Rise of XG Boost : Tree Trimming Tales
 Parth
Parth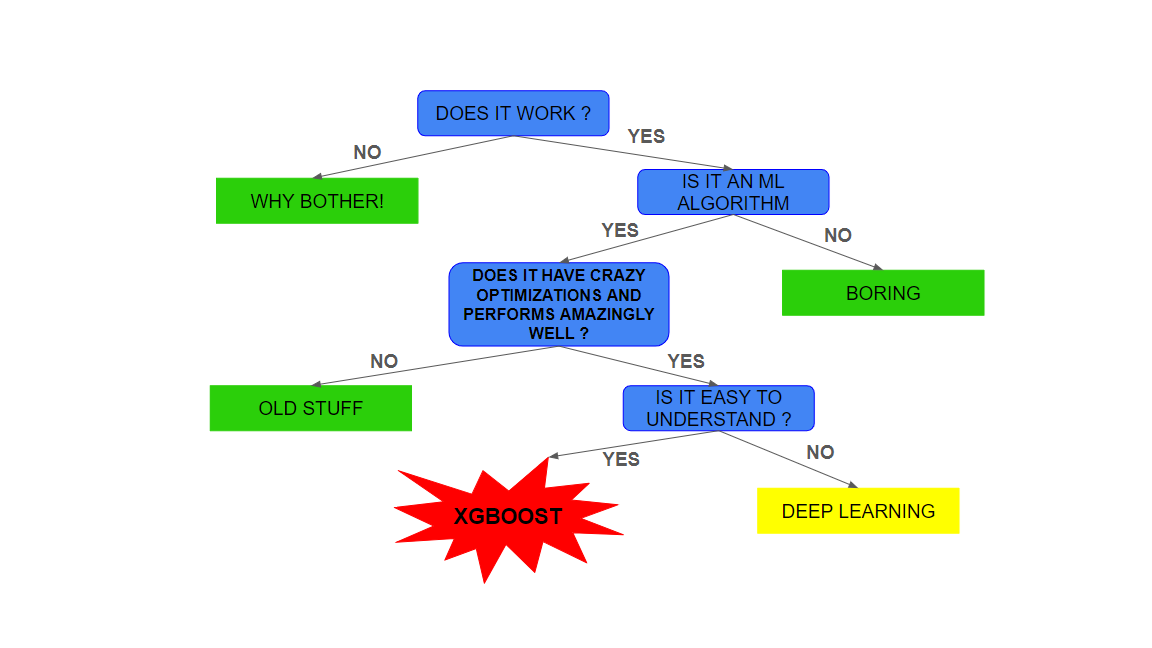
The world of Machine Learning has been developing for quite some time now , but one of the major breakthroughs in this dynamic field was the invention of XGBoost . The birth of Gradient boosting took place in 1999-2000 which starting the chain reaction of research in ML algorithms , which almost peaked in 2014 when the XGBoost Algorithm was first introduced.
XGBoost which stands for eXtreme Gradient Boost is an enhancement of the Gradient Boosting algorithms with different techniques.
What has XGBoost done ?
XGBoost is the king of performance . It has become the go to Algorithm used by Data Scientists and ML enthusiasts for any large data processing and prediction . It is not only designed for Prediction but can also be modelled to classification.
It has been used extensively in Kaggle competitions and Hackathons . XGBoost has been used in a large proportion of winning solutions in competitions. Its efficiency and ability to handle large datasets with high performance have made it a favorite choice for data scientists aiming for top rankings.
Since it works very well on large ordered data it’s used very widely in industry uses such as fraud detection , recommender system etc. It’s way more explainable n reversible than neural networks . It gives you full control over the hyperparameters and the hyperparameter is rather logical due to the high explainability .
The XGBoost framework is also highly optimized with it’s parallelized tree construction and optimized memory usage make it highly scalable , decreasing training time while maintaining the same accuracy.
XGBoost workflow and it’s intuition
XGBoost works in a way of modified Gradient Boosting .
Understanding Gradient Boosting
Let's first understand how gradient boosting works:
Build a base model
We start by building a base model that gives us initial predictions.Calculate residuals (errors)
Using the base model, we make predictions and compute the residuals (errors) based on those predictions.Assign higher weights to errors
The model assigns higher weights to predictions with larger errors, forcing the model to focus on correcting the predictions with the highest errors in the current iteration.
Build a decision tree
Using the residuals and the assigned weights, we construct a decision tree (or regression tree). This tree attempts to correct the errors from the previous model.Update the base model
Multiply the predictions from the decision tree by a constant learning rate and add them to the predictions of the base model.
Repeat the process
The process is repeated iteratively, improving the model by correcting errors at each step.

The intuition behind this process is to first create a weak learner , then create a learner which is at least as good as the previous learner but takes in accounts the errors made by the previous learner and now train itself to accommodate those errors.
This process in itself is very accurate and has high predictability but now let’s have a look as to how XGBoost further puts the X factor in this technique .
Building unique regression or classification trees :
In XGBoost we create much more particular and unique trees and prune them for regularization . We create similarity scores for different residuals and make branches based on the thresholds which give us higher similarity scores . Then we use our regularization parameters to prune those branches of the decision trees which are giving very high gain in similarity scores . These high similarity scores are a result of overfitting and tree pruning reduces this overfitting.
Mathematically the tree is build to reduce this function , the first part is the chosen loss function and the other part is what regularizes the tree ,
$$\mathcal{L}(\phi) = \sum_i l(\hat{y}_i, y_i) + \sum_k \Omega(f_k)$$
$$\text{where } \Omega(f) = \gamma T + \frac{1}{2} \lambda \|w\|^2$$
Greedy Splitting :
The tree splitting is governed exactly by a greedy approach . However there is still scope of optimization , exact greedy algorithm is difficult due it’s high memory complexity , so when working with larger data sets we use an Approximate Greedy Algorithm that reduces the memory complexity while still having a decent accuracy.
Weighted Quantile Sketch :
In XGBoost, the weighted quantile sketch algorithm is a specialized technique used to handle feature quantiles when building decision trees, especially for sparse or weighted datasets. Its main purpose is to efficiently find approximate split points (thresholds) in large datasets for decision tree nodes while considering the importance (weight) of data points. This algorithm is particularly useful when working with distributed data or data with imbalanced or weighted samples.
Sparsity-Aware Finding :
In many real life data sets we have missing values , To cater to this problem XGBoost adds a default direction for each node which is followed when a sparse point is encountered.
System design for XGBoost
XGBoost stores the information in a block based fashion , this helps in parallelizing the process .
Another optimization for split finding is Cache awareness Access .It is about structuring memory operations and data layout in such a way that it maximizes the use of the CPU cache, minimizing expensive memory accesses.
Plug and Play Power of XGBoost
XGBoost is not fancy thing but it’s rather simple to implement and understand . We will have a look at it’s Plug and Play Power through an example.
Let’s consider an example of predicting house prices based on various features. Here’s how you can train an XGBoost regression model:
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Load your dataset (X and y)
X, y = load_dataset()
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create DMatrix for XGBoost
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# Define the parameters for XGBoost
params = {
'objective': 'reg:squarederror',
'eval_metric': 'rmse',
'max_depth': 5,
'eta': 0.1,
'subsample': 0.8,
'colsample_bytree': 0.8
'gamma' : 2
}
# Train the XGBoost model
num_rounds = 100
model = xgb.train(params, dtrain, num_rounds)
# Make predictions on the test set
y_pred = model.predict(dtest)
# Evaluate the model
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
One can see how minimal efforts are required to implement this algorithm and the tuning is also rather fast and straight forward.
As you can see the xgboost framework gives you complete control over the hyperparameters . Due to the high explainability of XGBoost it’s very logical to tune these hyper parameters , for instance max_depth denotes the maximum depth of tree we know that the deeper the tree is the better it captures the particular data but leads to overfitting on the other hand if you build a tree too small it would not give any useful splits . So we can intuitively think that the best max_depth would be a value not too big and not too small , and it’s graph with respect to error would give us a U shaped graph which will have a minima somewhere in the middle .
Comparison metric
XGBoost outperforms other models in a lot of scenarios . We would take a particular study( link ) in which different machine learning algorithms have been applied to predict the behavior of the wind and, consequently, the produced power. The wind features studied here are the active power generated by the turbine, the wind speed, and the wind direction.
The forecasting algorithms used are gradient boosting (XGBoost), Support Vector Regression (SVR), Gaussian Process Regression (GPR) and neural networks (NN) models, being the best results for the chosen features obtained with XGBoost. That is, XGBoost is a good tool for forecasting.
Following are the metrics of the comparison
Table 1: Comparison between the algorithms results for Active Power
| Algorithm | Best RMSE | R2 |
| XGBoost | 482.4018 | 0.8646 |
| GPR | 487.8276 | 0.8616 |
| SVR | 497.8148 | 0.8558 |
| MLP | 529.3002 | 0.837 |
Table 2: Comparison between the algorithms results for Wind Speed
| Algorithm | Best RMSE | R2 |
| XGBoost | 1.4363 | 0.8655 |
| GPR | 1.4402 | 0.8648 |
| SVR | 1.4907 | 0.8551 |
| MLP | 1.6242 | 0.8281 |
Table 3: Comparison between the algorithms results for Wind Direction
| Algorithm | Best RMSE | R2 |
| XGBoost | 44.3778 | 0.7266 |
| GPR | 45.8228 | 0.7085 |
| SVR | 46.9885 | 0.6939 |
| MLP | 46.9521 | 0.6939 |
Conclusion
We saw the workflow of an XGBoost algorithm and can claim the high explainibility of the algorithm and in turn just see that why it works so well . XGBoost caters to all the problems the original gradient boosting had by some crazy cool optimizations .
It has revolutionized the field of ML and Data Science , and has become everyone’s go to algorithm . Even after so much research in such large models XGBoost outperforms most of them due to it’s optimised and clever approach.
For further readings you can try ,
https://arxiv.org/pdf/1603.02754 For the in depth math and optimisations of the algorithm.
https://www.kaggle.com/code/dansbecker/xgboost To have a look on the practical coding and tuning aspects of algorithm.
https://xgboost.readthedocs.io/en/latest/ The XGBoost docs , this one just seems obvious for random look ups.
Subscribe to my newsletter
Read articles from Parth directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by