Mastering Data Quality in ETL Pipelines with Great Expectations
 Anuj Syal
Anuj Syal
In the world of data engineering, ensuring data quality is paramount. From business analysts relying on dashboards to C-level executives making strategic decisions, and data scientists training machine learning models — everyone depends on the quality of the data. If the data is flawed, the insights and decisions drawn from it are equally flawed.
This is where Great Expectations (GX) comes into play. Built on Python, Great Expectations is a powerful open-source data validation and quality framework that helps ensure data is clean, accurate, and ready for use. This blog will guide you through the why and how of data quality, the Great Expectations workflow, and a hands-on tutorial for implementation.
Why Data Quality Matters
When building ETL pipelines, your end goal is to deliver clean, validated data. This data could be used as:
Business Intelligence Reports for business analysts.
Executive Dashboards for decision-makers.
Training Datasets for machine learning models.
If your data contains nulls, duplicates, incorrect formats, or misaligned schema, it undermines every stakeholder's effort. Data scientists can't build accurate models, analysts can't trust insights, and executives risk making bad decisions.
For data engineers, this makes data quality a moral and technical responsibility. It ensures that the hours spent building complex pipelines don't go to waste due to unreliable data.
Enter Great Expectations
![]()
Great Expectations (GX) aims to make data quality checks declarative, automated, and shareable. With GX, you can define “expectations” for your data, which are essentially quality rules, such as:
Ensuring no null values exist in critical columns.
Validating specific column values (like
countryonly having "US", "IN", "UK").Checking for minimum, maximum, and unique constraints on data.
The framework integrates with most data sources like databases, cloud storage (S3, GCS), Pandas, and Spark DataFrames. It provides easy-to-share data quality reports that can be shared with business users, creating transparency and clarity on what data passed/failed quality checks.
How Does the Great Expectations Workflow Look?
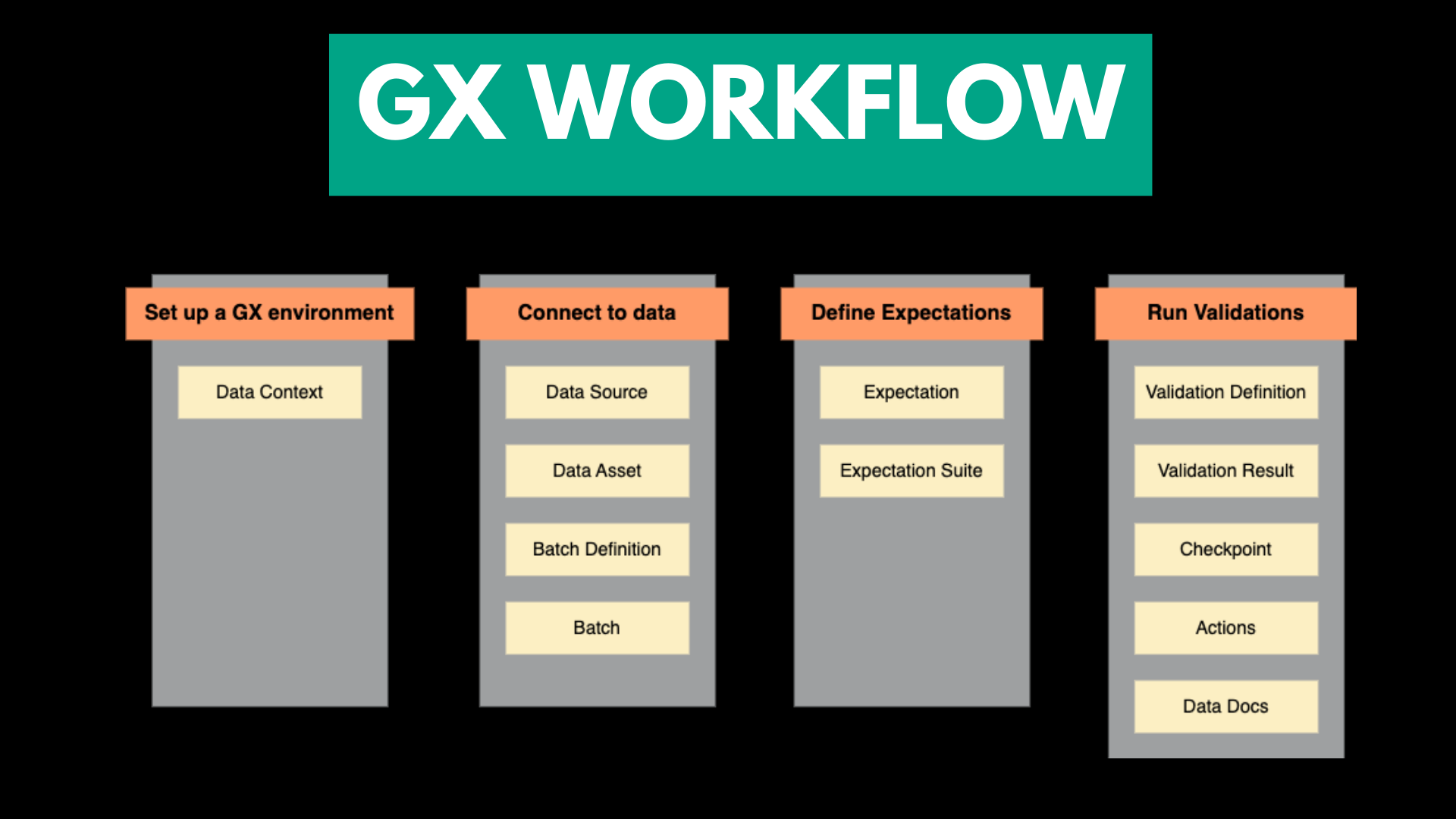
A typical Great Expectations workflow has 4 key steps:
Environment Setup: Define the context to track your data sources and validation logic.
Data Connection: Connect to databases, data warehouses, object storage, or files.
Expectation Suite Definition: Specify the quality checks (null checks, range checks, etc.).
Validation & Reports: Run validation on the data and generate shareable reports.
These steps map perfectly into a data engineer's workflow. If you think about an ETL pipeline, Great Expectations fits into the Extract, Transform, and Load (ETL) cycle.
During Extraction: Check for nulls, data formats, or schema inconsistencies.
During Transformation: Verify data quality after transformations (e.g., after joining datasets).
Before Loading: Final validation before pushing to a warehouse like BigQuery, Snowflake, or Redshift.
Great Expectations Product Offerings
Great Expectations offers two core products:
GX Core: The open-source version (focus of this blog).
GX Cloud: A managed cloud version with a GUI for managing expectations and validation reports.
In this guide, we'll focus on GX Core.
Deep Dive into the Great Expectations Workflow
1. Environment Setup
The first step is to create a Great Expectations context. The context tracks your data sources, expectation suites, and batch definitions. It works like a "brain" for your project, keeping all metadata in one place.
import great_expectations as gx
print(gx.__version__)
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "<service_account_key_path"
The demo covers using Google Cloud for data storage and retrieval, therefore we also have to authenticate GCP access using a service account
2. Define a Data Source
After the context is set, you need to connect your data source. This can be a local CSV, GCS/S3 file, DataFrame, or even a connection to a PostgreSQL, BigQuery, or Snowflake database.
Here’s how you can connect a CSV from a Google Cloud Storage (GCS) bucket:
data_source_name = "flights_data_source"
bucket_or_name = "flights-dataset-yt-tutorial"
gcs_options = {}
data_source = context.data_sources.add_pandas_gcs(
name="flights_data_source", bucket_or_name="flights-dataset-yt-tutorial", gcs_options=gcs_options
)
This sample data was already placed in google cloud storage, and the in-built connector from great_expectations is used to fetch this data.
3. Define Data Asset
A Data Asset is a specific file, table, or logical grouping of data from the source.
data_source = context.data_sources.add_pandas_gcs(
name="flights_data_source",
bucket_or_name="flights-dataset-yt-tutorial",
gcs_options={}
)
4. Define a Batch Definition
A Batch Definition defines which subset of the data (like rows or partitions) should be used for validation. This makes sense to use when you are working on a bigger project/database. You can define the batches of rows that needs to be tested in a certain way. For example, datasets coming from different countries would be subjected to different validations thus requiring multiple batches.
In our case to keep things simple we just have one big batch which is same as the data asset
batch_definition_name = "goibibo_flights_data_whole"
batch_definition_path = "goibibo_flights_data.csv"
batch_definition = data_asset.add_batch_definition(
name=batch_definition_name
)
batch = batch_definition.get_batch()
print(batch.head())
5. Define a Batch Definition
Now that the data is connected with batch defined, you define a list of data quality checks (expectations). This is done via an Expectation Suite, a collection of checks.
suite = context.suites.add(
gx.ExpectationSuite(name="flight_expectation_suite")
)
expectation1 = gx.expectations.ExpectColumnValuesToNotBeNull(column="airline")
expectation2 = gx.expectations.ExpectColumnDistinctValuesToBeInSet(
column="class",
value_set=['economy','business']
)
suite.add_expectation(expectation=expectation1)
suite.add_expectation(expectation=expectation2)
This defines two expectations:
expectation1: Column
airlineshould not be NULLexpectation2: Column
classcan only contain two values ['economy','business']
You can create as many expectations as you want, each covering a specific data quality rule.
6. Validation and Run
Once you’ve defined expectations, you must run validation to see if the data passes. Validation runs the expectations on batches of data and returns results (pass/fail) as shareable documentation.
# define `Validation Definition`: A Validation Definition is a fixed reference that links a Batch of data to an Expectation Suite.
validation_definition = gx.ValidationDefinition(
data=batch_definition, suite=suite, name='flight_batch_definition'
)
validation_definition = context.validation_definitions.add(validation_definition)
validation_results = validation_definition.run()
print(validation_results)
# %%
# Create a Checkpoint with Actions for multiple validation_definition
validation_definitions = [
validation_definition # can be multiple definitions
]
# Create a list of Actions for the Checkpoint to perform
action_list = [
# This Action sends a Slack Notification if an Expectation fails.
gx.checkpoint.SlackNotificationAction(
name="send_slack_notification_on_failed_expectations",
slack_token="${validation_notification_slack_webhook}",
slack_channel="${validation_notification_slack_channel}",
notify_on="failure",
show_failed_expectations=True,
),
# This Action updates the Data Docs static website with the Validation
# Results after the Checkpoint is run.
gx.checkpoint.UpdateDataDocsAction(
name="update_all_data_docs",
),
]
checkpoint = gx.Checkpoint(
name="flight_checkpoint",
validation_definitions=validation_definitions,
actions=action_list,
result_format={"result_format": "COMPLETE"},
)
context.checkpoints.add(checkpoint)
# %%
# Run checkpoint
validation_results = checkpoint.run()
print(validation_results)
The validation result tells you:
Which expectations passed/failed.
How many records failed.
JSON reports that can be shared with business teams
Reporting & Alerts
One of the most powerful features of Great Expectations is reporting and alerting. After a validation run, you can:
Email the reports to business users.
Log failures for debugging.
Trigger alerts via Slack or other services.
# Create a list of Actions for the Checkpoint to perform
action_list = [
# This Action sends a Slack Notification if an Expectation fails.
gx.checkpoint.SlackNotificationAction(
name="send_slack_notification_on_failed_expectations",
slack_token="${validation_notification_slack_webhook}",
slack_channel="${validation_notification_slack_channel}",
notify_on="failure",
show_failed_expectations=True,
),
# This Action updates the Data Docs static website with the Validation
# Results after the Checkpoint is run.
gx.checkpoint.UpdateDataDocsAction(
name="update_all_data_docs",
),
]
checkpoint = gx.Checkpoint(
name="flight_checkpoint",
validation_definitions=validation_definitions,
actions=action_list,
result_format={"result_format": "COMPLETE"},
)
context.checkpoints.add(checkpoint)
Built-in Expectations
Great Expectations provides a library of built-in expectations. Examples include:
Null checks: Ensure no nulls exist in a column.
Range checks: Check if column values lie within a range.
Data type checks: Ensure a column is of type integer, float, etc.
Uniqueness checks: Verify column values are unique.
You can see the full list of built-in expectations on the official Expectation Gallery.
Conclusion
If you're a data engineer, implementing Great Expectations in your ETL pipelines is a game-changer. The power to automate, validate, and report on data quality is something every data-driven company needs. Great Expectations makes this process automated, reproducible, and shareable.
Use GX in your ETL pipelines to validate extracted and transformed data.
Ensure transparency with quality reports that business teams can understand.
Automate alerts and logging to notify when data fails checks.
References
Full source code on my GitHub
Subscribe to my newsletter
Read articles from Anuj Syal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Anuj Syal
Anuj Syal
I am a Data Engineer I love Python! I am based in Singapore I have good knowledge on cloud I have some knowledge on building Machine Learning Models I have helped 30+ companies use data effectively I have worked with Petabytes scale of data I write @ TowardsDataScience Nowadays I am focusing on learning Natural Language Processing Ask me about anything, I'll be happy to help.