BugBounty
 FIKARA BILAL
FIKARA BILAL
Collecte d’informations
Dans un contexte de BugBounty ou de test de sécurité, la collecte d’informations est une étape qui consiste à recueillir un maximun de données sur une cible. Le but est de mieux comprendre son environnement et surtout identifier des vulnérabilités potentielles. Elle utilise des techniques variées dont certaines seront détaillées par la suite.
Google Dorking
Le Google Dork est une technique de recherche qui utilise des requêtes avancées afin de trouver des informations sensibles, non accessibles via une recherche Google standard. Cela permet d’affiner la recherche pour découvrir des pages web, des fichiers et d’autres données cachées.
Options
<keyword> site: www.website.com filetype:pdfsite:effectue la recherche du keyword seulement sur le site spécifié.filetype:recherche un type de fichiers spécifiques, ici les pdf.
intitle:<keyword> inurl:<keyword> cache:<keyword>intitle:recherche des pages web dont le titre contient le mot spécifiéinurl:recherche les pages web dont l’URL contient le mot spécifié. Cette technique permet de retrouver des pages spécifiques, des répertoires ou des fichiers qui incluent le mot-clé.cache:permet d’afficher la version en cache d’une page web. C’est à dire elle affiche une copie sauvegardée par un moteur de recherche.Elle est souvent utilisée pour afficher une page qui a été supprimée, mais toujours visible dans le cache du moteur de recherche. Ou encore voir comment un site apparaissaît avant des modifications majeures.
Sur l’image ci-dessous, on peut voir que la recherche retourne juste des fichiers PDF qui ont le terme "bug bounty" dans le titre.
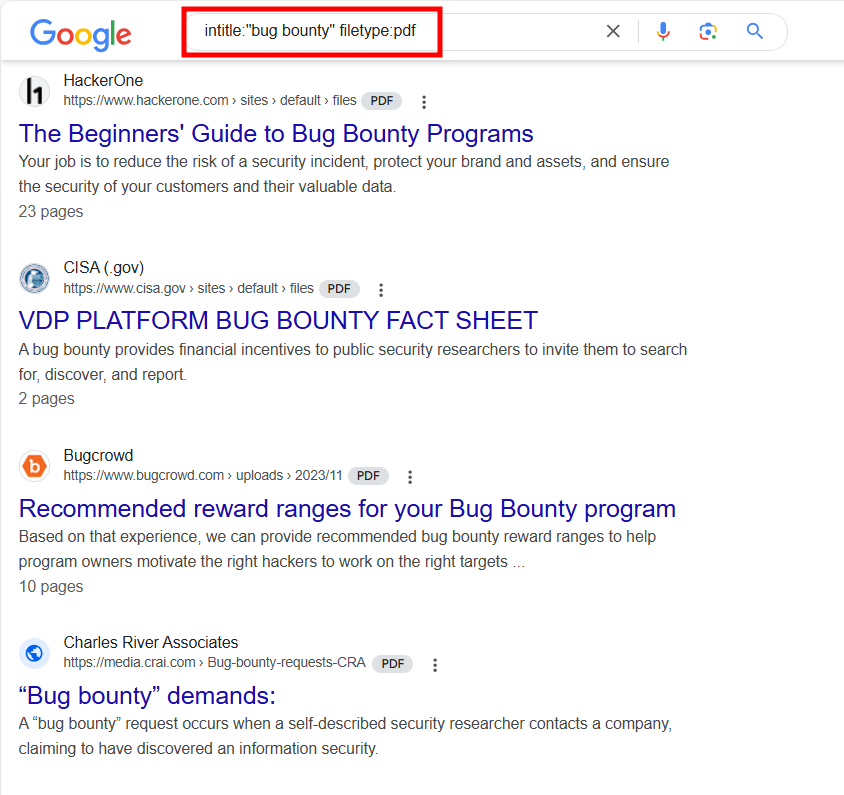
On peut utiliser des Google Dorks pour des informations plus sensibles.
intitle:"index of" "server-status" site:www.website.com: cette requête recherche des pages sur le site dont le titre contient ”index of ” et “server-status“. Cela peut permettre d’avoir des informations sur le serveur ou des pages de statut de serveur."public" "key" filetype:pem site:www.website.com: pour rechercher des fichiers de type PEM sur le site contenant les mots “public" et “key". Ces fichiers sont souvent utilisés pour stocker des clés pour la cryptographie. On pourrait donc potentiellement retrouve des clés publiques exposées.
Les Google Dorks peuvent être des moyens efficaces pour identifier des vulnérabilités sur un système. Il existe aussi des fichiers et des listes disponibles sur Internet contenant des google Dorks pour diverses recherches.
Bug Bounty Search Engine
BugBountySearchEngine est un moteur de recherche qui regroupe plusieurs moyens de rechercher des vulnérabilitées et des informations sensibles sur des domaines. Il offre des options pour trouver des fichiers de configuration ou de sauvegarde, des bases de données exposées, des sous-domaines et bien d’autres. On peut aussi y rechercher des données spécifiques sur des des sources publiques comme Github, Shodan, Censys et d’autres.
L’outil est disponible ici.
Pour l’utiliser, entrez un domaine cible dans l’interface. Sélectionnez ensuite l’une des recherches prédéfinies en fonction des types d’informations que vous souhaitez obtenir.
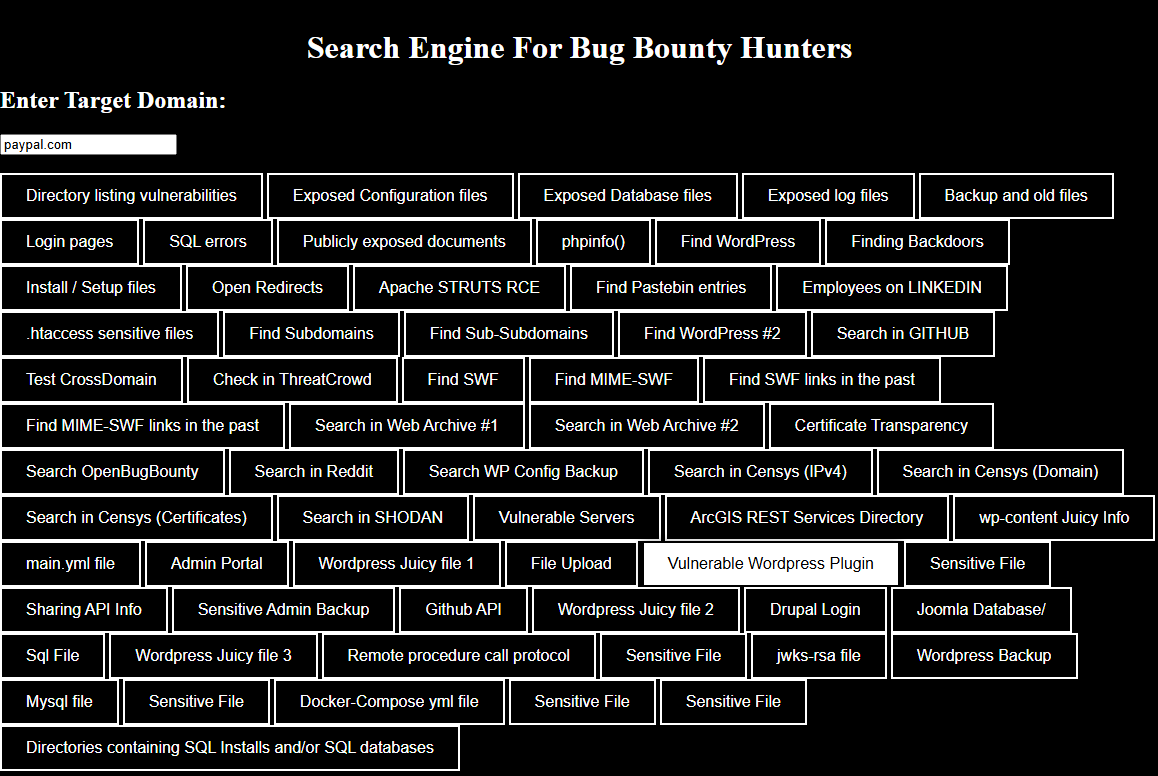
Github Recon
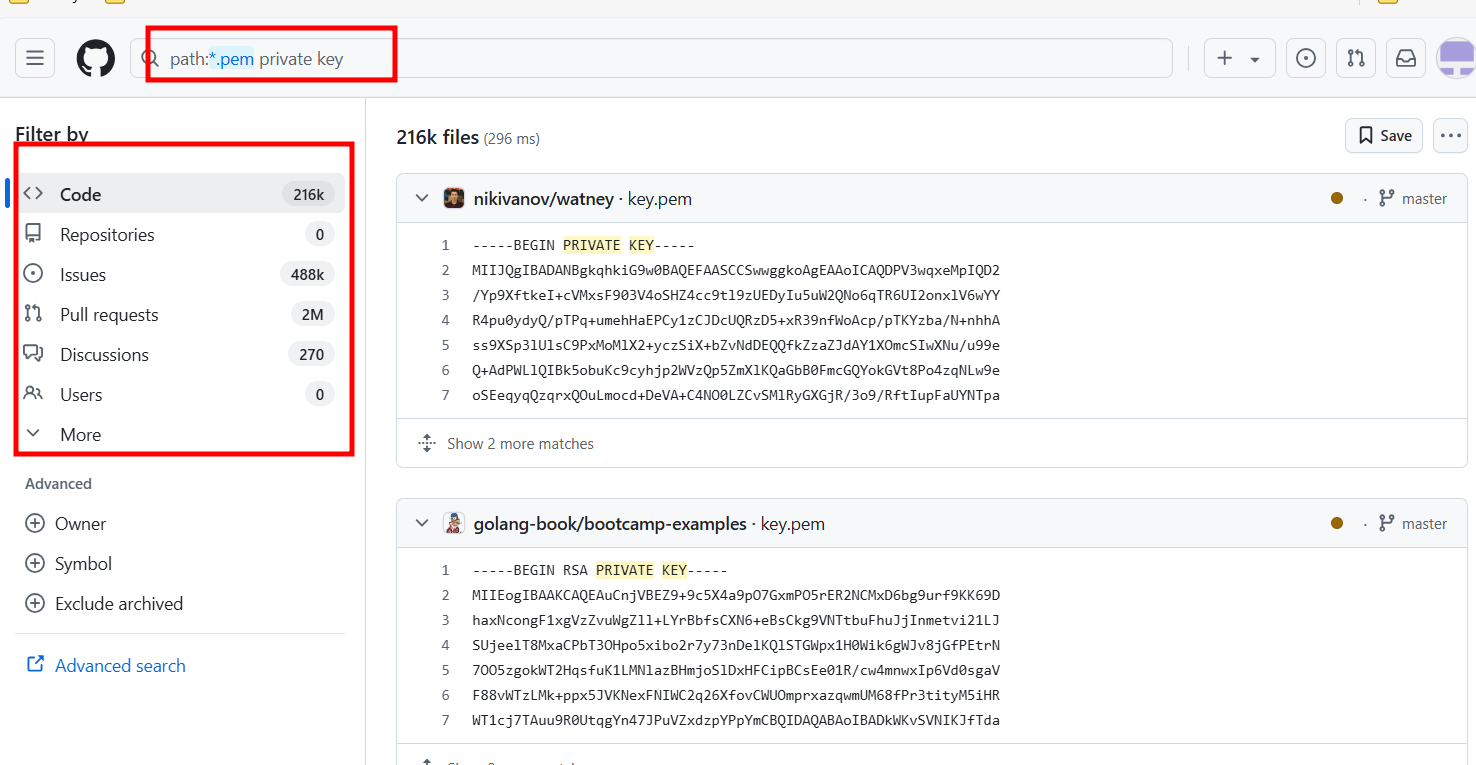
Le Github Recon est une technique utilisée pour rechercher des informations sur des projets, des organisations ou même des individus en explorant les dépôts sur Gihub. Elle consiste à analyser l’historique des commits, surveiller les activités dans le but de découvrir des informations sensibles. Vous pouvez aussi utiliser les Github Dorks pour affiner les recherches. Il est parfois possible que les développeurs oublient ou laissent des informations sensibles comme des clé APIs, des mots de passe par défaut et d’autres.
Dans la barre de recherhce, il suffit d’inscrire les dorks ou les requêtes souhaitées. Il faut ensuite examiner les codes, les commits et les branches afin d’y recueillir des informations qui pourraient être utiles.
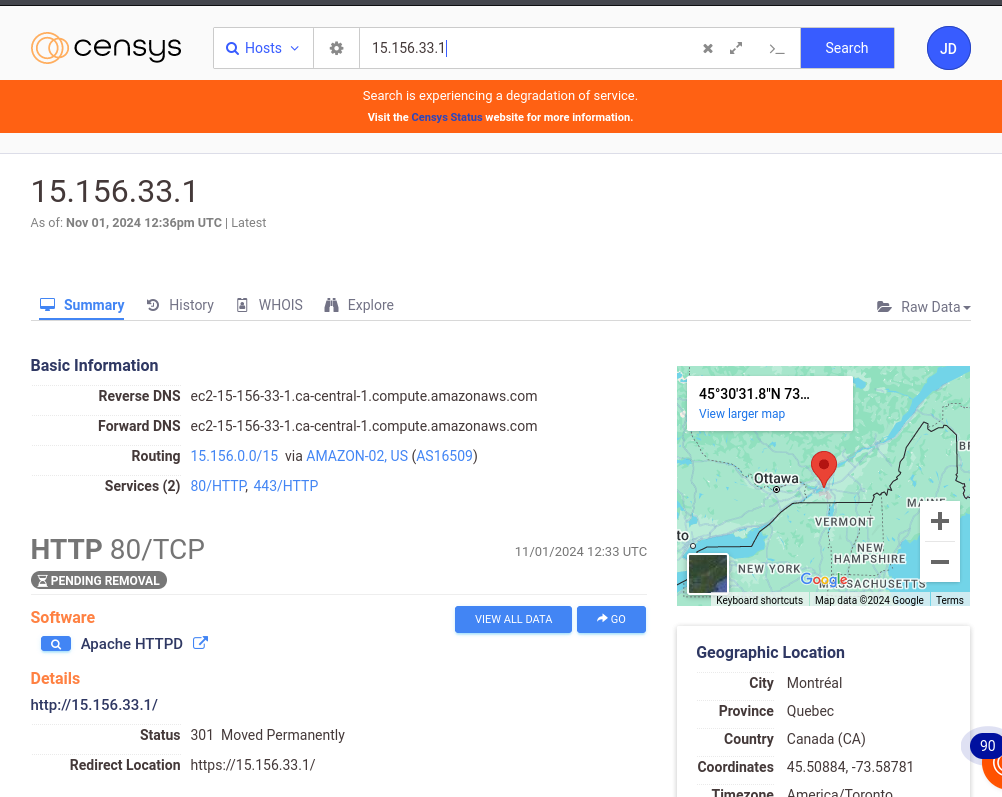
Censys
Censys est un moteur de recherche et une plateforme qui contient des données provenant de diverses sources sur les infrastructure connectées à Internet. Il dispose de données en temps-réel et retourne les informations sur des appareils, services ou des domaines. Il peut donc être très utile dans un processus de collecte d’informations sur une cible.
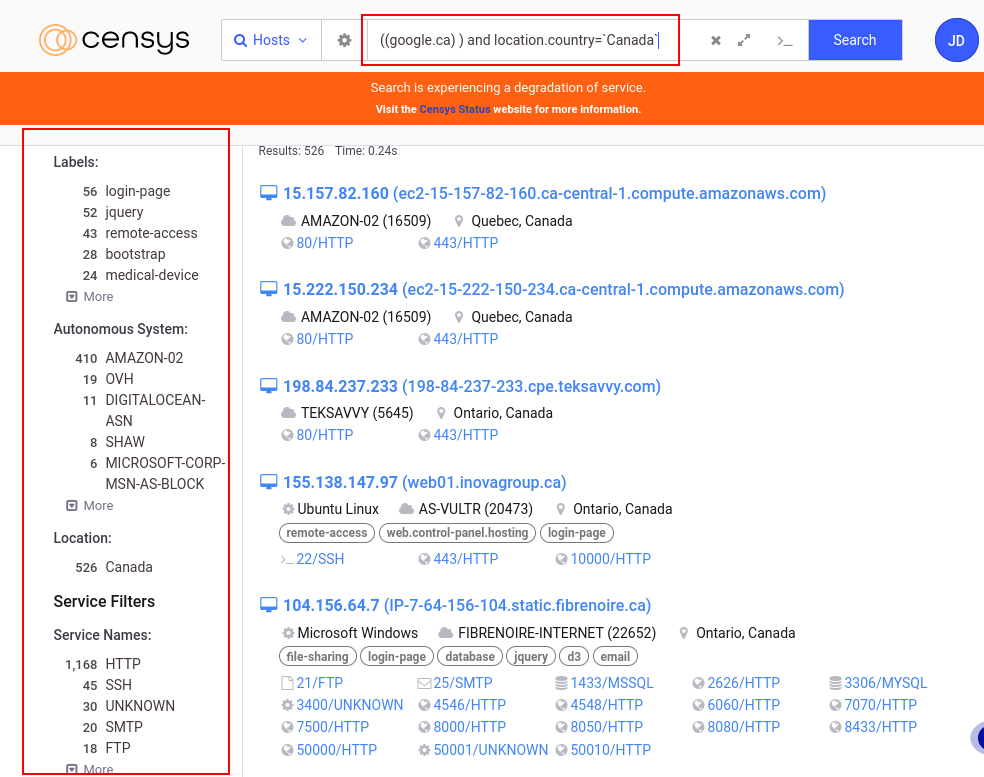
Censys permet de collecter des informations comme les adresses IP, les services et les ports ouverts. Avec les filtres avancés , on peut affiner les résultats selon les labels (hôtes IPV6, accès à distance, email etc.), les systèmes autonomes (AS), la localisation des serveurs, les fournisseurs de logiciels (Amazon, Akamai, Google, Apache, nginx)
En faisant une recherche sur Google, on peut voir qu’on a accès a beaucoup d’informations, et le résultat de la recherche retourne beaucoup d’hôtes qui pourraient être analysées.
En choisissant un hôte, on a d’autres informations comme le routage, les services , la localisation, l’historique des évènements associés et aussi un onglet Whois qui fournit des détails sur le propriétaire de l’adresse IP.
Enum4Linux
Enum4linux est un outil d'énumération pour extraire des données de systèmes utilisant le protocole SMB (Server Message Block). Il permet de recueillir divers informations à propos des comptes utilisateurs, des noms de domaines, les groupes locaux les dossiers partagés sur un réseau.
Options
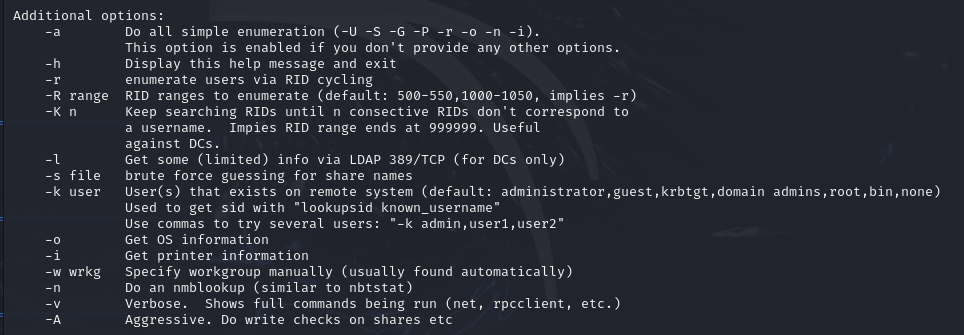
enum4linux -U -S -P -G [ip_adress]l’option
-Upermet de lister les utilisateurs sur le système ciblel’option
-Spermet de lister les partages disponibles sur le système ciblel’option
-Ppour afficher la politique des mots de passel’option
-Gliste les groupes du systèmel’option
-acombine toutes les options (-U -S -G -P -r -o -n -i). C’est l’option par défaut lorsqu’aucune n’est sélectionnée.
En exécutant la commande avec l’option -U, l’outil présente une liste d’utilisateur sur une machine 192.168.2.96
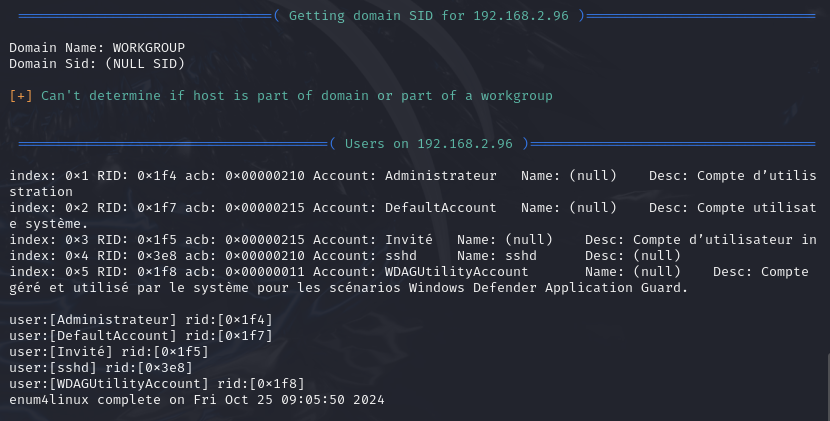
Enum4linux peut être très utile car les informations comme les utilsateurs, les partages de fichiers sur le réseau, ou encore les groupes et permissions. Ces informations peuvent être exploitées pour identifier de potentielles vulnérabilités.
WaybackURL
WaybackURL est un service qui permet d’accéder à des versions anciennes ou archivées de site web en utilisant l’Internet Archive, un service d'archivage de pages web. Il sert à consulter des anciennes versions de site web, et même si elles ont été modifiées, elle peuvent toutefois contenir des vulnérabilités qui n’ont peut être pas été corrigées ou toujours accessibles via ces archives
La documentation officielle se retrouve sur GitHub.
Pour installer WaybackURL, utilisez la commande suivante:
go install github.com/tomnomnom/waybackurls@latest
Options
waybackurls-h: l’option-hpermet de lister toutes les options de waybackurlswaybackurls https://site.com -dates | grep [word]l’option
-datesaffiche la date d’archivage de chaque URLgrep filtre les résultats pour ne montrer que les URL contenant le terme “word“
cat domains.txt | waybackurls | grep -vE "\.(js|txt)$" > urls.txtCette commande lit le fichier domains.txt et redirige la sortie vers waybackurls. Les résultats sont stockés à la fin dans le fichier urls.txt
l’option
-vEexclut les lignes correspondant à l’expression (-v) et active les expressions régulières étendues (-E).l’expression
".\(js|txt)$"correspond aux expressions régulières qui correspond aux URLs se terminant par.jsou.txt.Cette commande va donc lister les URL archivées, en excluant celles qui se terminent par
.jsou.txt.
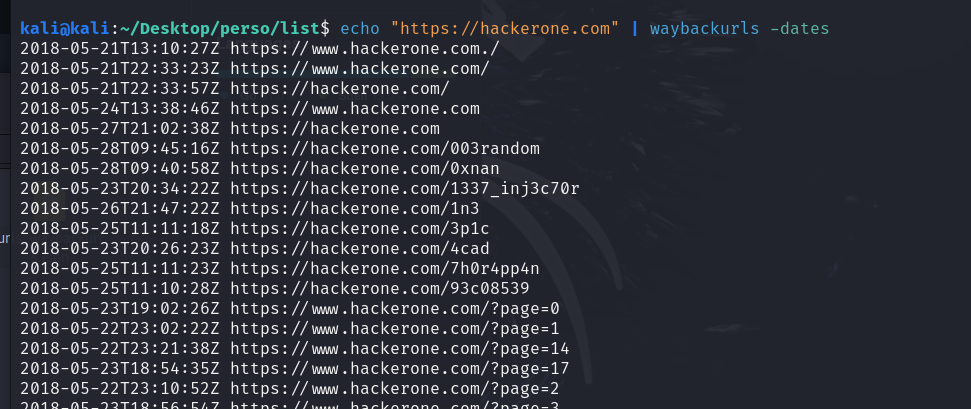
echo "https://hackerone.com" | waybackurls -no-subsl’option
-no-subsexclut les sous-domaines du domaine cible dans les résultatsCette commande affichera toutes les URLs archivées de
hackerone.com
Gowitness
Gowitness est un outil utilisé pour effectuer des captures d’écran de sites web, collecter des informations sur les en-têtes HTTP et créer des rapports sur les sites visités de manière automatisée.
Cet outil, même s'il peut sembler "inutile" parce qu'on pourrait simplement visiter les pages web, est en fait très pratique lorsqu'on a plusieurs sites à vérifier sans perdre un temps fou à les ouvrir un par un.
Pour l’installer, utilisez la commande suivante:
go install github.com/sensepost/gowitness@latest
Options
gowitness -h: cette option liste toutes les options de gowitnessgowitness scan -h: montre les options disponibles pour effecturer des scans.gowitness scan single --url https://google.com --screenshot-path ./PATH--screenshot-format png --screenshot-fullpagel’option
--urlindique à l’outil d’effectuer la capture sur l’URL spécifiél’option
--screenshot-pathdéfinit le chemin où la capture d'écran sera sauvegardée.l’option
--screenshot-formatdéfinit le format de la capture d’écran. Par défaut elle est en format JPEG. Et seuls les formats JPEG et PNG sont valides.l’option
--screenshot-fullpagecapture la page entière, plutôt que seulement la partie visible de la page. Elle est utile pour les pages avec beaucoup de contenu en défilement
gowitness scan file -f ./PATH --log-scan-errors --write-dbl’option
file -fspécifie un fichier contenant une liste d’URLs à afficherl’option
--log-scan-errorssignale les erreurs survenues lors des scans.l’option
--write-dbenregistre les résultats dans une base de données pour une consultation ultérieure.
La photo ci-dessous montre l’exécution d’une commande avec gowitness. Des messages indiquent une tentative échoué via le port 80 pour les connexions non sécurisées en HTTP. Par contre, la connexion a réussi via le port 443 pour les connexions HTTPS, avec les captures d’écran prises
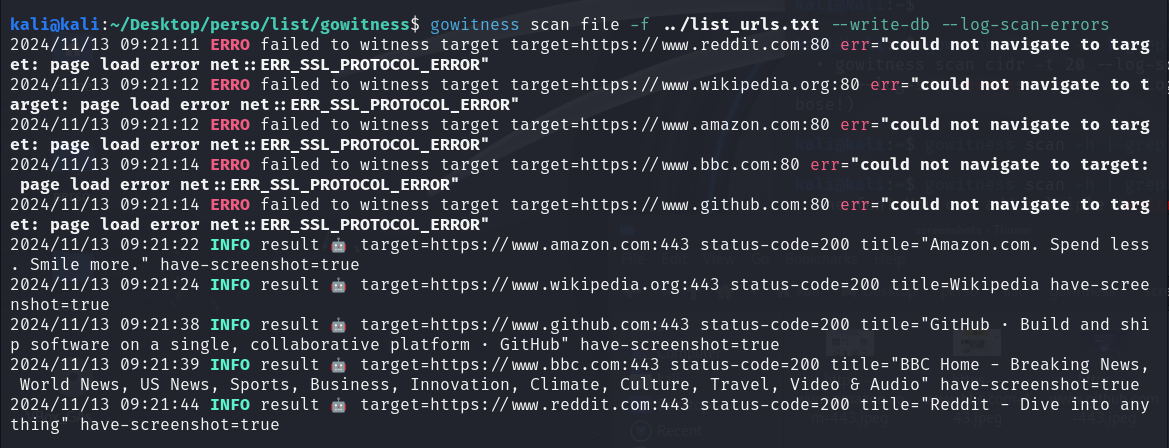
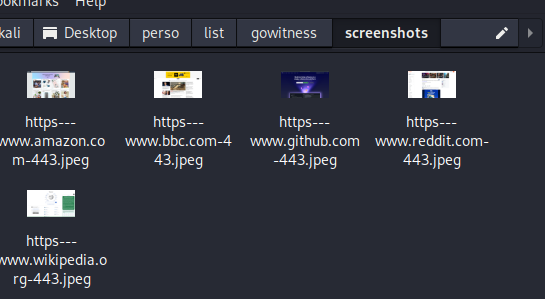
Cet outil te permet donc de visualiser plein de sites super rapidement.
Arjun
Arjun est un outil qui permet de découvrir des paramètres HTTP cachés dans les requêtes GET et POST qui pourraient être vulnérables dans des applications web. Il permet d’identifer des points d'entrée potentiels pour des attaques en testant plusieurs paramètres possibles. Pour information, les requêtes GET et POST sont des méthodes pour envoyer des données à un serveur web. Le méthode GET consiste à envoyer les données via l’URL ; c’est-à-dire qu’elles apparaissent dans la barre d’adresse du navigateur. La méthode POST consiste à envoyer les données dans le corps de la requête HTTP, ce qui les rend invisibles dans l'URL. L’outil Arjun permet donc de chercher ces paramètres dans les applications.
La documentation officielle se retrouve sur GitHub.
Pour installer Arjun, utilisez la commande suivante:
pipx install arjun
Options
arjun-h: cette option affiche toutes les options de l’outilarjun -u http://website.com -m POST -o output.json -oBl’option
-upermet de spécifier le site à analyserl’option
-oenregistre les données dans un fichierl’option
-mpermet de définir la méthode HTTP à utiliser pour la requête. Les formats valides sont GET ou POST pour la méthode HTTP et JSON ou XML pour le corps de la requête.l’option
-oBredirige le trafic via Burp Suite pour l'analyse. Par défaut, Burp écoute sur127.0.0.1:8080. Cela va donc permettre de visualiser les requêtes et les réponses interceptées par Burp.
arjun -i urls.txt -w /PATH/TO/FILE --include “token=qwerty“l’option
-ispécifie un fichier avec une liste d’URLs à analyser- l’option
-wpermet permet de spécifier une fichier contenant une liste de mots. Cette liste contient des noms de paramètres potentiels qu'Arjun utilisera pour tester l'URL cible. Par défaut, l’outil utilise une liste de mots intégrée située à{arjundir}/db/large.txt
- l’option
l’option
-inlcudepermet d’insérer des données pour chaque requête. La variable token avec une certaine valeur dans le cas d’applications nécéssitant des jetons d’authentifications. On pourrait inlure tout type de données comme des clé APIs, des clé d’authentification et autres.On peut aussi mettre les options
-m XML --include='<?xml><root>$arjun$</root>'qui incluent une structure XML spécifique dans la requête. Le marqueur$arjun$est l'endroit où l’outil va insérer les paramètres qu'il teste.
arjun -u http://website.com-c 10
Interprétation des résultats
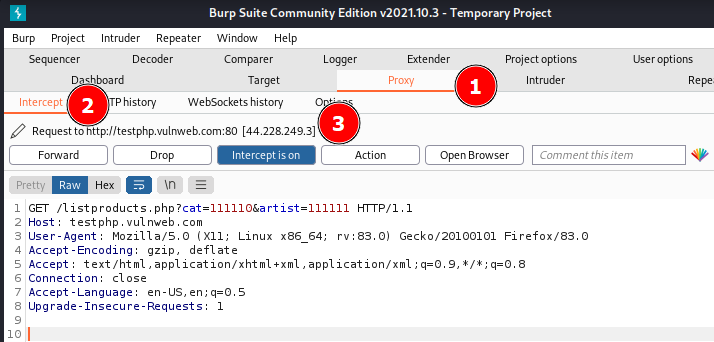
L’image ci-dessus montre la commande arjun -u http://testphp.vulnweb.com/listproducts.php -oB -o output.json exécuté.
On voit que la commande a identifié les paramètres artist et cat dans le corps la réponse.

Pour que l’option -oB fonctionne, il faut que Burp soit ouvert et configuré pour intercepter les requêtes. Vous pouvez ouvrir un terminal et lancer Burp avec la commande burpsuite. Allez dans les paramètres du Proxy et vérifiez que l’adresse du proxy sur Burp est bien configuré sur 127.0.0.1:8080. Activez ensuite l’interception.
On voit donc deux paramètres de requête “cat=111110“ et “artist=11111“ et d’autres détails comme l’hôte, le logiciel client etc.
Recherche de Sous-domaines
La recherche de sous-domaines permet d’identifier les parties d’un domaine qui pourraient être vulnérables, et donc des points d’entrée pour des services mal configurés. Le fait de découvrir les sous-domaines permet donc recueillir des informations sur les technologies et configurations utilisées.
Crt.sh
Crt.sh est un outil en ligne qui permet de rechercher et de consulter des certificats SSL/TLS pour divers domaines. Il peut aussi bien être utilisé pour trouver des sous-domaines. En recherchant un domaine principal, on peut voir les certificats associés, mais aussi ceux émis pour ses sous-domaines. Les recherches peuvent donc se poursuivre avec ces sous-domaines avec d’autres outils.
Virus Total
VirusTotal est un outil en ligne qui permet d’analyser des fichiers, des URLs afin de détecter de potentiels virus. Il effectue une analyse complète en utilisant plusieurs moteurs antivirus et outils de détections d’URLs. Il peut aussi être utilisé pour rechercher des sous-domaines et d’autres informations.
Les sous-domaines associés à la recherche seront listés dans l’onglet Relations. La photo ci-dessous montre une liste de sous domaines associés à Amazon.ca.

Chaos projectdiscovery
Chaos est un projet de ProjectDiscovery qui fournit des informations sur les sous-domaines. Il dispose d’une base données avec un grand nombre de sous-domaines pour les domaines publics, mis à jour régulièrement.

Il suffit donc de télécharger le fichier .zip et on obtient une liste de sous-domaines associés au terme ou au domaine dans la recherche.
Chaos ProjectDiscovery est un projet open-source et peut être aussi utilisé via GitHub. L’utilisation de cet outil avec l’API en ligne de commande est beaucoup plus flexible et puissante en terme de recherches. En utilisant l’outil en ligne de commande, on obtient une liste plus complète, contrairement à la version web où l’utilisation peut ne retourner aucun résultat pour certains domaines
Pour l’installer, utilisez la commande suivante:
go install -v github.com/projectdiscovery/chaos-client/cmd/chaos@latest
Options
chaos -h: cette option liste toutes les options de Chaos ProjectDiscoveryexport PDCP_API_KEY=[API_ KEY]cette option permet de spécifier la clé API qui peut être obtenue simplement en s’inscrivant sur le site
la clé API doit être spécifiée obligatoirement pour l’utilisation en ligne de commande
chaos -d [site.com] -count -o list.txtl’option
-dspécifie le domaine à analyserl’option
-countaffiche le nombre de sous-domaines sans les listerl’option
-ospécifie un fichier (ici list.txt) pour stocker la sortie
chaos -dL [list_domains.txt] -json | grep [STRING] > list.txtl’option
-dLspécifie un fichier contenant une liste de domaines à analyserl’option
-jsonaffiche la sortie en format JSONl’option
grepfiltre les résultats de la recherche selon le string défini et les enregistre dans le fichier list.txt

Subfinder
Subfinder est outil d’énumération de sous-domaines écrit en langage Go, développé par ProjectDiscovery. Il est utilisé pour effectuer une énumération passive des sous-domaines d’un domaine cible, c’est-à-dire, qu'il utilise des sources en ligne publiques pour identifier les sous-domaines sans interagir directement avec les serveurs cibles. Il utilise des sources comme Censys, Chaos, Recon.dev, Shodan, Spyse, Virustotal etc.
La documentation officielle se retrouve sur GitHub.
Pour installer Subfinder, utilisez la commande suivante:
go install -v github.com/projectdiscovery/subfinder/v2/cmd/subfinder@latest
Options
subfinder -h: l’option-hpermet de lister toutes les options de subfindersubfinder -ls: l'option-lspermet de lister toutes les sources de données possiblessubfinder -d [site.com] -all -json -cs -o [list.txt]l’option
-dspécifie le domaine à analyserl’option
-allpermet d’utiliser toutes les sources pour l’énumération.l’option
-jsonaffiche la sortie en format JSONl’option
-cspermet d’afficher la source dans le résultat de la commandel’option
-oenregistre les résultats dans un fichier
Ici, on analyse le domaine hackerone.com en affichant les sources de chaque sous-domaine avec l’option -cs, et en excluant les sources du serveur google 8.8.8.8 avec l’option -es.

subfinder -dL [list_domains.txt] -s/-es [SOURCES] -rl [INT]l’option
-dLspécifie un fichier contenant une liste de domaines à analyserl’option
-sspécifie les sources à utiliser lors de la recherchel’option
-esexclut les sources lors de la recherchel’option
-rldétermine le nombre de requêtes https par secondes. Cela limite et évite la surcharge
subfinder -d hackerone.com --active -oIl’option
--activeou-nWvérifie les sous-domaines en temps réel. Elle vérifie si les sous-domaines sont actifs et répondent aux requêtes, sinon, ils ne sont pas listées.l’option
-oIou-ippermet d’inclure les adresses IP des sous-domaines dans le résultat. Cette option ne s’utilise qu’en combinaison avec l’option--activeou-nW

Assetfinder
Assetfinder est aussi un outil développé en langage Go, utilisé pour énumérer des sous-domaines associé à un domaine principal. Il utilise des sources comme, certspotter, hackertarget, facebook, virustotal etc.
La documentation officielle se retrouve sur GitHub.
Pour installer Assetfinder, utilisez la commande suivante:
go install github.com/tomnomnom/assetfinder
Options
assetfinder -h: l’option-hpermet de lister toutes les options de assetfinderassetfinder -subs-only [SITE.COM] > list.txt- l’option
-subs-onlylimite la sortie aux sous-domaines du domaine cible. Cette option est la seule disponible pour assetfinder.
- l’option

Amass
Amass est un outil développé par l'OWASP (Open Web Application Security Project) qui est aussi utilisé pour l’identification de sous-domaines et des adresses IP associées en utilisant des sources publiques commes des APIs, des certificats SSL, des DNS etc.
La documentation officielle se retrouve sur GitHub.
Pour installer Amass, utilisez la commande suivante:
go install -v github.com/owasp-amass/amass/v4/...@master
Options
amass enum: ce mode est utilisé pour l’énumération des sous-domaines en utilisant des sources publiques et des techniques de reconnaissance active.amass intel: ce mode est utilisé pour découvrir des domaines et d'autres actifs qui peuvent être explorés plus en détail lors du processus d'énumérationamass enum -d website.com -active -brute -aw /PATH -bl “word“l’option
-dspécifie le domaine dont on veut énumérer les sous-domainesl’option
-activepermet de rechercher les sous-domaines actifs- l’option
-awpermet de spécifier un fichier de liste de mots qui sera utilisé pour les altérations des noms des sous-domaines. Cela permet de modifier dynamiquement les sous-domaines en ajoutant des termes dans les noms des sous-domaines non visibles dans les résultats de DNS standards.
- l’option
l’option
-blpermet de spécifier des domaines à exclure de la recherche
L’image ci-dessous montre la commande amass utilisée, qui a découvert plusieurs informations dont des enregistrements MX, A, AAAA et plusieurs autres sous-domaines. On y retrouve aussi des informations ASN de CloudFlare, qui gère probablement les adresses IP de ces sous-domaines là.

Sublist3r
Sublist3r est un outil d’énumération de sous domaines en utilisant des moteurs de recherche et d'autres sources en ligne. Il intègre l’outil Subbrute, un outil de brute force pour l'énumération de sous-domaines, afin d'augmenter la capacité de trouver plus de sous-domaines. Subbrute utilise une liste de mots améliorée pour tester de manière systématique des sous-domaines potentiels.
La documentation officielle se retrouve sur GitHub.
Pour installer Sublist3r, utilisez la commande suivante:
git clone https://github.com/aboul3la/Sublist3r.git
cd Sublist3r
pip install -r requirements.txt
Options
python sublist3r.py -h: l’option-hpermet de lister toutes les options de sublist3rpython sublist3r.py -b -d [site.com] -p 80,21 -o result.txtl’option
-dpermet de spécifier le domaine ciblel’option
-bactive le mode brute force pour découvrir les sous-domainesl’option
-pspécifie les ports à tester pour vérifier si un sous-domaine est actif sur ces ports.l’option
-oenregistre les résultats dans un fichier
python sublist3r.py -e google,virustotal -v -d [site.com]l’option
-epermet de spécifier le moteur de recherche à utiliserl’option
-vactive le mode verbeux, ce qui permet d'afficher plus de détails pendant l'exécution du script et les sous-domaines en temps réel.
La commande ci-dessous exécutée, enumère les sous-domaines de google.com et active le mode verbeux, ce qui permet d’afficher les sous-domaines en temps réel.
La commande recherche les sous-domaines sur plusieurs sources dont Baidu, Yahoo,Google,Bing, SSL Certificates etc.


OneForAll
OneForAll est un outil d’énumération de sous-domaines utilisé pour lister les sous-domaines d’un domaine principal. Cet outil utilse plusieurs techniques comme la résolution de DNS, le brute-forcing des sous-domaines et collecte aussi des données à partir de sources publiques que d’autres outils n’interrogent pas généralement. OneForAll règle le problème de puissance ou encore d’efficacité qu’on peut voir avec d’autres outils.
La documentation officielle se retrouve sur GitHub.
Pour installer OneForAll, utilisez les commandes suivantes:
Vérifiez d’abord les versions de Python et pip3 . La version de Python3 doit être supérieure à 3.6.0 et la version de pip3, supérieure à 19.2.2.
python -V
pip3 -V
Clonez le dépôt du projet.
git clone https://github.com/shmilylty/OneForAll.git
Créez un environnement virtuel pour séparer l’installation de votre environnement python.
virtualenv -p python3 .venv
source .venv/bin/activate
Installez les dépendances
cd OneForAll
python3 -m pip install -U pip setuptools wheel
pip3 install -r requirements.txt
Options
python3 oneforall.py -h: cette option permet de lister toutes les options de OneForAllpython oneforall.py --target [site.com] --brute FALSE --dns FALSE --valid TRUE runl’option
--targetpermet de spécifier l’URL ou le domaine à analyserl’option
--brutepermet d’activer/désactiver le module de bruteforce pour rechercher les sous-domaines. Par défaut, l’option est activéel’option
--dnspermet d’activer/désactiver la résolution DNS lors de l’analyse des sous-domaines. Cette option est aussi activée par défaut.l’option
--validpermet de spécifier que seuls les sous-domaines actifs et valides seront pris en compte. L’outil va donc interroger chaque sous-domaine afin de vérifier leur validité.
python oneforall.py --targets list_urls.txt --takeover TRUE --path /PATH/TO/FILE runl’option
--targetspermet de spécifier une liste de domaines contenue dans un fichierl’option
--takeoverpermet de vérifier si un sous-domaine trouvé est vulnérable à une prise de contrôle de sous-domaine (subdomain takeover, comme l’outil subzy détaillé un peu avant). Cette option est cruciale dans l’identification des sous-domaines mal configurés. Elle est par défaut désactivée.l’option
--pathspécifie le chemin du fichier où seront stockés les résultats de la collecte de sous-domaines. Lorsqu’un fichier n’est pas spécifié, OneForAll générera automatiquement un fichier de résultats.Comme le montre l’image ci-dessous, l'outil génère automatiquement un fichier
.csvqui répertorie les résultats, dans le dossier/results
Interprétation des résultats
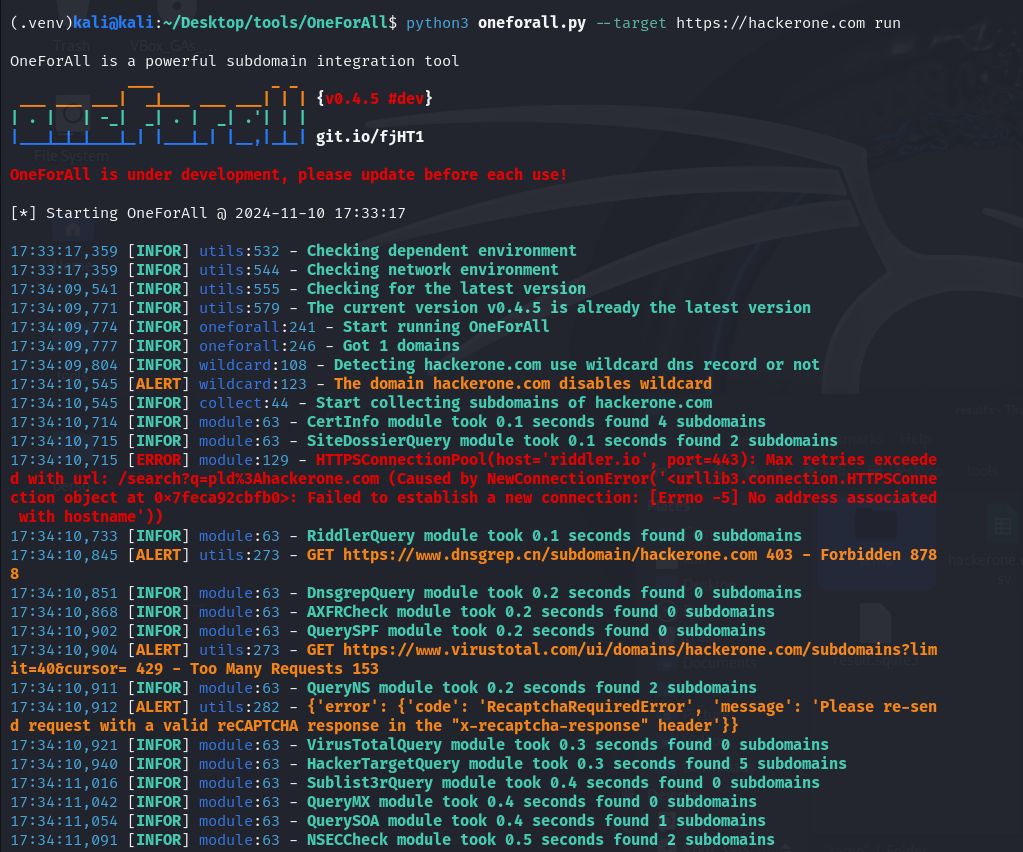
Les résultats de la commande OneForAll sur https://hackerone.com montrent les modules exécutés ainsi que le nombre de sous-domaines trouvés. Par exemple, avec les résultats de cette requête, on voit que le module CertInfo a trouvé 4 sous-domaines en 0,1 seconde, l'accès au site dnsgrep.cn a été refusé (statut403) et d’autres informations.
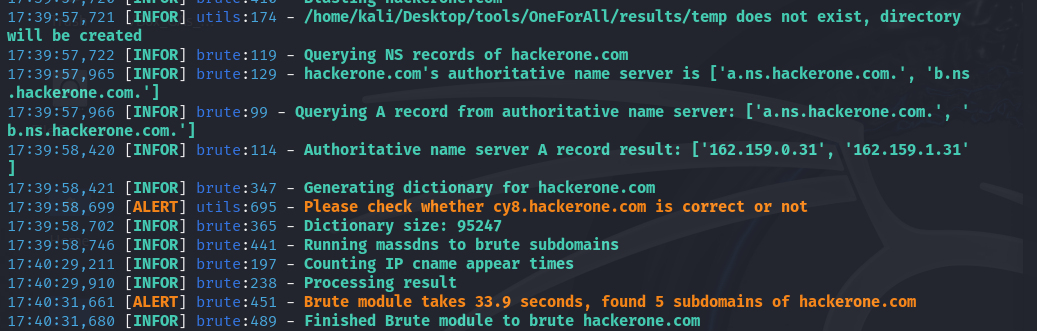
Les serveurs a.ns.hackerone.com et b.ns.hackerone.com ont aussi été trouvés, ce qui a permis de retourner les adresses IP 162.159.0.31 et 162.159.1.31.
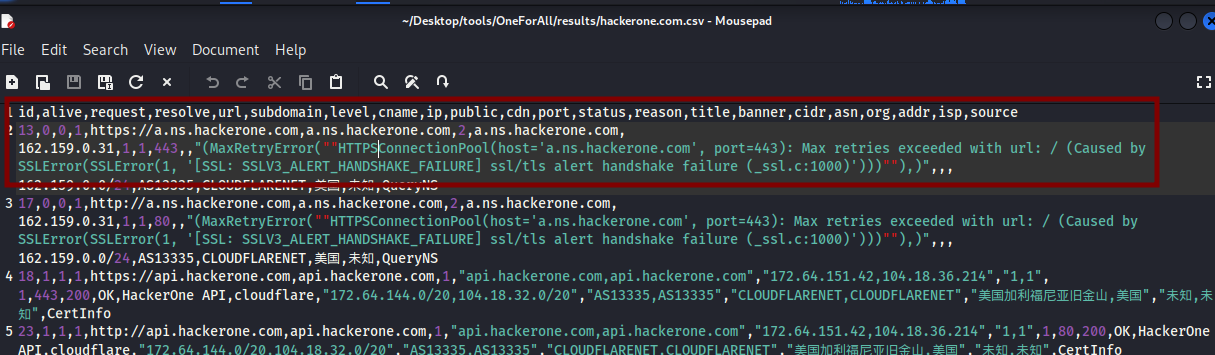
Les sous-domaines trouvés seront répertoriés dans le dossier /results par défaut dans un fichier csv qui peut être compliqué à lire. Vous pouvez formater les colonnes à l’affichage avec les commandes column et less:
column -s, -t < hackerone.com.csv | less -#2 -N -S
L’option
-s,(-s suivi de la virgule) spécifie que la virgule ( , ) est le délimiteur qui sépare les colonnes dans le fichier.L’option
-tindique à column de créer un tableau avec des colonnes alignées< hackerone.com.csvpermet une redirection du contenu du fichier hackerone.com.csv comme entrée pour la commande columnless -#2 -N -Spermet de paginer la sortie avecless, affiche les numéros de ligne avec-N, permet un défilement horizontal avec-S, et définit l'espacement des tabulations à 2 avec-#2. Vous pouvez quitter l’affichage avec la toucheq.
Le fichier avec les résultats avec un affiche standard se présente comme suit:
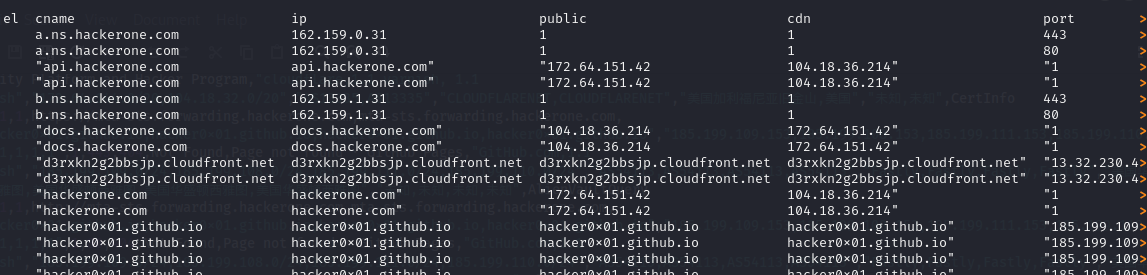
On passe donc de l’affichage de l’image au dessus à ceux en dessous avec la commande column -s, -t < hackerone.com.csv | less -#2 -N -S .

Linked Discovery
Le linked Discovery est un processus qui consiste à explorer et à extraire des liens et des ressources d’un site web pour obtenir des informations sur une cible. Il permet d’identifier la structure des pages et les relations entre elles pour mieux comprendre comment un site est construit. On peut aussi y ressortir les sous-domaines et d’autres ressources cachées ou moins visibles.
Katana
Katana est un outil d’exploration de sites web, écrit en Go, dévéloppé par Project Discovery. Il permet aussi d’analyser des sites web, d’y extraire des ressources cachées et identifer des vulnérabilitées potentielles.
La documentation officielle se retrouve sur GitHub.
Pour installer Katana, utilisez la commande suivante:
go install github.com/projectdiscovery/katana/cmd/katana@latest
Options
katana -h: cette option liste toutes les options de katanakatana -u [https://site.com] -d [INT] -e "STRING" -rl [INT] -o [results.json]l’option
-udéfinit le site ou l’URL à analyserl’option
-ddéfinit la profondeur d’exploration à partir du lien spécifiél’option
-eexclut divers éléments correspondants à la chaîne de caractère spécifiée. Cela peut être des chemins, des adresses IP, des sous-domaines etc.l’option
-rlfixe un nombre maximal de requêtes par secondes (150 par défaut)
cat file.txt | katana -jc -noicatpermet de lire un fichier qui contient une liste d’URLs (une par ligne) à explorerl’option
-jcactive l’analyse des fichiers JavaScript, ce qui permet d'extraire des liens et des ressources depuis les fichiers JavaScript du site.l’option
-noipour no incognito désactive le mode incognito, ce qui permet de conserver l'historique de navigation pendant l'exploration.
Toute la documentation et les options sont disponibles sur Github.
La photo ci-dessous montre une exécution de l’outil. Elle explorera le site http://youtube.com, à une profondeur de 3, exclura les chemins contenant /login, active l’analyse des fichiers JavaScript, et enregistrera les résultats dans un fichier.
On voit donc que des liens et fichiers JavaScript sont bien extraits.

GoSpider
GoSpider est un outil de reconnaissance écrit en langage Go, pour crawler ou extraire des données d’un site Web. Un crawler ou robot d’exploration est un programme ou un script automatisé destiné à collecter des informations sur des sites internet. GoSpider peut être utilisé lors de la reconnaissance pour identifier des liens, des ressources, des fichiers en lien avec un site spécifique.
La documentation officielle se retrouve sur GitHub.
Pour installer GoSpider, utilisez la commande suivante:
go get -u github.com/jaeles-project/gospider
Options
gospider -h: l’option-hpermet de voir la liste de toute les options de GoSpidergospider -s [site.com/URL] -c [INT] -o [resultat.txt/.json]l’option
-sspécifie l’URL ou le site à analyser;l’option
-cdéfinit le nombre maximal de requêtes simultanées lors de l’exploration du site (par défaut, il est fixé à 5);l’option
-oenregistre les résultats dans un fichier;
gospider -S [sites] -q --blacklist [ ] -d [INT]l’option
-Sspécifie une fichier texte contenant les URLS de sites à analyser;l’option
-qrend l’analyse plus concise et désactive les logs détaillés;l’option
--blacklistpermet d’exclure (blacklister) soit des extensions, des types de fichiers lors de l’analyse.l’option
-ddéfinit la profondeur de lien à explorer lors du crawl. Cela signique qu’il explore d’abord l’URL initiale, ensuite les liens trouvés sur cette page, et ensuite les liens sur ces pages, et ainsi de suite. Il est fixé à 1 par défaut.
En parcourant la liste des options, vous aurez accès aux différentes manières d’utiliser GoSpider.
Hakrawler
Hakrawler est aussi un outil de reconnaissance utilisé pour explorer des sites web et extraire des informations comme des liens, des formulaires et des emplacements de fichiers . Aussi écrit en langage Go, il est utilisé lors de la phase de reconnaissance lors des tests de sécurité.
La documentation officielle est disponible sur GitHub.
Pour installer Hakrawler, utilisez la commande suivante:
go get -u github.com/hakluke/hakrawler
Options
hakrawler -h: cette option affiche toutes les options de hackrawlerecho [URL] | hakrawler -t [INT] -d [INT] -t [INT] | grep "STRING"la commande
echoenvoie l’URL en tant qu’entrée à Hakrawler via le pipe|l’option
-tpour threads, définit le nombre de requêtes simultanées pour accélerer l’exploration. Cela permet de crawler plusieurs pages à la foisl’option
-ddéfinit la profondeur du crawll’option
-tfixe le délai dattente pour chaque requête. Passé ce délai, la requête d’exploration est abandonnée si elle ne recoit aucune réponsel’option
grepfiltre les résultats du hakrawler selon le string défini
cat sites.txt | hakrawler -subs -jsonle contenu du fichier “sites.txt” est lu (une URL par ligne) et redirigé à Hakrawler via le symbole pipe
|l’option
-subsindique qu’il faut analyser aussi les sous-domaines liés à chaque url dans le fichierl’option
-jsonretourne les résultats en format JSON
La photo ci-dessous montre une exécution de l’outil. La commande explore le site avec une profondeur d'exploration de 2 niveaux, incluant les sous-domaines et affiche les résultats en format JSON

Scan
Le scan d’un réseau ou d’une application permet d’identifier des vulnérabilités sur les services ou des applications qui s’exécutent. C’est une étape assez cruciale qui permet de détecter des failles de sécurité potentielles. Plusieurs outils de scan peuvent être utilisés dans ce cas.
Il existe plusieurs type de scans:
le scan de ports permet d’identifier des ports ouverts sur un système. Ces ports peuvent donc indiquer des services actifs qui peuvent être exploitées.
Nmapest l’outil le plus connu utiliser pour ce type de scan. Il existe aussiNaabuou encoreRustscan.le scan web permet d’explorer les applications web dans le but de détecter des failles commes les injections SQL, les failles XSS, CSRF et d'autres vulnérabilités spécifiques aux applications web. Des outils comme
Nikto,Burp Suitepeuvent être utilisés pour ce type de scanle scan réseau permet d’analyser l’ensemble d’un réseau dans le but d’identifier les appareils connectés, les services et aussi les configurations réseau pouvant être vulnérables
le scan de vulnérabilités permet de rechercher des failles de sécurité qui sont connues dans les systèmes. Ils sont généralement utilisés dans le cadre d’audit de sécurité et fournissent des rapports détaillés. Des outils comme
Nessus,Qualyspeuvent être utilisés dans ce cas. Ces deux outils sont payants, mais disposent aussi de plans limités qui sont gratuits. Nikto peut aussi être utilisé.
Naabu
Naabu est un scanner de ports devéloppé par Project Discorvery et écrit en lagange Go, pour identifier les services ouverts sur une machine ou un réseau. Il est connu pour être plus rapides, avec beaucoup d’options, comme le fait de pouvoir exclure des ports, scanner toute une liste de ports ou encore le combiner avec Nmap pour avoir des résultats plus détaillés. Vous pouvez l’installer directement via Github.
Installez d’abord Go sur votre machine avec la commande suivante:
sudo apt install golang-go
Installez ensuite l’outil Naabu
go install -v github.com/projectdiscovery/naabu/v2/cmd/naabu@latest
Options
naabu -h: l’option-hpermet de lister toutes les options de Naabunaabu -host [DOMAIN/IP] -exclude-ports [PORT,PORT] -jsonl’option
-hostdéfinit le domaine ou l’adresse IP à scannerl’option
-ppermet de scanner un port spécifiquel’option
-exclude-portspermet d’exclure des ports lors du scanl’option
-jsonpermet d’avoir les résultats en format JSON
naabu -list [domains.txt] -o [output.json]L’option
-listou-leffectue un scan avec un fichier contenant une liste de domaines ou d’adresses IPl’option
-opour sauvegarder les résultats dans un fichier
naabu -host [DOMAIN/IP] -p [PORTS] -nmap-cli 'nmap -sV -Pn'L’option
-nmap-clipermet d’exécuter la commande nmap directement sur les résultats obtenus. Nmap doit être déjà installé pour que ca fonctionne.Cette commande exécute Naabu pour scanner les ports spécifiés sur le domaine puis lance le service nmap sur chaque port.
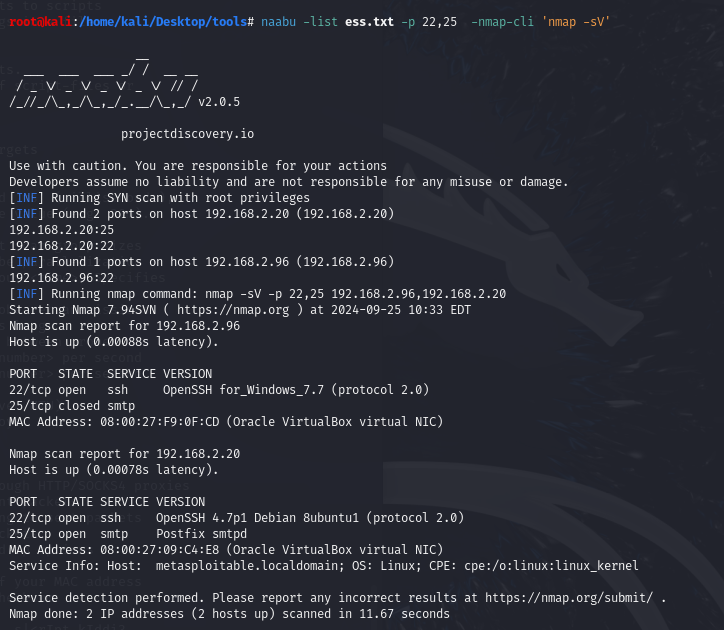
Il est aussi possible de combiner Naabu avec ASNmap avec la commande suivante:
asnmap -a ASXXXX -silent | naabu -p 22,80 -silent
Cette commande va d’abord récupérer les plages d’adresses IP associées à l’ASN en mode silent et ensuite scanner les ports 22 et 80 avec Naabu. Si vous n’êtes pas familier avec ASNMAP, vous pouvez lire un article à ce sujet ici.
Rustscan
RustScan est aussi un scanner de ports, écrit en langage Rust, beaucoup plus rapide et capable d’intégrer des outils comme Nmap pour des analyses plus détaillées. RustScan redirige directement ses résultats vers Nmap pour d’autres anlayses. Il est aussi possible de les modifier à votre guise.
Vous pouvez accéder au dépôt depuis la biliothèque officiel sur Github.
Téléchargement sur Kali Linux
Téléchargez le fichier d’installation depuis le terminal. Il existe plusieurs versions de Rustscan.
wget https://github.com/RustScan/RustScan/releases/download/2.0.1/rustscan_2.0.1_amd64.deb
Allez vers le dossier Downloads et modifiez les permissions du fichier installé en le rendant exécutable.
cd Downloads
sudo chmod +x rustscan_2.0.1_amd64.deb
Installez le package Debian
sudo dpkg -i rustscan_2.0.1_amd64.deb
En cas de problèmes, exécutez la commande suivante:
sudo apt update
sudo apt upgrade
Si vous rencontrez des problèmes de dépendances, exécutez la commande suivante :
sudo apt-get install -f
RustScan devrait être maintenant installé .
Options
rustscan -a [DOMAINE/IP] -p [PORT,PORT] -b -gl’option
-aspécifie l’adresse ou le domine ciblel’option
-ppermet de spécifier un ou plusieurs portsl’option
-bpermet de limiter la bande passante et éviter de surcharger le réseau pendant le scan.l’option
-gsimplifie l’analyse qui n'affiche que les ports ouverts détectés, sans les détails de Nmap
rustscan -a [DOMAINE/IP] -- -sV --script vulnl’option
--termine les arguments de RustScan. Tous les argument suivants sont directement passés à Nmapl’option
-sVde Nmap pour active la détection des services et leurs versions sur les ports ouvertsl’option
--script vulndétecte les vulnérabilités sur les services
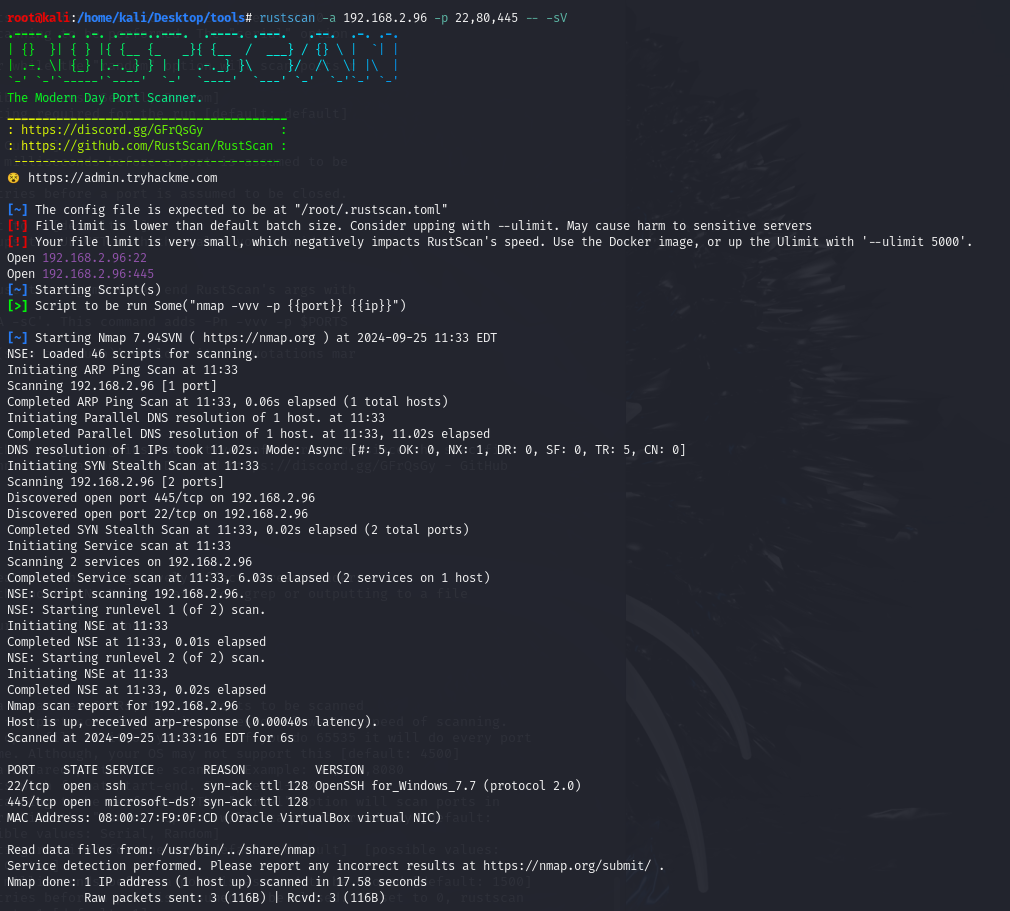
Ici on scanne les ports 22,80 et 445 de l’adresse 192.168.2.96. Le double-tiret indique les options sont passées à Nmap, avec l’option -sV, pour détecter la version des services.
Nmap
Nmap est un outil de scan qui permet aussi d’analyser un réseau ou une application web pour identifier des vulnérabilités potentielles. Il est utilisé pour scanner les ports et identifier les services actifs.
La documentation officielle de ffuf se retrouve sur le site officiel.
Pour installer nmap , utilisez la commande suivante:
sudo apt install nmap
Options
nmap -h: l’option-hpermet de lister toutes les options de nmapnmap -sn 192.168.1.0/24Cette commande exécute un scan de découverte réseau aussi appelé ping scan. Elle scanne toute les adresses dans la plage 192.168.1.1 à 192.168.1.254.
L’option
-snindique à nmap de ne pas effectuer de scan de ports, mais vérifie simplement les hôtes actifs sur le réseau
nmap -sS -sV -O --script vuln [IP_ADRESS]l’option
-sSeffectue un scan SYN rapide et discret. Il n’établit pas de connexion complète avec la cible,ce qui rend l’analyse moins visible par des sytèmes de détection par exemple.l’option
-sVpermet de détecter les versions des services en cours sur les ports ouverts sur la machinel’option
-Opermet de déterminer le système d’exploitation de la ciblel’option
--script vulnexécute des scripts qui permettent de détecter les vulnérabilités connues sur la cible.
nmap -T4 -sC -p 80,21 [IP_ADRESS]l’option
-T4permet de définir le niveau d'agressivité du scan et va de -T0 à T5. Cela permet de définir la vitesse d’exécution du scan, ce qui peut la rendre plus rapide, mais aussi détectable par des systèmes de d'étectionl’option
-sCexécute les scripts par défaut de nmap via le Nmap Scripting Engine (NSE) pour la détection de versions et la recherche de vulnérabilités.l’option
-pspécifie les ports à scanner
Voici un document qui détaille toutes les options de nmap : Nmap-Cheat-Sheet.pdf
nmap -T4 -sC -sV 10.192.160.244

La commande suivante utilise l’outil nmap pour une analyse sur l’adresse 10.192.160.244. On voit donc que 4 ports TCP ont été trouvés ainsi que des services ssh, dnsmasq et http.
Brute Force sur les sous-domaines
Le brute-force de sous-domaines est une méthode utilisée pour découvrir des sous-domaines associés à un domaine principal. Elle consiste à essayer une liste de mots pour évaluer des sous-domaines potentiels afin de vérifier leur réel existence. Ces sous-domaines peuvent parfois révéler des services, des applications vulnérables. Nous décrirons quelques outils utilisés pour cette technique.
Ffuf
Fast fuzzer (ffuf) est un outil outil open-source de fuzzing et de force brute, écrit en langage Go, utilisé pour découvrir des ressources web telles que des fichiers, des répertoires, et des sous-domaines. Le fuzzing est une méthode qui consiste à envoyer des données aléatoires, mal formées ou anormales à un système pour tester ses réponses, ce qui pourrait conduire à la découverte de vulnérabilités.
Un article décrivant l’outil ffuf au complet est disponible ici. Dans ce présent article, nous décrirons juste son utilisation dans le brute force de sous-domaines pour découvrir des sous-domaines associés à un domaine principal
La documentation officielle de ffuf se retrouve sur GitHub.
Pour installer ffuf, utilisez la commande suivante:
git clone https://github.com/ffuf/ffuf
cd ffuf
go get
go build
#La commande suivante rend ffuf disponible depuis nimporte quelle répertoire
sudo ln -s ~/go/bin/ffuf /usr/sbin/ffuf
Options
ffuf -h: l’option-hpermet de lister toutes les options de ffufffuf -u http://FUZZ.site.com -w [wordlists/common.txt]l’option
-upermet de spécifier l’URL à analyser. Cette option est obligatoire. La commande remplacera le terme “FUZZ“ dans l’URL par chaque mot de la liste et envoie une requête http à cette URL. Le paramètre FUZZ est placé ici, avant le domaine principal indiquant l’endroit où ffuf remplacera chaque mot de la liste pour tester des sous-domaines. Cela permettra donc de découvrir les sous-domaines potentiels.l’option
-wspécifie le chemin du fichier contenant la liste de mots à utiliser pour le fuzzing (option obligatoire)Chaque requête envoyée retournera donc un statut http de la réponse. En fonction de ce que l’on cherche à découvrir, un statut peut avoir une interprétation différente. Si par exemple on veut accéder à une page qui n’existe pas, mais on obtient un statut 200, cela indique une faille ou une mauvaise configuration.

Avec cette requête, on obtient un statut 200 qui indique donc que le chemin http://ffuf.me/cd/basic/class existe sur le serveur. Le fichier development.log existe aussi sur ce même serveur.
Subzy
Subzy est un outil utilisé pour détecter et prendre le contrôle (subdomain takeover) de sous-domaines vulnérables. Il s’utilise généralement lorsque des sous-domaines pointent vers des services inactifs ou mal configurés, favorisant ainsi une exploitation. Cet outil vérifie les sous-domaines pour voir s’ils sont configurés pour des services ne sont plus en usage.
Une documentation officielle se retrouve sur GitHub.
Pour installer Subzy, utilisez la commande suivante:
go install -v github.com/PentestPad/subzy@latest
Options
subzy -h: l’option-hpermet de voir la liste de toutes les options de Subzysubzy run -h: affiche les détails de la commande run de Subzy, qui détaille les options disponibles pour exécuter des vérifications de sous-domaines.subzy run --target [URL] --output [STRING] --httpsl’option
--targetpermet de spécifier un ou plusieurs domaines, séparés par une virgule.l’option
--outputspécifie un fichier de sortie en format JSON des résultatsl’option
--httpsforce l’utilisation du protocole https pour les requêtes. Il est désactivé par défaut. Cela signifie que si un sous-domaine est spécifié sans protocole http://site.com, il sera testé avec https://site.com.
subzy run --targets [PATH/TO/FILE] --hide_fails --verify_ssll’option
--targetspermet de spécifier un fichier contenant une liste de sous-domaines à tester.l’option
--hide_failspermet de masquer les résultats échoués. Seuls ceux qui réussissent (vulnérables) sont affichés.l’option
--verify_sslpermet de ne pas vérifier les sites avec des certificats SSL non sécurisés

Le message [NOT VULNERABLE] indique que les sous-domaines 00.paydiant.com et 11.paydiant.com ne sont pas vulnérables à une prise de contrôle avec l’outil Subzy.
Gobuster
Gobuster est outil écrit en langage Go utilisé pour le brute-force de répertoires et de sous-domaines. L’outil utlilise des listes mots qui peuvent être personnalisées afin de découvrir des sous-domaines cachés ou non référencés publiquement d'un domaine cible. Cet outil se distingue par sa rapidité par rapport aux autres outils.
La documentation officielle se retrouve sur GitHub.
Pour installer Gobuster, utilisez la commande suivante:
go install github.com/OJ/gobuster/v3@latest
Options
gobuster -hpermet de lister toutes les options de GobusterIl existe plusieurs modes pour utiliser l’outil gobuster

dnspour énumérer des sous-domaines DNS pour identifier des sous-domaines d'un domaine.dirénumère les répertoires/fichiers pour découvrir des chemins sur un serveur web.fuzzutilise le fuzzing sur les URLs en remplaçant le mot-clé FUZZ dans l'URL, les en-têtes et le corps de la requête pour tester différentes entrées.tftputilise l’énumération des serveurs TFTP (Trivial File Transfer Protocol)
gobuster [MODE] -hpermet de lister les options de chaque modegobuster dir -u http://site.com -t 7 -w /PATH/TO/FILE -x php,htmll’option
dirindique le mode utilisé, l’énumération de répertoires/fichiersl’option
-uspécifie l’URL ciblel’option
-tpermet de définir le nombre de threads à utiliser pour rendre l'exploration plus rapide.l’option
-xindique à l’outil d’explorer uniquement les répertoires avec les extensions spécifiéesl’option
-wspécifie le chemin vers la liste de mots à utiliser.
gobuster dns -d site.com -q -w /PATH/TO/FILE -il’option
dnsindique qu’il s’agit d’un brute force de sous-domainesl’option
-dspécifie le domaine ciblel’option
-qactive le mode silencieux pour réduire la sortie à l’écran et l’information inutilel’option
-ipermet d’afficher les adresses IPs
En exécutant la commande gobuster dns hackerone.com -i -w common.txt, on voit que plusieurs sous-domaines ont été trouvés, avec des adresses IPs associées. La liste de mots a été utilisée pour tester les sous-domaines potentiels. Chaque entrée est ajoutée à hackerone.com pour vérifier si le sous-domaine existe.

La commande gobuster fuzz -u https://hackerone.com/FUZZ -w common.txt utilise le mode fuzzing pour tester différentes entrées sur le site spécifié. Le paramètre FUZZ sera remplacé par les mots de la liste fournie. On voit que les certaines ressources demandées n’ont pas été trouvées sur le serveur qui a répondu avec un statut d’erreur 404.

On pourrait donc essayer de filtrer les résultats et ignorer le statut 404 avec l’option -b ou --excludestatuscodes .
Plusieurs autres outils peuvent être utilisés dans ce cas, comme Sublist3r, Subfinder, ou encore OneForAll.
Pour finir, la collecte d’informations, l'exploration des sous-domaines, la découverte de liens, le scan des services, et les attaques par force brute sont des étapes clés en bug bounty. En utilisant des outils comme Google Dorking, Subfinder, Naabu, ffuf, et Gobuster, il est possible de trouver des vulnérabilités cachées et maximiser les chances de détecter des failles
À noter, qu’il est important de rappeler que l'utilisation de ces outils doit toujours se faire dans un cadre légal.
Subscribe to my newsletter
Read articles from FIKARA BILAL directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
FIKARA BILAL
FIKARA BILAL
As a newcomer to the cybersecurity industry, I'm on an exciting journey of continuous learning and exploration. Join me as I navigate, sharing insights and lessons learned along the way