Is your mongoDB Analytics Slow? Here’s Why and How to Fix It
 Priyansh Khodiyar
Priyansh KhodiyarTable of contents
- Why MongoDB Slows Down For Analytics?
- Pain Points Users Face Daily
- Traditional Ways People Try to Solve This
- Enter Datazip’s OneStack: Analytics at Speed
- A Real Comparison: MongoDB vs. Datazip’s OneStack
- Benchmarks and Proof
- Connecting BI Tools (Metabase / Tableau / Superset / PowerBI / Redash) and Seeing Immediate Improvements in chart rendering times
- Running Queries Across Multiple Data Sources
- Common Errors and Myths
- When a Database (Like MongoDB) Is Better vs. When a Warehouse Is Better
- Conclusion: Move Past the MongoDB Analytics Pain
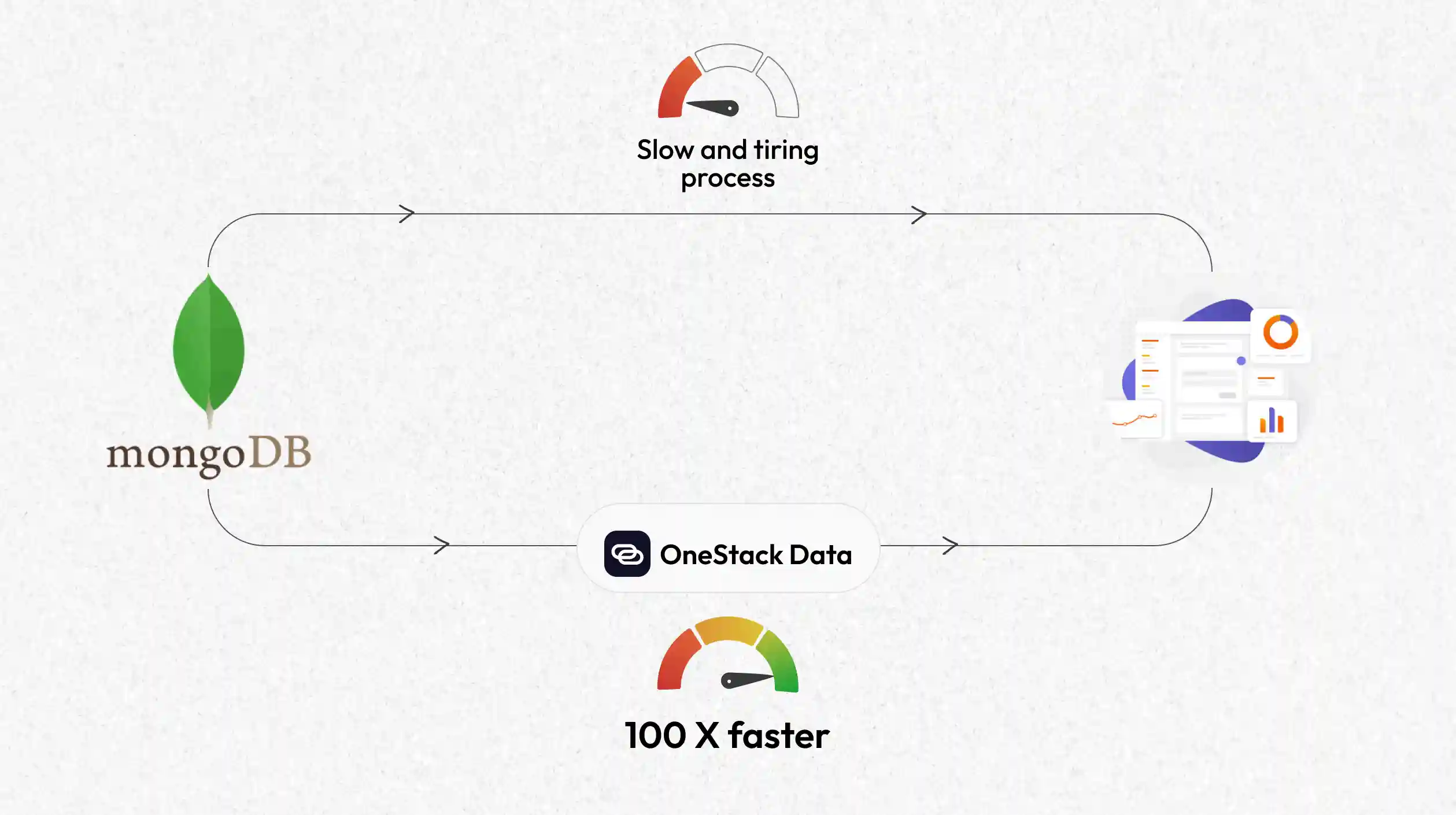
This is part of blog Series “Database to Analytics Ready Data“
If you are here, it’s likely that you’re frustrated with running analytical queries on your MongoDB analytics data.
You might have GBs to TBs of data sitting in MongoDB—user events, logs, application & transaction details, product catalogs—but every time you try a complex analytical query, it’s either painfully slow or just times out.
In this post, we’ll go beyond the surface. We’ll dissect why this happens, show what’s typically done in the market today, and explain how Datazip’s OneStack can help you run those very same queries in seconds.
Analytical queries taking hours to run.
Aggregations, multiple table lookups take forever.
Issues with real time querying of mongoDB data.
Or, Mongo memory issues (as stated by a US healthcare company using Atlas facing issues with chocked queries)
Writing queries in mongo is harder, especially because of the highly nested structure of data stores.
Urgently need flattening of
JSON / BSONmongoDB data to run time sensitive analytics query and reporting.Your manager sent you this article to read.
If any of the above mentioned issues ring a bell, you are at the right place.
We’ll also share a benchmark scenario where the same query that took over a minute on MongoDB can be executed in seconds using our platform. Let’s dive in.
Our goal is simple: Help you understand the core reasons behind slow analytics on MongoDB and guide you towards a solution that actually works.
Why MongoDB Slows Down For Analytics?
MongoDB is a NoSQL document database, primarily designed for operational workloads (think: quick inserts, flexible schemas, and supporting a large number of concurrent read/writes for a web or mobile app).
While it’s great at handling user-facing queries, it’s not built to handle heavy analytical workloads natively. Here’s why:
1. Document-Oriented Storage Is Not Analytics-Friendly
MongoDB stores data as JSON-like (BSON) documents. This is great for flexibility—no rigid schemas, easy to evolve—but analytics queries need something else entirely.
They need efficient ways to scan large volumes of data and perform complex aggregations. Traditional analytical databases (like ClickHouse, Snowflake, or BigQuery) store data in a columnar format.
This allows them to skip over irrelevant columns, compress data better, and perform complex calculations quickly.
MongoDB, on the other hand, must scan and process entire documents (if not limited by $limit, $skip). For large analytical queries (for example, grouping billions of rows by category and date), this approach becomes a bottleneck and even indexing might not work.
2. The Aggregation Framework Has Limitations
The MongoDB Aggregation Framework is powerful for light to medium complexity queries, but it’s not a full-fledged OLAP engine. For instance:
Complex Joins (via $lookup): MongoDB mimics joins using
$lookup. For small datasets, it’s okay. But once you scale to millions of documents,$lookupbecomes slow and memory-heavy plus ,maintaining them (aggregation) becomes complex (a reddit user said).Limited Advanced Functions: Unlike SQL warehouses that have rich sets of window functions, advanced statistical functions, and optimization strategies, MongoDB’s aggregation framework is more basic. Achieving the same in MongoDB involves long, complicated pipelines that are hard to maintain and slow to run.
Memory and CPU Constraints: Running an aggregation that needs to scan large portions of your dataset can spike CPU usage and memory consumption. This can degrade the performance of your production application that relies on the same database.
3. Inefficient Query Execution for OLAP Tasks
Most analytical queries need scanning large amounts of data. Even with indexing, once you start doing heavy grouping, lookups, or multiple pipeline stages, the query engine in MongoDB just doesn’t compare to specialized analytical engines. Plus auto-indexing is available only in mongo’s managed instances.
Indexes help with selective lookups, not full table scans and complex rollups. If your analytical query requires analyzing a significant chunk of data (say 100GB+ of documents), expect slow execution times—often measured in tens of seconds to minutes.
Pain Points Users Face Daily
Unpredictable Query Times: Queries can be fast one day and slow the next as data grows.
Difficult Debugging: Aggregation pipelines become huge and complex. If performance tanks, figuring out why is not always straightforward.
Resource Contention: Your analytics queries hog the same MongoDB that is serving your application. This can cause slow page loads or even timeouts for end users.
Scaling Costs: To handle analytics at scale, you might be forced to scale up your MongoDB cluster (more shards, bigger hardware), increasing costs without guaranteeing good analytic performance.
To put things into perspective, let’s pseudo compare SQL and mongo’s query language.
SQL: Fetch the data from table A,B and C. With the relation A.foreign = B.primary and B.foreign = C.primary. I want the union where C.status = 1 and A.value >4.
Roughly translates to:
MongoDB: An aggregation pipeline with a $match stage for A.value > 4, followed by a $lookup stage with B as the "from" collection, then a $replaceRoot stage with newRoot referencing the as field from the $lookup stage, and finally another $lookup stage with C as the "from" collection and a pipeline stage for the C.status = 1 and B.foreign = C.primary.
For someone not familiar with how queries are written in mongo, the initial learning curve compared to learning SQL can be higher and steep. New Data Analysts or Engineers are more likely to know and write SQL than mongo’s language.
Consider a scenario: You want to find monthly revenue per product category for the last 12 months. In a relational or columnar system, this might be a single SQL query with a few JOINs and GROUP BY clauses.
In MongoDB, you might need multiple $lookup stages (to combine transaction data with product metadata), $unwind to flatten arrays, and $group to aggregate.
On a multi-GB dataset, it’s common for such queries to take over 60 seconds. In some real user reports online, even medium complexity aggregations can drag on if the dataset is large and the pipeline is complex.
Traditional Ways People Try to Solve This
So, what have organizations tried over the years?
Querying Directly on MongoDB (The “Hope It Works” Approach)
Use tools like DBeaver or DataGrip to run the aggregation queries right on MongoDB.
Pain Point: Slow queries, often over a minute. Complex logic and poor performance.
Data Virtualization / Query Layers
Tools that translate SQL to MongoDB’s aggregation pipeline in real-time.
Pain Point: Still limited by MongoDB’s engine. If Mongo can’t handle it well, adding a “layer” on top won’t magically solve the performance problem.
ETL into a Traditional Warehouse (recommended)
Use scripts or ETL tools (like Stitch or Fivetran) to replicate MongoDB data into a relational or columnar data warehouse.
Pain Point: Maintaining ETL pipelines is extra engineering work if your team manages it. Data might be stale by hours or days. Complex transformations and schema mapping add overhead.
Solution: Datazip’s OneStack Data
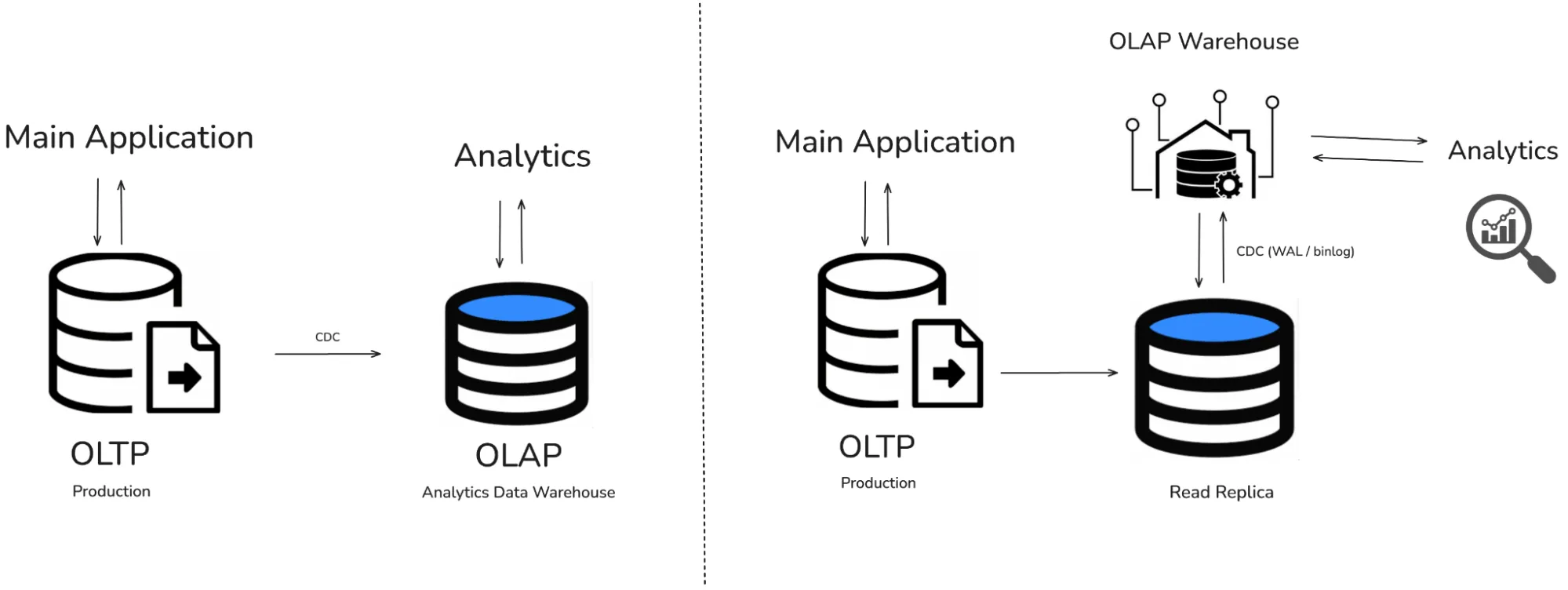
ETL into a SQL-Friendly Database
Move data into MySQL or PostgreSQL, then run SQL queries there (this will give you some boost, but at the end of the day, these are still OLTP’s and now built for big data analytics).
Pain Point: SQL databases are better than MongoDB at analytics, but they’re not always optimal for large-scale, columnar-style OLAP queries unless you pick a dedicated analytical engine.
Switching to an Analytics-Optimized NoSQL Engine
Some newer NoSQL systems or search analytics engines (like Elasticsearch or Druid) are better for certain analytical queries.
Pain Point: Managing yet another system, migrating data, and learning a new query language.
The bottom line: Traditional solutions either force you into manual ETL work or provide only incremental improvements.
Enter Datazip’s OneStack: Analytics at Speed
We know these challenges are painful. That’s why we built Datazip’s OneStack, a platform designed to solve exactly this problem. Our platform uses ClickHouse underneath—an analytical database known for its fast query performance on large datasets.
How It Works:
- Connect Your MongoDB (or any other Database source, we support 150+ connectors):
With a few clicks, you can connect your MongoDB instance to Datazip. We have over 150 source connectors, making this process simple and quick.
Full Load + CDC (Change Data Capture) Replication:
After the initial full load, we keep the ClickHouse instance in sync with MongoDB using CDC. This means your analytical warehouse is always fresh, typically with data latency as low as a few minutes or even near real-time depending on your setup. We use change streams from MongoDB to achieve this.SQL on ClickHouse:
Now you can run the same analytical queries using SQL on ClickHouse. ClickHouse is built for OLAP and can handle billions of rows easily. Common queries that took minutes on MongoDB often run in seconds on ClickHouse.We transform your mongo data (usually in JSON-like format) into level 0 flattening. Here’s how:
Note: Flattening is the process of converting nested JSON or hierarchical data into a flat, tabular structure with rows and columns.
It involves breaking down nested objects and arrays into separate rows (sometimes complete different tables), while preserving the relationships using consistent keys (e.g., parent_child_key).
This makes complex data easier to store, query, and analyze in relational databases or BI tools.
Source MongoDB Data Sample:
- Map Flattening (without Explore JSON Arrays option)
Input Data Sample
{
"name": "John Doe",
"email": "xxxx@datazip.io",
"#password": "xxxxx",
"phone_number": "+91907xxxxxx",
"test": {
"password": "1234",
"tel": {
"password": ["heelo"]
}
},
"pets": [
{
"type": "dog",
"name": "Buddy"
},
{
"type": "cat",
"name": "Whiskers"
}
]
}
Output after level 0 flattening by OneStack [Sample] :
| name | _password | phone_number | test_password | test_tel_password | pets_type | pets_name | |
| John Doe | xxxx@datazip.io | xxxxx | +91907xxxxxx | 1234 | ["heelo"] | dog | Buddy |
| John Doe | xxxx@datazip.io | xxxxx | +91907xxxxxx | 1234 | ["heelo"] | cat | Whiskers |
Output Data:
{
"name": "Piyush Singariya",
"email": "xxxx@datazip.io",
"_password": "xxxxx",
"phone_number": "+91907xxxxxx",
"test_password":"1234",
"test_tel_password": "[\"heelo\"]"
}
For JSON data containing arrays, we do vertical array explosion / flattening:
Read the complete flattening doc here.
- Connect to Your BI Tools:
You can plug in Metabase, Tableau, Power BI, or any other BI tool directly into Datazip’s OneStack. The dashboards that used to take forever to load will now appear almost instantly.
A Real Comparison: MongoDB vs. Datazip’s OneStack
To make this more concrete, we took the twitter dataset (~ 200GB uncompressed) of data stored in MongoDB. You want to:
Have multiple Joins
Aggregate
Return results for the last x months or some other filter.
On MongoDB:
You write an aggregation pipeline with multiple
$lookup,$unwind, and$groupstages.The basic simple query might run for over 60 seconds (if unindexed, on a 200mill + dataset). As your data grows (say from 100GB to 500GB incrementally), it could go beyond a few minutes to hours.
With Datazip’s OneStack (Powered by ClickHouse):
You set up a source connector for MongoDB in OneStack.
OneStack performs a full load and then keeps it updated with CDC (Change Data Capture) so data stays fresh.
Now, instead of dealing with a complicated pipeline, you run a standard SQL query on ClickHouse.
ClickHouse, a columnar OLAP database, handles large scans and aggregations in seconds.
The same query that took 60+ seconds on MongoDB might now return in under 5 seconds, often just 1-2 seconds depending on order by column (as ClickHouse does not natively have Primary Key concept) and compression.
Using basic & simple SQL, Clean up data, make materialized tables / models, join various other datasets required to get the final metrics.
Tools like Metabase, Tableau, or Power BI speak SQL fluently. Connecting them directly to MongoDB often leads to pain. Connecting them to ClickHouse through Datazip’s OneStack means dashboards load fast and refresh smoothly, making analysts 10x productive.
This isn’t theoretical fluff. Columnar databases like ClickHouse are known for sub-second response times on analytical queries over billions of rows, as long as the queries are properly structured and the cluster is sized correctly.
Benchmarks and Proof
Directly on MongoDB: A complex aggregation query on a > 100GB dataset may take at least 60 seconds to hours to run.
On Datazip’s OneStack with ClickHouse: The same logical query might complete in under 5 seconds.
These aren’t marketing numbers pulled from thin air. ClickHouse is known for its speed. Companies with terabytes of data rely on it for sub-second queries. You can easily find public benchmarks and case studies online (e.g., comparing it against traditional row-store databases).
A simple COUNT(*) took 0.1 seconds to give the result in ClickHouse where it took more than 2 minutes.
Query1: Find tweet count and its language [Basic]
1. Direct run on MongoDB
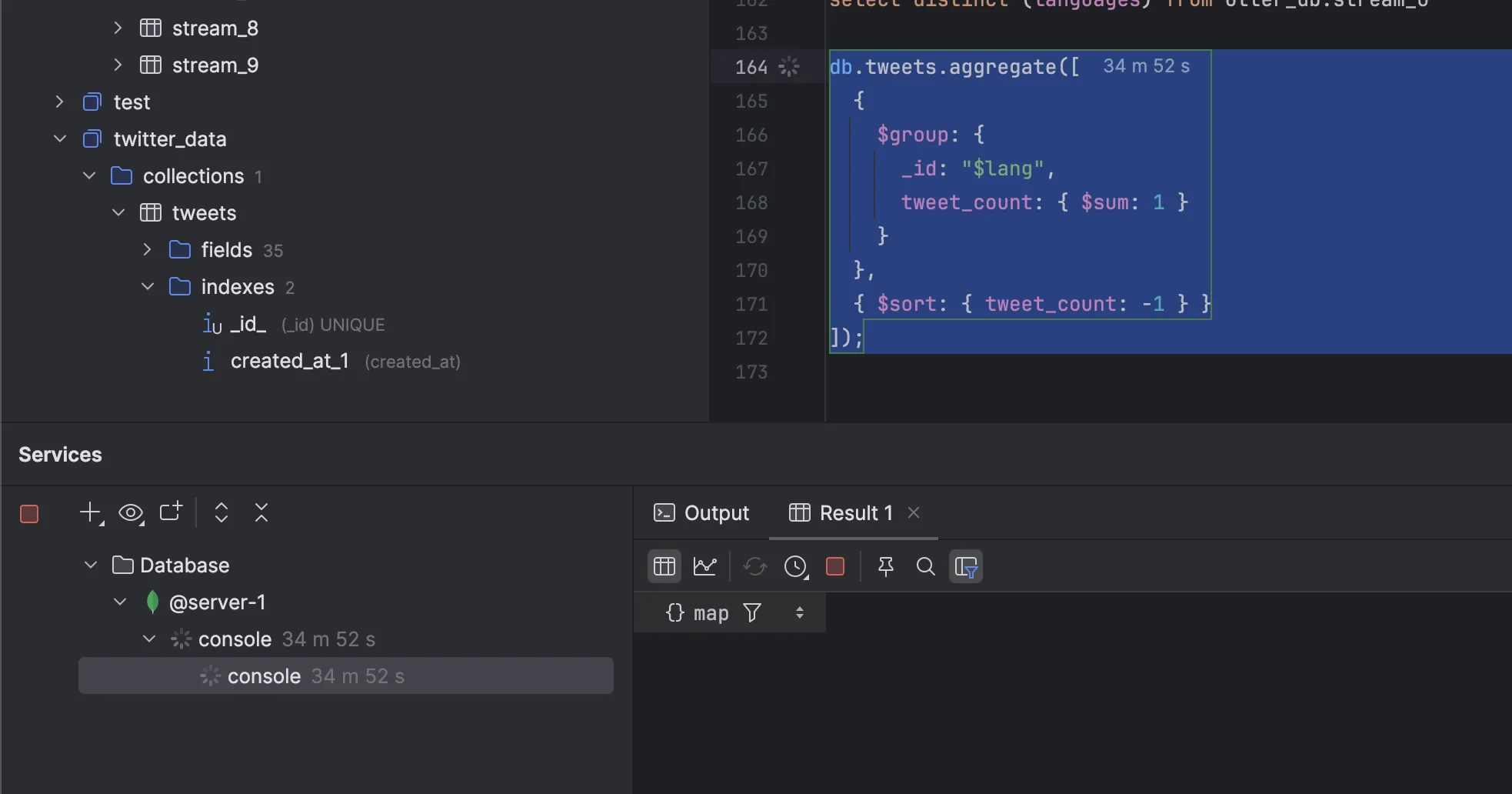
2. Run on Datazip’s OneStack
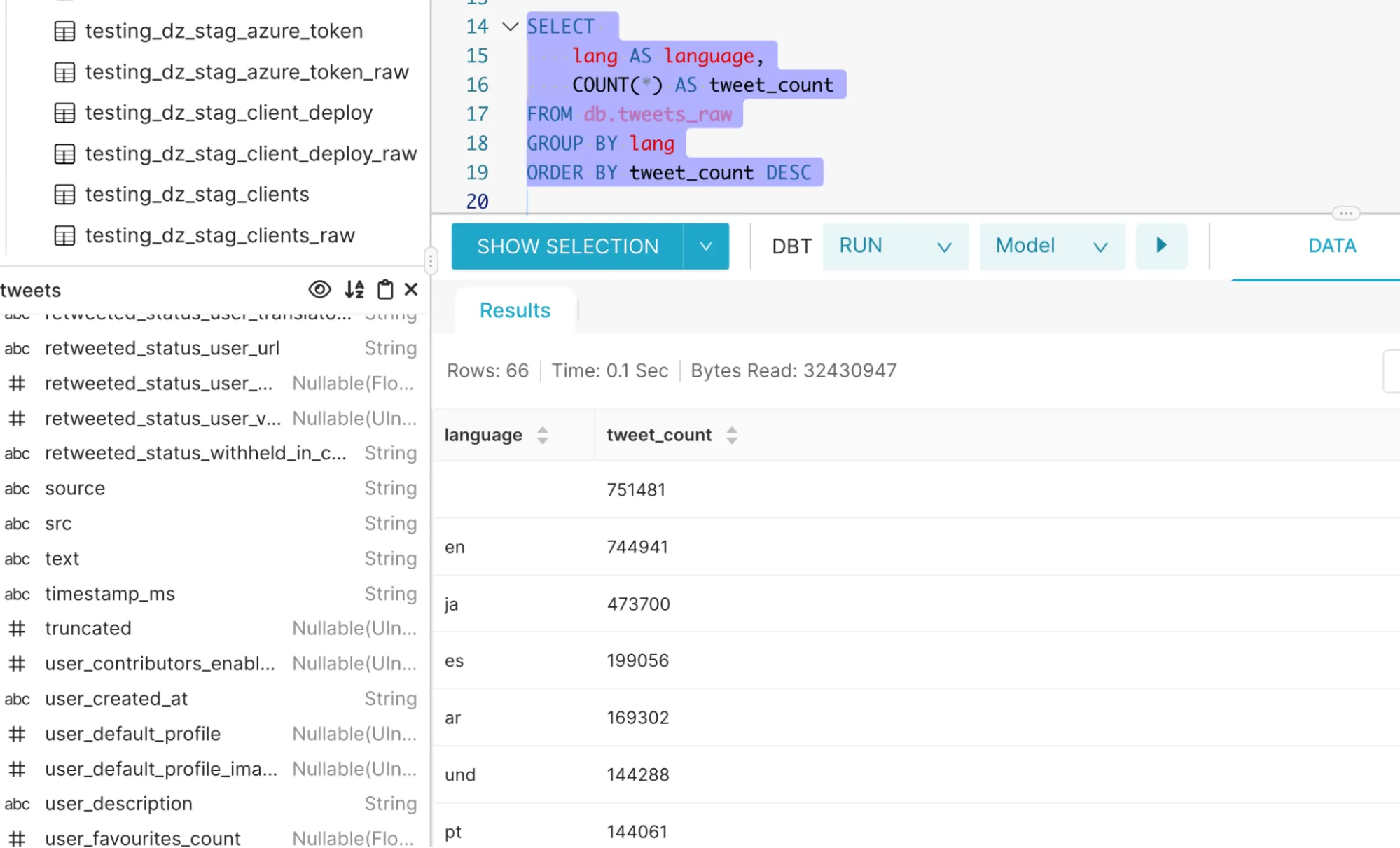
Result: mongoDB failed to run such a basic query on a dataset of 250GB (233 mill records), ClickHouse did it in 0.1 sec.
Note that we had indexed id and createdat keys in mongoDB.
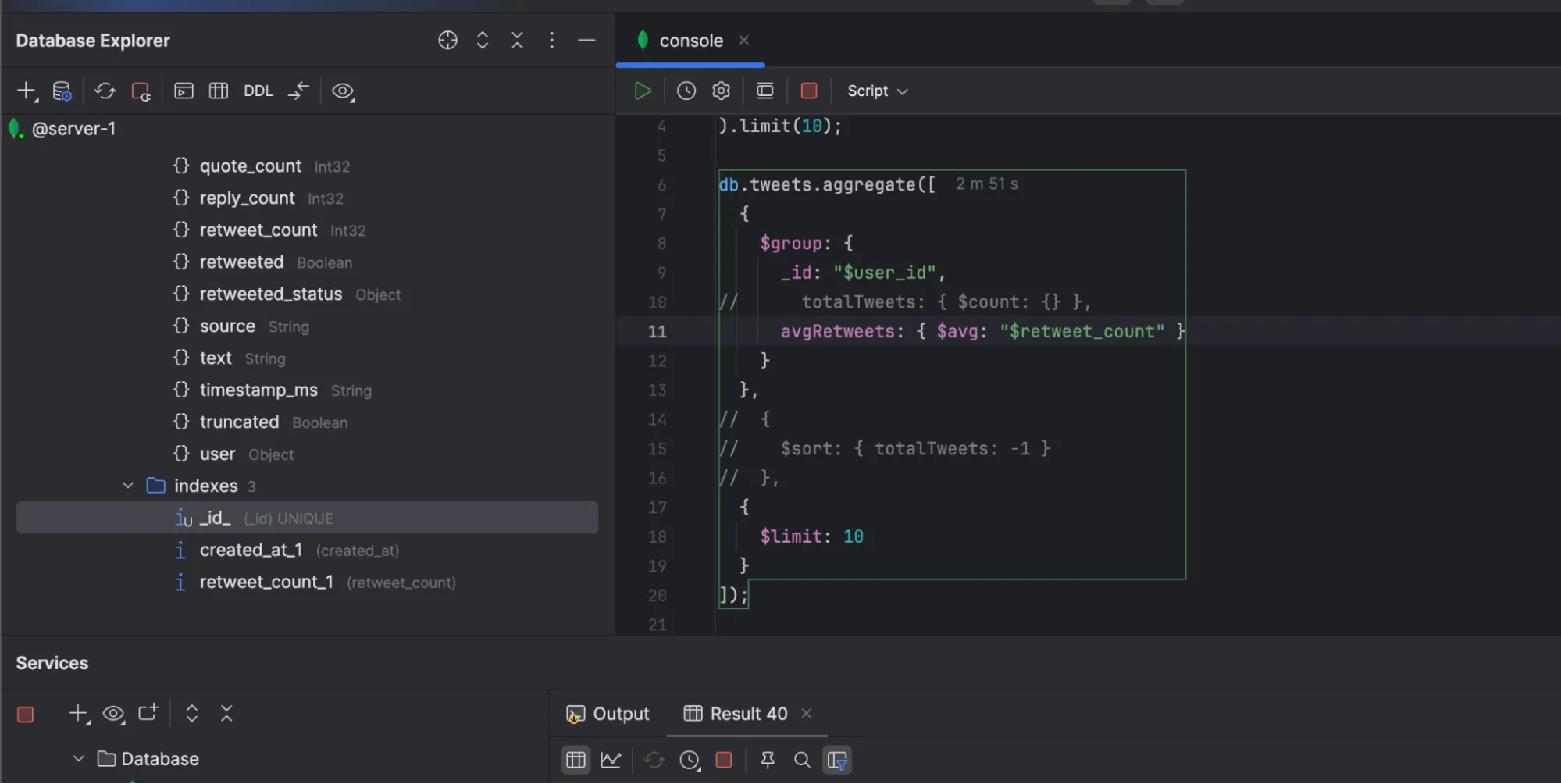
Query2: Aggregation with additional metrics: Group by user_id, get total tweets and average retweet_count
1. Direct run on MongoDB [2 min + execution time]
2. Run on Datazip’s OneStack
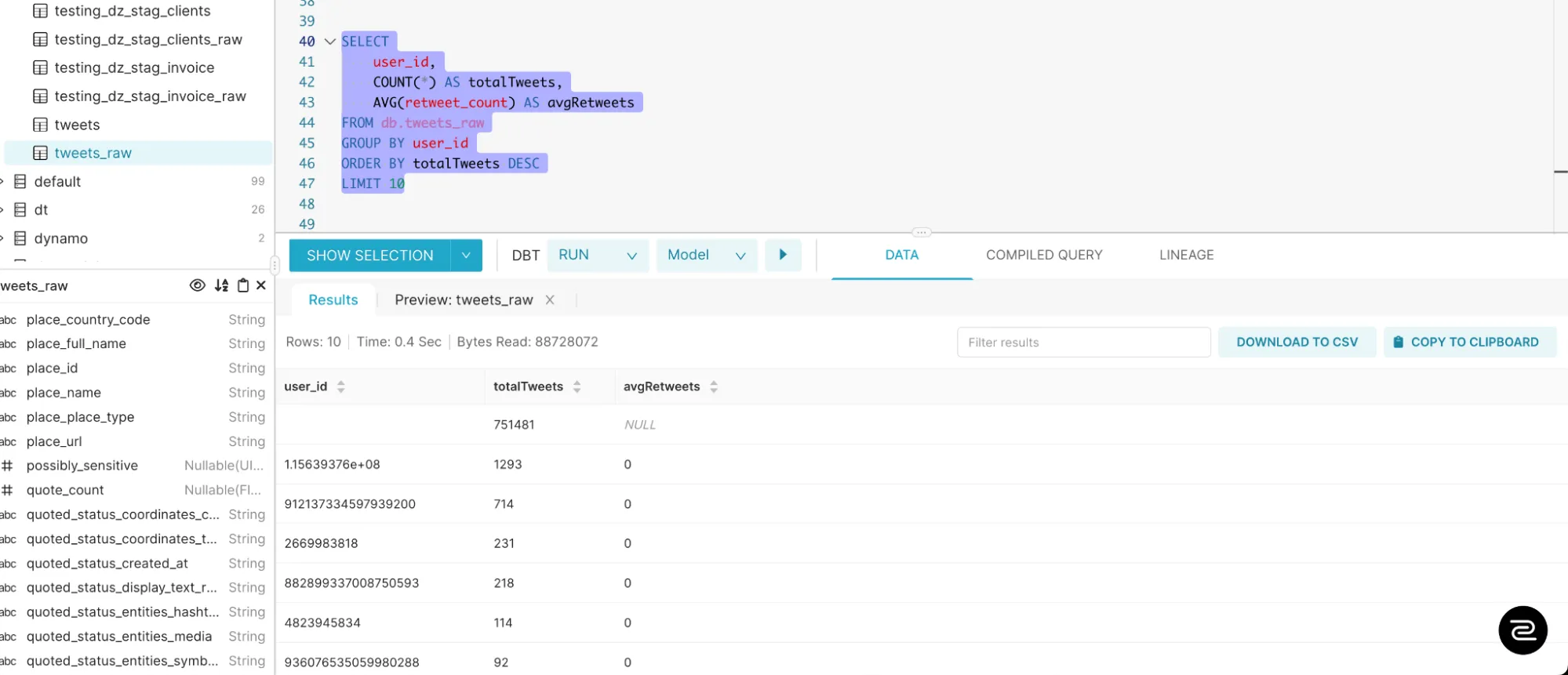
Result: Query execution on mongoDB took forever (note that retweet_count was indexed as well), OneStack’s managed ClickHouse did it in 0.4 seconds.
We initially planned to run a lot more complex queries on mongoDB but seeing this kind of performance, I think we know its just impossible to run analytical queries with this big of a data size (200 mill + records).
Making indexes will help, but it's impractical to make indexes out of each / all column that you want to use.
Query 3: Example query for pattern matching in ClickHouse
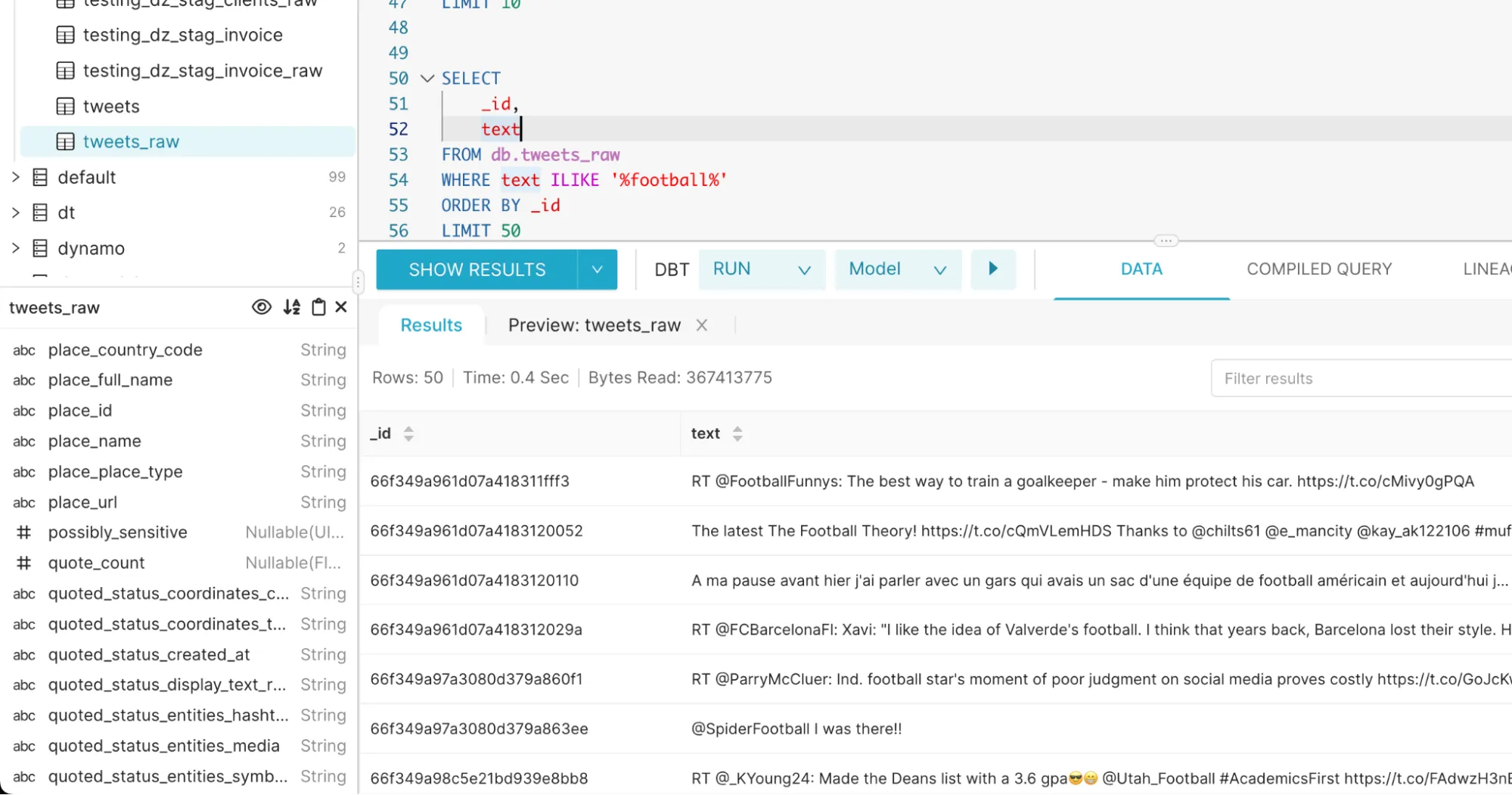
The below query:
b.tweets.createIndex({ text: "text" });
// Searching for the word "football"
db.tweets.find(
{ $text: { $search: "football" } },
// { score: { $meta: "textScore" } }
).sort({ score: { $meta: "textScore" } });
Kept on buffering and never yielded the result.
We also did look into ClickBench: a Benchmark For Analytical Databases. Take a look
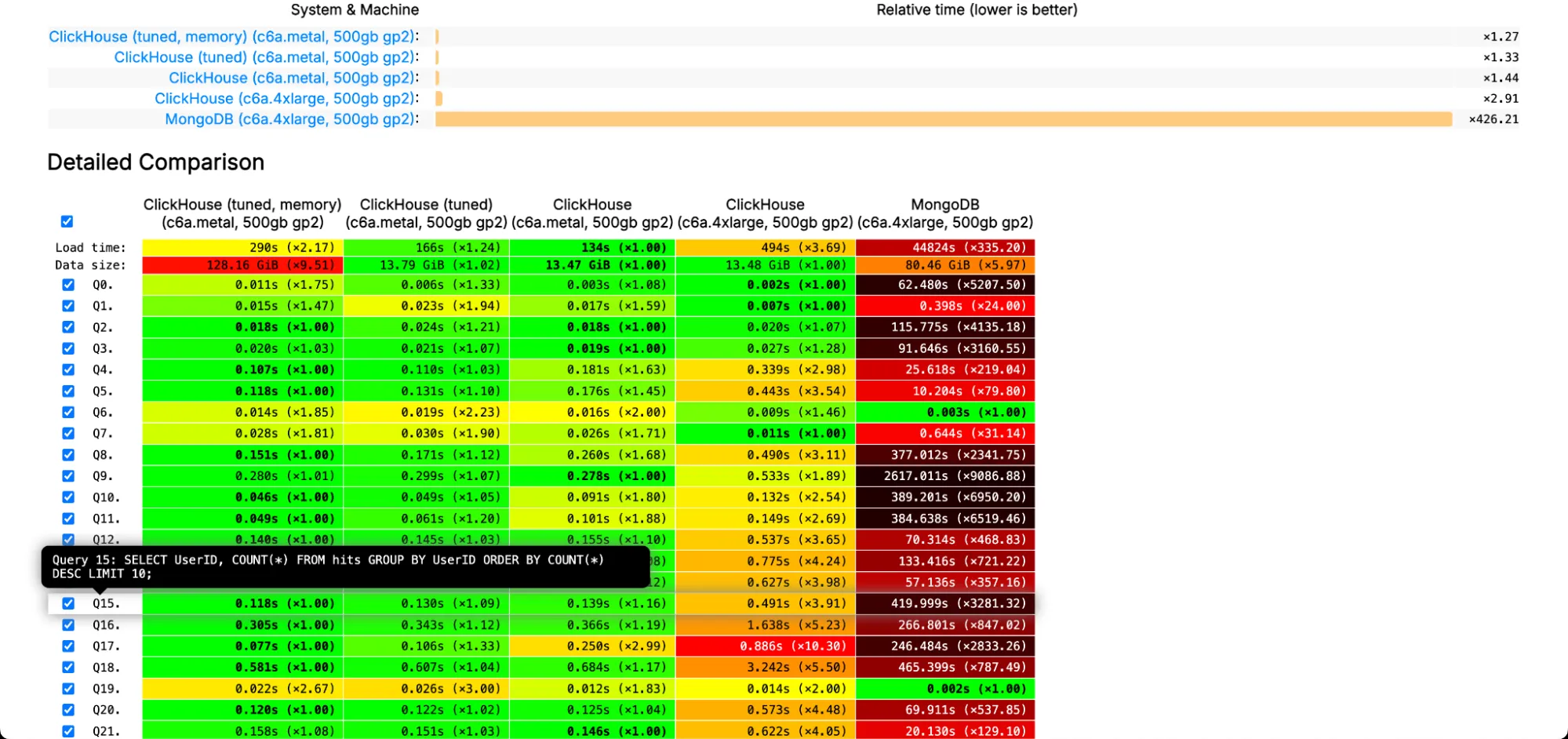
Source - ClickBench (Q0, Q1, Q2, etc are standard queries, hovering on them will give you the exact query that was being tested)
So, you did execute your queries and got the intended result, now what? Yeah getting the data to a BI so you can visualise the data.
Assuming you cleaned up the data, applied some transformations, got the data from 🥉Bronze -> 🥈Silver -> 🥇Gold following the medallion architecture, now it's time you make sense of this data.
Connecting BI Tools (Metabase / Tableau / Superset / PowerBI / Redash) and Seeing Immediate Improvements in chart rendering times
Refer to our guide on “Connecting your BI tool directly on MongoDB vs with OneStack Data for faster chart loading times” here.
Running Queries Across Multiple Data Sources
Modern analytics often requires combining data from multiple sources—maybe you want to join mongoDB data with a SQL database or with a SaaS application’s API data.
Since Datazip supports 150+ source connectors, you can pull data from multiple DBs and SaaS sources into a unified analytical layer. Suddenly, joining across sources and building holistic dashboards becomes trivial and fast.
Running Queries with SaaS data source and multiple Database data (MongoDB + Postgres + Google Analytics)
If your final query requires you to aggregate data from multiple database sources, a SaaS source, you can perform those queries here as well.
- Sync Database1 with OneStack
Fig: Showing 4 of 150+ connectors.
- Sync Database2 with OneStack
Fig: Add database details to connect and sync data instantly.
Sync SaaS source data with OneStack (click here to see all the SaaS source connectors we support [oh, we support many])
Decide the joining key (assuming your data has some common key to make a
JOIN)Run the query.
Yeah that’s basically it.
Refer the below picture
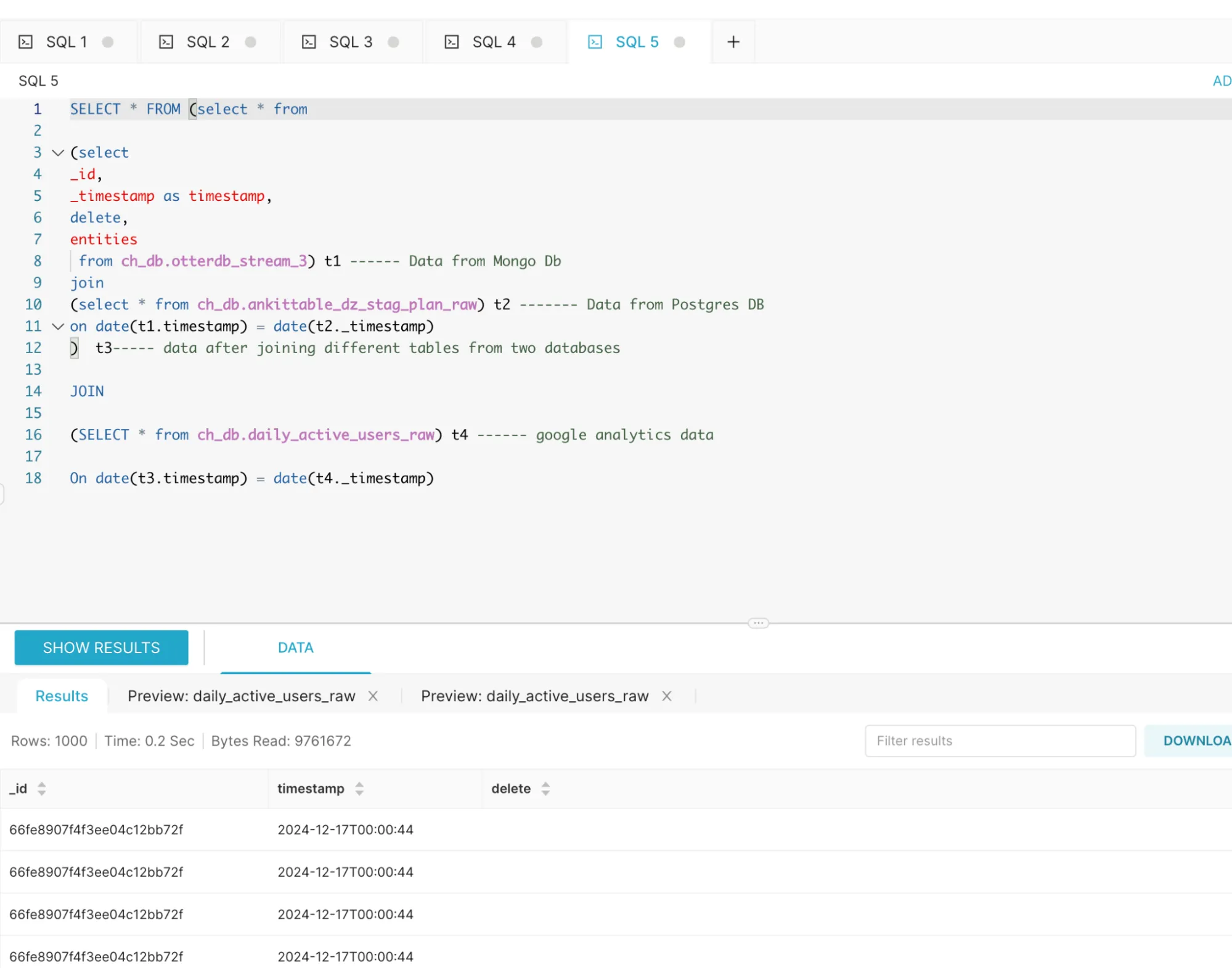
The query:
SELECT *
FROM
(
SELECT *
FROM
(
-- Data from MongoDB
SELECT
_id,
_timestamp AS timestamp,
delete,
entities
FROM ch_db.otterdb_stream_3
) t1
JOIN
(
-- Data from Postgres DB
SELECT *
FROM ch_db.ankittable_dz_stag_plan_raw
) t2
ON DATE(t1.timestamp) = DATE(t2._timestamp)
) t3 -- Data after joining different tables from two databases
JOIN
(
-- Google Analytics data
SELECT *
FROM ch_db.daily_active_users_raw
) t4
ON DATE(t3.timestamp) = DATE(t4._timestamp);
Here, we used the Data from MongoDB + Postgres and Google Analytics to show even joining multiple Databases together and on top of that joining another SaaS source and running queries under 1 second is also possible with OneStack Data. So, what are you waiting for?
Common Errors and Myths
Myth 1: Adding More Indexes Will Fix MongoDB Analytics
Indexes help with point lookups or small subsets. But analytics often needs full table scans and complex aggregations. Indexes alone won’t cut down query time drastically for large-scale analytical workloads.
Myth 2: MongoDB’s Aggregation Framework is “Just Like SQL”
Though powerful, it’s different. The learning curve is steep, and complex analytics that are trivial in SQL can become multi-stage, unreadable pipelines in MongoDB.
Myth 3: Real-Time Analytics Is Impossible Without Massive Infrastructure
With tools like Datazip’s OneStack, you don’t need a huge team to maintain ETL pipelines or specialized infrastructure. A single Data Engineer or an Analyst can easily run the entire platform for your data needs. The platform handles real-time syncing and optimal storage (with 3 modes, Cost Saver, Balanced and Performance), so you can focus on insights.
When a Database (Like MongoDB) Is Better vs. When a Warehouse Is Better
Database (MongoDB) for OLTP: If your main workload is supporting a user-facing app with fast reads/writes of small units of data, MongoDB shines. Schemaless design and horizontal scaling are big advantages here.
Warehouse (ClickHouse) for OLAP: When the query is analytical—aggregating millions of rows, joining multiple datasets, exploring historical trends—a warehouse/OLAP system is far superior. It’s built for scanning large data sets, compressing them, and running analytical functions fast.
You don’t have to pick one over the other. Use MongoDB for what it’s good at (storing and retrieving operational data quickly) and ClickHouse for what it’s good at (fast analytics).
Datazip’s OneStack gives you the best of both worlds.
Read more here: Why Move from a Database to a Data Warehouse for Analytics?
Conclusion: Move Past the MongoDB Analytics Pain
Trying to force heavy analytics directly on MongoDB is like trying to race a family car on a Formula 1 track. Yes, the car will move, but it won’t compete. MongoDB is a great operational database, but it’s not a high-performance analytics engine. To get real analytical speed and simplicity, you need the right tool for the job.
Datazip’s OneStack sits neatly between your MongoDB and your BI layer, continuously updating a ClickHouse data warehouse.
This lets you run analytical queries that once took a minute or more now in a few seconds—often under a second with proper optimization.
No more complicated pipelines, no more slow dashboards, no more frustrated analysts. Just connect MongoDB, let Datazip handle replication, and start querying at lightning speed.
Try It Yourself:
Connect MongoDB to Datazip’s OneStack.
Run the same analytical queries that struggled in MongoDB directly on ClickHouse.
Connect Metabase, Tableau, or any BI tool, and watch dashboards load instantly.
If you’ve struggled with slow MongoDB analytics, now you know why—and how to fix it. It’s time to unlock the true potential of your data and transform slow queries into fast, insightful analytics.
If you have any questions or want to learn more, drop us a line at hello@datazip.io or book a quick demo meeting with us.
Disclaimer: Actual query speeds depend on data size, cluster configuration, and query complexity. The examples given are based on common industry patterns and ClickHouse’s known performance characteristics.
Subscribe to my newsletter
Read articles from Priyansh Khodiyar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Priyansh Khodiyar
Priyansh Khodiyar
Building Composable Lakehouse | DevRel at Datazip. Linkedin - https://www.linkedin.com/in/zriyansh