles from Spheron Network directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Spheron Network
Spheron Network
On-demand DePIN for GPU Compute