Under the hood of the V8 engine
 Vedant
Vedant
Introduction
V8 is Google’s open source high-performance JavaScript and WebAssembly engine, written in C++. It is used in Chrome and in Node.js, among others. It implements ECMAScript and WebAssembly, and runs on Windows, macOS, and Linux systems that use x64, IA-32, or ARM processors. V8 can be embedded into any C++ application.
It's the thing that takes our JavaScript and executes it while browsing with Chrome. V8 was chosen to be the engine that powered Node.js back in 2009, and as the popularity of Node.js exploded, V8 became the engine that now powers an incredible amount of server-side code written in JavaScript.
V8 is written in C++, and it's continuously improved. It is portable and runs on Mac, Windows, Linux and several other systems.
Every line of javascript code goes through many steps in the V8 engine. They have made many iterations of the code execution.

History
Previously v8 used to have 2 compliers ,one that does a quick-and-dirty job (full-codegen), and one that focuses on hot spots (Crankshaft).
full-codegen — a simple and very fast compiler that produced simple and relatively slow machine code.
Crankshaft — a more complex (Just-In-Time) optimizing compiler that produced highly-optimized code.
When first executing the JavaScript code, V8 leverages full-codegen which directly translates the parsed JavaScript into machine code without any transformation.
Next, Crankshaft optimizations begin in another thread. It translates the JavaScript abstract syntax tree to a high-level static single-assignment (SSA) representation called Hydrogen and tries to optimize that Hydrogen graph. Most optimizations are done at this level.

There were further improvement in these steps by introducing turbofan complier

Source : V8 official blogs
These compiler pipeline lead to 33% more parsing time and increase heap usage. The actual compile time was less than the parsing time. This lead to the introduction of the Ignition interpreter.
We now come to the recent and effective version of the complier pipeline:

I will be explaining these steps further in this article
Parsing
This is step where the goal is to create a AST(Abstract Syntax Tree).
Abstract Syntax Tree is the tree representation of the source code
For example :
var a = 1
For this one line of code the tree would look like this:

You can explore more of this here AST Explorer.
To generate this AST Parsing has 2 steps
Lexical Analysis
Syntactical Analysis
Lexical Analysis
Once V8 downloads the source code via a network, cache, or service workers, the scanner takes the code and converts it into tokens. There is also a list of JS tokens.
Syntactical Analysis
After converting to tokens, it is then converted into AST (Abstract Syntax Tree) V8's Parser. Each node of the tree denotes a construct occurring in the code.
Preparser
Eagerly compiling code unnecessarily has real resource costs:
CPU cycles are used to create the code, delaying the availability of code that’s actually needed for startup.
Code objects take up memory, at least until bytecode flushing decides that the code isn’t currently needed and allows it to be garbage-collected.
Code compiled by the time the top-level script finishes executing ends up being cached on disk, taking up disk space.
For these reasons, all major browsers implement lazy parsing. Instead of generating an abstract syntax tree (AST) for each function and then compiling it to bytecode, the parser can decide to “pre-parse” functions it encounters instead of fully parsing them. It does so by switching to the preparser, a copy of the parser that does the bare minimum needed to be able to otherwise skip over the function. The preparser verifies that the functions it skips are syntactically valid, and produces all the information needed for the outer functions to be compiled correctly. When a preparsed function is later called, it is fully parsed and compiled on-demand.
Just-In-Time Compilation
The compilation is often done in a Just-In-Time (JIT) approach. JIT means that the compilation happens at runtime, just before the code is executed. Initially, the engine interprets the code line by line, but as the code is executed, the engine identifies frequently executed code segments, also known as “hot code paths”
The JIT compiler then compiles these hot code paths into executable code using type information from previous executions., which can be executed more efficiently by the computer’s processor.
However, there is a chance that the type might change. We need to de-optimize compiled code and fallback to interpretation instead (after that, we can recompile the function after getting new type feedback).
Interpreter
V8 engine uses a interpreter called as Ignition. Ignition is a fast low-level register-based interpreter written using the backend of TurboFan. Once the engine has AST, it sends this tree to Ignition which converts it into bytecode. Bytecode is an abstraction of machine code. Compiling bytecode to machine code is easier if the bytecode was designed with the same computational model as the physical CPU. This is why interpreters are often register or stack machines. Ignition is a register machine with an accumulator register.
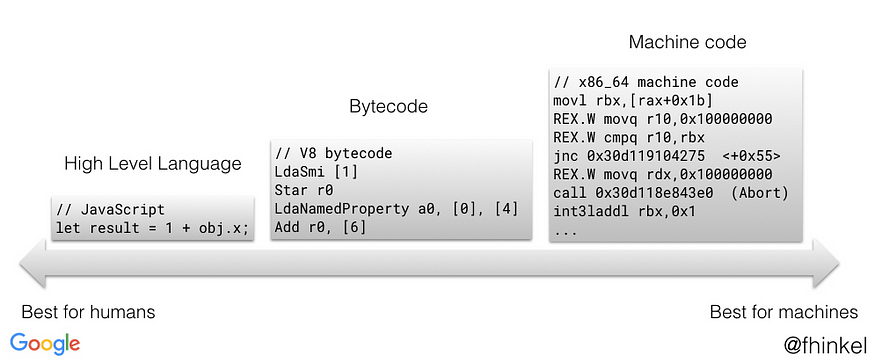
You can think of V8's bytecodes as small building blocks that make up any JavaScript functionality when composed together.
TurboFan
When the ignition interpreter is doing it’s job it recognizes some code which is used a lot and gives that code to the TurboFan complier so that the code (hot code) is complied and optimized so that next time the code is executed very fast.
Turbofan converts code into optimized machine code and then that code is executed. Turbofan follows the JIT(Just-In-Time) design where it looks for hot code to be optimized code for execution.
TurboFanmakes assumptions :
function sum(a,b){
return a+b;
}
sum(0,5) // Assumption : arguments will be num)
sum(2,3) // Optimised code
sum(6,7) // Optimised code
sum("a","b") // Leads to de-optimization
Here in the last function call, turbofan will de-optimize the code and sends it back to the interpreter, as it was optimizing the function for number and not strings.
So to conclude the whole concept, the way V8 Engine works is
Code is parsed to AST by a Parser
Ignition converts it into Bytecode and an interpreter reads it (This Interpreter is in Ignition)
If Ignition finds a Hot function, it makes an assumption and sends it to TurboFan.
TurboFan uses these assumptions to generate an optimized version of that code.
Conclusion
So to conclude the whole article, the way V8 Engine works is
Code is parsed to AST by a Parser.
Ignition converts it into Bytecode and executes it.
If Ignition finds a Hot function, it makes an assumption and sends it to TurboFan.
TurboFan uses these assumptions to generate an optimized version of that code.
There are other optimization techniques that V8 uses to enhance the performance of JavaScript code execution. Some of them are : Inline Caching, Hidden Classes, Function Inlining, Escape Analysis, Garbage Collection Optimizations and more. I will be talking about this in another article.
I would suggest reading through the Official V8 Docs for deeper understanding.
Thank you for reading!
Subscribe to my newsletter
Read articles from Vedant directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by