문자 인코딩 탐구 - Part 2: UTF-16, UTF-8, BOM, 자기 동기화 등
 정승아
정승아
원문: David Varghese, "Character Encoding Explored - Part 2: UTF-16, UTF-8, BOM, Self-Synchronization & More"
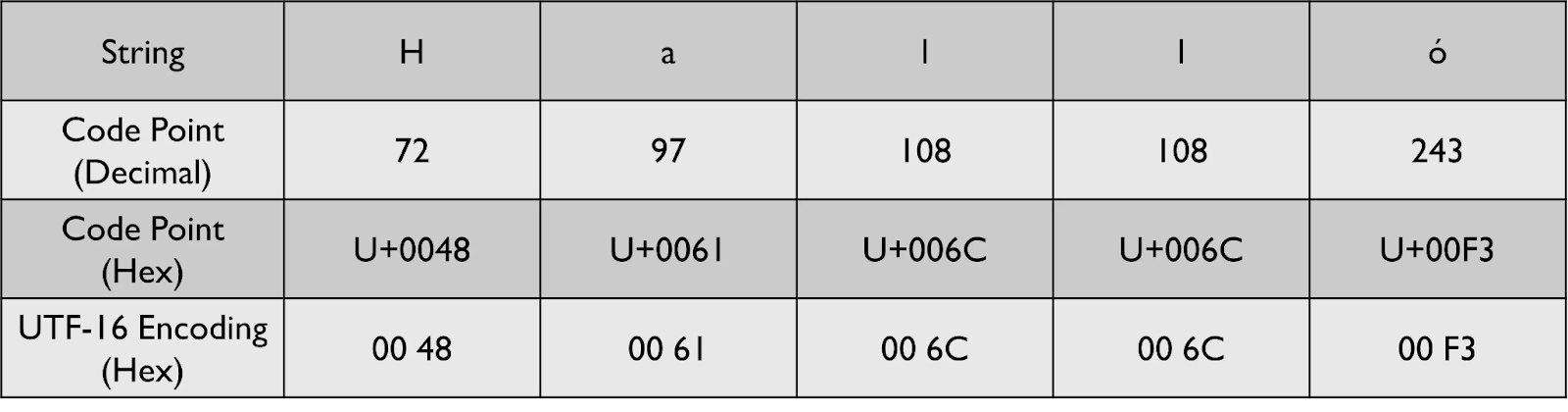
이전 글에 이어서 진행하겠습니다. 이번에는 UTF-16 및 UTF-8 인코딩 방식에 대해 살펴볼 예정입니다. 이후, BOM과 유니코드 인식 함수에 대해 알아볼 것이며 마지막으로 문자 인코딩이 자기 동기화된다는 것이 무엇을 의미하는지에 대해 다룰 것입니다.
UTF-16 인코딩
UTF-16은 UTF-32의 공간 비효율을 해결하기 위해 설계됐습니다. UTF-16 이전에는 UCS-2라는 인코딩 방식이 있었습니다. UCS-2는 유니코드 문자 세트의 자소를 나타내기 위해 16비트(2바이트)를 사용했습니다. 이러한 16비트 단위를 "워드"라고 부릅니다. UCS-2는 모든 문자를 16비트 코드 유닛으로 인코딩하므로 고정 길이 인코딩 방식에 속합니다.
유니코드 3.0 이 될 때까지 약 50,000개의 자소가 유니코드 코드 포인트에 할당되었습니다. UCS-2는 이러한 자소를 쉽게 인코딩할 수 있었습니다. 2바이트(16비트)를 사용하면 최대 65,536개의 문자를 표현할 수 있기 때문이었습니다. 그러나 유니코드의 이후 버전이 출시될 때마다 많은 새로운 자소가 추가되는 문제가 있었습니다. 결국, 코드 포인트가 65,536을 초과하는 자소들이 등장했으며, 이러한 자소는 UCS-2로는 인코딩할 수 없었습니다.
이 문제를 해결하기 위해 UTF-16이라는 새로운 인코딩 방식이 만들어졌습니다. UTF-16은 서로게이트 페어라는 개념을 도입했습니다. 16비트로 표현하기에 너무 큰 문자는 서로게이트 페어를 사용해 표현됩니다. 서로게이트 페어는 두 개의 16비트 코드 유닛으로 구성되며, 첫 번째 16비트 유닛을 상위 서로게이트, 두 번째 16비트 유닛을 하위 서로게이트라고 합니다.
코드 포인트 범위가 U+0000-U+FFFF인 자소는 UCS-2와 동일한 방식으로 인코딩됩니다. UTF-16은 유니코드의 모든 자소를 2바이트 또는 4바이트를 사용해 표현할 수 있으며, 인코딩 길이가 가변적이므로 가변 길이 인코딩 방식입니다.
0xFFFF를 초과하는 자소를 인코딩하는 알고리즘은 다음과 같습니다:
자소의 유니코드 코드 포인트에서
0x10000을 뺍니다.결과 값을 이진수로 변환합니다. 이 결과는 항상 20비트가 됩니다.
이 20비트를 두 개의 10비트 단위로 나눕니다. 이 단위들이 서로게이트 페어를 형성합니다.
상위 서로게이트 값을 계산하기 위해 10비트 상위 값에
0xD800을 더합니다.하위 서로게이트 값을 계산하기 위해 10비트 하위 값에
0xDC00을 더합니다.
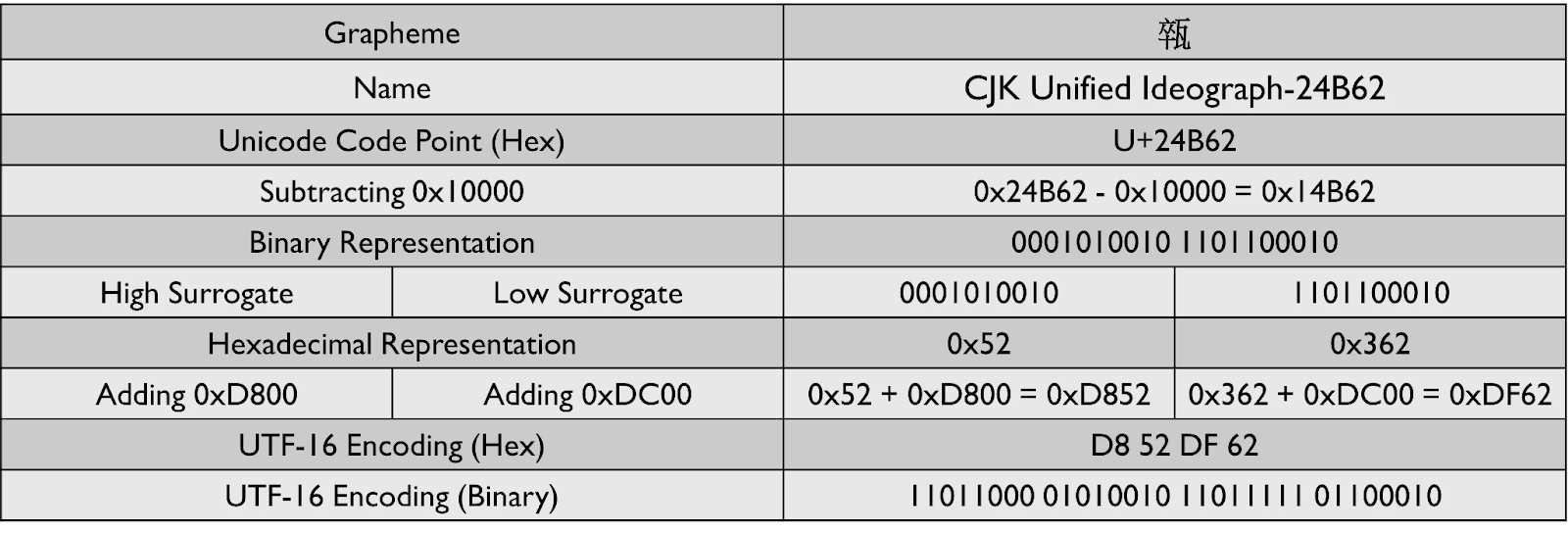
상위 서로게이트 값은 항상 0xD800 - 0xDBFF 사이에 있습니다. 하위 서로게이트 값은 항상 0xDC00 - 0xDFFF 사이에 위치합니다.
인터넷 세계 속 엄청나게 많은 콘텐츠의 대부분은 영어로 작성되어 있습니다. 라틴 문자는 ASCII를 이용해 인코딩할 경우 8비트로 표현이 가능했지만, 같은 문자를 UTF-16으로 인코딩하면 16비트가 필요합니다. UTF-16은 대부분의 경우 UTF-32에 비해 절반의 저장 공간만 필요하지만, ASCII에 비하면 여전히 더 많은 공간을 차지합니다.
특히 UTF-16은 아시아권 문자로 구성된 텍스트를 인코딩할 때 효율적인 방식으로 평가받고 있습니다.
UTF-8 인코딩
UTF-8은 UTF-32와 UTF-16의 단점을 해결하기 위해 만들어졌습니다. UTF-8은 코드 포인트를 1바이트에서 4바이트 사이로 매핑합니다. 작은 코드 포인트는 1바이트로 표현할 수 있어 많은 저장 공간을 절약할 수 있습니다. 반면, 더 큰 코드 포인트는 2바이트에서 4바이트까지 사용됩니다. UTF-8은 인코딩 길이가 고정되어 있지 않기 때문에 가변 길이 인코딩 방식에 속합니다.
UTF-8은 ASCII와 완벽히 호환됩니다. ASCII로 표현된 모든 자소는 UTF-8에서도 동일한 코드 포인트와 인코딩 값을 가집니다. 이 때문에 UTF-8 인코딩은 ASCII만 이해하는 프로그램과도 문제없이 통신할 수 있습니다. 오래된 프로그램들이라 할지라도 아무런 부작용 없이 UTF-8로 인코딩된 데이터 스트림을 읽고 ASCII로 디코딩할 수 있습니다. 또한 UTF-8의 인코딩 방식은 어떤 코드 포인트도 연속된 8개의 0을 포함하지 않도록 설계되었습니다. 이는 데이터 스트림의 안정성과 신뢰성을 보장하는 데 기여합니다.
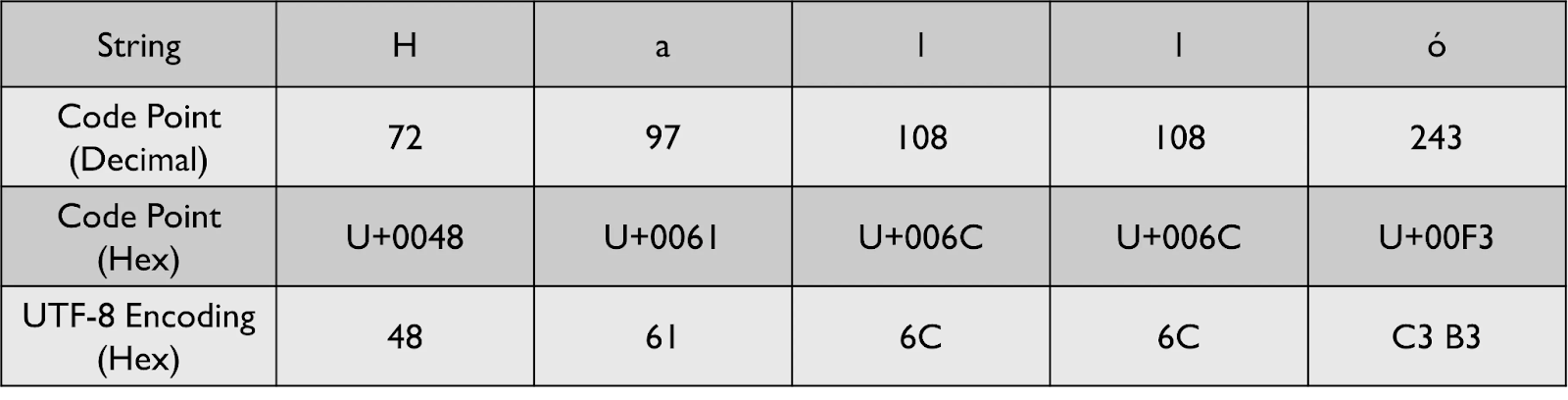
UTF-8은 자소 하나를 가변 길이로 인코딩하기 때문에 디코딩 과정이 더 복잡하며, 이는 상수 시간으로 처리되지 않습니다. 또한 UTF-8로 인코딩된 데이터 스트림에서 n번째 자소를 찾아가는 작업도 쉽지 않습니다. 고정된 크기로 건너뛸 수 없기 때문입니다. 이러한 특성은 성능에 약간의 영향을 줄 수 있지만, 대부분의 경우 큰 문제가 되지 않습니다.
UTF-8은 현재 전 세계에서 가장 많이 사용되는 인코딩 표준입니다. UTF-8에서 작은 코드 포인트는 주로 영어 알파벳을 표현하는 데 사용되며 큰 코드 포인트는 다른 문자 체계의 문자를 표현합니다. 이 때문에 영어 텍스트는 다른 언어에 비해 더 적은 바이트로 표현할 수 있습니다. 이는 인터넷에서 영어가 가장 널리 사용되는 언어라는 점에서 비롯된 불가피한 결과이며, 영어가 공간 효율성 측면에서 다른 언어보다 유리하게 작용하게 만듭니다.

유니코드의 처음 127개 자소는 확장 ASCII와 1:1로 매핑됩니다. 이 자소는 UTF-8에서 1바이트로 표현됩니다. 이 범위의 모든 자소는 7비트로 인코딩할 수 있으므로, 문자열의 왼쪽에 0을 추가해 8비트 길이로 만듭니다.
128에서 1,919 사이의 자소는 UTF-8에서 2바이트로 인코딩됩니다. 이 경우, 첫 번째 바이트의 왼쪽 3비트는 110으로 설정됩니다. 두 번째 바이트의 왼쪽 2비트는 10으로 설정됩니다. 유니코드 코드 포인트의 이진 표현은 11비트 길이가 되도록 패딩 처리한 후 UTF-8로 인코딩됩니다.
비슷한 패턴이 나머지 범위의 자소를 인코딩할 때도 적용됩니다. 이 과정에서, 1바이트 이상 필요한 자소의 경우, 첫 번째 바이트의 1의 개수가 인코딩에 사용되는 바이트 수와 동일하다는 점을 알 수 있습니다. UTF-8 인코딩을 수행하기 전, 위의 규칙에서 나타나는 x의 개수에 의해 데이터 스트림의 길이가 결정됩니다.
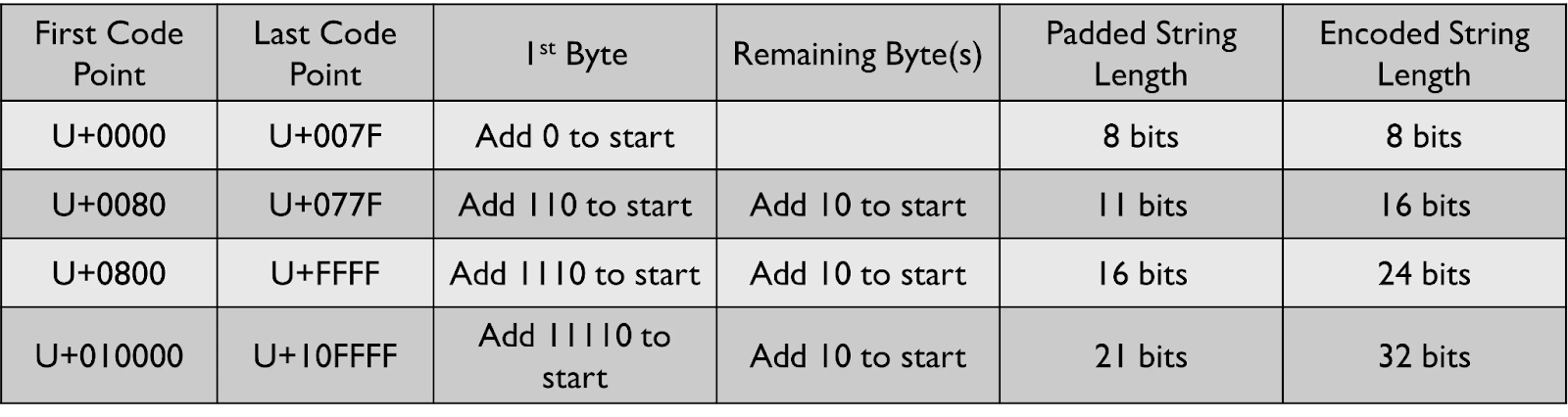
몇 가지 예제를 통해 UTF-8 인코딩이 어떻게 수행되는지 살펴보겠습니다.
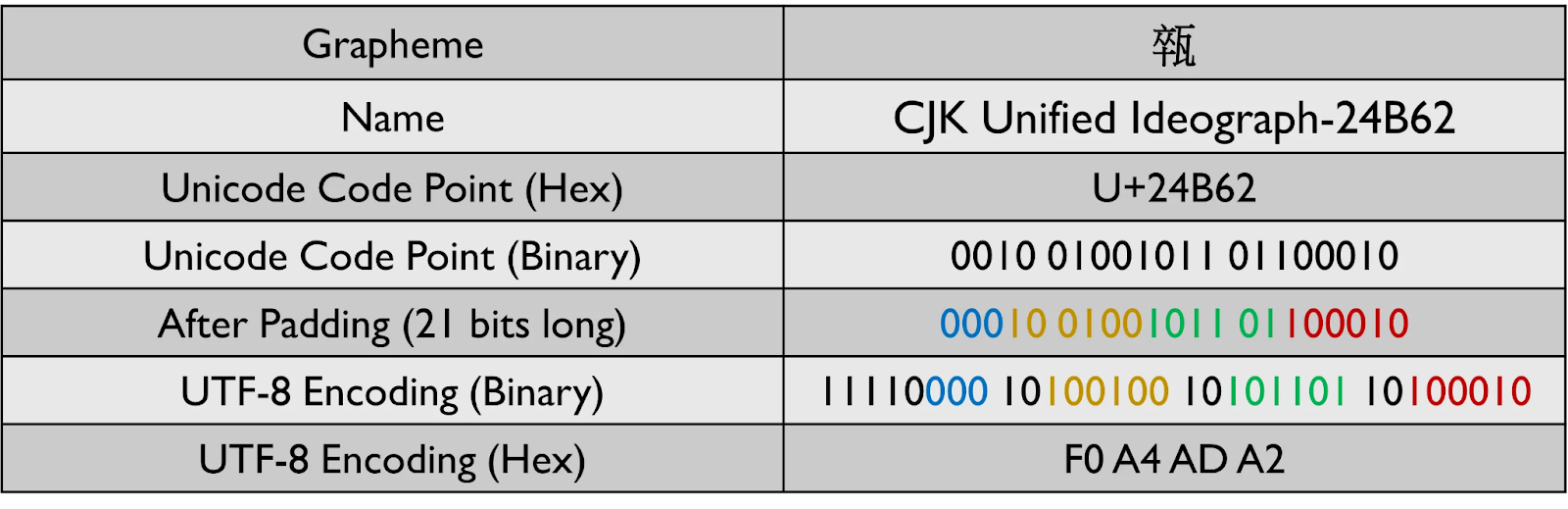
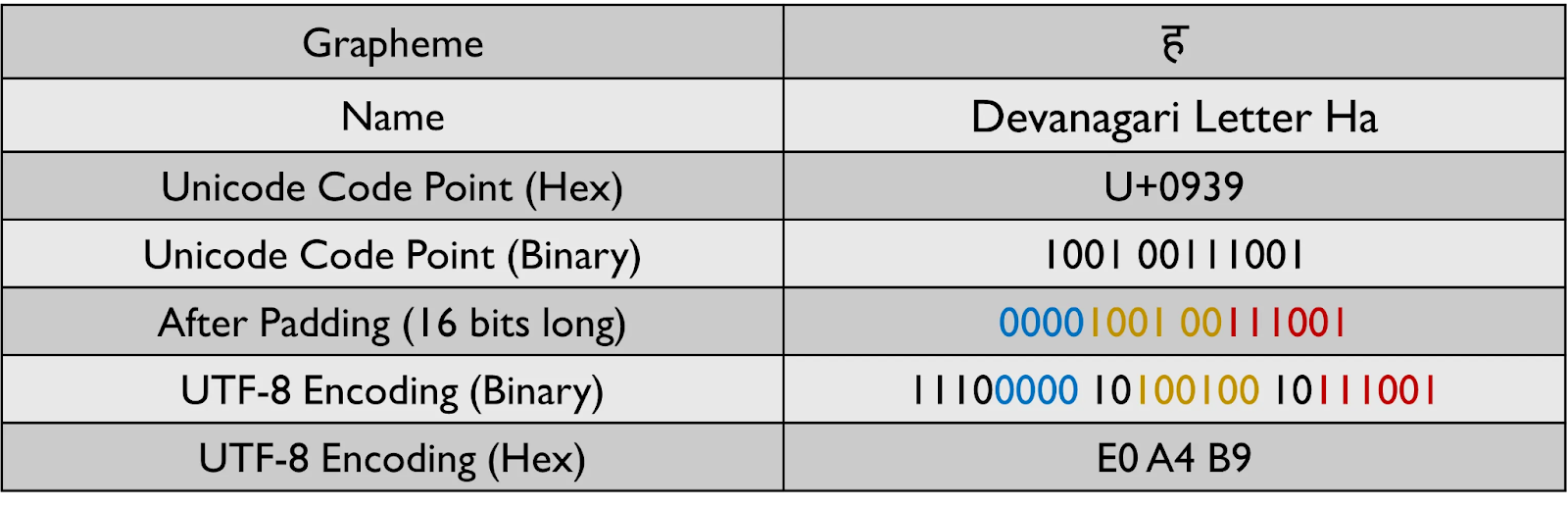
UTF-8에서는 8개의 연속된 0이 나타나는 경우가 없기 때문에, 데이터 전송 중에 예기치 않게 전송이 종료되는 문제를 걱정할 필요가 없습니다. 또한 영어에서 사용되는 라틴 문자같이 일반적으로 사용되는 대부분의 문자가 1바이트로 표현될 수 있기 때문에, UTF-8은 UTF-16이나 UTF-32보다 훨씬 더 공간 효율적입니다.
Unicode 인식 함수
파이썬 2로 만든 코드를 보십시오.
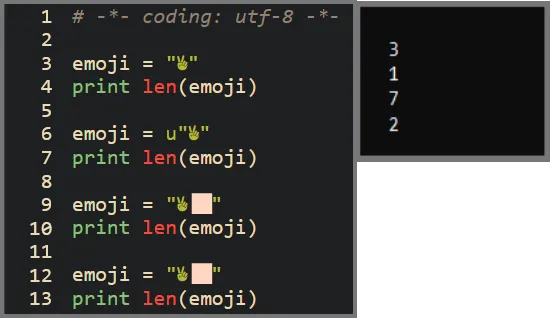
기본적으로 len 함수는 문자열에 포함된 바이트 수를 반환합니다. 예를 들어, 첫 번째 사례에서는 문자열의 바이트 수가 3이지만 실제 코드 포인트의 개수는 1입니다. 문자열의 바이트를 직접 다루는 이러한 함수들을 유니코드 비인식 함수라고 부릅니다. 유니코드에 대해 len 함수가 코드 포인트 수를 반환하도록 하려면, 문자열 앞에 u 접두어를 추가해야 합니다. 이렇게 하면 len 함수가 예상대로 동작하여 문자열에 포함된 코드 포인트의 개수를 반환합니다. 두 번째 사례에서는 이 방법으로 len 함수가 정확히 동작하는 것을 보여줍니다.
마지막 두 예제는 색상 수정자와 승리 이모지를 함께 나타냅니다. 단일 자소지만 제 터미널에서는 두 개의 자소로 표현되죠. 유니코드 비인식 함수를 사용할 경우 7이라는 결과를 얻습니다. 승리 이모지와 색상 수정자는 각각 3바이트와 4바이트로 표현되죠. 유니코드 인식 함수를 사용할 경우 문자열에 나타난 대로 2라는 결과를 얻게 됩니다.
BOM (Byte Order Mark)
BOM은 유니코드 문자 U+FEFF의 특별한 사용 사례입니다. 이 문자는 유니코드 표준에서 "폭 없는 비분리 공백"이라고 불립니다. BOM은 유니코드로 인코딩된 데이터 스트림의 시작 부분에 위치하며 해당 스트림에 대한 유용한 정보를 제공할 수 있습니다.
BOM은 주로 UTF-16 및 UTF-32에서 데이터의 엔디언을 나타내는 데 사용됩니다. BOM이 존재하면 해당 데이터가 유니코드를 사용하고 있음을 어느 정도 확신할 수 있으며 사용된 유니코드 인코딩 방식의 종류를 식별하는 데도 활용될 수 있습니다.
엔디언은 컴퓨터 과학에서 데이터 바이트가 메모리에 저장되는 순서를 나타내는 용어입니다. 엔디언은 빅 엔디언과 리틀 엔디언으로 구분됩니다. 엔디언 개념은 UTF-16의 16비트 코드 유닛이나 UTF-32의 64비트 코드 유닛같이 여러 바이트로 구성된 데이터를 다룰 때 중요해 집니다. 예를 들어, 16비트 숫자 12345(16진수로 30 39)가 있다고 가정해 봅시다. 빅 엔디언 시스템에서는 30 39로 저장됩니다. 리틀 엔디언 시스템에서는 같은 숫자가 39 30으로 저장됩니다.
빅 엔디언과 리틀 엔디언의 선택은 종종 시스템의 특정 요구 사항에 따라 결정됩니다. 예를 들어 TCP/IP와 같은 네트워크 프로토콜은 빅 엔디언(네트워크 바이트 순서)을 사용하고, 반면에 x86이나 ARM과 같은 많은 프로세서 아키텍처는 리틀 엔디언(호스트 바이트 순서)을 사용합니다.
문자열 "¡Hello World!👍🏻"은 아래에 제시된 예제에서 입력값으로 사용되었습니다.
UTF-32
UTF-32에서는 BOM이 바이트 순서를 나타내는 데 사용됩니다. BOM 문자는 UTF-32-BE에서 00 00 FE FF로 인코딩됩니다.

UTF-32-LE에서는 BOM이 FF FE 00 00으로 인코딩됩니다. 아래 이미지에서 볼 수 있듯이, UTF-32-LE에서는 모든 자소의 인코딩이 반대로 저장됩니다.

UTF-16
마찬가지로 UTF-16에서도 BOM은 바이트 순서를 나타내는 데 사용됩니다. BOM 문자는 UTF-16-BE에서 FE FF로 인코딩됩니다.

UTF-16-LE에서는 BOM이 FF FE로 인코딩됩니다. 아래 이미지에서 볼 수 있듯이, UTF-16-LE에서는 모든 자소의 인코딩이 반대로 저장됩니다.

UTF-8
UTF-8에서는 각 자소가 8비트 코드 유닛으로 인코딩되기 때문에 BOM이 필요하지 않습니다. 또한, 유니코드 표준에서는 UTF-8에서 BOM의 사용을 권장하지 않습니다.

그러나 일부 애플리케이션에서는 UTF-8 스트림에 BOM을 추가하기도 합니다. 이 경우 BOM은 데이터 스트림이 UTF-8로 인코딩되었음을 나타내는 데 사용됩니다. UTF-8에서 BOM은 EF BB BF로 인코딩됩니다.
BOM은 ASCII만을 이해하는 소프트웨어에서 읽을 UTF-8 데이터 스트림에 사용하지 말아야 합니다. BOM은 ASCII에 존재하지 않기 때문에, 데이터를 읽는 소프트웨어가 이를 해독할 수 없습니다. 또한, 브라우저에서 표시 문제를 일으킬 수 있습니다. 예를 들어, BOM이 포함된 HTML 파일에서는 웹 페이지 시작 부분에 원하지 않는 문자가 표시될 수 있습니다.
자기 동기화 인코딩
문자 인코딩을 배우다 보면 "자기 동기화"라는 용어를 접하게 됩니다. 그렇다면 문자 인코딩이 자기 동기화된다는 것은 무엇을 의미할까요? 자기 동기화된 문자 인코딩 방식은 인코딩된 문자 스트림의 어느 지점에서든 읽기를 시작해도 각 문자가 어디에서 시작하는지 식별할 수 있어야 합니다. 예를 들어 책을 읽는 상황을 상상해 보세요. 책의 어떤 페이지를 펼치더라도 이전 내용을 몰라도 문장을 읽고(데이터를 해석하여) 이해할 수 있습니다. 자기 동기화된 문자 인코딩 방식은 이와 비슷하게 동작합니다.
이 특성은 문자 인코딩 방식을 선택할 때 중요하게 고려해야 할 요소입니다. 데이터는 전송 중 손실되거나 손상될 수 있습니다. 그러나 인코딩 방식이 자기 동기화를 지원한다면 일부 데이터가 누락되거나 손상되더라도 나머지 데이터를 이해할 수 있습니다. 이는 몇몇 페이지가 찢어진 책을 읽는 것과 유사합니다.
UTF-32
UTF-32는 바이트 수준에서 자기 동기화특성을 가집니다. 이는 모든 자소가 고정된 4바이트로 인코딩되기 때문입니다. 전송 중 오류가 발생하여 문자를 구성하는 일부 비트가 손상되거나 변경되더라도, 가장 가까운 4바이트 경계로 이동하여 다음 문자를 디코딩할 수 있습니다. UTF-32에서는 손상된 문자도 디코딩할 수 있지만 결과적으로 원래 인코딩된 문자와는 다른 문자가 나타날 수 있습니다.
즉, UTF-32는 고정 길이 인코딩 방식 덕분에 자기 동기화 특성을 가지게 됩니다. 하지만 앞서 언급했듯이 UTF-32는 공간 효율성이 떨어지기 때문에 데이터 전송에는 일반적으로 사용되지 않습니다. 대신 고정된 문자 폭이 특정 작업을 간소화할 수 있는 로컬 데이터 처리에서 주로 사용됩니다.
UTF-16
UTF-16은 16비트 코드 유닛 수준에서 자기 동기화를 지원합니다. 이는 UTF-8 및 UTF-32가 바이트 수준에서 자기 동기화를 지원하는 것과는 다릅니다.
16비트 코드 유닛 시퀀스를 읽으면 각 코드 유닛의 값을 기준으로 문자 시작점을 식별할 수 있습니다. 값이 0xD800-0xDBFF 범위에 있으면 이는 상위 서로게이트 페어입니다. 값이 0xDC00-0xDFFF 범위에 있으면 이는 하위 서로게이트 페어입니다. 두 범위에 속하지 않으면 이는 독립된 문자입니다. 전송 중 데이터가 변경되더라도 스트림을 읽을 때 16비트 코드 유닛을 확인하면 상위 서로게이트, 하위 서로게이트 또는 독립된 문자 범위를 기반으로 정확히 식별할 수 있습니다.
반면 UTF-16으로 인코딩된 바이트 시퀀스의 중간에서 8비트 단위로 읽기를 시작할 경우, 해당 바이트가 16비트 코드 유닛의 시작인지 중간인지 알 수 없습니다. 이는 데이터를 16비트 단위로 읽을 수 없는 시스템에서는 문제가 됩니다.
이로 인해 UTF-16은 UTF-8에 비해 더 취약합니다. 이는 UTF-16이 아시아 문자에서 공간 효율성이 더 나을 수 있음에도 불구하고 텍스트 데이터를 전송하고 저장하는 데 일반적으로 UTF-8이 선호되는 이유 중 하나입니다.
UTF-8
UTF-8은 바이트 수준에서 자기 동기화 특성을 가집니다. UTF-8에서는 모든 문자가 1바이트에서 4바이트로 표현됩니다. 각 문자의 첫 번째 바이트는 특정 패턴을 사용하여 해당 문자가 몇 바이트로 이루어졌는지 나타냅니다. 이 패턴 덕분에 UTF-8이 자기 동기화 인코딩 방식이 될 수 있습니다.
예를 들어, 자소 A를 생각해 봅시다. UTF-8에서는 A가 단일 바이트(01000001)로 표현됩니다. 이 바이트에서 읽기를 시작하면, 해당 바이트가 0으로 시작하기 때문에 1바이트 문자임을 알 수 있습니다.
또 다른 예로, 자소 ©를 생각해 봅시다. UTF-8에서는 ©가 2바이트(11000010 10101001)로 표현됩니다. 첫 번째 바이트에서 읽기를 시작하면 이 바이트가 110으로 시작하므로 2바이트 문자임을 알 수 있습니다. 반면 두 번째 바이트에서 읽기를 시작했다고 했을 땐 이 바이트가 10으로 시작하기 때문에 문자의 시작이 아님을 알 수 있습니다.
UTF-8로 인코딩된 데이터 시퀀스를 가정해 봅시다. 전송 중 데이터의 일부 비트가 변경되는 오류가 발생했다고 할 때, 스트림을 읽으면 오류가 발생한 바이트를 잘못 해석하게 됩니다. 그러나 다음 바이트를 읽으면 해당 바이트가 문자의 시작인지, 중간인지 쉽게 식별할 수 있습니다. 이는 각 바이트에 포함된 패턴 덕분입니다. 따라서 오류는 발생한 문자에 국한되며, 시퀀스 내 나머지 문자에는 영향을 미치지 않습니다.
이러한 특성 덕분에 UTF-8은 전송 오류에 대해 강인하며, 텍스트 데이터를 전송하고 저장하는 데 널리 사용되는 주요 이유 중 하나입니다.
마치며
이전 글에서는 문자 인코딩 개념을 설명하는 데 사용되는 몇 가지 용어를 알아보았습니다. 그런 다음, 인터넷 초기에 널리 사용되었던 두 가지 인코딩 방식인 ASCII와 확장 ASCII를 살펴보았습니다. 이후 유니코드로 넘어가 새로운 표준이 왜 필요한지 논의했습니다. 또한, 유니코드 코드 공간과 관련된 플레인과 블록같은 주제를 다뤘고, 마지막으로 UTF-32, 고정 길이 문자 인코딩 방식을 살펴보았습니다.
이번 글에서는, 가변 길이 문자 인코딩 방식인 UTF-16과 UTF-8을 다뤘습니다. 또한 유니코드 인식 함수에 대해 살펴보았고, 유니코드에서 텍스트의 엔디언을 나타내는 데 사용되는 BOM 문자에 대해 논의했습니다. 마지막으로, 자기 동기화 문자 인코딩과 외부 동기화를 필요로 하는 인코딩 방식에 비해 왜 더 우수한지에 대해 간단히 논의했습니다.
이 글이 마음에 드셨다면 다음과 같은 방법으로 응원해 주세요.
이 글에 박수 보내기 (최대 50번까지 가능)
댓글로 응원의 메시지 남기기
이 글이 유용할 것 같은 사람들과 공유하기
Source Code에서 제 글 더 보기
Subscribe to my newsletter
Read articles from 정승아 directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by