Writing data quality tests in Dataform
 Raghuveer Sriraman
Raghuveer Sriraman
Reliable, accurate data is the foundation of data-driven decision-making. Poor data quality can lead to incorrect insights, a lack of trust in data and data products. It really is quite an obvious statement to make, but what’s not obvious is how exactly to go about getting this “reliable, accurate” data.
Dataform tries to tackle this problem through "Assertions". And since it is Dataform, you can validate data with SQL or Javascript.
Jump to the code here: https://github.com/raghuveer-s/brewery-dataform/tree/assertions-data-quality/definitions
Wait. Assertions? You mean like unit tests?
Kinda, sorta. Unit tests in SQL do exist, but that is different from tests for Data Quality.
For SQL unit tests, we fix the inputs, apply the transformation, and set expectations on what the output should look like. For the most part, it tests the actual transformation. Which is very similar in principle to unit tests in code, where we want to test the behavior of the function.
However, data quality tests set expectations about the nature of the data itself. For example, let’s say in a table called user_first_visit, you’d expect every row to be a user and none of those users are repeated, after all you can have more than one first visit. You’d also expect user id never to be null. We’re not talking about the output of the data transformation, but rather the nature of the output of the data transformation. In general, this probably will be closely tied in with the expectations that the consumer of the data has.
A key point where the difference between SQL unit tests and data quality tests comes into focus is that, data quality tests can break without you ever changing data pipelines. As in, the tests are not strictly Hermetic. For example, let’s say you have a validation on a user’s mobile phone column which checks for number of digits to ensure a valid mobile number. If your company expands into different geographies, it may happen that this particular validation breaks.
In short, the idea behind good data quality is that we capture the “correctness” of the data itself.
Assertions in Dataform
Once again we’ll use the brewery data seen in the Introduction to Dataform post. In the brewery data, we have the daily sales data job which runs every day. The table has just 3 columns : location, daily sales and date. If I imagine myself as a brewery owner for a moment, what I would expect of my daily sales data is:
The daily sales data must be generated for every location, which makes location a unique value in the context of that day.
Date must make sense. I.e, if I was looking at yesterday’s daily sales as a report, it must only have data with yesterday’s date.
Daily sales of each location is > 0.
This is the “business expectations” part of data quality. We talk about the first two in the inbuilt assertions section.
The last one is interesting. Sales of a location “must be greater than 0”? What if there were no sales at that location? Then technically it’s not a “data” issue right? Well.. maybe. Maybe the data pipeline is indeed broken, but maybe something happened at the data source, maybe the internet was down, maybe this maybe that. The only thing we know for a fact is: It’s weird if sales is 0 all of a sudden. Strictly speaking, this falls under data anomaly detection. And the cool thing about Dataform is that it integrates very well with BigQuery. And BigQuery has anomaly detection out of the box (https://cloud.google.com/bigquery/docs/reference/standard-sql/bigqueryml-syntax-detect-anomalies). We’ll touch upon this in the manual assertions section.
Inbuilt assertions
Data quality checks on the generated data is very useful, the earlier we know about quality issues, the better. The inbuilt assertions can be set in the config block, which means the same SQLX you use for table / incremental / view workflow objects just need a bit of tweaking.
Out of the box, Dataform offers:
Null checks
Uniqueness checks
Custom row level conditions
For us this, this looks like:
config {
type: "incremental",
// .. the other configurations
// Note: Remember the partitions filtering caveat mentioned below
assertions: {
nonNull: ["Location"],
uniqueKey: ["Location"],
rowConditions: [
'd < TIMESTAMP_TRUNC(CURRENT_TIMESTAMP(), DAY)'
]
}
}
SELECT
Location as location,
TIMESTAMP_TRUNC(Brew_Date, DAY) d,
SUM(Total_Sales) AS daily_location_sales
FROM
${ref("brewery_partitioned_clustered")}
WHERE
TIMESTAMP_TRUNC(Brew_Date, DAY) >= timestamp_checkpoint
GROUP BY
location, d
pre_operations {
DECLARE timestamp_checkpoint DEFAULT (
${when(incremental(),
`SELECT MAX(d) FROM ${self()} WHERE d is not null`,
`SELECT TIMESTAMP("2023-01-01")`)}
)
}
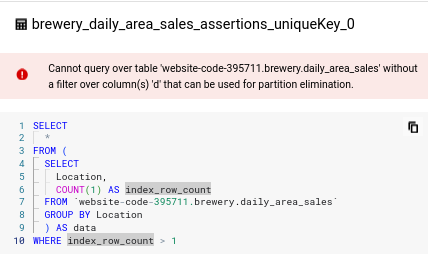
Note: If partition filters are mandated using requirePartitionFilter in the config block, the inbuilt assertions will not work. This is because internally, Dataform uses Views to implement assertions. And since a View is basically just a query, it requires the partition filter to be specified, and Dataform has no way to know ahead of time which partition you want for the View.
For example, the uniqueness constraint above gets converted into this query by Dataform:
Manual assertions
This is my preferred way of writing assertions because I like the idea of separating my code which does the assertions and the code that does the data transformations. In this style, assertions are just another Action in Dataform. This means you can utilize the full power of BigQuery SQL. And since it’s just another Action, you can have independent tags for assertions, dependencies become much more readable in my opinion, and even specify assertions in a different release configuration with its own schedule if needed.
Since we’re looking at anomaly detection, we will use BigQuery’s machine learning capabilities. Let’s keep it simple and use k-means.
Let’s create the model in BigQuery first.
CREATE OR REPLACE
MODEL `website-code-395711.brewery.sales_anomaly`
OPTIONS(
MODEL_TYPE='kmeans',
KMEANS_INIT_METHOD='kmeans++',
NUM_CLUSTERS=10
)
AS
SELECT
location, daily_location_sales
FROM
`brewery.daily_area_sales`
WHERE
d IS NOT NULL;
Then, we need the anomalous data. For this, I just manually inserted daily sales data with 0 value for the location “Koramangala”. And for those of you who know the scene in Koramangala, Bengaluru, you can most definitely agree that a brewery having beer sales of 0 is definitely weird 😁
Next, run the anomaly detection as an assertion. Create a new folder called “assertions” under “definitions” folder, and then the sales_anomaly.sqlx.
config {
type: "assertion",
tags: ["daily", "anomaly_detection"]
}
SELECT
*
FROM
ML.DETECT_ANOMALIES(
MODEL `brewery.sales_anomaly`,
STRUCT(0.01 AS contamination),
(SELECT location, daily_location_sales FROM `brewery.daily_area_sales` WHERE d >= TIMESTAMP('2024-01-01'))
)
WHERE
is_anomaly IS TRUE
If done right, you should see something this.

This is great, we can use all of BigQuery’s cool stuff directly in Dataform. But still, something is not quite right. Assertions are “binary” in some sense, that is they can say “all good” or scream “Alert!”, but anomalies fall somewhere in the middle which says “Hey, something’s odd.”. Unfortunately, this type of alert levels is not something doable out of the box in Dataform and needs more effort.
Writing Assertions in Javascript
Since Javascript is a first class citizen in Dataform, you can use it write assertions as well. It becomes extremely easy to create test assertions by applying programming patterns, for example, if we have the same test assertion to apply for different tables, we can just do so using for loops. You can also bring the benefits of having node modules into the mix. For example, I can imagine using json schema validators if you are storing event data in your tables. We’ll cover using Javascript in Dataform with some examples in a future article.
A word on Data Quality
So far, we’ve described the why and how of Data Quality tests but to a lesser extent, the what to test for. A brief overview of the so-called “six pillars of data quality” should give a bit more direction in that regard:
Accuracy: The degree to which data about the real world object or event is captured. Eg: Filling out a tourist visa application and you put a space accidentally in your first name, leave the middle name blank, and fill the last name correctly. It is easy to imagine that this may cause problems as you try to explain yourself at the immigration counter. Closely related to precision. Eg: Event timestamps till millisecond granularity.
Completeness: How “complete” is the data being stored. Say for user data, do we have everything that adequately describes the user for our needs? Eg: A name can be first name, last name. But you could also capture middle name, birth name (Will your system use it though?).
Consistency: Multiple data stores must not differ in the data stored. Eg: Same userId must not have different birth dates in two different systems.
Timeliness: Freshness of the data. Eg: Must not store events timestamped in the future, must not have “stale” data (definition of stale comes from business logic).
Uniqueness: Unique constraints in the world must be respected in the data as well. For example, unique email ids. There are some edge cases here though. For example, Mobile numbers are unique, but they can be reassigned to a different person if the original holder decides to cancel their mobile subscription.
Validity: Semantic or syntactic checks. Eg: Email must have “@” in it.
Conclusion
We’ll close off with a quick overview of the pros and cons.
Pros:
If you’re using BigQuery, data quality assurance becomes extremely easy.
Assertions are written in SQL or Javascript. SQL is the lingua franca of the data domain, Javascript brings node modules with it should you need it. Both are widely used and powerful, making it a strong choice for writing data quality checks.
Assertion failures are just like workflow execution failures. Which means if you have observability built on Google Cloud Logging, you can easily reuse that for alerts on data quality.
Cons:
Rows that break the assertions are accessible through a view. But since this is created on every run of the assertions, if the next assertion is run before you get the chance to view the existing assertion failures, the failing rows may be lost.
While we can alert on data quality failures, we cannot configure different alerting levels. I’ve often found that some data quality checks are more important than others, having a way to configure this does not exist out of the box.
Overall, Dataform assertions offer a simple and flexible way to get started on ensuring the quality of your data in BigQuery. However, it’s simplicity does have some tradeoffs. It’s a great tool in the data quality toolbox, but it does have its limitations compared to more powerful tools out there.
Subscribe to my newsletter
Read articles from Raghuveer Sriraman directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Raghuveer Sriraman
Raghuveer Sriraman
Working mostly on Data Engineering, Machine Learning and Bayesian analytics.