Extracting All Images From A Google Doc Using Python
 GreenFlux
GreenFlux
Google makes it as easy as possible to add new images to a Google Doc, with options like drag-and-drop, paste from clipboard, insert from Drive/URL, etc. But they make it surprisingly hard to get the images back out! I’ve written about this before [blog post], but that was before I started learning Python. So I wanted to follow up with this new guide using Google Colab and the Drive Python SDK to add one more method to the list.
This guide will cover:
Connecting to Google Drive/Docs from Colab
Getting a Google Docs’ parent folder ID
Creating a new folder in the parent folder
Extracting URL for all images in the Google Doc
Downloading all images to a new folder in the parent folder
I’ve broken this down into separate functions to make it more modular, and easy to modify for other use cases.
Let’s get started! 🐍
Connecting to Google Drive/Docs from Colab
Start out by creating a new Colab Notebook and install the required libraries:
# Install required libraries
!pip install --upgrade google-api-python-client oauth2client Pillow
Be sure to run this cell before continuing. Then add a new code cell to import the dependencies, and mount Google Drive.
from google.colab import auth, drive
from googleapiclient.discovery import build
from googleapiclient.http import MediaFileUpload
from oauth2client.client import GoogleCredentials
from google.colab import auth, drive
from oauth2client.client import GoogleCredentials
import io
import os
import requests
from PIL import Image
from io import BytesIO
auth.authenticate_user()
drive.mount("/content/drive", force_remount=True)
With the Drive mounted, we can now start using the Docs Service and Drive Service.
credentials = GoogleCredentials.get_application_default()
docs_service = build('docs', 'v1', credentials=credentials)
drive_service = build('drive', 'v3', credentials=credentials)
print(drive_service.about().get(fields="user").execute())
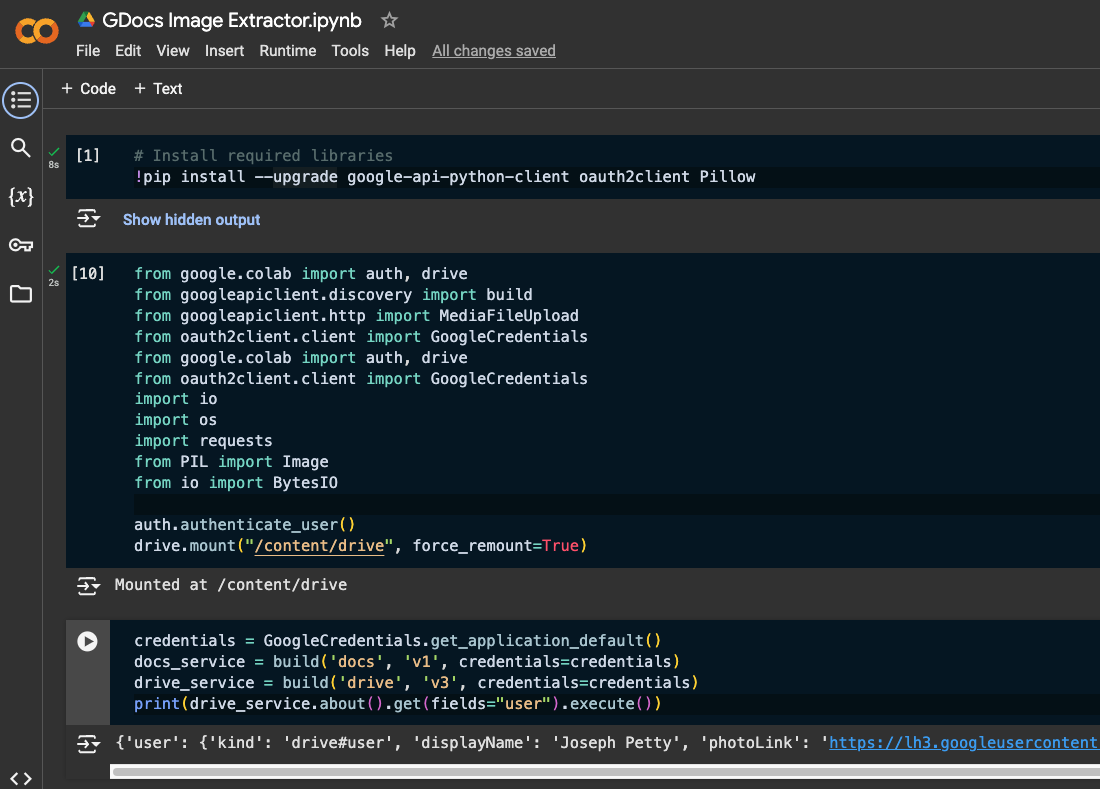
Getting a Google Docs’ Parent Folder ID
The first step is to get the parent folder’s ID, given a Google Doc ID. Then we can use this to create a new folder in the same directory in the next section.
def get_file_parent_folder(file_id):
file = drive_service.files().get(fileId=file_id, fields='parents').execute()
parent_id = file.get('parents', [None])[0]
return parent_id
if __name__ == '__main__':
file_id = 'GOOGLE_DOC_ID'
parent_id = get_file_parent_folder(file_id=file_id)
print(parent_id)
Insert the Doc ID for one of your docs that contains multiple images, and run the cell. You should see the parent folder’s ID printed.
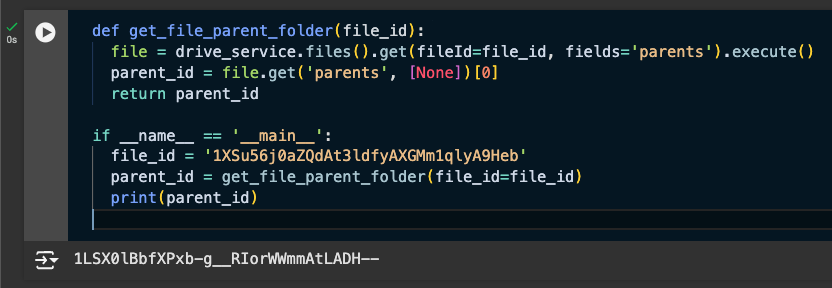
Creating a New Folder in the Parent Folder
Next, we’ll add a function to create a new folder in that parent folder.
def create_folder_in_parent(folder_name, parent_id):
"""Create a new folder in the specified parent folder."""
file_metadata = {
'name': folder_name,
'mimeType': 'application/vnd.google-apps.folder',
'parents': [parent_id]
}
folder = drive_service.files().create(body=file_metadata, fields='id').execute()
return folder.get('id')
if __name__ == '__main__':
folder_name = "New Folder"
parent_id = "root"
new_folder_id = create_folder_in_parent(folder_name, parent_id)
print(new_folder_id)
Run this cell and you’ll see the new folder in the root of your Google Drive.
Extracting URLs for all images in the Google Doc
This is where things start to get tricky. I’ve split this logic up into separate functions because extracting the url’s is a bit complex on its own, before we even get to saving them to Drive.
def get_inline_image_urls(doc_id):
"""
Extracts image URLs from a Google Doc.
Args:
doc_id (str): The Google Doc ID to extract images from
Returns:
tuple: (document_title, parent_id, list of tuples (object_id, image_url))
"""
doc = docs_service.documents().get(documentId=doc_id, fields='*').execute()
document_title = doc.get('title', 'Untitled Document')
parent_id = get_file_parent_folder(doc_id) or 'root'
image_urls = []
inline_objects = doc.get('inlineObjects', {})
for obj_id, obj in inline_objects.items():
if not all(key in obj.get('inlineObjectProperties', {}).get('embeddedObject', {})
for key in ['imageProperties']):
continue
image_url = obj['inlineObjectProperties']['embeddedObject']['imageProperties'].get('contentUri')
if image_url:
image_urls.append((obj_id, image_url))
return document_title, parent_id, image_urls
if __name__ == '__main__':
doc_id = 'GOOGLE_DOC_ID'
print(get_inline_image_urls(doc_id))
This function loops over the inline objects in a Google Doc, which may or may not be images. It checks each one for an image_url, and if found, adds it to an array.
Given a Doc ID, this function returns the Title, its parent folder ID, and an array of the inline images (url and object ID).
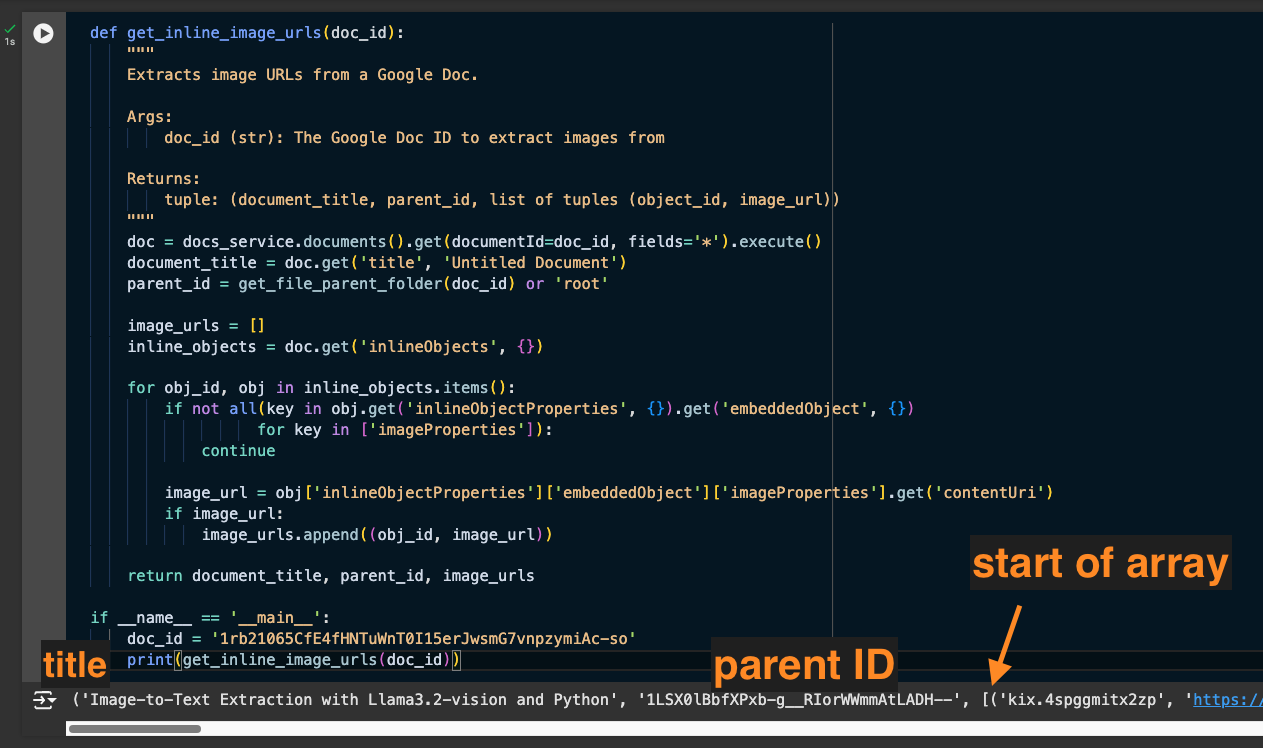
Downloading all Images
Finally, with the list of url’s ready to download, we can loop over the array and add the images to a new folder in Drive.
def download_images_from_urls(document_title, parent_id, image_urls):
"""
Downloads images from URLs, processes them, and saves them to a new folder in Google Drive.
Args:
document_title (str): Title of the document (used for folder naming)
parent_id (str): ID of the parent folder where to create the images folder
image_urls (list): List of tuples (object_id, image_url) to download
Returns:
tuple: (number of successful downloads, list of failed downloads)
"""
folder_name = f"{document_title}_images"
new_folder_id = create_folder_in_parent(folder_name, parent_id)
if not new_folder_id:
print("Failed to create folder. Aborting.")
return 0, []
image_index = 0
failed_images = []
for obj_id, image_url in image_urls:
try:
response = requests.get(image_url)
response.raise_for_status()
image = Image.open(io.BytesIO(response.content))
# Image processing logic with explicit MIME type handling
if image.mode in ('RGBA', 'LA', 'P'):
save_format = 'PNG'
file_ext = '.png'
mime_type = 'image/png'
else:
save_format = 'JPEG'
file_ext = '.jpg'
mime_type = 'image/jpeg'
if image.mode == 'P':
image = image.convert('RGB')
temp_path = f"/content/temp_image_{image_index}{file_ext}"
image.save(temp_path, format=save_format)
file_metadata = {
'name': f"image_{image_index}{file_ext}",
'parents': [new_folder_id]
}
# Create MediaFileUpload
media = MediaFileUpload(
temp_path,
mimetype=mime_type,
resumable=True
)
drive_service.files().create(
body=file_metadata,
media_body=media,
fields='id'
).execute()
os.remove(temp_path)
print(f"Downloaded and uploaded image_{image_index}{file_ext}")
image_index += 1
except requests.exceptions.RequestException as e:
failed_images.append((obj_id, f"Network error: {str(e)}"))
except Exception as e:
failed_images.append((obj_id, f"Processing error: {str(e)}"))
print(f"\nDownloaded {image_index} images to folder '{folder_name}'")
if failed_images:
print("\nFailed images:")
for img_id, error in failed_images:
print(f"- {img_id}: {error}")
return image_index, failed_images
if __name__ == '__main__':
# Replace with your source doc ID to have images extracted
doc_id = 'GOOGLE_DOC_ID'
document_title, parent_id, image_urls = get_inline_image_urls(doc_id)
download_images_from_urls(document_title, parent_id, image_urls)
Note: When uploading files to Drive, you can leave out the MIME type and Google will try to auto-detect it, but that results in multiple warnings in the console (one for every file). I’ve added a little logic to detect the type before uploading, so it can be set explicitly.
Run the cell with your doc ID and you should see a new folder in the same folder as the original Google Doc, with all of the associated images in it.
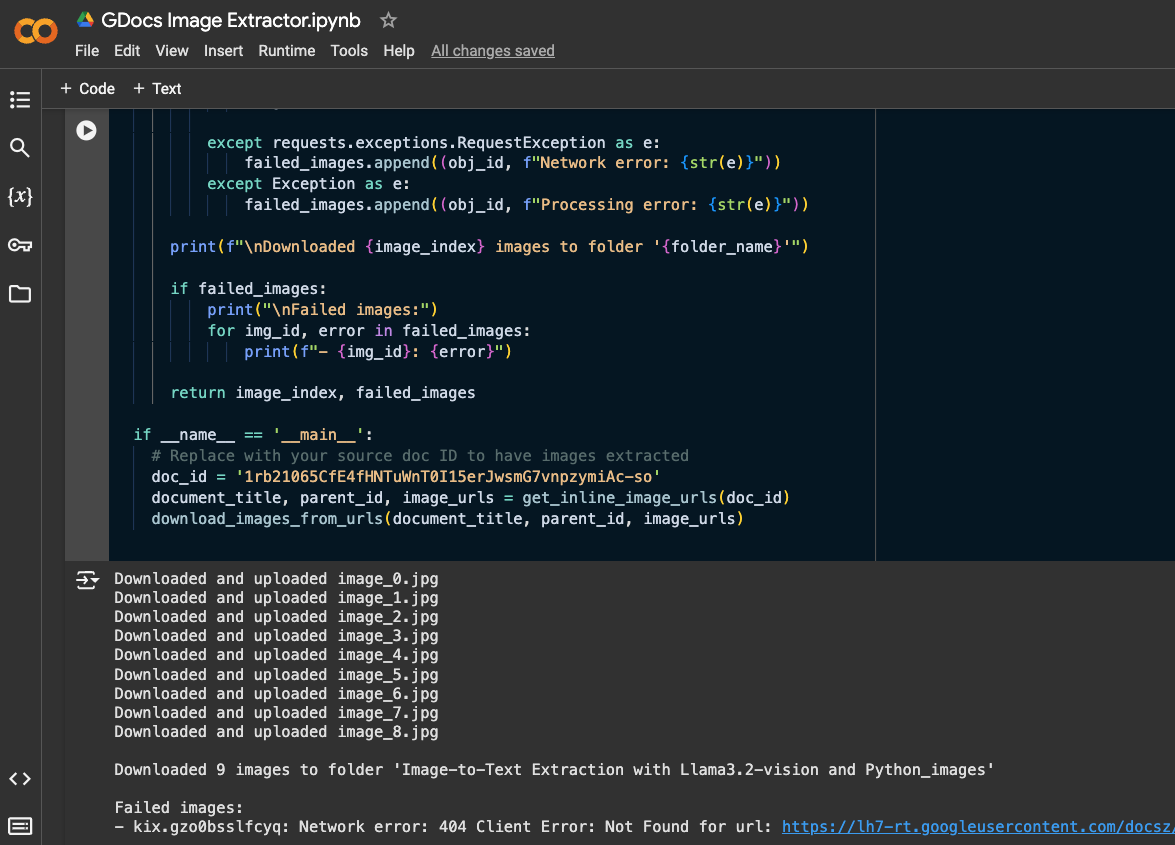
If any of the images fail to download, you’ll see them logged along with the reason.
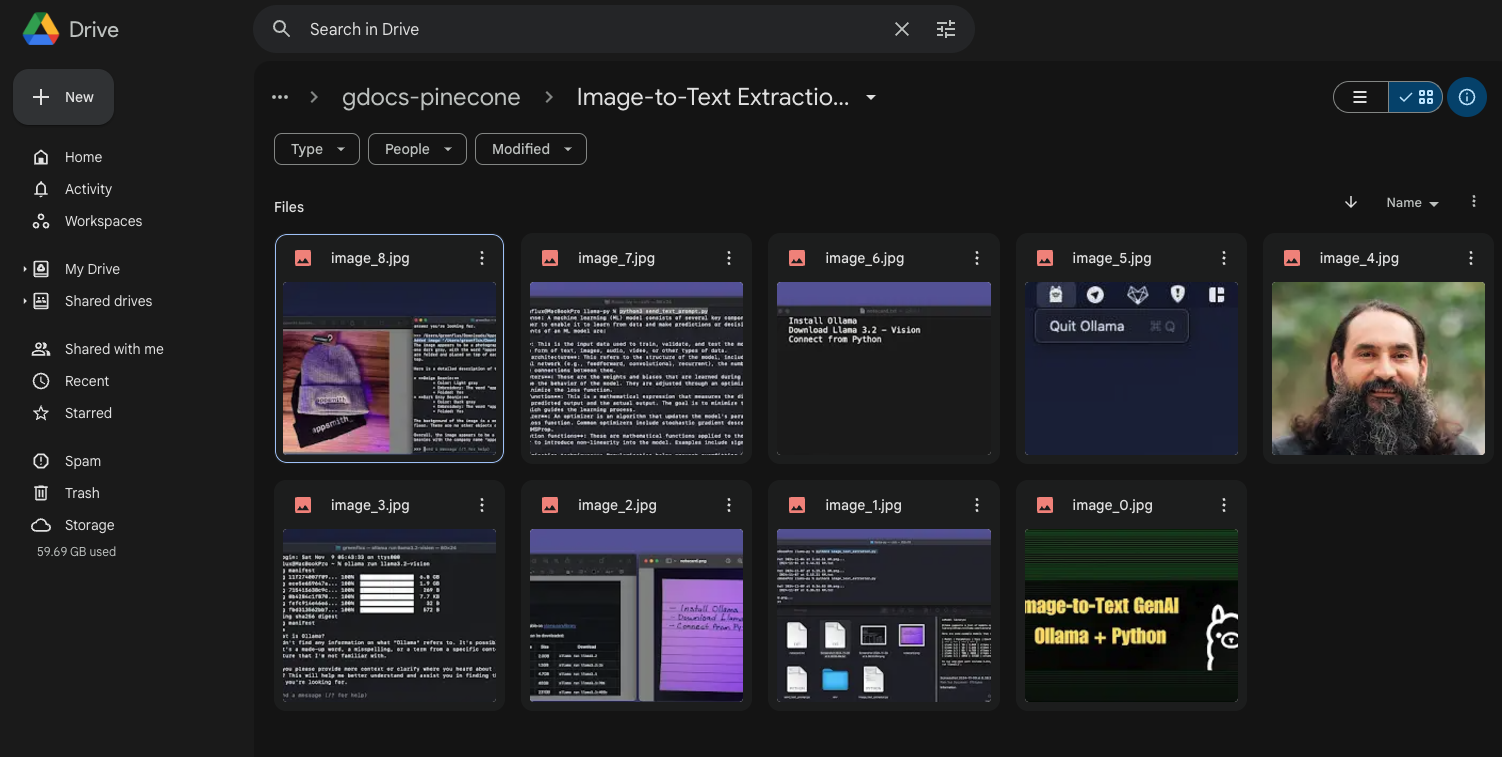
In this case, I used a Google Doc storing a draft blog post on Image to Text Extraction. As you can see, the function created a folder with the same name as the Google Doc, and saved all the images.
Conclusion
Google may not make it easy to extract all the images from Docs, but it turns out there are still quite a few ways to do it. Using Python in Google Colab is a great option, given the ease of authentication and access to Google Drive. From here you could even automate the process on a set of folders, or on a timer to monitor a folder for new files. Got an idea for another use case? Drop a comment below. Thanks for reading!
Subscribe to my newsletter
Read articles from GreenFlux directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
GreenFlux
GreenFlux
NO LONGER ON HASHNODE: Follow at: https://news.greenflux.us/ Nuclear Plant Operator (US Navy), Turned Freelancer, Turned Developer Advocate. Head of Developer Relations @ Appsmith, Inc Founder/ Freelancer @ GreenFlux, LLC GREENFLUX, LLC WE'VE GOT YOUR APP COVERED. Veteran Owned & Operated Since 2016 - Tallahassee, FL