Datacenter AI di rumah sendiri menjalankan LLM Lokal ala ChatGPT
 Affan Basalamah
Affan BasalamahTL;DR, apaan lagi ini?
Datacenter yang saya bikin di rumah kemarin itu bertransformasi menjadi datacenter AI, dengan menambahkan card GPU dan aplikasi LLM (seperti ChatGPT) yang berjalan di atas server sendiri.
Background Story
Gara-gara sering lihat posting orang bikin homelab untuk bikin local self-hosted LLM, basically bikin chatGPT lokal di rumah sendiri, saya lihat ini menarik juga. Di satu sisi, saya memerlukan update knowledge tentang teknologi AI, dan bagi seorang system administrator, saya ingin memiliki pengetahuan tentang bagaimana dasar-dasar aplikasi AI di dalam datacenter, apa aplikasi yang berjalan dan keperluannya, bagaimana kriteria hardware GPU yang diperlukan, bagaimana setup aplikasi yang umum dipakai untuk LLM lokal ini, dan banyak lagi.
Tapi pada dasarnya, semua perusahaan teknologi di dunia saat ini menjadi keranjingan dengan AI, karena merasakan mereka akan tertinggal tren teknologi terbaru ini kalau tidak segera berinovasi memanfaatkan atau menambahkan fitur AI dalam produk mereka, apalagi dengan kemunculan teknologi LLM (Large Language Model) seperti ChatGPT dari OpenAI. Gambar di bawah ini mestinya cukup mewakili pandangan perusahaan teknologi saat ini.

Kalau mau dilihat lebih serius, bagi network engineer seperti saya, saya juga perlu mengetahui tren terakhir tentang bagaimana teknologi AI datacenter ini. Tantangan nya apa sih? Secara ringkas cukup banyak ya:
Pengolahan data AI di server dilakukan di dalam GPU, dan untuk memperbesar skala pengolahan data ini, GPU-GPU di masing-masing server ini perlu digabungkan. Masalahnya, data yang akan dipertukarkan dalam sebuah cluster GPU di antara server-server ini sebesar apa? dan harus secepat apa? Data training ini berada dalam memori dari GPU, artinya network yang dipakai haruslah network high bandwidth low latency, sehingga port 100GE di satu server itu di dunia datacenter AI itu masih dihitung biasa aja, musti naik kelas ke 400GE, bahkan saat ini network switch bagi datacenter AI sudah mendukung network 800GE.
Pada saat ini, interkoneksi clustering pada datacenter AI ini sebenarnya mirip dengan interkoneksi clustering yang dikerjakan pada datacenter pada superkomputer yang dimiliki oleh lembaga penelitian di dunia, yang cukup sering mempublikasikan sistem yang dia bangun pada situs TOP500, merinci siapa saja pemilik superkomputer tercepat di dunia (daftar terkini bisa dilihat di sini). Teknologi interkoneksi itu adalah InfiniBand, dan penguasa teknologi InfiniBand di dunia teknologi superkomputer ini sejak lama adalah perusahaan bernama Mellanox, yang jeniusnya oleh NVidia diakusisi di tahun 2019. Sehingga NVidia saat ini menjadi pemilik teknologi GPU yang paling powerful, serta teknologi interkoneksi GPU yang paling powerful. Kekuatan NVidia di dunia interkoneksi cluster ini coba diimbangi oleh perusahaan teknologi lainnya yang menggabungkan diri dalam konsorsium UEC (Ultra Ethernet Consortium), yang bertujuan untuk mengangkat standar teknologi Ethernet yang sudah ada menjadi teknologi yang memiliki kemampuan yang setara dengan InfiniBand sehingga dapat dipakai sebagai teknologi interkoneksi cluster tanpa bergantung pada satu perusahaan seperti NVidia
Kalau bikin interkoneksi clustering datacenter AI dalam 1 rack, 3 rack, 1 row (5 rack) di datacenter mungkin masih cukup trivial, tapi bagaimana dengan interkoneksi dari satu datacenter yang terdiri dari 1000 atau bahkan 10.000 server? Muncul berbagai masalah dengan topologi apa yang dipakai, bagaimana dampak terhadap latensi, dan segala macam permasalahan yang timbul? Saya melihat ini topik yang cukup menarik, dan di LinkedIn ada narasumber bernama Sharada Yeluri dari Juniper Networks yang sering menulis artikel teknis tentang apa permasalahan yang dihadapi dalam membangun cluster datacenter AI, ini contoh tulisannya yang saya temukan (di APNIC Blog):
Tiga tulisan di atas tadi juga ada versi video YouTube nya, membahas tentang perkembangan terakhir bagaimana network dibangun untuk mendukung AI datacenter, silakan dilihat di bawah ini:
Pada akhirnya saya tetap harus memiliki pengetahuan praktis tentang AI workload di datacenter, dan hanya dengan modal server yang sudah ada, saya ingin mencoba menambah pengetahuan tentang apa itu AI workload yang saat ini ramai dibicarakan, dan lebih baik kalau bisa saya coba dengan menjalankan aplikasi AI di server sendiri.
Sedikit tentang LLM
LLM (Large Language Model) adalah teknologi yang mendasari aplikasi AI paling populer saat ini, yaitu ChatGPT dan aplikasi sejenis. Ia merupakan hasil dari model training AI dari berbagai data di Internet, kemudian model tadi dijadikan sebagai inferencing atau bahan jawaban dari pertanyaan yang ditanyakan oleh user.
Pada dasarnya ada dua macam proses AI, yaitu:
AI model training
AI model inferencing
Pada dasarnya AI model training adalah pembuatan sebuah model AI dengan menggunakan berbagai data dsb. Ini proses yang paling intensif yang berjalan di atas datacenter AI, di mana data akan dimasukkan dan dioleh oleh server yang menggunakan GPU berkapasitas besar yang berada di dalam sebuah cluster terinterkoneksi, sehingga sekian banyak GPU dalam server tadi akan menjadi sebuah GPU raksasa, dan akhirnya membuat model AI yang diinginkan. Model AI memiliki ukuran parameter, mulai dari model berukuran kecil di angka 1 sd 7 milyar parameter (1-7B), berukuran menengah di angka 70B parameter, dan model berukuran besar di angka 400B parameter.
Besar kecilnya ukuran model ini akan dikonsumsi oleh proses AI kedua, yaitu AI model inferencing, yaitu model yang sudah ada akan dipakai oleh GPU untuk menjalankan aplikasi AI, salah satunya adalah LLM ini. Model yang kecil dapat dipakai untuk server berukuran kecil dengan GPU memori rendah yang ditempatkan di tempat spesifik dengan batasan konsumsi daya, seperti pada Edge computing, sementara model berukuran raksasa diletakkan di datacenter raksasa dan menjalankan aplikasi LLM milik perusahaan besar, seperti OpenAI ChatGPT, Claude, xAI Grok, Google Gemini, Microsoft Copilot, dan sebagainya.
Yang akan saya kerjakan di sini adalah menggunakan GPU daya rendah sebagai alat AI model inferencing bagi aplikasi LLM yang berjalan di lokal. Aplikasi LLM lokal yang saya pakai bernama Ollama, dan frontend GUI nya bernama OpenWebUI, untuk bikin LLM kita tampangnya mirip-mirip ChatGPT.
Kalau mau menjalankan AI model training, jelas nggak pakai server rumahan seperti saya ini. Bisa sih, tapi selesainya entah berapa bulan atau bahkan berapa tahun.
Tambahan Hardware berupa GPU
Tentu saja untuk menjalankan aplikasi AI di datacenter memerlukan tambahan hardware berupa GPU (Graphical Processing Unit). Dulunya GPU dikenal sebagai alat tambahan di komputer yang dipakai untuk memainkan game dengan kompleksitas dan resolusi tinggi, namun sekarang GPU, terutama yang dibuat oleh perusahaan NVidia, dikenal sebagai alat untuk mempercepat proses komputasi aplikasi AI.
Setelah saya survey, dengan berbagai faktor yang saya akan jelaskan di bawah ini, maka saya memilih GPU NVidia Tesla P4 (datasheet). Mengapa GPU NVidia Tesla P4 ini yang dipilih?
Beberapa hal yang mendasari penggunaan Tesla P4 ini adalah:
Kemampuan: Tesla P4 memiliki berbagai kapabilitas sebagai GPU Datacenter untuk keperluan AI, dan salah satu yang terpenting adalah memori GPU sebesar 8GB yang cukup baik dipakai untuk aplikasi AI yang basic. Selain itu dari review di YouTube, dia juga cukup perform untuk dipakai bermain game dengan FPS yang tidak rendah, serta dapat dipakai sebagai alat bantu aplikasi home video streaming seperti Jellyfin untuk melakukan transcoding bagi video yang disajikan ke user.
Batasan sistem yang ada: GPU ini akan dipasang di datacenter rumah saya, di server Dell R730xd, yang saya inginkan untuk tidak mengkonsumsi terlalu banyak resource. Secara umum, GPU NVidia mengkonsumsi daya sebesar 150-350W, dan hanya beberapa GPU yang didesain NVidia untuk dipasang pada server dengan power dan cooling yang terbatas, salah satunya ya Tesla P4 ini. Dia hanya mengkonsumsi daya sebesar 75W, sehingga dia cukup menggunakan power dari bus PCI Express tanpa perlu menggunakan kabel power tambahan dari server. Ukurannya juga single width, jadi nggak tebal.
Batasan capex/resource: Saya kebetulan hanya memiliki sedikit kelebihan penghasilan sehingga bisa bikin datacenter di dalam rumah. Saya kebetulan nggak punya uang yang cukup untuk bikin Jensen Huang (CEO NVidia) bisa saya ajak makan gultik di warung kaki lima di Blok M Jakarta karena GPU nya saya beli sekian banyak. Saya juga bukan Elon Musk (CEO X.com) dan Larry Ellison (CEO Oracle) yang mengajak Jensen Huang makan malam dan bilang, “Please take our money. Please take our money. By the way, I got dinner. No, no, take more of it.” (Link) . Bahkan untuk beli GPU generasi di atas Tesla P4 ini, yaitu RTX A2000 yang 4 kali lebih mahal, dan A16 yang harganya lebih mahal daripada servernya itu sendiri. Ini pun saya cari di toko hijau, ketemu satu seller yang jual bekas, tinggal 1 unit, ya saya coba beli aja.
Konsekuensi: beberapa teman merekomendasikan GPU Tesla P40 atau Tesla M40, agar dapat menjalankan language model yang besar, sayangnya konsumsi daya nya berada di angka 250 W, sehingga saya hanya bisa menjalankan model yang cukup basic. Mungkin kalau sudah sampai di titik tertentu, saya akan coba ganti GPU nya menjadi lebih besar dari yang sekarang.
Beli GPU nya dulu
Akhirnya datang juga barangnya. Iseng saya lihat harga terdahulu ketika pertama kali ia diluncurkan di tahun 2018, harganya mencapai US$2500 bahkan melebihi angka US$4000 (Link), alhamdulillah sekarang di awal tahun 2025 ini ia bisa ditebus bekas cukup dengan harga 2,3 juta rupiah saja.
- Foto unboxing, nggak ada buku manual apa-apa, hanya GPU nya serta tambahan slot full height serta tambahan blower fan kalau dia kurang dingin. Nanti musti dilihat lagi apakah dia cukup didinginkan pakai angin semilir di dalam servernya, atau musti pakai blower lagi.






Sebagai selingan, anda sudah lihat datacenter AI nya X.com nya Elon Musk kan? Gila banget ini. Silakan lihat video YouTube nya:
-
Instalasi Fisik
Mari dipasang dulu GPU nya di server. GPU nya dipasang di riser 2 dari server, sementara di riser 3 sudah terisi SSD NVMe yang dipasang di PCIe adapter. Riser 1 nya masih kosong, belum ada risernya. Kalau nanti mau dipasang GPU lagi, ya pakai riser 2 ini, pasang yang dual width.

Instalasi software - VM, OS, dan aplikasi
Kalau GPU nya sudah dipasang dengan sukses, maka GPU ini akan terdeteksi di ESXi sebagai device PCI. Lalu kita enable fitur Passthrough agar device PCI di ESXi ini bisa dipakai oleh VM yang akan dipasang. Ada beberapa setting yang perlu di-enable juga.

Lalu kita coba bikin VM Ubuntu yang dipasangi device PCI Passthrough ini, artinya GPU di dalam server ini akan dipakai oleh satu VM aja. Dan ini bikin GPU nya nggak bisa dipakai oleh VM yang lain, nggak bisa dibagi-bagi. Kalau mau dibagi-bagi, musti dipasangi driver NVidia vGPU untuk VMware ESXi, tapi ini mbayar ya, ada trial nya sih 90 hari, tapi kalau mau aman damai, kayaknya cocok pakai Proxmox aja, karena GPU nya nanti bisa dibagi-bagi, ada trik nya.
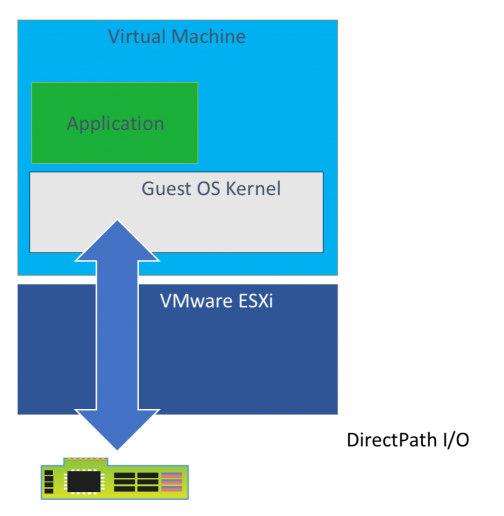
Ketika mulai bikin VM untuk device PCI Passthrough, pastikan pada pilihan Memory pilih centang “Reserve all guest memory (All locked), kalau nggak dipilih, nanti VM nya nggak bisa di Power On.

Lalu kita Add New Device, pilih PCI Device, muncul pilihan GPU yang tadi kita pilih untuk Passthrough.

Lalu di tab VM Options, ada pilihan Advanced dan Configuration Parameter, kita berikan setting tambahan di situ. Saya masih kurang faham, tapi kita tambahkan aja, yang penting jalan dulu.

Kita tambahkan setting sebagai berikut:
pciPassthru.use64bitMMIO="TRUE"pciPassthru.64bitMMIOSizeGB = "64"
Penjelasannya ada di website Broadcom VMware ini. Cara konfigurasi ini saya pelajari dari website VMware yang ini. Kalau sudah selesai, baru VM bisa bisa selesai dibikin dan bisa distart. VM nya jangan lupa dikasih ISO CD installer Ubuntu LTS terbaru (saat ini pakainya 24.04 LTS).

Install Ubuntu sih yang default aja, tapi yang pertama itu kita cek apakah GPU nya terdeteksi sebagai device PCI, caranya cek dengan perintah lspci. Kelihatan di paling bawah ada GPU NVidia Tesla P4. Alhamdulillah.

Cara menginstall driver NVidia nya nggak terlalu straighforward langsung jadi ya, ini pengalaman saya:
Download driver NVidia untuk Tesla P4 seperti ini di link NVidia Driver. Sesuaikan dengan GPU NVidia yang dipakai.

Kalau sudah dapat, download aja drivernya, lalu di-SCP ke VM Ubuntu tadi untuk diinstall.

Cara install nya ikuti petunjuk dari NVidia Driver Installation Guide. Nah lucunya di saya ini instalasi drivernya kalau ikut petunjuk ini nggak berhasil untuk install open driver nya, tapi bisa untuk install propriatery driver nya. Sudah dicoba reboot tetap nggak bisa. Bingung kan? terus gimana dong?
Akhirnya coba ikuti langkah instalasi driver NVidia di Ubuntu dengan petunjuk resmi dari Ubuntu. Ini dijalankan dengan perintah
sudo ubuntu-drivers list --gpgpumengikuti manual di https://documentation.ubuntu.com/server/how-to/graphics/install-nvidia-drivers/Abis itu install Docker Engine agar bisa jalankan aplikasinya yang sudah berbasis Docker Container. Petunjuknya cukup jelas kok, ada di website Docker Engine.
Sekalian juga install NVidia Container Toolkit, karena software Ollama dan OpenWebUI berjalan di atas container, jaga-jaga seandainya kalau dia nggak diinstall, bakal bermasalah.
Reboot
Setelah reboot, Alhamdulillah akhirnya keluar output dari nvidia-smi sebagai berikut:

Aplikasi ChatGPT Lokal - Ollama & OpenWebUI
Install nya gampang banget, jalankan perintah one liner di CLI, yang penting itu si NVidia GPU driver nya sudah terpasang dulu.
Nah, di langkah berikut ini saya katakan bahwa sistem ini saya install 2 kali:
Pertama kali hanya install Ollama saja, jadi akses ke LLM nya melalui CLI, bukan melalui GUI. Ketika saya coba install OpenWebUI setelahnya, jadi bingung kok si OpenWebUI nya nggak tahu di mana instalasi Ollama yang sudah ada. Ya sudahlah daripada pusing, saya install ulang saja.
Kali kedua install paket Ollama + OpenWebUI, baru LLM nya bisa diakses melalui GUI.
Cara pertama ini saya baca di website Ollama.com dengan perintah oneliner:
curl -fsSL https://ollama.com/install.sh | sh
Setelah itu, jalankan perintah ollama run llama3.2 yang cukup ringan, cuma 3B parameter, maka prompt LLM LLama3.2 nya akan muncul di CLI nya. Alhamdulillah akhirnya punya jadi juga punya chat bot lokal sendiri.

Kalau dilihat lagi di perintah nvidia-smi, kelihatan bahwa proses Ollama ini sudah pakai GPU, bukan pakai CPU nya si VM Ubuntu ini.

Kalau sudah bisa jalan ini, Ollama ada beberapa model LLM yang bisa dipakai, coba dilihat di https://github.com/ollama/ollama/blob/main/README.md#quickstart. Kalau mau sok kayak ChatGPT/xAI-Grok/Gemini/Claude ya jangan terlalu jumawa lah, tahu diri lah, lihat-lihat memori (VRAM) GPU yang kita pakai, mereka yang gede-gede itu pakai ratusan ribu GPU NVidia H100 di beberapa datacenter, kalau cuma 8GB di NVidia Tesla P4 sebiji segede upil ini ya pakai model yang ukurannya 7B parameter ke bawah aja.
Nah, langkah kedua, saya putuskan install ulang dari awal, sebab saya nggak ngerti gimana caranya OpenWebUI (GUI) nya ini bisa nyambung dengan Ollama yang sudah ada. Sudahlah mumpung belum terlalu jauh, install ulang aja seperti tadi, ikuti semua langkah konfigurasi VM, instalasi OS, dan instalasi driver NVidia yang diperlukan, barulah pakai oneliner dari OpenWebUI yang menggabungkan satu instalasi Ollama dengan OpenWebUI dengan support GPU NVidia, jadi sudah beres semua. Perintahnya seperti ini:
docker run -d -p 3000:8080 --gpus all -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:cuda
Lalu setelah perintah tadi selesai dijalankan, akan terpasang sebuah Docker container dari OpenWebUI. Cek dengan perintah sudo docker ps, akan muncul output seperti ini:

Bener nih sudah jalan? coba kita buka http://localhost:3000, kebetulan saya pakai Tailscale dengan domain name sendiri, akhirnya bisa kebuka juga jendela OpenWebUI nya:

Lihat di bawah, ada Get Started, maka masukkan username dan password kita sendiri sebagai admin.

Kalau sudah selesai, baru deh sudah jadi kayak ChatGPT, tapi ini jalan di lokal sendiri.

Ketika sudah jalan OpenWebUI nya, tampilan nya cukup menarik, tapi dia belum ada gunanya kalau model language nya belum dipasang. Kita musti install dulu LLM modelnya yang cocok, kalau tidak, dia cuma jadi prompt bodong aja, nggak bisa apa-apa.
Kita pilih di Cek di pilihan model LLM yang bisa dipakai, pilih yang ukurannya kecil, cukup yang 7B. Modelnya yang mana? silakan dipilih, cari yang 7B ke bawah:
| Model | Parameters | Size | Download |
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Phi 3 Mini | 3.8B | 2.3GB | ollama run phi3 |
| Gemma 2 | 2B | 1.6GB | ollama run gemma2:2b |
| Gemma 2 | 9B | 5.5GB | ollama run gemma2 |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
Cara install nya bagaimana? Klik gambar profile di kanan atas, pilih Settings. Lalu pilih Admin Settings, akan muncul pilihan Connection. Pilih pilihan Manage Ollama API Connection, ada tulisan http://localhost:11434, pilih paling kanan ada tulisan Manage.
Akan muncul pilihan Pull a Model from Ollama.com, pilih model yang dituliskan di atas, maka model tersebut akan didownload dan dipasang di OpenWebUI agar bisa dipakai. Di bawah ini contohnya saya mendownload model Mistral 7B.

Setelah dipasang, maka baru kita bisa bertanya ala ChatGPT di sini. Tapi ya karena cuma 7B, maka jawabannya singkat-singkat, nggak kayak ChatGPT yang panjang menjawab pertanyaan, maklum otaknya (GPU) cuma segitu doang. Coba dia ditanya siapa presiden Indonesia, jawabannya masih pak Jokowi. Wah payah dia, belum move on.

Sebagai pembuktian penggunaan GPU, saya coba bertanya tentang resep nasi padang dengan rendang dan dendeng batokok (kok model Mistral ini tahu dendeng batokok ya? atau ngarang-ngarang aja?), lalu cek di servernya melalui perintah nvidia-smi, ternyata dapat dilihat beberapa hal:
GPU memakan power 59W dari 75W power yang dimiliki
Penggunaan VRAM sebesar 5,6GB dari 8GB memori VRAM yang dimiliki GPU
GPU dipakai oleh PID 24905 dengan nama proses
ollama_llama_server
Karena pakai Tailscale, bisa juga dipakai di iPhone dan di iPad.


Pertanyaan imajiner dari pembaca
Saya coba menjawab beberapa pertanyaan yang muncul dari pembaca, anggap aja seperti FAQ:
GPU nya kekecilan mas, pakai yang Tesla P40 atau M40 dong? Iya euy, ternyata pakai P40 ini nggak bisa jalankan model yang agak gede, tapi ya sudahlah ini cuma belajaran dulu, nanti kalau ada server dan GPU nya lagi dicoba lagi.
Pakai yang agak bagusan dikit kek, misalnya RTX A2000 atau A16? Ya elah ini juga sama, malah lebih mahal. Kalau yang tadi P40 ama M40 masih ada second nya di toko hijau, kalau ini mah lebih mahal lagi. Boleh aja sih kalau mau minjemin.
Pakai server terpisah sendiri mas, kan lebih enak? Betul sih, masalahnya ini mau mencoba teknologi baru tanpa menambah tagihan listrik datacenter. Ini aja mau coba nambah bikin storage server juga ditunda dulu, mudah-mudahan bisa segera dibikin.
LLM yang dibikin ini lebih pintar atau lebih bodoh daripada ChatGPT? Ya jelas lebih bodoh lah, modelnya entah pakai yang berapa ratus billion parameter? Ini cuma belajar bikin aja sendiri, agar paham istilah-istilah teknologi AI yang populer dipakai.
LLM bisa dipakai buat apa aja? Kalau ini sementara buat chat percakapan sudah bisa, kalau mau generative bikin gambar AI yang aneh-aneh ada sih modelnya, tapi perlu GPU yang agak gede. Masih banyak sekali yang bisa dieksplor, saya baru sesekali buka website HuggingFace aja juga masih bengong belum mengerti.
GPU ini apa cuma dipakai LLM doang? rugi dong. Ya iya sih kalau cuma mikirnya untuk satu aplikasi. Ya ini sementara dipakai untuk hal yang agak populer sehingga kalau ditulis di blog jadi agak menarik, siapa tahu berguna buat yang mau coba-coba. Ya kalau sudah bosan ya tinggal dipakai GPU nya untuk aplikasi lain, misalnya transcoding video untuk server streaming di rumah, atau dipakai jadi game server untuk dipakai main game secara remote.
Apa berikutnya?
Kalau pingin punya LLM yang bisa menjawab agak panjang, ya otaknya dibelikan dulu yang mumpuni. Cari GPU second di toko hijau dengan spek memori VRAM 24 GB ke atas, dan disesuaikan dengan server yang dimiliki, serta berapa rupiah anda berencana menambah tagihan listrik di rumah. Semuanya disesuaikan dengan keadaan masing-masing.
Buat saya, ini saya pakai sebagai pembelajaran instalasi sistem kekinian, setidaknya saya jadi system administrator punya bayangan bagaimana bikin AI datacenter, dengan barang ini sebagai PoC (proof of concept) yang saya sesuaikan dgn budget capex dan opex yang dapat saya tanggung. Belum berani sih invest lebih besar, kecuali kalau ada pemodalnya yang mau minta saya bikinkan datacenter AI, mau bayarin saya bikin cluster GPU pakai A100, H100, atau bahkan GH200, disambung pakai InfiniBand atau Ethernet 400GE, hayuk deh saya jabanin.
Saya sadari juga bahwa pengetahuan saya tentang AI ini masih sangat-sangat cetek, masih banyak teman-teman praktisi IT di Indonesia yang punya pengetahuan jauh lebih tinggi, sudah menggunakan AI di aplikasi production dengan nilai milyaran rupiah, tapi kalau saya nggak nyoba nyemplung, ya nggak akan tahu, setidaknya ada sesuatu hal yang pernah saya kerjakan, dan bukan omon-omon aja.
Penutup
Mudah-mudahan artikel ini berguna bagi anda, saya pun juga tahu masih banyak hal yang harus dipelajari, tapi mudah-mudahan ini jadi awal untuk berangkat mempelajari teknologi baru.
Saya masih berharap banyak hal yang bisa dituliskan tentang datacenter di rumah sendiri, termasuk follow up instalasi datacenter kemarin, beberapa tambahan teknologi yang dipakai, serta berbagai aplikasi yang dapat dijalankan di atasnya.
Terima kasih, dan Wassalam.
Subscribe to my newsletter
Read articles from Affan Basalamah directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by