What is Incident Response Management?
 Rajni Rethesh
Rajni RetheshTable of contents
- What Is Incident Response Management
- Why Is Incident Response Management Crucial in DevOps?
- How Does Incident Response Management Fit into DevOps?
- Challenges in Incident Response Management: Tackling the Tough Stuff
- How Middleware Handles Incident Response?
- Why Middleware Stands Out in Incident Response?
- Final thoughts: Incident Response is the Backbone of DevOps
- FAQs

Let’s take this scenario: your e-commerce app is hosting a Black Friday sale. Thousands of customers are adding items to their carts when, suddenly, the app crashes. Panic sets in. The clock is ticking, revenue is draining, and your customer support is lighting up with complaints. How you respond to this scenario determines whether your team is hailed as heroes or left scrambling in damage control mode. This is where Incident Response Management steps in to save the day.
What Is Incident Response Management
Incident Response Management is a structured approach to detecting, managing, and resolving unplanned events (incidents) that disrupt normal operations.
Why Is Incident Response Management Crucial in DevOps?
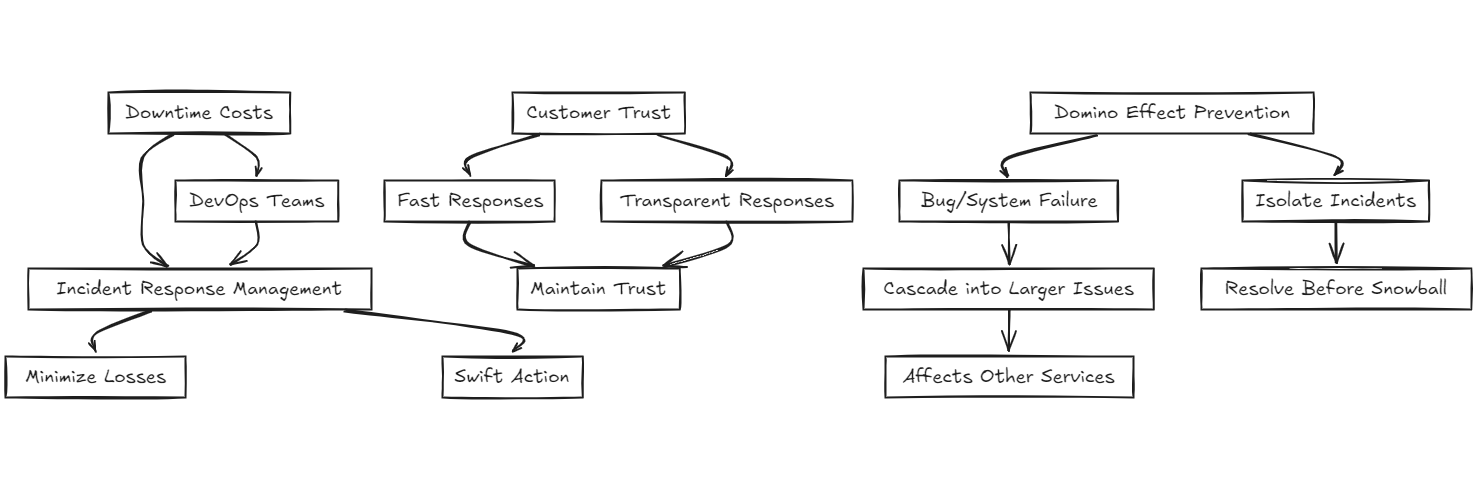
Downtime Costs a Fortune
A report by Gartner estimated that downtime costs businesses an average of $300,000 per hour. For DevOps teams managing critical services, the stakes are high. Effective Incident Response Management ensures you’re minimizing losses by acting swiftly.
Customer Trust is Fragile
In a world where a single tweet can tarnish your brand, fast and transparent incident responses are key to maintaining customer trust
Preventing a Domino Effect
In DevOps, a single bug or system failure can cascade into larger issues, affecting other services. IRM ensures that incidents are isolated and resolved before they snowball.
How Does Incident Response Management Fit into DevOps?
DevOps thrives on collaboration, automation, and continuous improvement. Incident Response Management complements this by fostering:
Proactive Monitoring: Tools like PagerDuty and Datadog enable teams to identify incidents early.
Streamlined Communication: With real-time alerts and escalation protocols, DevOps teams know who’s responsible for what.
Continuous Feedback Loops: Post-incident reviews feed back into the development cycle, helping to prevent similar issues in the future.
Also read: Measuring Open DevOps Success with Dora Metrics
Key Steps in Incident Response Management
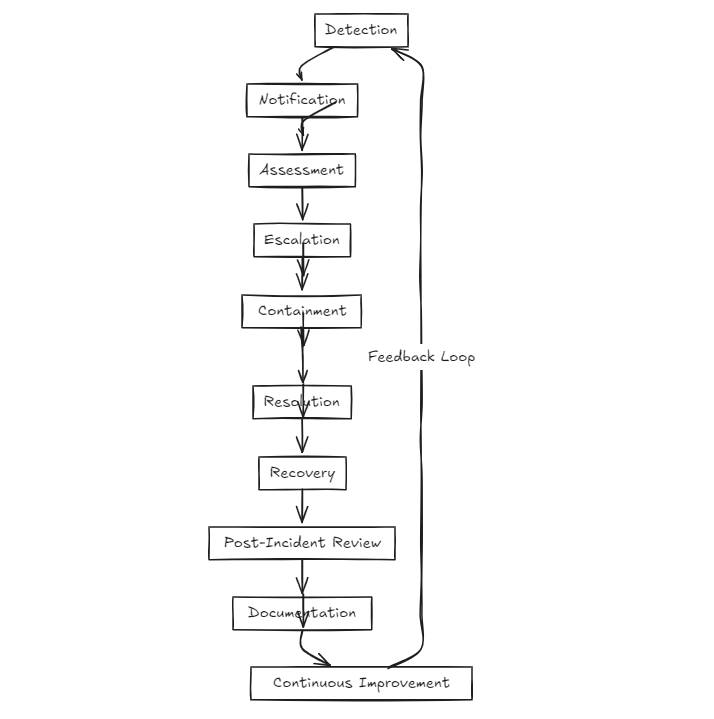
Detection
Identify incidents as early as possible using monitoring tools like Datadog, Prometheus, or New Relic. For example, a spike in error rates in your API endpoints might signal an issue.
Notification
Automate alerts to notify the on-call team. Tools like PagerDuty send notifications via SMS, email, or Slack, ensuring no one misses the call.
Assessment
Classify incidents by severity: Is it a minor bug, or is it a production outage affecting users? This helps prioritize responses.
Escalation
If the first responder can’t resolve the issue, escalation protocols kick in, notifying the next level of expertise.
Containment
Implement quick fixes to stop the incident from escalating. For example, roll back a faulty deployment or reroute traffic to a backup server.
Resolution
Dive into root cause analysis, debug the issue, and deploy a permanent fix.
Recovery
Bring affected systems back to full functionality and validate that everything is working as expected.
Post-Incident Review
Analyze what went wrong, what went right, and how to improve. Tools like MiddlewareHQ can provide metrics like MTTR (Mean Time to Recovery) for insights.
Documentation
Record every detail of the incident and response. This creates a valuable knowledge base for future reference.
Continuous Improvement
Use the lessons learned to optimize processes and tools, making your system more resilient. For instance, Netflix practices proactive incident response with its Chaos Monkey tool, which deliberately introduces failures into systems to test their resilience. By simulating incidents, Netflix ensures that its teams are always prepared, and its systems are fault-tolerant. This approach aligns perfectly with the DevOps mantra of continuous improvement.
Challenges in Incident Response Management: Tackling the Tough Stuff
Incident Response Management is no walk in the park. While it’s critical for ensuring system reliability and maintaining user trust, it comes with its own set of challenges that can overwhelm even the most seasoned DevOps teams. Let’s explore the three common hurdles and how to overcome them.
1. Alert Fatigue: The Cry-Wolf Syndrome

The Problem
Imagine your phone buzzing every five minutes with alerts, from a minor server hiccup to a critical production outage. It doesn’t take long before your brain tunes out the noise, treating every alert with the same urgency—or worse, ignoring them altogether. This phenomenon, known as alert fatigue, can leave critical issues unnoticed and unresolved.
Why It Happens
Overly sensitive monitoring systems that generate false positives.
Poorly configured alert thresholds that flag every minor deviation.
Lack of prioritization, leading to the same level of urgency for all alerts.
The Fix
Intelligent Alerting: Use tools like PagerDuty to prioritize alerts based on severity and impact. For instance, an alert for a database server crash should take precedence over a minor CPU usage spike.
Noise Reduction: Set up filters to suppress low-priority alerts or batch similar ones together.
On-Call Rotations: Rotate responsibilities among team members to prevent burnout and ensure fresh eyes on incoming alerts.
2. Inculcating Blameless Culture: From Finger-Pointing to Problem-Solving

The Problem
When an incident occurs, it’s tempting to point fingers at others and blame them. While this might provide temporary satisfaction, it undermines team morale and discourages transparency. Team members may start hiding mistakes or avoid taking risks—both of which stifle growth and innovation.
Why It Happens
High-pressure environments that prioritize results over learning
Lack of trust within the team, leading to defensive behavior
Leadership styles that focus on punishment rather than solutions
The Fix
Blameless Postmortems: Analyze incidents objectively, focusing on the root cause rather than who was responsible. Use questions like “What went wrong?” and “How can we prevent it?” instead of “Who messed up?” Better, use tools like Middleware that gives you an holistic insight into each aspect of your project, on individual as well as organizational level.
Celebrate Transparency: Encourage team members to report issues as soon as they occur, without fear of retribution.
Leadership by Example: Leaders should model a growth mindset, emphasizing learning over punishment.
3. Tool Overload: Too Many Tools, Too Little Time

The Problem
The modern DevOps landscape is brimming with specialized tools for monitoring, alerting, ticketing, and collaboration. While these tools are invaluable, juggling multiple platforms can lead to inefficiencies, miscommunications, and missed updates. Teams may find themselves spending more time managing tools than resolving incidents.
Why It Happens
Lack of integration between tools, leading to silos of information
Poorly defined processes for how and when to use each tool
Over-reliance on tools as a substitute for clear communication
The Fix
Consolidation: Choose tools that offer comprehensive functionality or integrate seamlessly. For instance, Middleware integrates with PagerDuty, Slack, and Jira, centralizing incident management in one place.
Streamlined Workflows: Define clear processes for how tools should be used, from alert escalation to incident tracking and postmortem documentation.
Regular Audits: Periodically review your toolset to identify redundancies and ensure all tools are adding value.
How Middleware Handles Incident Response?
Middleware goes beyond traditional incident management by empowering engineering teams with data-driven insights, seamless integrations, and actionable metrics. Here's how Middleware simplifies and enhances the incident response process for DevOps teams:
1. Proactive Incident Data Ingestion
Middleware continuously collects and consolidates incident data from monitoring tools and platforms like PagerDuty. By centralizing data, it provides a unified view of all incidents across your systems, ensuring that nothing slips through the cracks.
Suppose a critical alert is triggered in PagerDuty. In that case, Middleware automatically pulls the incident details, including timestamps, affected services, and assigned responders, making it easy for teams to assess the situation quickly.
2. Intelligent Data Synchronization
Middleware ensures your incident data is always up to date by syncing with platforms in real-time. It organizes this data into categories like severity, impact, and resolution status, enabling faster decision-making.
This eliminates manual updates and ensures all stakeholders have access to accurate information during incident resolution.
3. Advanced Metrics for Incident Performance
Middleware provides detailed metrics to help teams measure their incident response performance. Key metrics include:
Change Failure Rate (CFR): Tracks the percentage of changes causing incidents.
Mean Time to Recovery (MTTR): Measures how quickly incidents are resolved.
Incident Frequency: Highlights recurring issues to pinpoint systemic weaknesses.
Teams can identify patterns, such as a high CFR following deployments, and adjust their CI/CD pipeline accordingly.
4. Actionable Insights Through Data Transformation
Middleware transforms raw incident data into meaningful insights. By analyzing the root causes and contributing factors, teams can focus on preventing future incidents rather than just resolving the current one.
Use Case:
If multiple incidents stem from a specific microservice, Middleware’s insights enable teams to prioritize that service for fixes or redesigns.
5. Real-Time Reporting and Visualization
Middleware offers visually intuitive dashboards that showcase incident trends, team performance, and areas for improvement. Teams can easily filter by time, severity, or service to uncover actionable insights.
6. Blameless Incident Analysis
Middleware emphasizes a blameless culture by providing objective post-incident analysis. It captures details like timelines, actions taken, and outcomes, helping teams learn without finger-pointing.
A retrospective report from Middleware tool might reveal that slow recovery times are due to unclear escalation policies, prompting teams to refine their response process.
7. Continuous Improvement Through Feedback Loops
Middleware helps teams turn every incident into an opportunity for improvement. Insights from post-incident reviews feed back into the development and deployment cycle, ensuring that similar issues are avoided in the future.
If an incident review reveals frequent failures during peak traffic, Middleware’s recommendations can help teams optimize load balancing and scalability strategies.
Why Middleware Stands Out in Incident Response?
Middleware doesn’t just help resolve incidents—it makes your team better at handling them. By combining advanced analytics, real-time data synchronization, and seamless integrations, it equips DevOps teams with the tools they need to minimize downtime, improve performance, and foster a culture of resilience.
If you’re looking to transform your incident response strategy, Middleware is the partner you need. With its robust features and focus on actionable insights, Middleware ensures your engineering team is always prepared for the unexpected.
Final thoughts: Incident Response is the Backbone of DevOps
In DevOps, speed and reliability are non-negotiable. Incident Response Management ensures that systems remain stable, teams stay focused, and customers stay happy. Whether you’re a small startup or an enterprise giant, having a solid Incident Response Management strategy isn’t optional—it’s essential.
Looking to enhance your incident response strategy? Middleware has you covered. With advanced analytics, seamless integrations with PagerDuty, and actionable insights, Middleware transforms the way you manage incidents. From reducing alert fatigue to improving MTTR, Middleware equips your team with the tools they need to handle incidents like pros.
FAQs
1. What are the 5 steps to incident response?
The 5 key steps to effective incident response are:
Preparation: Establish policies, procedures, and tools for responding to incidents.
Detection and Analysis: Identify potential incidents, analyze the scope, and confirm them.
Containment: Isolate the threat to prevent further damage.
Eradication: Remove the root cause of the incident and any residual threats.
Recovery: Restore affected systems and verify they’re functioning as expected.
2. What are the 7 steps in incident response?
The 7-step approach expands on the 5-step framework:
Preparation: Build your incident response plan and train your team.
Identification: Detect and validate the incident.
Containment (Short-Term): Limit immediate damage.
Containment (Long-Term): Create sustainable containment strategies.
Eradication: Eliminate the source of the incident.
Recovery: Reinstate normal operations.
Lessons Learned: Conduct a post-mortem to identify gaps and improve future responses.
3. What is an incident response in incident management?
Incident response is a subset of incident management. It focuses specifically on the detection, containment, and resolution of an incident to minimize its impact. It’s all about taking swift and organized action to address the issue and restore normalcy while gathering insights to prevent future occurrences.
4. What are the 5 stages of the incident management process?
The 5 stages of incident management are:
Incident Identification: Recognize and report the incident.
Logging and Categorization: Document details and classify the incident by priority and type.
Initial Diagnosis: Investigate to determine the root cause.
Resolution and Recovery: Address the issue and restore services.
Closure: Confirm the incident is resolved, communicate with stakeholders, and document the process.
Subscribe to my newsletter
Read articles from Rajni Rethesh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rajni Rethesh
Rajni Rethesh
I'm a senior technical content writer with a knack for writing just about anything, but right now, I'm all about technical writing. I've been cranking out IT articles for the past decade, so I know my stuff. When I'm not geeking out over tech, you can catch me turning everyday folks into fictional characters or getting lost in a good book in my little fantasy bubble.