Problems with Debezium and How we (OLake, Open-Source) solves it
 Priyansh Khodiyar
Priyansh KhodiyarTable of contents
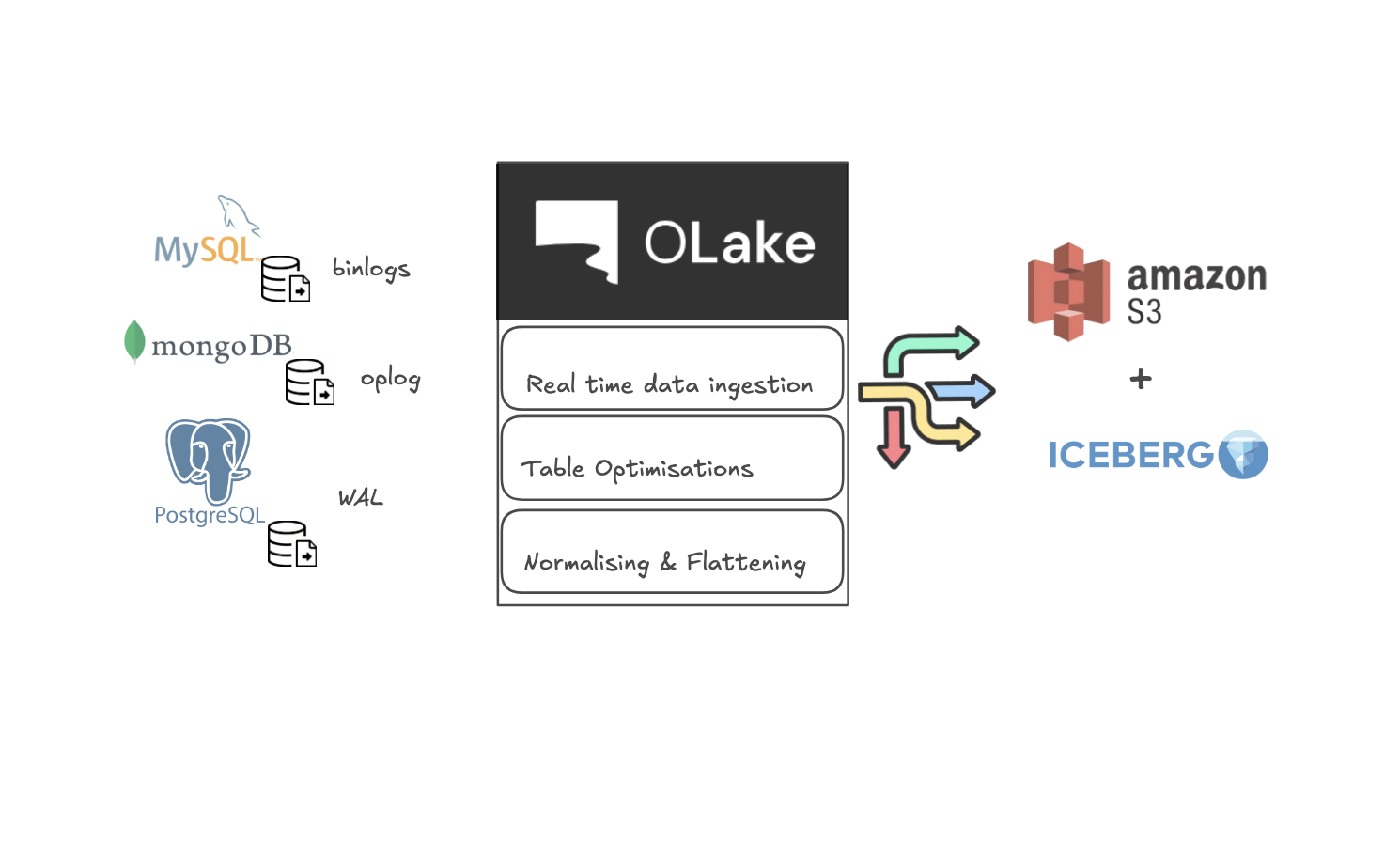
Change Data Capture (CDC) is essential for modern data architectures that require real-time data replication and synchronization across systems. Debezium (a Java utility based on the Qurkus framework), coupled with Apache Kafka, has become a popular open-source solution for implementing CDC.
However, while this combination offers powerful capabilities, it also comes with significant drawbacks that can impact your organization's efficiency and resources.
In the previous article we discussed in details about all the common challenges with Debezium, and now here, we present you an better open source alternative to debezium + kafka setup.
In this article we will see how OLake solves most of the problems that exist with your current Debezium + Kafka Connect setup.
Introducing OLake (Open Source Alternative to Debezium + Kafka Setup)
1. Purpose and Overview
| Feature | Olake | Debezium + Kafka |
| Description | Fastest open-source platform for real-time ingestion and normalization of tables , |
and collections ( MongoDB, currently) data into data Lakeshouses (Iceberg on S3) with minimal coding and single component architecture. | An open-source CDC tool that streams changes from MongoDB to Kafka for real-time data processing. | | Best For | Data teams seeking fault-proof, streamlined pipelines to replicate huge data into a lakehouse for analytics use cases. | Organizations with existing Kafka-based architectures needing robust CDC for MongoDB without built-in transformation capabilities. |
2. Installation and Setup
Installation Options and Ease of Setup
| Feature | Olake | Debezium + Kafka |
| Installation Options | - Open-source & Self-Hosted |
- Deploy on standalone machines with flexibility. | - Open-Source | | Ease of Setup | User-friendly, code-free interface with Docker support for quick deployment.
Minimal configuration required. | Complex setup requiring detailed knowledge of Kafka clusters, Debezium connectors, and potential DevOps support. NO UI. | | Example | As planned launch on popular market places, soon with one-click install as a managed service. | Install Kafka and ZooKeeper → Configure Debezium connectors → Develop custom scripts for scaling and monitoring. |
3. Data Processing
ELT Capabilities and Transformation
| Feature | Olake | Debezium + Kafka |
| ELT Functionality | Fully automated ELT: extraction, data merging, schema and table creation, data type conversion. | Only handles data extraction (CDC). Loading and transformation require custom coding or additional tools. |
| Data Transformation | Automated parsing, extraction, flattening, and transformation of nested JSON (semi-structured data) into relational streams / tables. | Requires Kafka Streams or KSQL for transformations, necessitating additional setup and coding. |
| JSON Array Flattening | Arrays are exploded into separate tables with primary and foreign keys relationship (Flatbread by Datazip). | No native support, outside of Debezium product |
| Schema Handling | Automatically manages schema changes and complex polymorphic (changing key types, INT-> STRING) data without manual intervention. | Minimal schema change support; complex changes may require manual intervention and risk schema drift. |
| Historical Data Handling | Automatically handles both historical and real-time data seamlessly with incremental snapshotting. | Manual backfill processes needed for historical data; requires maintaining large Kafka log retention or manual snapshotting. |
| CDC Impact | Change Data Capture (CDC) utilizes a log-based approach, enabling replication through parallel and multithreaded loading, as well as partitioning and compression techniques. | Snapshotting is incremental but not concurrent, meaning large tables with millions of rows may take hours to complete. During this process, tables remain inaccessible until snapshotting finishes. |
4. Performance, Scalability and Rich Feature
| Feature | Olake | Debezium + Kafka |
| Full Data Sync Speed | - Up to 15x faster full data sync compared to Debezium. | Dependent on Debezium snapshotKafka performance. |
| Incremental Sync Speed | - 27.3x faster incremental synchronization, enabling rapid updates and real-time data availability. | Dependent on Debezium CDC performance; JVM and processing CDC in sequential way affects severely. |
| Scalability | - Automatically handles large datasets with parallel processing by breaking large collections into chunks. | Requires manual scaling of Kafka brokers and connectors, which can be complex and resource-intensive. |
| Snapshotting | Incremental and automatic snapshotting, enabling seamless historical data integration. | Manual and time-consuming snapshots, and potentially causing lag to read large tables. |
| Backpressure and Resource Limitations | Olake monitors data flow and automatically scales resources to handle high volumes, preventing backpressure and ensuring consistent performance | - Possibility of data loss from Consumer lag |
| Latency | - Near real-time replication (1-minute benchmark). | - Real-time streaming with low latency possible. |
| Data Type Support | Supports handling of most commonly used data types (natively supported of each source) including BLOB types. | Certain Debezium connectors have limitations with specific data types; for example, the Oracle connector has restrictions when handling the BLOB data type. |
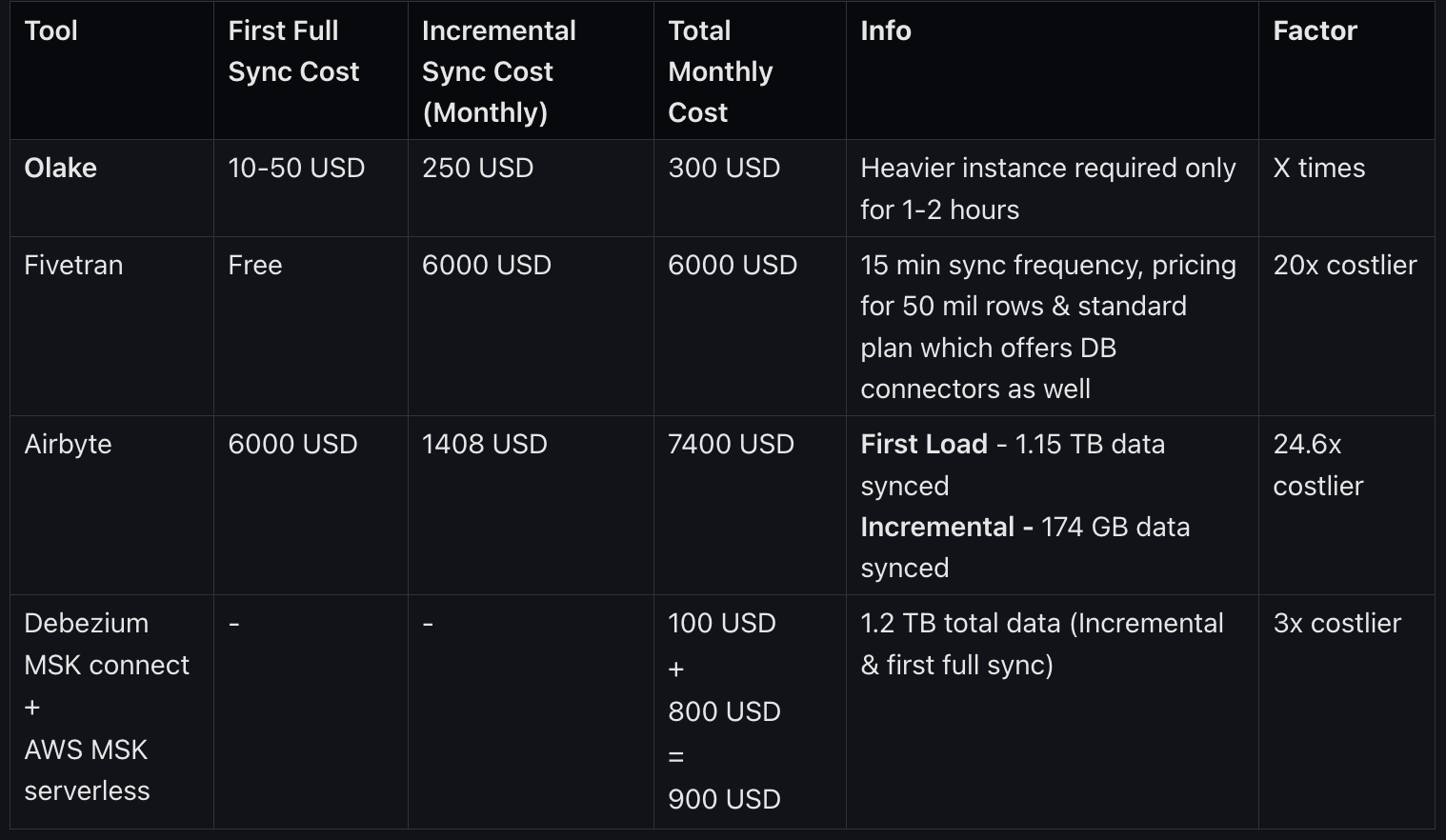
5. Cost Efficiency
Cost Comparison
| Feature | Olake | Debezium + Kafka |
| Pricing Model | Open-Source: Free to use with no licensing fees. | Open-Source: Free to use, but incurs costs related to infrastructure and maintenance. |
| Cost Comparison | - 20x cheaper than Fivetran. | - Infrastructure Costs: Maintaining Kafka clusters can be expensive, especially at scale. |
| Example | A medium-sized company can implement Olake for approximately $300/month, saving significantly compared to managed alternatives. | A similar company might spend $900 - $1200 monthly on cloud resources and DevOps labor to maintain a Debezium + Kafka setup. |
More on Cost. See Benchmarks
6. Integration and Monitoring
Integration with Destinations and Monitoring
| Feature | Olake | Debezium + Kafka |
| Integration with Destinations | - Native Support: Apache Iceberg, Amazon S3, | - Kafka Topics: Streams data to Kafka topics, requiring manual setup of sink connectors for specific destinations. |
| Monitoring & Alerts | Built-In: Real-time monitoring with configurable alerts for pipeline status and schema changes. | External Tools: Relies on Kafka monitoring tools like Kafka Manager or Prometheus for monitoring and alerts, requiring additional setup. |
7. Ease of Use
User Interface and Learning Curve
| Feature | Olake | Debezium + Kafka |
| User Interface | User-Friendly: Designed with a code-free interface, making it accessible for non-technical users. | Technical: Command-line based, requiring familiarity with Kafka and Debezium configurations. |
| Implementation | Quick to implement and manage, tailored for data teams with minimal coding requirements. | Requires significant technical expertise to set up, configure, and manage Kafka clusters and Debezium connectors. |
| Learning Curve | Low: Intuitive setup and management, suitable for teams without deep DevOps resources. | High: Steeper learning curve due to the complexity of Kafka ecosystems and the need for ongoing maintenance. |
8. Community and Support
Support Channels and Documentation
| Feature | Olake | Debezium + Kafka |
| Support Channels | Dedicated Support: Access to Olake and Datazip communities, with opportunities for partnerships and technical advisory roles. | Community-Driven: Supported by a large open-source community with extensive documentation and active forums. |
| Documentation | Comprehensive documentation tailored to Olake’s features and integrations. Docs here. | Extensive and long Kafka and Debezium documentation, but may require piecing together information for specific use cases. |
| Licensing | Apache License 2.0: Open-source, free to use with permissive licensing. | Apache License 2.0: Open-source, free to use with permissive licensing. |
9. Additional Features
Advanced Capabilities and Extensibility
| Feature | Olake | Debezium + Kafka |
| Advanced Capabilities | - Automatic Handling of Complex Data Types and Schema Drift. Complexity will only grow as data grows. | - Minimal Schema Drift Handling functionality |
| Extensibility | NA, input required | Highly flexible, enabling deep customization through Kafka Streams and the development of custom connectors as needed. |
Conclusion
While Debezium with Kafka provides powerful capabilities for CDC, it comes with significant challenges that can impact your organization's resources and efficiency. The complexity of setup, high operational overhead, and the need for specialized expertise make it a solution that requires careful consideration.
Organizations must weigh the benefits against the drawbacks, considering factors like existing infrastructure, team expertise, and long-term maintenance costs. With the emergence of new tools and managed services like Olake, Fivetran, and others, companies now have more options to achieve real-time data replication with reduced complexity and operational burden.
Key Takeaways:
Assess Your Needs: Determine if the flexibility and control of Debezium with Kafka justify the required investment in resources and expertise.
Explore Alternatives: Consider modern CDC solutions that offer managed services, ease of use, and scalability without the need for extensive infrastructure.
Plan for the Future: As data volumes grow and architectures evolve, choose a solution that can adapt to your organization's changing needs.
Subscribe to my newsletter
Read articles from Priyansh Khodiyar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by