Demystifying Memory Management: From Deadlocks to Page Replacement Policies
 Aakashi Jaiswal
Aakashi Jaiswal
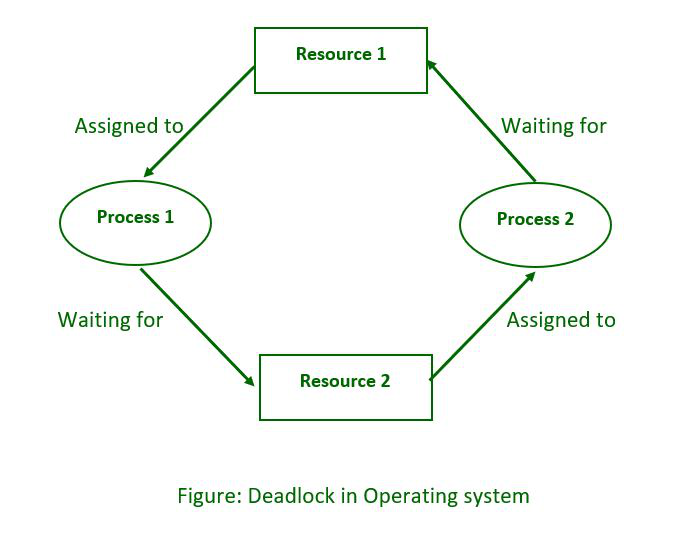
A deadlock occurs when two or more processes are stuck waiting for each other to release resources, causing them all to stop functioning. Imagine two people trying to cross a narrow bridge from opposite sides; if they both refuse to back up for the other, they will remain stuck indefinitely. In computing, this situation can significantly hinder system performance.
Deadlock Characteristics
Deadlocks are characterized by four specific conditions that must all be true for a deadlock to occur:
Mutual Exclusion: This means that at least one resource (like a printer or memory) is held in a way that only one process can use it at a time. If one process is using a resource, others must wait.
Hold and Wait: Processes that are holding resources can request additional resources without releasing what they already have. For example, if Process A is using a printer and requests access to a scanner while still holding onto the printer, it creates a potential deadlock.
No Preemption: Resources cannot be forcibly taken away from a process holding them. If Process A has the printer and is waiting for the scanner, the system cannot take the printer from Process A to give it to another process.
Circular Wait: There exists a circular chain of processes where each process is waiting for a resource held by the next process in the chain. For instance, if Process A waits for a resource held by Process B, Process B waits for one held by Process C, and Process C waits for one held by Process A, they are all deadlocked.
Deadlock Prevention
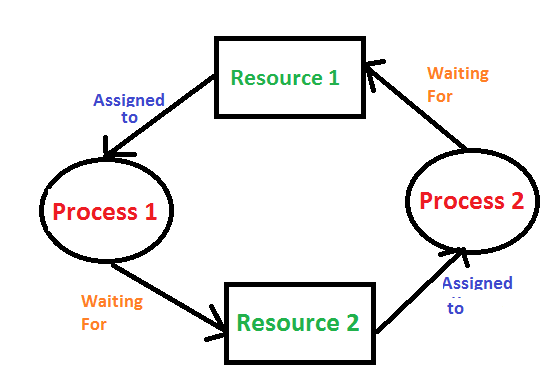
To prevent deadlocks from occurring, we can alter how resources are allocated:
Eliminate Mutual Exclusion: Whenever possible, allow resources to be shared among processes. For example, multiple processes could print simultaneously if the printer supports it.
Eliminate Hold and Wait: Require processes to request all resources they need at once instead of holding onto some while waiting for others. This way, no process holds onto resources while waiting.
Allow Preemption: If a process requests a resource that cannot be granted immediately, the system can take away some of its currently held resources (if possible) and allocate them to other processes.
Eliminate Circular Wait: Create an ordering of resources and require processes to request resources in this predefined order. This prevents cycles from forming.
Deadlock Avoidance: Banker's Algorithm

The Banker's Algorithm is a method used to avoid deadlocks by ensuring that resource allocation does not lead to an unsafe state:
The algorithm keeps track of how many resources each process might need (maximum needs) and how many they currently hold (allocated).
When a process requests resources, the system checks if granting this request would still allow all processes to complete eventually (safe state). If it would lead to an unsafe state where deadlocks could occur, the request is denied until it can be safely granted.
This proactive approach ensures that the system remains stable while allowing processes to run efficiently.
Deadlock Detection and Recovery
In computing, deadlocks can significantly hinder system performance, making it essential for operating systems to have effective mechanisms for detecting and recovering from these situations. When processes become deadlocked, they are unable to proceed because each is waiting for resources held by another process. This creates a cycle of dependencies that can halt system operations. Here’s a closer look at how deadlocks are detected and the recovery strategies used to resolve them.
Deadlock Detection Mechanisms
One of the primary methods for detecting deadlocks is through the use ofWait-for Graphs (WFG). In this graphical representation, processes are represented as nodes, and directed edges indicate resource requests between them. For example, if Process A is waiting for a resource held by Process B, an edge is drawn from A to B. If there is a cycle in this graph—meaning that you can start at one process and follow the edges to return to the same process—it indicates a deadlock situation.To confirm whether a deadlock exists, algorithms can be applied to analyze the WFG.
These algorithms check for cycles within the graph and can help identify which processes are involved in the deadlock. For instance, if three processes are waiting on each other in a circular manner, the detection algorithm will reveal this cycle, allowing the operating system to take appropriate actions.
Recovery Strategies
Once a deadlock is detected, the operating system must implement recovery strategies to restore normal operation. Here are three common approaches:
Process Termination: This strategy involves killing one or more processes involved in the deadlock. By terminating a process, its resources are released back to the system, allowing other processes to continue their execution. The choice of which process to terminate can depend on various factors such as priority levels or how long they have been running.
Resource Preemption: In this approach, the operating system temporarily takes resources away from one process and allocates them to another process that needs them more urgently. This can help break the cycle of dependencies causing the deadlock. However, preemption must be handled carefully to avoid further complications or resource starvation for processes that are preempted.
Rollback: Rollback involves restoring processes to their previous states before they entered the deadlocked condition. This method often requires maintaining checkpoints of process states so that if a deadlock occurs, the system can revert back to a known good state. This allows processes to restart their operations without being stuck indefinitely.
These recovery strategies are crucial for maintaining system stability and ensuring that resources are utilized efficiently even in the face of potential deadlocks. By implementing effective detection mechanisms and recovery methods, operating systems can minimize downtime and improve overall performance.
Memory Management
Basic Memory Management
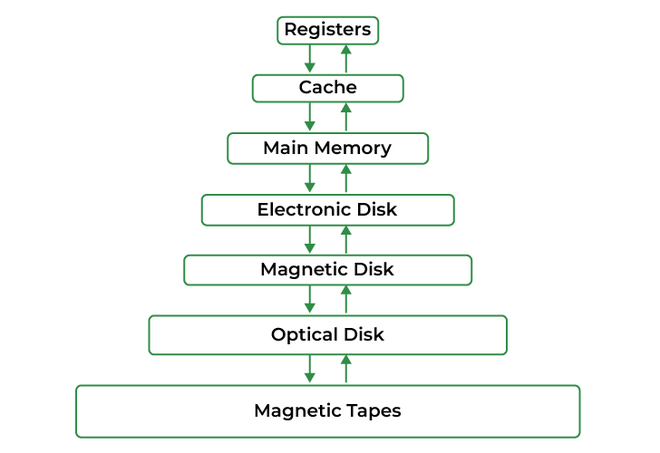
Memory management refers to how an operating system handles its memory resources—allocating space for programs when they need it and freeing that space when they’re done. Efficient memory management is crucial for overall system performance.
Logical and Physical Address Space

Logical Address: This is the address generated by the CPU during program execution. It’s what programs use when accessing memory.
Physical Address: This refers to actual locations in RAM where data resides. The operating system translates logical addresses into physical addresses so that programs can access their data properly.
This mapping allows programs to operate without needing to know where exactly in physical memory their data is stored.
Memory Allocation Strategies
Memory allocation strategies determine how memory is divided among running processes:
Contiguous Memory Allocation:
Fixed Partitioning: The operating system divides memory into fixed-sized blocks (partitions). Each block can hold one process. While this method is simple, it can lead to internal fragmentation if processes do not fully utilize their allocated space.
Variable Partitioning: Memory is allocated based on the actual needs of each process. This method can lead to external fragmentation over time as free space becomes scattered across memory.
Fragmentation Types:
Internal Fragmentation: Occurs when allocated memory blocks contain unused space because they are larger than needed.
External Fragmentation: Happens when free memory is scattered throughout; even though there may be enough total free space available, it may not be contiguous enough for larger requests.
Compaction: A technique used periodically by the operating system to eliminate fragmentation by moving processes around in memory so that free spaces become contiguous again.
Paging
Paging is an advanced memory management technique that eliminates the need for contiguous allocation:
Principle of Operation: The physical memory (RAM) is divided into fixed-size blocks called frames, while logical memory (the program's view) is divided into pages of the same size. When programs run, their pages are loaded into any available frames in RAM.
Page Allocation: Pages do not need to be loaded in contiguous blocks; they can be scattered throughout physical memory. This flexibility minimizes fragmentation issues common with contiguous allocation methods.
Hardware Support for Paging
Paging requires hardware support from components like the Memory Management Unit (MMU), which translates logical addresses into physical addresses using page tables maintained by the operating system. These tables store information about which pages are currently loaded into which frames in RAM.
Protection and Sharing
Paging allows multiple processes to share physical memory while keeping them isolated from each other. Each process has its own page table that maps its logical addresses to physical addresses securely, preventing unauthorized access between processes.
Disadvantages of Paging
While paging has many advantages, it also has some drawbacks:
Increased overhead due to managing page tables.
Performance issues may arise if many pages are accessed frequently (a situation known as thrashing), where constant loading and unloading of pages slow down overall performance.
Virtual Memory
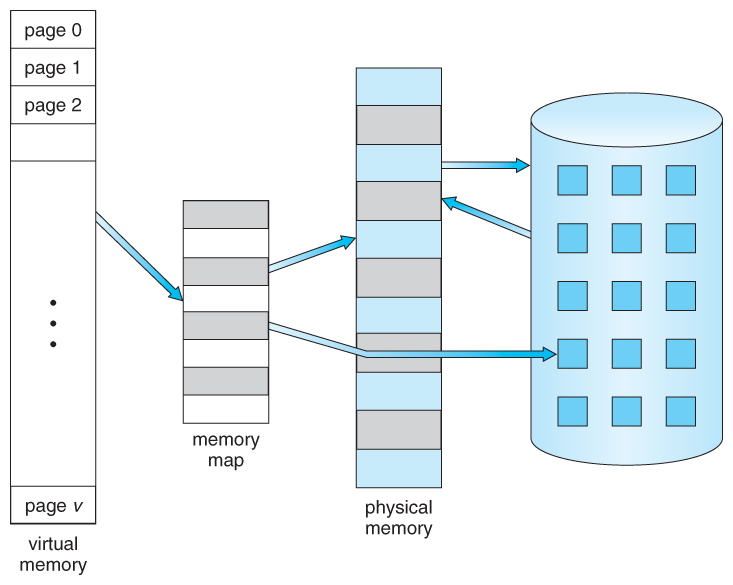
Basics of Virtual Memory
Virtual memory extends the available memory beyond what physically exists in RAM by using disk storage as an overflow area. This allows systems to run larger applications than would otherwise fit into physical RAM alone.
Hardware and Control Structures
Virtual memory relies on hardware support from components like MMUs for translating logical addresses into physical addresses via page tables. Control structures manage this translation efficiently during program execution so that applications run smoothly without interruption.
Locality of Reference
Programs tend to access only a small portion of their address space at any given time—a principle known as locality of reference. Virtual memory takes advantage of this behavior by keeping frequently accessed data in RAM while less-used data resides on disk storage until needed again.
Page Faults
A page fault occurs when a program tries to access data not currently loaded into RAM. When this happens:
The operating system pauses the program.
It locates the required page on disk.
It loads this page into RAM.
Finally, it resumes program execution with access now available.
This mechanism allows programs to use more memory than what physically exists in RAM but may introduce delays during execution when page faults occur frequently.
Working Set Model
The working set model defines which pages are actively used by a process within a specific time frame—essentially identifying which pages should remain in RAM for optimal performance. Keeping these pages resident minimizes page faults and improves efficiency during program execution.
Dirty Page/Dirty Bit
A dirty page refers to a page that has been modified but not yet written back to disk storage (the original copy). The dirty bit indicates whether a page has been modified since it was loaded into RAM; this helps optimize write operations during page replacement because only dirty pages need attention when being swapped out of RAM.
Demand Paging
Demand paging only loads pages into RAM when they are needed rather than preloading all pages at once when an application starts running. This approach conserves memory usage and improves load times since only necessary pages occupy valuable RAM space at any given moment.
Page Replacement Policies
When a computer's physical memory is full, it cannot accommodate new pages that need to be loaded. This is wherepage replacement policiescome into play. These policies determine which existing pages should be evicted to make room for new ones. Here’s a closer look at some of the most commonly used page replacement policies:
Optimal (OPT)
TheOptimal page replacement policyis considered the best possible algorithm for managing page replacements because it minimizes the number of page faults. The principle behind this policy is straightforward: it replaces the page that will not be used for the longest time in the future.For example, suppose a program needs to load a new page, but all available frames in memory are occupied. The operating system will look ahead at the future requests and determine which of the currently loaded pages will not be needed for the longest duration.
By evicting that page, the system ensures that it is making the most efficient use of memory resources.While this policy can theoretically provide optimal performance, it is impractical in real-world scenarios because it requires future knowledge of page requests, which is not typically available. However, it serves as a benchmark against which other algorithms can be compared, providing insights into their efficiency.
First In First Out (FIFO)
The**First In First Out (FIFO)**page replacement algorithm is one of the simplest and most straightforward methods. In FIFO, pages are organized in a queue, and when a page fault occurs (meaning a requested page isn’t currently in memory), the oldest page in memory—the one that has been there the longest—is removed first.This method is akin to a line of people waiting for service; the person who has been waiting the longest gets served first.
While FIFO is easy to implement and understand, it doesn’t always lead to optimal performance. For instance, it can lead to situations where frequently accessed pages are removed simply because they were loaded earlier, which might not be efficient if those pages are still needed.
Second Chance (SC)
The**Second Chance (SC)**algorithm builds on FIFO by giving pages a "second chance" before eviction. When a page fault occurs, instead of immediately removing the oldest page, SC checks whether that page has been used recently. Each page has an associated reference bit that indicates whether it has been accessed since it was last loaded.If the oldest page has its reference bit set to 1 (indicating it has been used), it gets its bit reset to 0 and is given another chance to stay in memory.
The algorithm then moves on to check the next oldest page. If that one also has its reference bit set to 1, it too gets reset and is given another chance. This process continues until a page with a reference bit of 0 is found and evicted.This method helps improve performance by retaining frequently accessed pages while still following an orderly eviction process.
Not Recently Used (NRU)
The**Not Recently Used (NRU)**algorithm classifies pages based on their recent usage patterns and employs this classification to decide which pages should be evicted. Pages are categorized into four classes based on two bits: whether they have been referenced and whether they have been modified.
Class 0: Not referenced and not modified.
Class 1: Not referenced but modified.
Class 2: Referenced but not modified.
Class 3: Referenced and modified.
When a page fault occurs, NRU selects a victim from the lowest non-empty class. This means that pages that have not been used recently—and especially those that have not been modified—are prioritized for eviction. This approach helps ensure that frequently accessed data remains in memory while minimizing unnecessary writes back to disk.
Least Recently Used (LRU)
The**Least Recently Used (LRU)**policy operates on the assumption that pages that have not been accessed for the longest time are less likely to be needed in the near future. When a page fault occurs, LRU replaces the page that has not been accessed for the longest period.To implement LRU effectively, operating systems maintain a record of when each page was last accessed—this could involve timestamps or counters associated with each frame in memory.
When deciding which page to evict, LRU looks at these records and selects the one with the oldest access time.Although LRU can provide better performance than FIFO or SC by keeping frequently accessed pages in memory longer, its implementation can be more complex due to tracking access times or maintaining sorted lists of pages.Each of these policies offers different trade-offs between complexity and performance, making them suitable for various scenarios depending on system requirements and expected workloads. Understanding these policies helps developers optimize memory management strategies within their applications and operating systems effectively
Storage Management
File Concepts
Files represent collections of related data treated as single entities within an operating system—like documents or images stored on your computer’s hard drive or SSD:
Access Methods
Access methods define how data is read from or written to files:
Sequential Access: Data must be read or written in order; think of reading a book chapter by chapter.
Random Access: Data can be accessed directly without needing sequential reads; imagine being able to jump straight to any chapter in your book without flipping through all previous ones first.
Directory Structure
Directories organize files hierarchically within file systems—similar to folders on your computer—allowing users easy navigation through their stored files based on categories or types rather than having everything lumped together randomly.
File System Mounting
Mounting makes file systems accessible at specific points in your directory structure so users can interact with files stored across different devices seamlessly—like plugging in an external hard drive or USB stick and having its contents appear alongside your internal files automatically!
File Sharing and Protection
File sharing enables multiple users or processes access files simultaneously while protection mechanisms ensure unauthorized access is prevented through permissions settings—like who can read or edit certain documents based on user roles within an organization’s network environment!
Implementing File Systems
Implementing file systems involves managing how data gets stored on storage devices effectively:
Directory implementation defines how directories are structured and accessed so users find what they need quickly.
Allocation methods determine how files occupy space on disks—whether contiguously (all together) or through linked lists/indexes (scattered).
Free space management tracks available storage efficiently so new files can be added without wasting existing capacity unnecessarily!
Recovery mechanisms ensure data integrity during failures or crashes—like backing up important documents regularly just in case something goes wrong!
Mass Storage Structure
Overview of Mass Storage Structure
Mass storage provides long-term data retention beyond volatile memory (RAM)—think hard drives (HDDs) or solid-state drives (SSDs)—allowing users access their information even after turning off their computers!
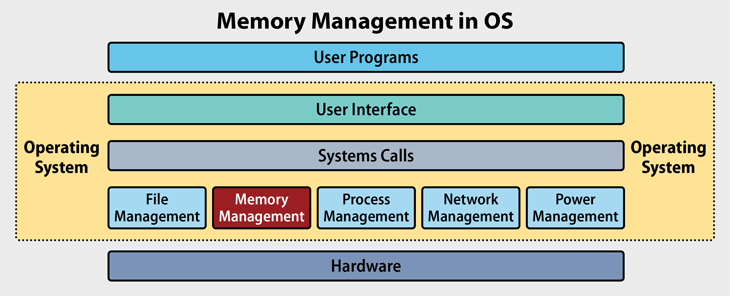
Disk Structure and Attachment
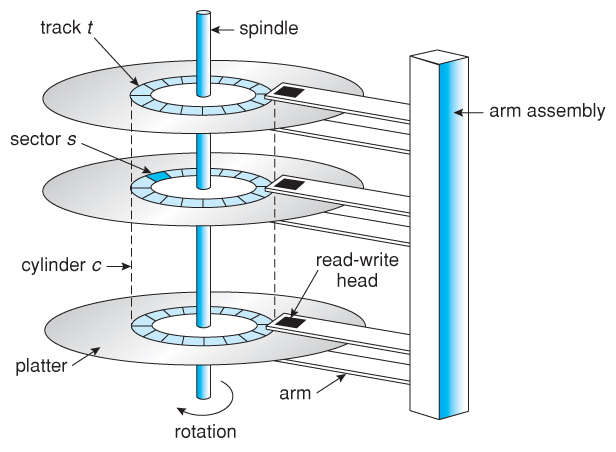
Disks organize themselves into tracks and sectors where data gets stored efficiently! Disk attachment refers specifically how these disks connect with computer systems—such as using SATA cables versus SCSI connections—which impacts performance reliability depending on what type you choose!
Disk Scheduling
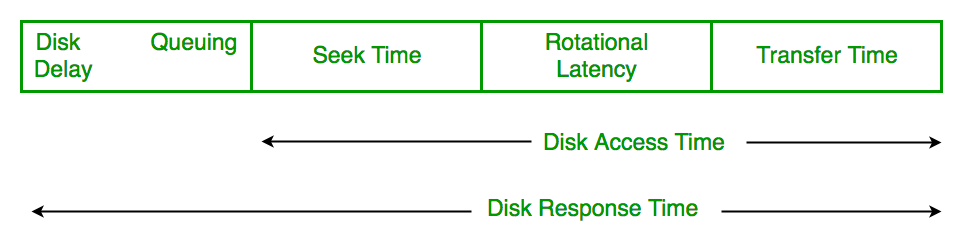
Disk scheduling algorithms optimize read/write operations by determining which requests should be handled first based on various criteria like urgency! Common algorithms include:
FCFS (First-Come First-Served): Processes requests strictly based on arrival order.
SSTF (Shortest Seek Time First): Prioritizes requests closest physically located next within disk surface area reducing overall seek times improving throughput!
Swap Space Management
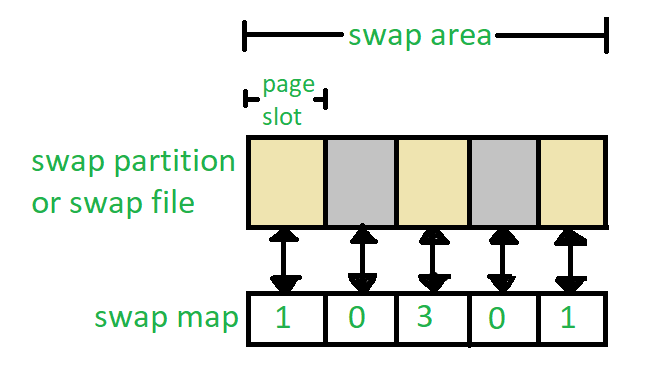
Swap space allows operating systems extend RAM using disk space as virtual memory during high load periods! This enables more applications run simultaneously without exhausting physical resources leading smoother user experiences even under heavy workloads!
RAID Structure
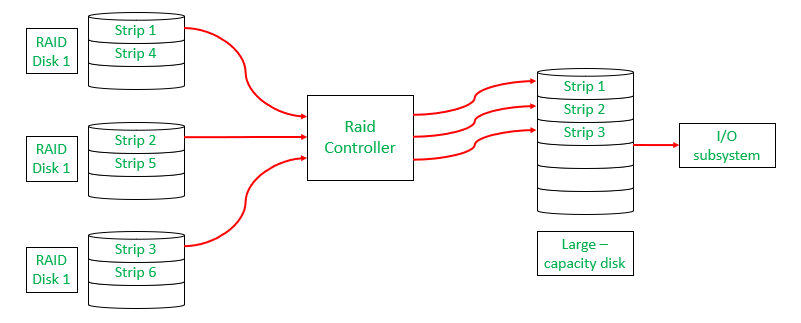
RAID stands for Redundant Array of Independent Disks—a technology combining multiple disks into single units improving performance/redundancy through configurations like RAID 0 (striping) enhancing speed but risking data loss versus RAID 1 (mirroring) ensuring redundancy protecting against failures!
Stable Storage Implementation
Stable storage ensures data integrity even during failures using techniques like journaling/replication maintaining copies critical states safeguarding against unexpected crashes ensuring users don’t lose important work unexpectedly!
Tertiary Storage Structure
Tertiary storage includes removable media such as tapes/optical disks primarily used backup archival purposes providing long-term solutions lower costs compared primary options like HDDs/SSDs making them ideal choices organizations looking retain historical information securely!
Case Study
Real-Time Operating System (RTOS)
Real-Time Operating Systems cater specifically applications requiring timely processing predictable response times! They prioritize tasks based deadlines rather than traditional scheduling methods found general-purpose OS ensuring critical functions execute reliably without delays impacting performance negatively!
iOS Architecture and Features

iOS operates Unix-based architecture optimized mobile devices! Key features include multitasking capabilities allowing background processing without draining battery life excessively alongside security enhancements sandboxing protecting user data malicious applications ensuring smooth operation across various device types!
Applications of iOS Operating System
iOS supports diverse applications ranging productivity tools document editors games leveraging user-friendly interface robust performance capabilities tailored specifically mobile environments making it popular choice users seeking seamless experiences across devices!
Unix Operating System

Unix known multiuser capabilities portability across different hardware platforms employing hierarchical file systems powerful command-line tools facilitating efficient administration tasks diverse environments enabling developers create robust applications easily adaptable various settings!
Windows Operating System
Windows OS offers extensive application support focusing user interface design allowing compatibility various software ecosystems providing robust security features user account controls regular updates enhancing overall stability keeping systems secure against threats evolving landscape technology!
Android OS
![]()
Android open-source mobile operating system based Linux supporting diverse hardware configurations offering extensive customization options through application framework making popular among developers seeking flexibility app development fostering innovation creativity across industry sectors!
This comprehensive exploration covers essential concepts related deadlocks memory management virtual storage management various operating systems architectures! Understanding these topics equips individuals foundational knowledge crucial advancing computer science software engineering fields paving way exciting careers future technological advancements!
Subscribe to my newsletter
Read articles from Aakashi Jaiswal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aakashi Jaiswal
Aakashi Jaiswal
Coder | Winter of Blockchain 2024❄️ | Web-Developer | App-Developer | UI/UX | DSA | GSSoc 2024| Freelancer | Building a Startup | Helping People learn Technology | Dancer | MERN stack developer