STATE-MACHINES: How to Begin Building an Agent from Scratch on Android
 Richard Thompson
Richard Thompson
Conversational AI: The DNA of the next generation of operating system.
The complexities of conversational agents varies according to how complex the task is. Ultimately, we will all be interacting with agents (operating systems) on our computers that understand everything we are trying to do and can even predict what we are likely to want to do next, and are able to seamlessly carry out tasks and commands that we provide, while also maintaining lists of ongoing goals (essentially maintaining a set of project management operations), and potentially even helping us schedule these goals effectively. All of this done through a mixture of conversation and visual representations.
In a world where our private Ai- Agent-OS can seamlessly generate conversation, lucid and relevant thoughts and ideas (if not decisions) it will also be able to communicate with us using imagery and animation. These Next Gen OS’s will also need to be created to help us manage the complexity of the everyday world. Some of this will be to do with prioritising and sequencing tasks and goals, others with selecting exactly what information to present at exactly the right time.
At this point, we will also consider how we change these AgentOS’s behaviour, what things and when they learn, and how and when to delve under the hood ourselves, to modify the internal workings of the thing. It’s a super exciting set of ideas, and we’re only a few years away from this being a reality.

This definition from Google engineers in this interesting video from Google Cloud Events.
Building An Agent from Scratch
For now though, we’re at the beginning of understanding how to design and implement these types of autonomous programs. And like all types of design and building, we must start with the simplest and most atomic form of the idea, and then expand in complexity over time.
In my Android App, Vox_Manifestor, I created a kind of Ai “Genie” who helps the user with 3 high level outcomes they are wishing to achieve. The Genie first helps the user to define their “3 wishes.” After this, rather than getting too much into the details, it uses a process to retrieve information from the user, which it then stores in the user interface (essentially a way for the user to access the Genie’s “memory,” i.e. things that have been discussed).
This information can then be used to help the user bring their wish into manifestation, using 5 methods:
Working to refine and continually define the achieving of the goal, what it would look like (sensory description), and having the user practice experiencing these things in their mind (positive visualisation)
Examining where the user is with regard to achieving this goal, and establishing the main things that are holding the user back from achieving this goal, and suggesting plans of action to resolve these, having the user suggest what needs to be done next, and in what time frame.
Speaking positive affirmations relating to achieving the goal, as a kind of meditation / hypnosis / self affirmation process.
As you can see, the agent overall needs to:
Be able to access the underlying information that has been retrieved in previous iterations, and stored within the App’s data layer & user interface, and
Use the current ‘state of play’ to inform its understanding of the types of actions that can and should be performed at different stages of the information gathering process,
Suggest a potential course of action for the current session (e.g. 3 minutes of visualising each of 3 goals, or more clearly defining one goal and working on that, etc.)
Take into account what has been done previous sessions, compared with what the options are, and how frequently different actions should be performed ideally.
Have a way of prioritising certain behaviours over others, then running through these behaviours in turn for each of the wishes. It must be able to maintain some kind of working memory relating to these behaviours and when they were last performed.
Always be proactive in its interactions with the user, ideally providing options at each potential stage of the decision tree, along with suggestions based on its own analysis of the existing information or lack thereof.
So, from an intially relatively simple premise (setting 3 goals and exploring one of 3 processes around each of them), a rather complex set of potential activities and needs emerges.
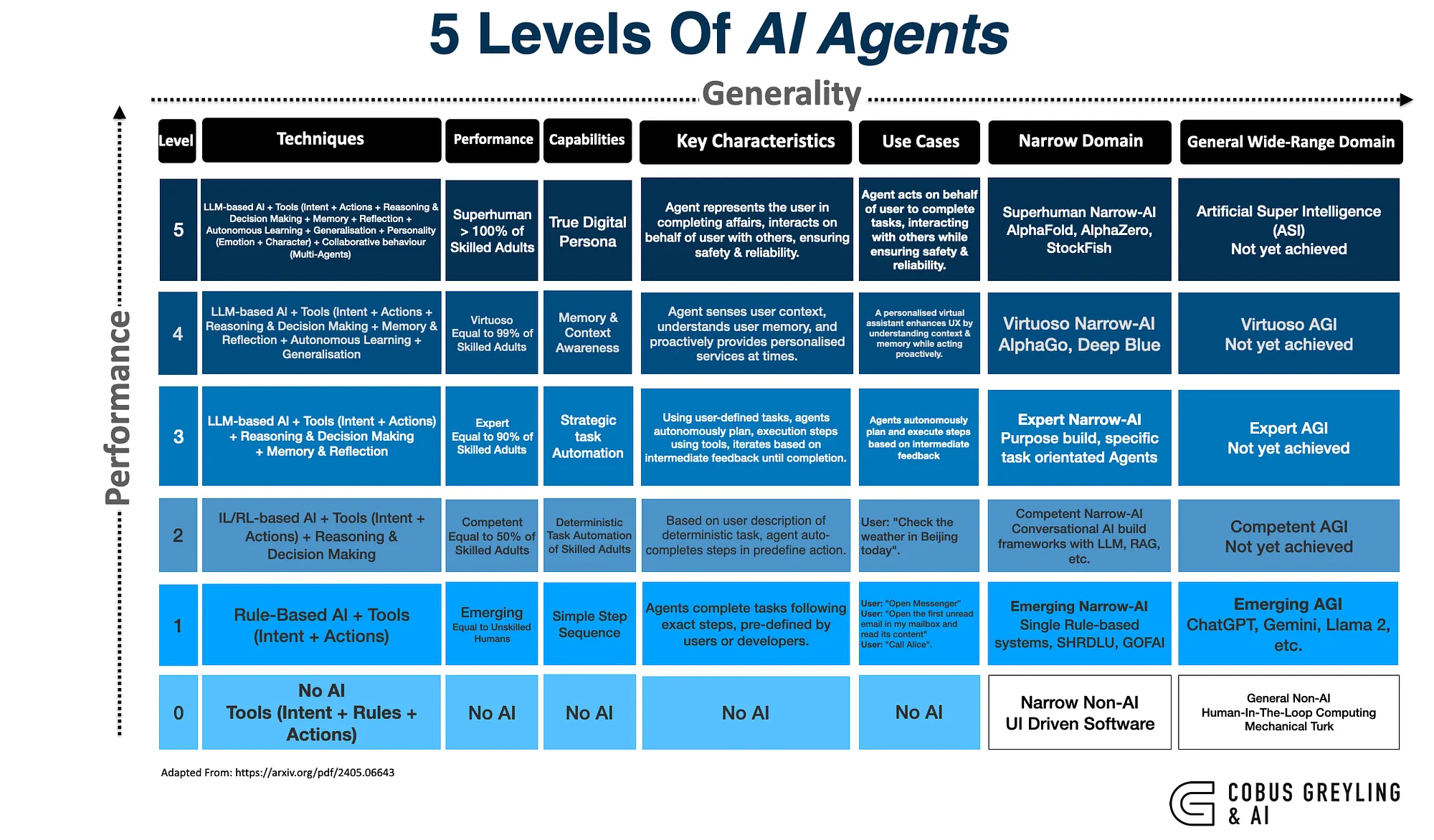
/Graph explaining the different levels of agents and their characteristics. From this article.
The 5 Levels of AI Agents
Most articles on agents seem to refer to the 5 or 6 levels of agentic capability, ranging from a simple rule-follower, to one who learns over time what to do and how best to do it. I see this list as a potential guide to the evolution of a particular agent over time.
(Here is a particularly good and clear article by a Computer Scientist about these Levels, called “Levels of AI Agents: from Rules to Large Language Models”).
We would tend to start off designing a very simple agent that can accomplish some basic decision making, then increase in complexity over time.
Simple reflex agents
A simple reflex agent operates strictly based on predefined rules and its immediate data. As a Genie, it could work through a process to store the relevant information about goals within each of the fields in the UI.
Model-based reflex agents
A model-based agent builds an internal model of the world it perceives and uses that to evaluate probable outcomes and consequences before deciding.
From the article above, based on the user’s description of a deterministic task, the agent auto-completes the steps in a pre-defined action space.
A Genie at this level could follow a set process to help the user elaborate any number of wishes.
Goal-based agents
Goal-based agents have more robust reasoning capabilities. The agent compares different approaches to help it achieve the desired outcome. Goal-based agents always choose the most efficient path.
From the article above, based on user-specified tasks, agents autonomously plan the execution steps Using various resources and tools and iterates the plan based on intermediate feedback until completion.
A goal-based Genie would consider its goal hierarchy, examine which is currently of highest priority given the existing manifestation data, probably look at the history of which “wishing processes” the user has done recently (e.g. affirmations, goal visualisation, obstacle analysis) and formulate and carry out a reasonably sophisticated plan as to the next appropriate action, checking in with the user at various points to determine which direction to go in with particular processes.
Utility-based agents
A utility-based agent uses a complex reasoning algorithm to help users maximize the outcome they desire. The agent compares different scenarios and their respective utility values or benefits. Then, it chooses one that provides users with the most rewards.
For a Genie, this might involve an analysis of the present state along with the goal-state for each wish, may possibly lead to forming its own conclusions about the main obstacles facing the user, and a proposal of the next best action, in terms of the processes the app can facilitate.
Learning agents
A learning agent continuously learns from previous experiences to improve its results. It can also use a problem generator to design new tasks to train itself from collected data and past results.
A learning Genie would have a way to learn about what approaches have worked for the user in the past, in terms of manifesting their desires, and examining what type of obstacles the user tends to face. It might then design a novel approach to helping the user close the gap between present and desired reality. It would also have a ‘dreaming’ process where it runs any new data and updates its concepts and processes.
Hierarchical agents
Hierarchical agents are an organized group of intelligent agents arranged in tiers. The higher-level agents deconstruct complex tasks into smaller ones and assign them to lower-level agents. Each agent runs independently and submits a progress report to its supervising agent. The higher-level agent collects the results and coordinates subordinate agents to ensure they collectively achieve goals.
A hierarchical Genie would involve sub-agents who specialised in different aspects of accomplishing goals, e.g. a psychology coach, a scheduling assistant, a project manager, etc. It would determine which was most appropriate at any given time, and manage switching between them to maximise the value to the user.
Agent Structure
Agents have 4 main capabilities.
Goal-seeking and planning: They can store goals and formulate strategies on the best ways to achieve these, planning steps between the current state and the desired state.
Interacting with tools: They can use tools, e.g. internet search, to accomplish these goals
Memory and external knowledge: Can access up-to-date information as well as consult their existing knowledge base.
Executing actions: Agents can then actually carry out the actions they have planned in order to get them closer to their goal-state.

The flow chart shows the flow of information between the user, an agent, it’s brain (the LLM), and the tools and memory it can access to help it accomplish its goals. Stolen from this cool video on How Ai Agents Work (Without getting too technical)
Starting out building an agent from scratch in Kotlin
To start with, I began implementing the Genie agent in its most fundamental form. For me, the foundation of this construction was getting my Android phone to recognise things that I was saying, and to be able to say things back to me.
The quickest path to achieving this was to simply use Google’s APIs for Speech to Text, and Text to Speech. While I expected this to be relatively straightforward, of course, it wasn’t! I might write a little about that journey elsewhere.
Agent Level 0: Building A Voice Controlled Reflex Agent in Android
After setting up some basic voice interactivity (which I celebrated as a major achievement), it was time to try to figure out the most atomic form of an agent. It seems the kind of agent I’m interested in building is slightly different to the ones that other people seem to be building out there on the web.
Is it an Ai agent or an Ai assistant?
So is the correct name for what I’m designing an agent, or assistant?
Let’s look at some definitions.
What is an Ai Agent?
Let’s look at that definition again.
That’s Google’s definition.
And IBM defines an agent as:
A system or program that can autonomously complete tasks on behalf of users or another system by designing its own workflow and by using available tools.
Think we get the idea. What about an Assistant then?
What is an Ai Assistant?
An Ai Assistant is an intelligent application that understands natural language commands and uses a conversational Ai Interface to complete tasks for a user. Ai Assistants have limitations. They cannot take action without defined prompts, though they can use tools in a limited way when equipped to do so.
To be honest, it sounds like an Ai Assistant is more like a Level 1 or Level 2 (Reflex Agent or Model-based Agent).
The distinction doesn’t seem useful to me.
For example, how would we class the Intelligent OS in the movie “Her”? I always come back to this is its such a great demonstration of what an intelligent system of the future will look like.
I firmly believe the next generation of Operating System will be based around a mixture of in depth, intelligent voice interaction and the generation of complex and multi-faceted supporting visual information by the OS.
If we visualise the next generation of ‘Ai agents’ or ‘Ai assistants,’ we envisage an entity that is able to interact with and understand their human, to go off and do tasks themselves, come back and check results, receive further input, and generally operate independently, while also maintaining a tight tether to their user’s needs and feedback.
In my mind, we should work towards building something that has the interactivity and helpfulness of an assistant, along with the reasoning, memory and action-oriented capabilities of an agent.

Hardwiring the “agent” as a pathway through a state machine
Core Architecture: The Conversation Agent
The heart of the system is the ConversationAgent class, which integrates several key capabilities:
class ConversationAgent(
private val repository: ManifestationRepository,
private val ttsRepo: TextToSpeechRepository,
private val statusService: StatusMessageService
)
In this simplistic v.1.0, our “Genie” has access to the wish database, our Text to Speech capability, and our Status Messaging Service, for debugging. Soon after initialisation, the Genie also obtains access to the Voice Recognition Repository, through a Voice-Managed View Model.
A Simple State-Machine
A state machine is a computer sciency way of modeling how something works, using states and transitions to show how something changes over time in response to events, formally modelling how a system transitions from one state to another based on specific events.
In our case, I hard-coded the different stages of the various conversations I wanted to be able to have with the agent.
Building the Foundation - A Voice-Controlled Agent
After exploring the theoretical landscape of AI agents, I began implementing the Genie, starting with a focused goal: creating an agent that could engage in voice conversation with users to collect and manage their wishes. The architecture that emerged combines elements of both simple reflex agents and model-based agents, with some interesting design choices around state management and voice interaction.
Core Architecture: The Conversation Agent
The heart of the system is the ConversationAgent class, which integrates several key capabilities:
class ConversationAgent(
private val repository: ManifestationRepository,
private val ttsRepo: TextToSpeechRepository,
private val brainService: BrainService,
private val scope: CoroutineScope,
private val statusService: StatusMessageService
)
This design gives our agent:
Data persistence through the repository
Voice output through text-to-speech
AI capabilities via Gemini
Asynchronous operation support
Status reporting for debugging
State Management: A Three-Layer Approach
One of the most interesting architectural decisions was implementing a three-layer state system that manages different aspects of the conversation:
- Conversation Type - The high-level context.
sealed class ConversationType {
object WishCollection : ConversationType()
object WishSelection : ConversationType()
}
- Conversation Step - I mapped each specific stage within a conversation:
sealed class ConversationStep {
sealed class WishStep : ConversationStep() {
object AskForWish : WishStep()
object CaptureWish : WishStep()
object CheckWish : WishStep()
object CaptureValidation : WishStep()
}
// Other step types...
}
- Dialogue State - The immediate interaction state:
sealed class DialogueState {
object Speaking : DialogueState()
data class ExpectingInput(val inputType: VoxInputType) : DialogueState()
object Idle : DialogueState()
}
This hierarchical state system allows the agent to:
Maintain context at multiple levels
Handle complex conversation flows
Manage timing between speaking and listening
Track progress through multi-step processes
// A typical sequence for wish collection might be:
ConversationStep.WishStep.AskForWish
↓
DialogueState.Speaking ("What is your first wish?")
↓
DialogueState.ExpectingInput(VoxInputType.FREEFORM)
↓
ConversationStep.WishStep.CaptureWish (when voice input received)
↓
ConversationStep.WishStep.CheckWish
↓
DialogueState.Speaking ("I've entered your wish as... is that ok?")
↓
DialogueState.ExpectingInput(VoxInputType.YES_NO)
↓
ConversationStep.WishStep.CaptureValidation (when yes/no received)
↓
(if yes) -> Store wish and return to checking manifestations
(if no) -> Return to AskForWish
Key aspects:
ConversationStep controls the logical flow - what phase we're in
DialogueState manages the immediate interaction state - whether we're speaking or listening
VoxInputType tells us what kind of input we're expecting - free text or yes/no
I also had to hardcode quite a lot of implementation details to stop the agent listening to the things it would say, and interpreting them as inputs, thereby creating all sorts of weird feedback loops.
Transitions between states were managed by functions that were called at each stage of a conversation, once the previous stage had been completed. The conversational sequence is therefore very constrained and highly specific. No room for answers outside of what is expected. This is because the agent doesn’t at this point ‘understand’ language in any way. There isn’t the interpretation that would be possible from using an LLM. It simply processes strings with no context at all, other than what is required to shift from state to state.
State transitions were managed by functions like:
private suspend fun proceedToNextWishStep(step: ConversationStep.WishStep) {
updateCurrentStep(step)
when (step) {
is ConversationStep.WishStep.AskForWish -> {
askForWish()
}
is ConversationStep.WishStep.CaptureWish -> {
updateDialogueState(DialogueState.ExpectingInput(VoxInputType.FREEFORM))
}
// etc.
}
}
When voice input is received, it's processed according to both the Dialogue state (which tells us we should be listening rather than speaking), and the ConversationStep state variable (which tells us where we are in the conversation)
when (dialogueState.value) {
is DialogueState.ExpectingInput -> {
// What we do with the input depends on currentStep
if (currentStep == ConversationStep.WishStep.CaptureWish) {
captureWish(text)
}
if (currentStep == ConversationStep.WishStep.CaptureValidation) {
validateWish(resolveYesNo(text))
}
}
is DialogueState.Speaking -> {
// Ignore input while speaking
}
// etc.
}
This dual state system allows the agent to:
Keep track of the overall conversation flow (steps)
Manage immediate interaction timing (dialogue)
Know what kind of input to expect
Process input in the correct context
The separation also makes it easier to:
Add new conversation flows
Modify input validation
Debug conversation issues
Test different components
Agent “Memory”
The agent maintains both an extremely primitive “working memory”, whereas the app proper is used for what you could call “persistent storage.”
// Working Memory
private var currentConversation: ConversationType? = null
private var currentStep: ConversationStep? = null
private val currentWishIndex = MutableStateFlow<Int>(0)
private var tempWishResponse: String? = null
private var selectedManifestationId: Int? = null
private var lastSpeechEndTime: Long = 0L
// Persistent Storage
// Handled through ManifestationRepository
This dual-memory system allows the agent to:
Hold temporary conversation context
Track timing between interactions
Store permanent wish data
Maintain conversation progress
Voice Interaction Integration
Rather than building voice recognition directly into the agent, the system separates concerns:
Voice input is handled by a separate VoiceManagedViewModel
Text-to-speech output is managed through a dedicated repository
The agent coordinates between these systems while focusing on conversation logic
This separation allows for:
Clean management of voice I/O timing
Clear responsibility boundaries
Easier testing and modification
Future enhancement of either voice input or output

Reflections on Building a Primitive Structured Reflex Agent
I used to love playing Monkey Island. The number of different permutations of how the game would go was at first mind-bending, but then as I got to know the game, racking up hundreds of hours on the thing, I started to see how limited the potential number of permutations were.
The programmers of that excellent, but now incredibly primitive game, had to write every single possible variation of every single conversation, much like I had to do with this first version of the Genie.
The use of sealed classes, as shown above, make this a very 1990s way of writing an agent, and there’s definitely no intelligence at play, artificial or otherwise.
Looking Forward
This foundation is particularly interesting because it separates conversation logic from both voice I/O and data storage while maintaining clear interfaces between these components. This architecture supports future evolution toward:
More complex dialogue patterns
Integration of AI-driven decision making
Enhanced context awareness
Learning from interaction history
In the next stage of development, we'll explore the process of giving the agent ‘a brain’ - and managing the process of communicating back and forth between the app and an LLM!
Subscribe to my newsletter
Read articles from Richard Thompson directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Richard Thompson
Richard Thompson
Spending a year and a half re-educating myself as a Cognitive Scientist / Ai Engineer.