From Research to Production: AI Model Lifecycle in GPU Clouds
 Tanvi Ausare
Tanvi Ausare
The journey from research to scalable production in AI is complex, requiring a robust infrastructure to handle the demanding processes of training, fine-tuning, and deployment. Leveraging Cloud GPU environments provided by cutting-edge GPU Cloud Providers, such as NeevCloud, can help simplify this transition by offering scalable, high-performance computing tailored for AI workloads. This blog explores the lifecycle of AI models in GPU clouds, focusing on processes, use cases, and the advantages of AI Cloud and AI Datacenter solutions.
5 Key Stages of AI Model Lifecycle in GPU Clouds
Research and Prototyping
Defining the problem and selecting appropriate AI models.
Using pre-trained models or building architectures from scratch.
Leveraging GPU-accelerated environments for faster experimentation.
Model Training
Large-scale training on high-performance GPU Clouds.
Optimizing data pipelines for efficient computation- Optimizing data pipelines and monitoring metrics like loss and accuracy are critical components in the lifecycle of AI models, especially when deployed in GPU cloud environments. These practices significantly enhance the efficiency of computation and the overall performance of machine learning (ML) systems.
Efficiency Gains: Optimizing data pipelines ensures that data is processed quickly and accurately, reducing latency and improving throughput. This is crucial for real-time applications where timely predictions are necessary. Efficient data handling can lead to a reduction in processing time by as much as 30-50%, depending on the complexity of the tasks and the volume of data being handled.
Scalability: Cloud GPUs allow for dynamic scaling of resources, which means that optimized pipelines can efficiently utilize these resources during peak loads without significant delays. This scalability is essential for handling large datasets typical in AI applications, allowing businesses to respond swiftly to changing demands.
Monitoring metrics like loss and accuracy.
Performance Tracking: Monitoring key metrics such as loss and accuracy helps in assessing model performance over time. Continuous tracking allows teams to identify degradation in model performance early, often leading to timely interventions that can improve accuracy by 10-20% through retraining or fine-tuning.
Business Impact
The implications of these optimizations are profound for businesses:
Cost Efficiency: By reducing processing times and improving resource utilization, companies can lower operational costs associated with cloud computing. For instance, optimizing data pipelines might reduce cloud costs by up to 20-30%, as less compute time is required.
Enhanced Decision-Making: Improved accuracy and faster processing times lead to better insights from AI models, enabling more informed decision-making. This can translate into competitive advantages in areas such as customer service, fraud detection, and predictive analytics.
Increased Revenue Opportunities: Faster and more accurate models can enhance user experiences (e.g., through personalized recommendations), potentially increasing customer satisfaction and retention rates. This could drive revenue growth by 15-25%, particularly in sectors reliant on real-time data processing like e-commerce and finance.
Model Fine-Tuning
Customizing pre-trained models for specific use cases such as:-
Healthcare Applications:-
Medical Imaging: Fine-tuning models pre-trained on general image datasets can help in identifying specific medical conditions, such as detecting tumors in MRI scans or classifying types of skin lesions. For instance, a model trained on diverse medical images could be adapted to focus on a rare type of cancer with limited labeled data available.
Natural Language Processing (NLP):-
Sentiment Analysis: A pre-trained language model can be fine-tuned to analyze customer feedback or social media posts for sentiment detection, enabling businesses to gauge public opinion about their products or services.
Domain-Specific Text Generation: Fine-tuning can adapt models for generating technical documentation or legal texts, ensuring that the generated content adheres to industry-specific terminology and style
Financial Services:-
Risk Assessment: Models can be fine-tuned to analyze financial news articles or transaction data to identify potential risks or fraudulent activities, enhancing decision-making in investment strategies .
Algorithmic Trading: Pre-trained models can be adapted to predict stock price movements based on historical data and news sentiment analysis.
Manufacturing and Quality Control:-
- Defect Detection: Image recognition models can be fine-tuned to detect defects in manufacturing processes by training them on images of products with known defects, improving quality assurance efforts .
E-commerce Personalization:
- Recommendation Systems: Fine-tuning collaborative filtering models allows businesses to personalize product recommendations based on user behavior and preferences, increasing conversion rates .
Speech Recognition and Processing:
- Voice Assistants: Pre-trained speech recognition models can be fine-tuned for specific accents or dialects, improving accuracy in voice command recognition for diverse user groups.
Environmental Monitoring:
Wildlife Conservation: Models trained on general image datasets can be fine-tuned to recognize specific species from camera trap images, aiding in biodiversity monitoring efforts.
Reducing training time with transfer learning.
Leveraging tools to refine hyperparameters and improve performance.
Model Validation and Testing
Evaluating models against benchmarks and datasets.
Stress-testing models under different scenarios using GPU-powered simulations.
Ensuring robustness and fairness of predictions.
Deployment to Production
Transitioning from development to a production-ready AI Datacenter.
Ensuring scalability with containerized deployments.
Monitoring and maintaining models post-deployment.
Benefits of GPU Clouds in the AI Model Lifecycle
GPU Clouds bring unparalleled benefits throughout the AI lifecycle:
Speed: Faster training and inference due to GPU acceleration.
Scalability: Dynamically scale resources for research or production demands.
Flexibility: Support for diverse AI workloads across various industries.
Cost Efficiency: Optimize resource usage with GPU Cloud Providers like NeevCloud.
Integration: Seamless compatibility with popular ML frameworks and tools.There are several frameworks and platforms that provide seamless compatibility with popular machine learning (ML) frameworks and tools. Here are some notable examples:
1. Weights & Biases
Overview: A platform designed for tracking experiments, visualizing results, and collaborating on ML projects.
Compatibility: Integrates well with TensorFlow, PyTorch, Keras, and other frameworks.
Use Cases: Ideal for managing ML workflows, versioning datasets, and reproducing experiments.
2. Vertex AI
Overview: Google Cloud's ML platform that simplifies the process of building, deploying, and scaling ML models.
Compatibility: Works seamlessly with TensorFlow, PyTorch, and BigQuery.
Use Cases: Supports a variety of tasks including text translation and image generation.
3. Amazon SageMaker
Overview: A comprehensive service that provides tools for building, training, and deploying ML models at scale.
Compatibility: Supports popular frameworks like TensorFlow, PyTorch, and MXNet.
Use Cases: Enables users to quickly develop models for tasks such as classification and sentiment analysis.
4. TensorFlow
Overview: An open-source ML framework widely used for building deep learning models.
Compatibility: Easily integrates with various tools and libraries in the ML ecosystem.
Use Cases: Suitable for a range of applications from image recognition to natural language processing.
5. BigML
Overview: A cloud-based platform offering both supervised and unsupervised learning capabilities.
Compatibility: Supports integration with Python, Node.js, Ruby, Java, and Swift.
Use Cases: Useful for tasks like classification, regression, and clustering.
6. spaCy
Overview: An NLP library designed for efficiency and ease of use.
Compatibility: Works well with other ML frameworks and provides pre-trained models for various languages.
Use Cases: Ideal for tasks such as named entity recognition and text classification.
7. Replicate
Overview: A platform that allows users to run machine learning models in the cloud.
Compatibility: Supports various model types including those built on TensorFlow and PyTorch.
Use Cases: Useful for generating images, music, or other creative outputs using pre-trained models.
8. Run:ai
Overview: A platform focused on optimizing AI infrastructure for better resource utilization.
Compatibility: Integrates with Kubernetes and various ML frameworks.
Use Cases: Helps organizations manage their AI workloads efficiently.
These platforms provide diverse functionalities that cater to different aspects of the machine learning lifecycle, from model training to deployment and monitoring. By leveraging these tools alongside popular ML frameworks like TensorFlow and PyTorch, developers can enhance their workflows and improve the efficiency of their projects.
Training AI Models in GPU Clouds
Training AI models in GPU clouds is essential for several reasons, particularly due to the computational demands of modern machine learning (ML) and artificial intelligence (AI) applications. However, improper implementation can lead to significant risks and impacts on model performance and output.
Importance of Training AI Models in GPU Clouds
Enhanced Computational Power: GPUs are designed for parallel processing, allowing them to handle multiple computations simultaneously. This capability is crucial for training complex models that require processing vast amounts of data quickly. GPU clouds provide scalable resources that can be adjusted based on the workload, enabling faster model training and experimentation.
Cost Efficiency: Utilizing GPU clouds eliminates the need for substantial upfront investments in hardware. Organizations can access high-performance computing resources on a pay-as-you-go basis, which significantly reduces operational costs associated with maintaining physical servers.
Scalability and Flexibility: GPU clouds allow businesses to scale their computational resources up or down based on demand. This flexibility is vital for handling varying workloads, especially during peak usage times or when experimenting with different model architectures.
Accelerated Time to Market: Faster training times lead to quicker iterations and refinements of AI models, enabling companies to bring products and services to market more rapidly. This agility is crucial in competitive industries where timely innovations can determine market leadership
Dangers of Not Training Correctly in GPU Clouds
Underutilization of Resources: If not configured properly, organizations may fail to leverage the full capabilities of GPU clouds, resulting in wasted resources and increased costs without corresponding performance gains.
Model Performance Issues: Inadequate training due to insufficient computational power can lead to poorly performing models. For example, models that are not trained long enough or with enough data may suffer from overfitting or underfitting, resulting in inaccurate predictions and insights.
Data Security Risks: Mismanagement of cloud resources can expose sensitive data to security vulnerabilities. Without proper security measures, data breaches could occur, leading to significant financial and reputational damage.
Increased Latency: Inefficient configurations can cause delays in processing time, leading to slower inference speeds when deploying models in real-time applications. This latency can negatively impact user experience and satisfaction
Impact on Output
Accuracy and Reliability: Models trained incorrectly may produce unreliable outputs, affecting decision-making processes across various applications such as healthcare diagnostics or financial forecasting. For instance, a poorly trained model might misclassify images or provide inaccurate sentiment analysis results.
Business Outcomes: The overall effectiveness of AI solutions directly influences business performance. Inaccurate models can lead to misguided strategies, lost revenue opportunities, and diminished customer trust. For example, a recommendation system that fails to accurately predict user preferences could lead to decreased sales and customer dissatisfaction.
Innovation Stagnation: If organizations do not effectively utilize GPU cloud capabilities for AI training, they risk stagnating in innovation compared to competitors who harness these technologies properly. This could result in missed opportunities for developing new products or improving existing services
Hence, while training AI models in GPU clouds offers significant advantages such as enhanced performance and cost efficiency, failing to implement this process correctly can lead to serious drawbacks. These include reduced model accuracy, increased operational costs, security risks, and ultimately negative impacts on business outcomes. Training is the cornerstone of the AI model lifecycle. GPU Clouds accelerate training through parallel processing and optimized workflows. Key steps in training include:
1. Data Preparation
Preprocessing: Cleaning and normalizing datasets.
Data Augmentation: Enhancing data variety to improve model generalization.
Dataset Storage: Utilizing AI Datacenters to store and retrieve large datasets efficiently.Data centers are increasingly adopting advanced storage solutions like WEKA.io, DDN (DataDirect Networks), and VAST Data to enhance their data management capabilities. These platforms provide high-performance, scalable storage options that are particularly suited for modern workloads, including big data analytics, AI/ML training, and high-performance computing (HPC).
2. Training Model Architecture
Select frameworks like TensorFlow, PyTorch, or JAX optimized for GPUs.
Implement distributed training for large-scale models across multiple GPUs.
Utilize mixed precision training to balance performance and computational efficiency.
3. Monitoring Training Performance
Use GPU-accelerated tools to visualize loss curves, accuracy metrics, and hardware utilization.
Employ hyperparameter optimization techniques like grid search or Bayesian optimization.
Training model architectures in machine learning (ML) is crucial for achieving optimal performance and computational efficiency. Here are some key statistics and insights regarding the performance metrics and computational efficiency of various model architectures based on the search results.
Performance Metrics
Accuracy:
- A common benchmark for model performance is accuracy, with a standard threshold suggesting that an accuracy greater than 70% is considered good for many applications. Accuracy between 70% and 90% is often viewed as ideal, depending on the complexity of the task and the dataset involved
Error Metrics:
- Mean Absolute Error (MAE) and Mean Squared Error (MSE) are widely used to evaluate regression models. MSE, which penalizes larger errors more heavily, is particularly useful in contexts where outlier sensitivity is important. A lower MSE indicates better model performance; for example, an MSE of 21.89 was noted in a regression problem involving housing prices, illustrating how error metrics can provide insight into model effectiveness.
ROC-AUC:
- The area under the Receiver Operating Characteristic (ROC) curve (AUC) is another critical metric for classification tasks, with values ranging from 0 to 1. A higher AUC indicates better model performance in distinguishing between classes, with values closer to 1 representing superior predictive power.
F1 Score:
- The F1 score combines precision and recall into a single metric, providing a balance between false positives and false negatives. It is especially useful in imbalanced datasets where one class may significantly outnumber another.
Computational Efficiency
Training Time:
- The computational efficiency of a model architecture can be significantly influenced by its design. For instance, deep neural networks (DNNs) typically require more computational resources compared to simpler models like decision trees due to their complexity and the number of parameters involved.
Resource Utilization:
- Frameworks like TensorFlow and PyTorch facilitate efficient training through GPU acceleration, which can drastically reduce training times compared to CPU-only environments. This capability allows for handling large datasets and complex models effectively.
Scalability:
- Well-designed ML architectures enable scalability, allowing organizations to train models on larger datasets without a linear increase in training time or resource consumption. This is critical in modern data-driven applications where data volumes are continually growing.
Hyperparameter Tuning:
- The choice of hyperparameters can greatly affect both performance and efficiency. Techniques like grid search or random search are employed to optimize these parameters, ensuring that models achieve the best possible performance without unnecessary computational overhead
Use Case: A financial institution trains a fraud detection model using historical transaction data. By leveraging GPU Clouds, the training time reduces by 50%, enabling quicker insights into fraud patterns.
Fine-Tuning AI Models in GPU Clouds
Fine-tuning is essential for adapting pre-trained models to domain-specific applications. GPU Clouds make this process faster and more precise.
1. Transfer Learning
Fine-tune large models like GPT, ResNet, or Vision Transformers for specific tasks.
Save compute costs and time by training only the last few layers.
2. Domain-Specific Customization
Incorporate domain-specific datasets for greater accuracy.
Test performance on edge cases unique to the domain.
3. Experimentation and Iteration
Rapidly iterate on different fine-tuning approaches using GPU Cloud environments.
Automate workflows with AI Cloud orchestration tools for hyperparameter tuning.
Use Case: A healthcare provider fine-tunes a pre-trained NLP model to analyze electronic health records (EHR). GPU Cloud Providers like NeevCloud facilitate fast fine-tuning, ensuring HIPAA-compliant deployment in an AI Datacenter.
Deploying AI Models in GPU Clouds
Deployment is the final step in the lifecycle, transforming research outputs into scalable, production-ready systems. GPU Clouds provide the tools and infrastructure to streamline this process.
1. Containerized Deployments
Use container technologies like Docker and Kubernetes for scalability.
Deploy models in AI Datacenters to handle high-volume inference requests.
2. Real-Time Inference
Optimize models for low latency and high throughput using GPU acceleration.
Enable batch processing or streaming for real-time applications.
3. Monitoring and Maintenance
Utilize tools to track model performance in production environments.
Retrain and redeploy models seamlessly as data evolves.
Use Case: An e-commerce platform deploys a recommendation system in a GPU Cloud. The system processes real-time user interactions, increasing conversion rates through personalized recommendations.
Use Cases of GPU Clouds Across Industries
1. Healthcare
AI Models: Disease prediction, medical imaging analysis, EHR data processing.
GPU Cloud Role: Accelerating diagnostics and ensuring scalable deployment in hospitals.
2. Retail and E-Commerce
AI Models: Recommendation systems, inventory management, and dynamic pricing.
GPU Cloud Role: Providing real-time insights during high-traffic shopping events.
3. Financial Services
AI Models: Fraud detection, risk assessment, and algorithmic trading.
GPU Cloud Role: Ensuring quick model updates and real-time analytics for trading systems.
4. Autonomous Vehicles
AI Models: Object detection, path planning, and driver assistance systems.
GPU Cloud Role: Enabling large-scale simulations and real-time model inference.
5. Media and Entertainment
AI Models: Content recommendation, video upscaling, and voice synthesis.
GPU Cloud Role: Scaling AI-driven services for millions of concurrent users.
Transitioning from Research to Production
Transitioning AI models from research to production requires overcoming several challenges, including scalability, latency, and model retraining. GPU Clouds bridge this gap by providing:
Unified Environments: Consistent workflows from prototyping to production.
Scalable Resources: On-demand GPU scaling for diverse workloads.
Seamless Integrations: Compatibility with CI/CD pipelines for continuous deployment.
Why Choose NeevCloud for the AI Model Lifecycle?
NeevCloud offers a comprehensive suite of AI Cloud and GPU Cloud solutions designed to simplify the AI model lifecycle:
High-Performance GPUs: Access state-of-the-art GPU infrastructure for training and inference.
AI Datacenter Integration: Ensure enterprise-grade reliability and scalability.
Dedicated Support: Tailored solutions for industry-specific AI workloads.
Security and Compliance: Robust protection for sensitive data.
Case Study: An energy company used NeevCloud to deploy a predictive maintenance model for turbines. The GPU Cloud ensured real-time fault detection, reducing downtime by 30%.
Key Stages of the AI Model Lifecycle
Data Collection and Preparation:
This initial phase involves gathering relevant data, which is crucial for training AI models. The quality and quantity of data significantly impact model performance.
Model Development:
- Utilizing GPUs accelerates the training process by performing complex mathematical operations required for adjusting model parameters. This phase often involves iterative testing and refinement of algorithms to enhance accuracy.
Model Evaluation:
- After training, models are evaluated for their performance using metrics such as accuracy, precision, recall, and F1 score. This step ensures that the model meets the desired standards before deployment.
Deployment:
- Once validated, models are deployed into production environments. Cloud platforms like Google Cloud and AWS offer scalable infrastructure to support real-time inference and processing demands.
Monitoring and Maintenance:
- Continuous monitoring of model performance is essential to detect issues such as model drift, where the model's accuracy diminishes over time due to changes in underlying data patterns. Regular updates are necessary to maintain effectiveness.
Statistical Insights
Market Growth: According to Credence Research Report, The global cloud GPU market is projected to grow from USD 3.17 billion in 2023 to USD 47.24 billion by 2032, reflecting a compound annual growth rate (CAGR) of 35%. This growth is driven by increasing demand for high-performance computing in AI applications across various sectors, including healthcare and finance.
GPU Utilization: GPUs are pivotal in training AI models due to their ability to perform massive parallel computations efficiently. This capability drastically reduces training times compared to traditional CPUs, enabling faster iterations and deployment of AI solutions
Cost Efficiency: Cloud-based GPU solutions provide significant cost advantages by allowing organizations to scale resources according to demand without the high upfront costs associated with on-premises hardware
Graphical Representation
Below is a conceptual graph illustrating the projected growth of the cloud GPU market over the next decade:
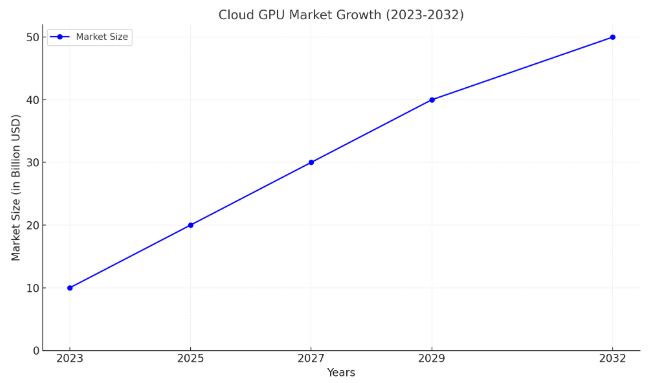
Here is the proper graph showing the Cloud GPU Market Growth (2023-2032). Let me know if you need any modifications or further details!
Conclusion
From research to production, the lifecycle of AI models is a dynamic process that demands robust infrastructure and optimized workflows. GPU Clouds simplify this journey, offering unparalleled speed, scalability, and flexibility. NeevCloud empowers businesses to harness the power of GPU Clouds, seamlessly transitioning AI models from the lab to the real world.
The AI model lifecycle in GPU clouds is a complex yet structured process that requires careful management at each stage. The significant growth projected for the cloud GPU market indicates a robust demand for these technologies as organizations increasingly adopt AI solutions across various industries. By leveraging advanced GPU architectures, businesses can enhance their AI capabilities while ensuring scalability and cost-effectiveness throughout the model lifecycle.
Embrace the future of AI with NeevCloud—your partner in AI innovation.
Subscribe to my newsletter
Read articles from Tanvi Ausare directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by