Client-Server Architecture
 Jay Kadlag
Jay Kadlag
Introduction
The client-server architecture is a revolutionary concept that fundamentally changed how applications are built and deployed. It introduced the idea of separating the client and server into distinct components, allowing the core pieces of code to exist in different locations. This innovation paved the way for modern distributed computing.
Previously, applications ran on large mainframes, which were expensive and resource-intensive. The client-server model addressed this by moving heavy workloads, such as computational tasks or database queries, to servers equipped with powerful resources. Clients, on the other hand, became lightweight, requiring only basic hardware to interact with the server
For example, consider a scenario where a server performs resource-intensive tasks like database queries or complex computations. A thin client device, like a tablet or desktop, sends requests to the server. The server processes these requests and sends the results back to the client. This separation improves scalability and reduces costs since multiple clients can use a single powerful server.
Remote Procedure Calls (RPCs)
To enable communication between the client and server, Remote Procedure Calls (RPCs) were introduced. These allow a client to execute functions on a remote server as if they were local.
Early implementations lacked standardization, but over time, standards like gRPC (Google RPC) were developed. These standards provide efficient and universal communication between distributed components.
What is a Client?
A client is a computer or device, also known as a host, that requests and uses services or receives information.
It is the part of an application that directly communicate with the users. Clients send requests to the server, process the server's responses, and display the results to the user.
Clients are designed to be lightweight, fast and simple.
Examples of a client are:
Web Browsers: Chrome, Firefox, Safari
Mobile Applications: Instagram, WhatsApp, Facebook
IoT Devices: Fitness trackers, Thermostats, Smart Speakers
What is a Server?
A server is a remote computer that provides access to data and services. It processes requests from clients, performs the required tasks, and sends the responses back to the clients.
Servers are typically physical devices, such as rack-mounted servers, but with the rise of cloud computing, virtual servers have become increasingly common.
Servers handle a variety of processes, such as:
Email services: Managing and sending emails efficiently.
Application hosting: Hosting and Running software applications for users.
Internet connections: Providing web hosting and data access.
Printing services: Managing print jobs across a network.
Examples of a server are:
Web Servers: Apache, Nginx
Database Servers: MySQL, PostgreSQL
Cloud Servers: AWS, Google Cloud
Client-Server Architecture
What Is It?
Client-server architecture is a system where a server hosts and manages resources or services, and a client (like a computer, phone, or tablet) requests these services over a network. It’s also known as the client-server network or network computing model.
In simple words, this model splits tasks between the client and the server. The client sends a request, and the server processes it and sends back the result.
How It Works?
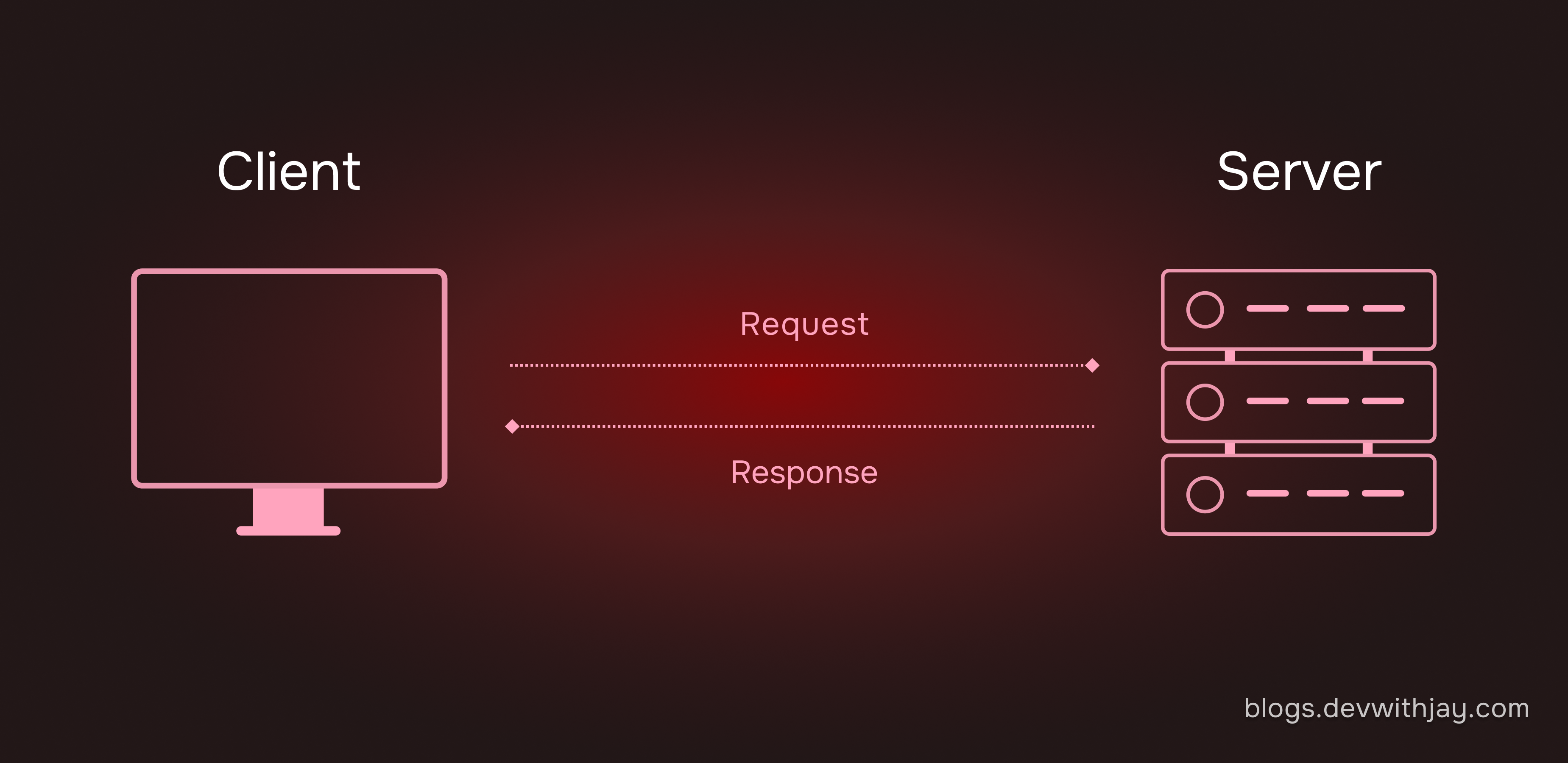
In this model:
Clients send requests to servers for data like web pages or applications.
Servers process these requests and send back the required responses to the clients.
This communication happens over a network, connecting the client and server.
For example, when you open a website, your browser (the client) requests data from the web server. The server processes the request and sends the website's content back to the browser.
Why It Is Required?
Today, many businesses depend heavily on technology to succeed. Client-server architecture helps them:
Collect, process, and share data efficiently.
Manage networks and systems from a central point.
Scale operations easily as businesses grow.
Improve productivity by handling heavy tasks on powerful servers while keeping clients light and fast.
Characteristics
Clients and servers do different tasks and often use different hardware and software.
More devices can be added easily.
It uses stronger or multiple servers for bigger tasks.
A server can handle many tasks at the same time, but each task needs its own program.
Clients and servers follow specific rules (protocols) to share data.
Both clients and servers use all the necessary rules (protocols) to send and receive information correctly.
Advantages
Centralized system: All data and services are stored in one place, making it easier to manage, update, and secure.
Cost-efficient: Clients don’t need much hardware or software. They only need a network connection and an app or browser to access the server.
High performance: The server can handle many client requests quickly and efficiently with low delays.
Disadvantages
Limited scalability: The system depends on the server’s capacity. If the server is overloaded or breaks down, the system may not work properly.
Network dependency: The system relies on the connection between the client and server. If the network is slow or unstable, it can cause delays or errors.
Complex setup: The system has many parts that need to work together. This makes it harder to design, set up, and manage, with challenges like security, synchronization, and compatibility.
Microservices
Microservices architecture is a modern version of the client-server model. Instead of building one large application, it divides the application into smaller, independent parts that communicate using APIs or RPCs. This makes the system easier to scale and more flexible, but it can also make it more complex to manage.
How Do Server-Side Processes Work In a Serverless Architecture?
In serverless computing, all backend processes still run on servers instead of client devices, but they are not deployed on any specific server or set of servers. Backend processes are broken up into functions, which run on demand, and automatically scale up to handle more load. Developers can still build all the functionality that normally runs server-side within a serverless architecture.
Peer-To-Peer Network
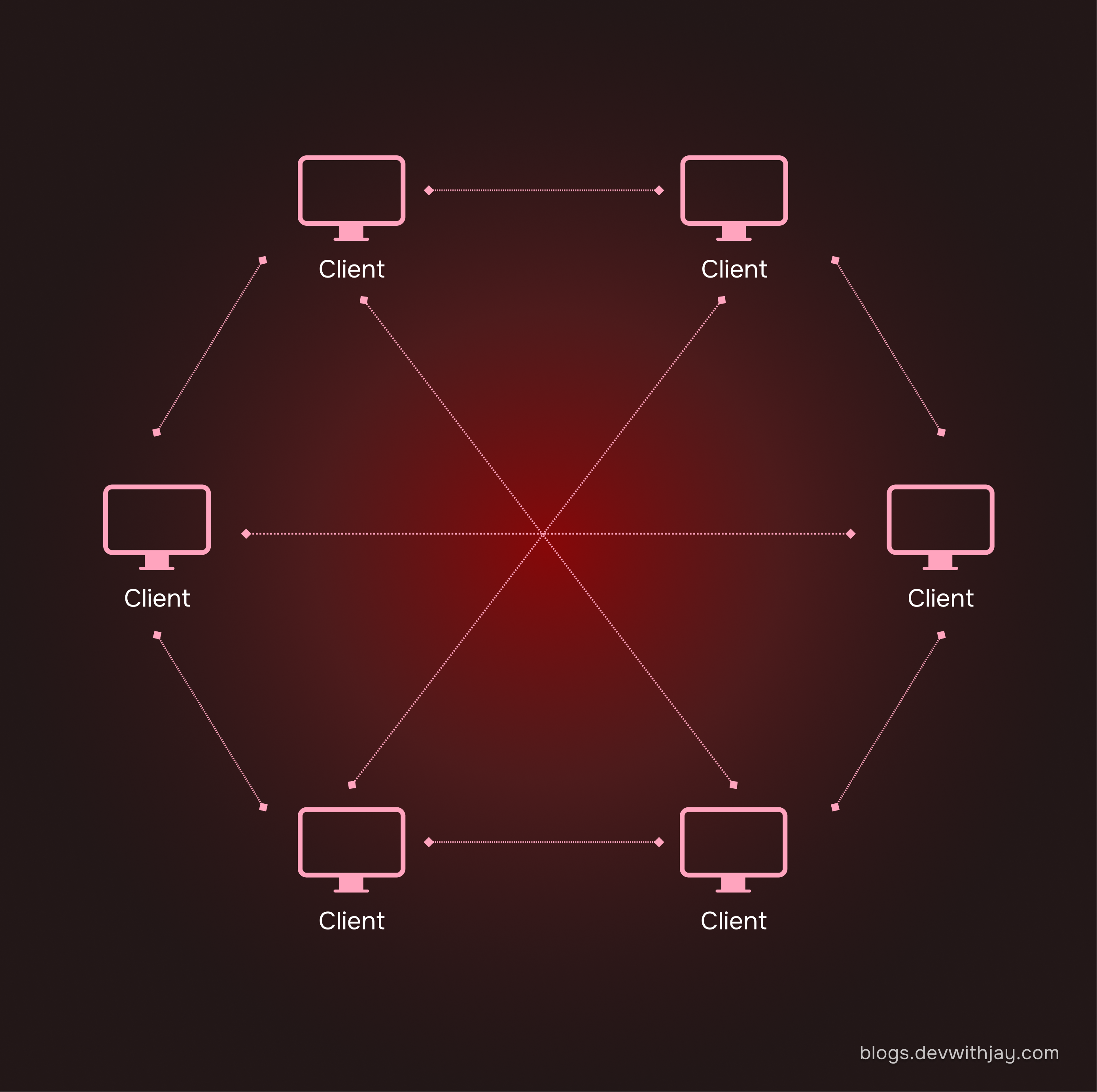
Peer-to-peer (P2P) networks are made up of groups of computers, called nodes or peers, connected in a network. In these networks, each peer acts as both a client and a server.
All peers have the same responsibilities and permissions to manage data. This is very different from the client-server model, where users and servers have specific and separate roles.
Comparison between Client-Server & Peer-To-Peer Network
| Client-Server | Peer-to-Peer (P2P) |
| Needs a central server | No central server |
| Safer with better security | Users are responsible for security |
| Scalable and stable for many users | Performance drops with more users |
| Server failure stops the system | One failure doesn’t affect the network |
| Slower for file sharing | Faster for file sharing |
Conclusion
In this article, we understood that the client-server architecture is a strong and flexible way to manage network resources and applications. It helps IT professionals deal with the challenges of a fast-changing and competitive world by sharing tasks between clients and servers. This system also makes the network scalable, secure, reliable, and high-performing.
If you found this article helpful, share it with others and feel free to leave your feedback—I’d love to hear your thoughts!
Want More…?
I write articles on blog.devwithjay.com and also post development-related content on the following platforms:
Subscribe to my newsletter
Read articles from Jay Kadlag directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by