Paper review - Exploring the landscape of spatial robustness
 Victor Z
Victor ZTL; DR
Image classification model (probably vision models in general) are spatially brittle. Small combination of rotation and translation can radically change model output.
Introduction
The focus in on spatial robustness, i.e. small spatial transformations (rotation and translations).
More specifically, the idea is to use small transformation to craft adversarial example, instead of the classic gradient-based optimization. More generally, it is interesting to study these perturbation even without an adversary, since they naturally occur in the real world. In a previous paper [2], it was noted that state of the art convolutional network were brittle wrt small transformations (on MNIST and CIFAR10).
Given this brittleness, a lot more questions open up, in logical order.
What's the best method to craft a "spatial" adversarial example?
Different methods can be used to optimize a spatial perturbation. One way is to make a differentiable rotator+translator and optimize the transformation using gradient descent (called first order method, since it relies on first order derivatives of the error). In this case, they do Projected Gradient Descent for 200 steps, each step can be a maximum of ~0.6 degrees of rotation or ~0.25 pixel translation
However, comparing spatial attacks to adversarial attacks crafted in pixel space, the search space is significantly smaller (e.g. the number of possible rotations and translation is significantly smaller then number of possible modification to pixels). This opens up grid search as a way to optimize the attacks. In this case, the grid has 5 translations per direction and 31 values for rotation.
Finally, one can always attempt random transformation as a sort of baseline. To make it a little stronger, they sample 10 random roto-translation, evaluate all versions and pick the worst loss-wise (Worst-of-10)
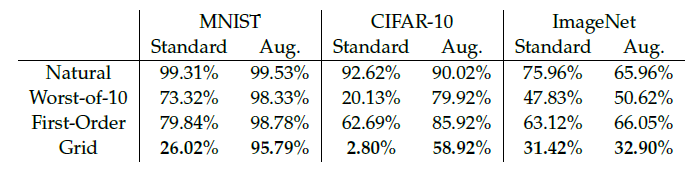
Focusing on ImageNet (since everything works on MNIST and CIFAR):
First order attackers are surprisingly weak, despite having considerable computational budget
Worst-of-10 and grid search work very well. The former is particularly computationally effective, requiring 10 forward passes per images vs ~150 passes for the grid search.
Spatial attacks and \(l_\infty\) attacks seems to be additive in effects.
Can data augmentation mitigate this issue?
Rotation and translations are bread and butter data augmentation transformations. A natural question is if just adding more rotation and translation (i.e. even more than the attacks search space) improves spatial robustness. They also try \(l_\infty\) adversarial training (PGD-based attack) and removing cropping (from CIFAR and ImageNet).
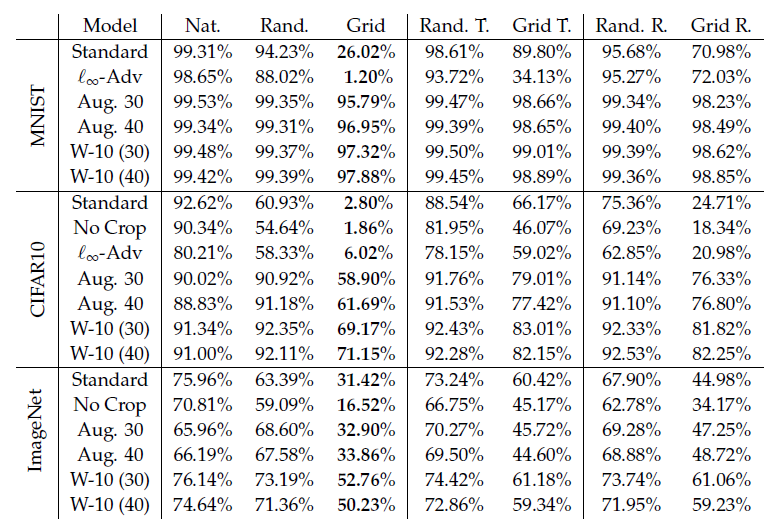
Setting aside MNIST and CIFAR (since everything works on MNIST and CIFAR), and focusing on the combined attacks (first three columns) the results on ImageNet are very interesting:
Aggressive data augmentation seems pretty ineffective against adversarial attacks (recover ~2% accuracy), and it loses ~10% accuracy on clean samples. However, it seems pretty effective against random transformations. This appears to be one of the case where benchmarks and real world performances are anti-correlated.
Removing cropping actually makes the classifier worse all around
Robust optimization techniques seem to be very helpful! They recover most of the accuracy when the attack is not adversarial and are the best defense against the most powerful adversarial studied (grid search) Taken together, the lesson appears to be to prefer worst of 10 training, if you can afford the extra computational load (which is pretty heavy).
How comes first order methods fail?
An analysis of the loss landscape is provided.
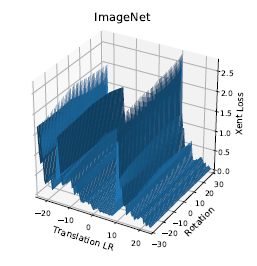
Visually, one can get an idea on why gradient based method fail. There are a lot of local minima, where a gradient based optimizer could get stuck.
This figures reminds me a lot of another paper [3], where spatial brittleness was linked to aliasing. It seems consistent to hypothesize that at least some spatial brittleness is induced by aliasing. It would be interesting to plot the same loss landscape for an anti-aliased network.
Conclusions
Spatial robustness is one of those things that is not really evaluated in standard benchmarks (e.g. ImageNet validation accuracy) but is absolutely critical for any real-world scenario. This is one of those paper that actually offers nice solutions, but given that the absence of public libraries (and computational cost) is rarely taken into account. Great idea for contribution to augmentation libraries!
References
[1] L. Engstrom et al. - Exploring the Landscape of Spatial Robustness
[2] A. Fawzi, P. Frossard - Manifest: are classifiers really invariants?
[3] R. Zhang - Making Convolutional Networks Shift-Invariant Again
Subscribe to my newsletter
Read articles from Victor Z directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by