Optimizing Efficiency in Large Language Models Through Distillation
 Amey Muke
Amey MukeIn the rapidly evolving field of artificial intelligence, distillation has emerged as a powerful technique for creating smaller, more efficient models from bigger and better large language models (LLMs). This process transfers knowledge from a large, complex model (the “teacher”) to a smaller model (the “student”), retaining most of the performance while reducing computational demands. In this blog, we’ll explore the distillation process, its types, difference between fine-tuning and distillation, and its importance in the development of efficient small LLM models.
What is Distillation?
Distillation allows a smaller model to learn from a larger one. This technique significantly reduces model size and computational cost without sacrificing much performance. It is widely used in areas like image diffusion, speech transcription, and lightweight versions of LLMs.
Why Use Distillation?
Efficiency Gains: Requires only a fraction of the data and computational resources needed for training models from scratch.
Applications: Useful in creating scalable models for edge devices and real-time applications.
Cost-Effectiveness: Makes high-performing models deployable in resource-constrained environments.
The Distillation Process: Step by Step
Selecting the Teacher Model:
The process begins by selecting a teacher model, which is typically a large, pre-trained language model known for its high performance. The student model is a smaller version that will learn from the teacher's outputs and internal representations.
Student Model Initialization:
The student model is prepared by either:
Random Initialization: Starting with randomly initialized weights.
Pruning the Teacher Model: Reducing complexity through:
Layer Pruning: Removing redundant layers.
Width Pruning: Narrowing specific layers based on activation errors.
Layer Pruning
Layer pruning involves removing entire layers from the teacher model to create a smaller student model. This approach is straightforward and effective for reducing model size quickly. Typically, the final layers (except for the last one) are removed, as they often contain redundant information.
Width Pruning
Width pruning focuses on reducing the number of neurons or attention heads within each layer. This method is more granular and allows for finer control over the model's size and performance. Selective width pruning involves calculating the activation error on a test set to determine which neurons to prune.
Student Model Training:
This involves training the student to replicate the teacher’s outputs using one of two approaches(You could combine both pre-training and distillation as well):
Pre-Training: Traditional training with labeled datasets.
Distillation: Using the teacher’s predictions as soft labels, leveraging loss functions like:
Cross-Entropy Loss: Measures the difference between predicted probabilities and ground truth.
KL Divergence: Aligns the student’s outputs with the teacher’s softened probabilities.
Pre-Training
Pre-training involves training the student model on a large corpus of data, similar to how the teacher model was trained. However, the student model starts from a better initialization point (either random or pruned from the teacher model). This approach requires more data and computational resources compared to distillation but can be effective in scenarios where the student model needs to learn general language representations before fine-tuning.
During pre-training, Cross-Entropy Loss is typically used. This loss function measures the difference between the predicted probabilities and the actual distribution (ground truth labels). It is calculated as:

where yi is the actual distribution (e.g., [1.0, 0.0, 0.0] for "dog") and y hat is the predicted probability distribution (student probabilities).
Distillation
Distillation, on the other hand, uses the teacher model's predictions (soft labels) to guide the student model's training. This approach requires significantly less data (only about 2-5% of the data needed for pre-training) and computational power. The student model learns to mimic the teacher's output probabilities, which often contain richer information than hard labels.
During distillation, KL Divergence is typically used as the loss function. KL Divergence measures how one probability distribution (the student's output) diverges from a reference distribution (the teacher's output). It is calculated as:
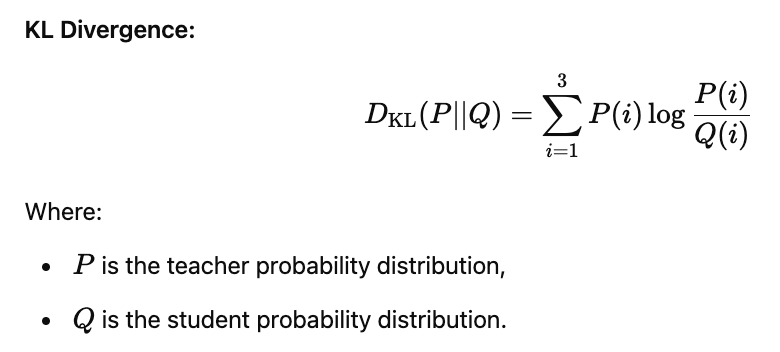
Instruction Fine-Tuning:
The final step involves aligning the student model with real-world tasks using:
Supervised Fine-Tuning: Training on task-specific data.
Preference Optimization: Using methods like PPO (Proximal Policy Optimization) or DPO (Direct Preference Optimization) for user-defined objectives.Distillation vs. Fine-Tuning
Types of Distillation Methods
Knowledge Distillation (KD):
Soft Target Distillation: The student model is trained to mimic the output distribution (soft targets) of the teacher model. Instead of hard labels, the student learns from the probabilities assigned by the teacher to each class.
Hint-based Distillation: The student model is guided by intermediate representations (e.g., hidden states or attention maps) from the teacher model, not just the final output.
Temperature-scaled Distillation:
- A temperature parameter is introduced to soften the probability distribution of the teacher model's outputs. This helps the student model to learn more nuanced information from the teacher's predictions.
Feature-based Distillation:
- The student model is trained to replicate the internal representations (e.g., embeddings, hidden states) of the teacher model. This can involve matching the outputs of specific layers or the entire network.
Attention-based Distillation:
- The student model is trained to mimic the attention patterns of the teacher model. This is particularly useful in transformer-based models where attention mechanisms play a crucial role.
Task-specific Distillation:
- The distillation process is tailored to a specific task (e.g., sentiment analysis, machine translation). The student model is trained to perform well on that particular task by learning from the teacher model's task-specific outputs.
Data-free Distillation:
- The student model is trained without access to the original training data. Instead, synthetic data or data generated by the teacher model is used for distillation.
Multi-teacher Distillation:
- The student model learns from multiple teacher models, each potentially specialized in different aspects or tasks. The student model integrates knowledge from all teachers to improve its performance.
Online Distillation:
- The teacher and student models are trained simultaneously. The student model continuously learns from the teacher model during the training process, rather than after the teacher model has been fully trained.
Self-distillation:
- The same model acts as both the teacher and the student. The model is trained to improve its own performance by learning from its own predictions or intermediate representations.
Cross-modal Distillation:
- Knowledge is transferred between models of different modalities (e.g., from a text-based model to an image-based model). This is useful in multi-modal learning scenarios.
Distillation vs. Fine-Tuning
Model distillation and fine-tuning are both techniques used to adapt large pre-trained models for specific tasks, but they serve different purposes and have distinct methodologies:

Key Differences:
Distillation focuses on creating a smaller, more efficient model that retains the performance of the larger teacher model. It uses the teacher's predictions (soft labels) and requires less data and computational power.
Fine-Tuning, on the other hand, adapts a pre-trained model to a specific task by training it on task-specific labeled data. This process is more computationally intensive and results in a specialized model tailored to the task at hand.
Challenges and Drawbacks of Distillation
While distillation offers significant benefits, it is not without its challenges and drawbacks. Here are some of the key issues:
1. Loss of Information
Challenge: The student model may not fully capture the complexity and nuances of the teacher model, especially when the size difference between the two is substantial.
Impact: This can lead to a noticeable drop in performance, particularly in tasks requiring deep reasoning or nuanced understanding.
2. Overfitting to Soft Labels
Challenge: The student model might overfit to the soft labels provided by the teacher, especially if the teacher model is too confident in its predictions.
Impact: This can reduce the student model's ability to generalize to new, unseen data, making it less robust in real-world applications.
3. Balancing Soft and Hard Labels
Challenge: While soft labels provide rich information, they may not always align perfectly with the true labels. Finding the right balance between learning from soft labels and hard labels is crucial.
Impact: Improper balancing can lead to suboptimal performance, as the student model might not learn the correct task-specific features.
4. Complexity of Teacher Models
Challenge: Some teacher models, especially those with advanced architectures, may be difficult to distill effectively. The student model may struggle to replicate the teacher's behavior, particularly in tasks requiring deep reasoning or nuanced understanding.
Impact: This can limit the effectiveness of distillation, requiring more sophisticated techniques to achieve desired performance levels.
5. Computational Costs of Teacher Model
Challenge: The process of generating soft labels from the teacher model can be computationally expensive, especially for very large models.
Impact: This can offset some of the efficiency gains of using a smaller student model, particularly in scenarios where the teacher model needs to be run frequently.
6. Data Requirements
Challenge: Effective distillation often requires a large amount of high-quality training data to generate meaningful soft labels.
Impact: In domains where data is scarce or expensive to obtain, this can be a significant barrier to successful distillation.
7. Task-Specific Adaptation
Challenge: Distilled models may require additional fine-tuning to adapt to specific tasks, which can add complexity to the deployment process.
Impact: This can limit the plug-and-play usability of distilled models, requiring additional effort to achieve optimal performance in specific applications.
Best Practices for Effective Distillation
Pruning Strategies:
- Use layer pruning for simplicity or selective width pruning for finer control.
Learning Rate:
- Maintain gradient norms below 5, ideally closer to 1.
Batch Size:
- Use large batch sizes (32-64) for effective knowledge transfer.
Instruction Fine-Tuning:
- Align the student with practical tasks for optimal performance.
Regularization Techniques:
- Employ regularization methods to prevent overfitting to soft labels.
Data Augmentation:
- Use data augmentation techniques to enhance the diversity and quality of training data.
Subscribe to my newsletter
Read articles from Amey Muke directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by