Pasang DeepSeek* di Rumah Anda Sendiri: Beberapa Cara Menjalankan Self-Hosted LLM
 Affan Basalamah
Affan BasalamahTable of contents
Ceritanya apa ini?
Beberapa hari terakhir ini terjadi gonjang-ganjing di dunia jagat teknologi AI dengan peluncuran model AI LLM (Large Language Model) dari China bernama DeepSeek. Mengapa jadi heboh? Karena dengan model yang mendekati kualitas dari LLM dari OpenAI bernama ChatGPT, dia ditawarkan dengan harga akses yang sangat murah, dan bukan hanya akses ke DeepSeek yang sangat murah, bahkan model ini bisa anda simpan di sistem (server atau cluster) anda sendiri.

Disclaimer dulu
Topik AI ini sangat menarik, tapi saya coba hanya membahas tentang bagaimana menjalankan AI ini di infrastruktur lokal, karena latar belakang saya lebih kepada infrastruktur IT. Kalau ditanya AI itu bagaimana, isinya apa secara mendetail, saya pun sedang mempelajarinya juga. Bisa juga belajar AI dengan AI, tanya aja ke ChatGPT atau DeepSeek, tapi saya lagi suka baca buku ini: https://www.oreilly.com/library/view/ai-engineering/9781098166298/

Kenapa DeepSeek dicari-cari orang?
Beberapa alasan mengapa DeepSeek dicari-cari orang bisa saya jelaskan sedikit:
DeepSeek merupakan AI reasoning model yang memiliki performa yang mendekati AI yang sudah terkenal yaitu OpenAI, jadi performanya 11-12 dengan barang yang sudah ada
DeepSeek tersedia dalam bentuk opensource, dapat didownload dan dijalankan pada infrastruktur sistem sendiri, di server sendiri, di datacenter sendiri, dan ini big deal untuk beberapa orang yang ingin memanfaatkan AI untuk keperluan pengolahan data yang bersifat konfidensial/rahasia.
DeepSeek yang tersedia dalam bentuk yang dapat didownload oleh semua orang memungkinkan AI bisa dijalankan oleh orang US yang nggak ingin datanya disimpan di China, atau orang China yang nggak ingin datanya disimpan di US, atau orang non-US dan non-China yang nggak ingin datanya disimpan di US atau China.
DeepSeek juga teresedia dalam bentuk “distilled model”, yaitu model yang “diencerkan”, dibuat lebih kecil ukurannya tanpa mengurangi esensi dari isi model tersebut. Gunanya apa? Agar model ini bisa didownload dan dijalankan pada sistem yang cukup kecil, contohnya:
Sistem dengan GPU server dengan VRAM 8GB
Sistem dengan GPU desktop dengan VRAM 24GB, atau 2 GPU atau 4 GPU dirangkai jadi satu
Sistem tanpa GPU, hanya mengandalkan CPU dengan memori 1 GB sampai 8 GB atau 16 GB
DeepSeek di lokal, sesuai dengan keperluannya
Model LLM DeepSeek ini tersedia secara gratis di platform hosting LLM HuggingFaces dan dapat didownload sendiri untuk di-load ke sistem anda sendiri, dengan catatan anda memilki kemampuan komputasi yang cukup untuk menjalankan model ini. Berbeda dengan ChatGPT dari OpenAI, anda nggak bisa menyimpannya di server anda. Seberapa besar kekuatan komputasi yang diperlukan untuk menjalankan model DeepSeek ini? Dengan total parameter 671 billion dan 37 billion parameter yang diaktifkan, tidak sembarang sistem dapat menjalankan model ini untuk disimpan di tempat anda sendiri.
Mari kita diskusikan satu persatu:
DeepSeek lokal dengan 671 B parameter
Ini versi full version, basically kalau anda bisa pakai ini di lokal, ya anda punya DeepSeek yang sama seperti DeepSeek di https://chat.deepseek.com/. Tapi ya gitu, resources nya cukup besar. Setidaknya nggak perlu sebesar resource yang diperlukan untuk menjalankan layanan yang diakses orang sedunia, tapi minimal di tempat anda sendiri itu kapabilitasnya sudah sama seperti yang di tempat aslinya.
Barangnya yang mana sih? Ini nih barangnya:
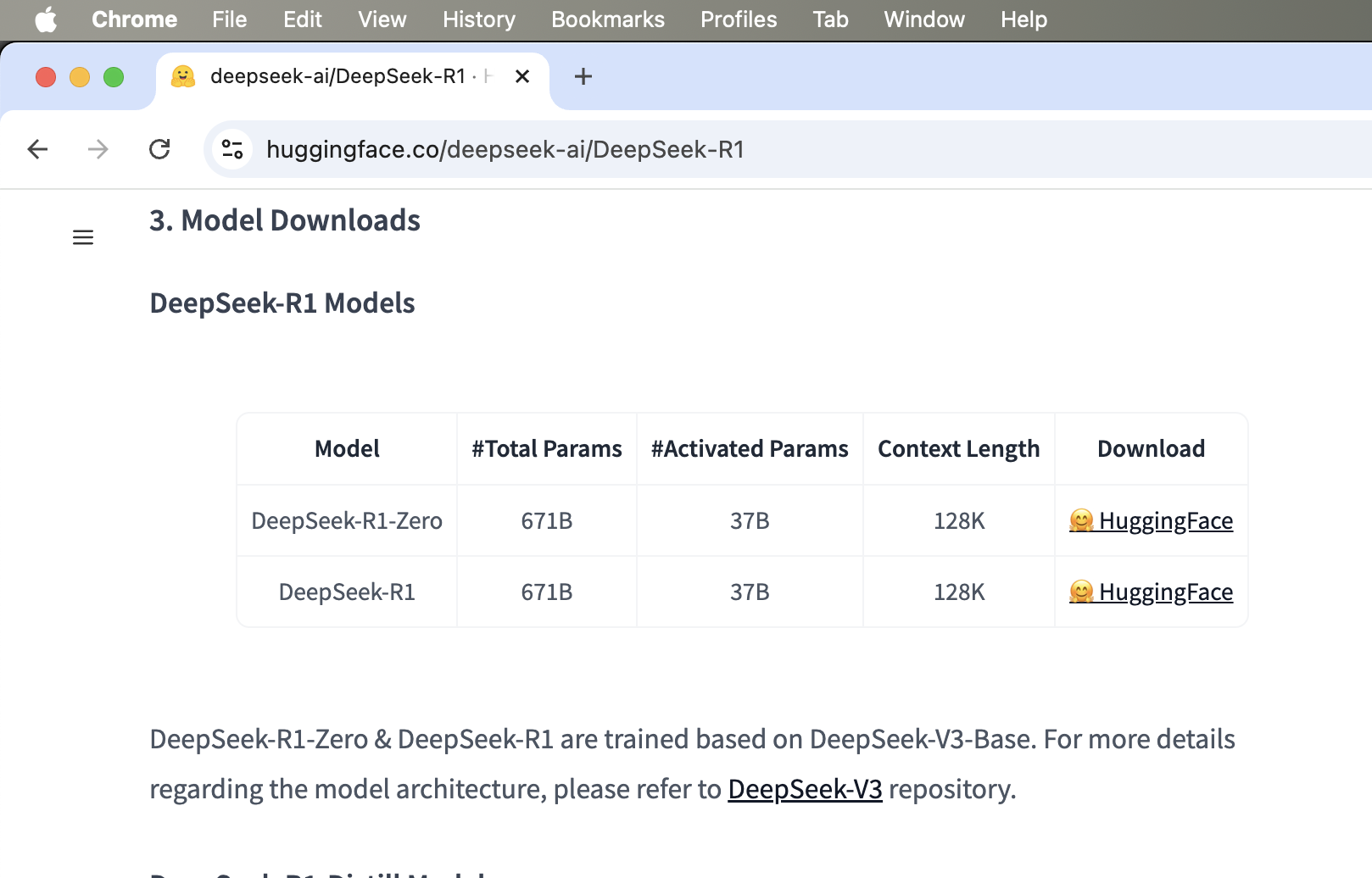
Saya sih nggak punya resource untuk menjalankan ini, tapi dari gonjang-ganjing di jagad AI di Internet, saya menemukan beberapa orang yang mencoba menjalankan DeepSeek ini di lokal, ada tulisannya: https://digitalspaceport.com/running-deepseek-r1-locally-not-a-distilled-qwen-or-llama/
Saya coba ringkaskan ceritanya video ini untuk anda: Jadi orang ini pakai server bekas Dell R930, server yang generasinya sama dengan server yang saya pakai di datacenter rumah sendiri, tapi spek nya lebih gede, lebih haus daya listrik, prosesornya ada 4 (quad socket), dan memorinya gede banget sampai 768GB. Kira-kira kayak gini:
Dell R930. Ini barang mahal, orang luar ada aja sih nemu di eBay, saya cek di toko hijau nggak ada, adanya Dell R910, yang lebih jadul
Xeon E7-8890V4 CPU, 24 core, 48 thread, ada 4 biji, total 192 thread, cek aja makan listriknya segede apa
Memori nya 1,5TB dengan total slot memori nya ada 96, kepingnya 16GB.
Ada ceritanya dan cukup kompleks juga sih. Tapi seru ya.
BTW sudah baca ceritanya saya bikin datacenter di rumah sendiri? Ini ceritanya:
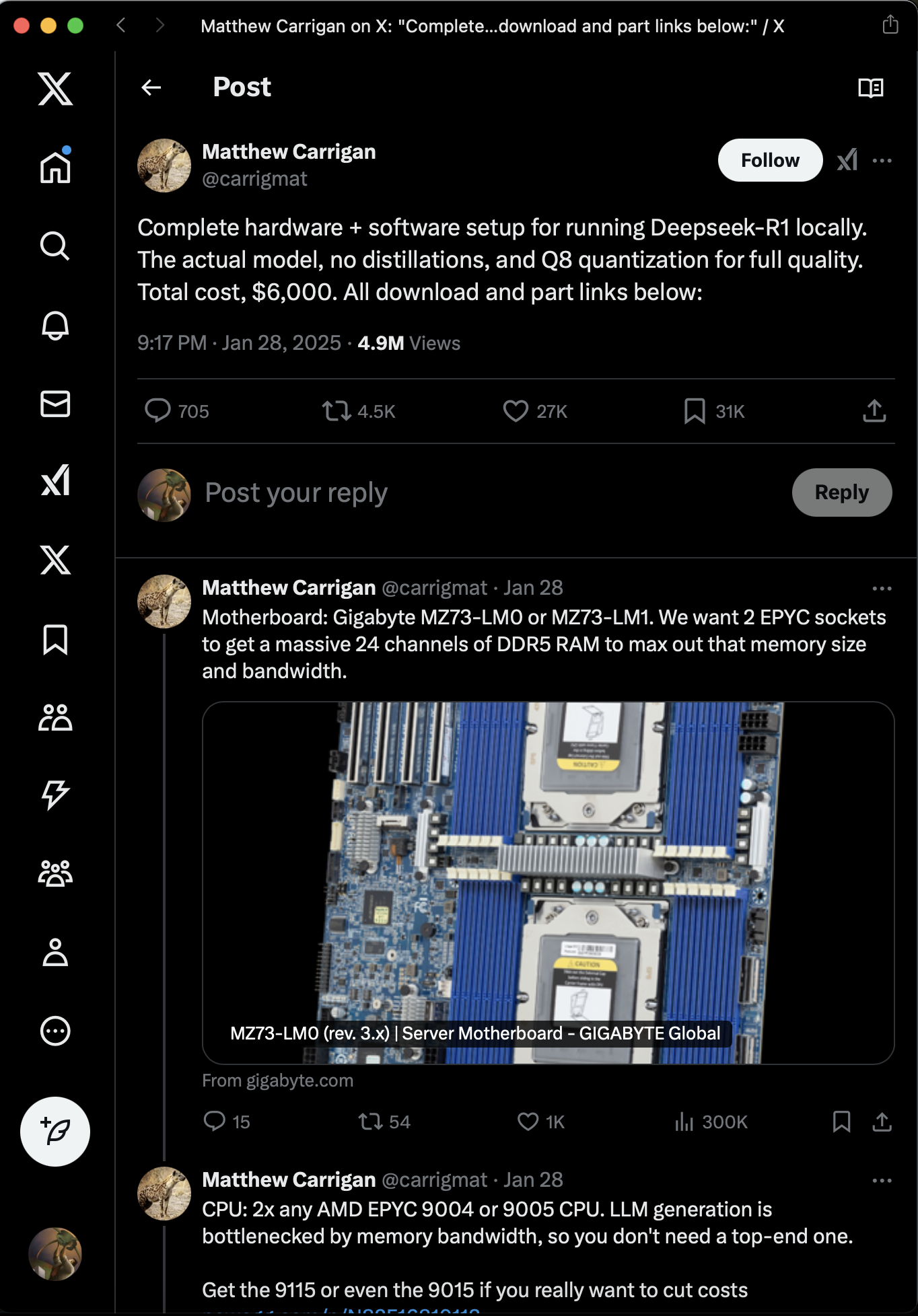
Ada satu lagi orang di Twitter, namanya Matthew Carrigan, dia bilang kalau bikin sistem seperti ini harganya US$ 6000 aja. Mau coba? Ini link twitternya: https://x.com/carrigmat/status/1884244369907278106 (maaf ini embedding Twitter nya nggak jalan, saya kasih screenshot nya aja):
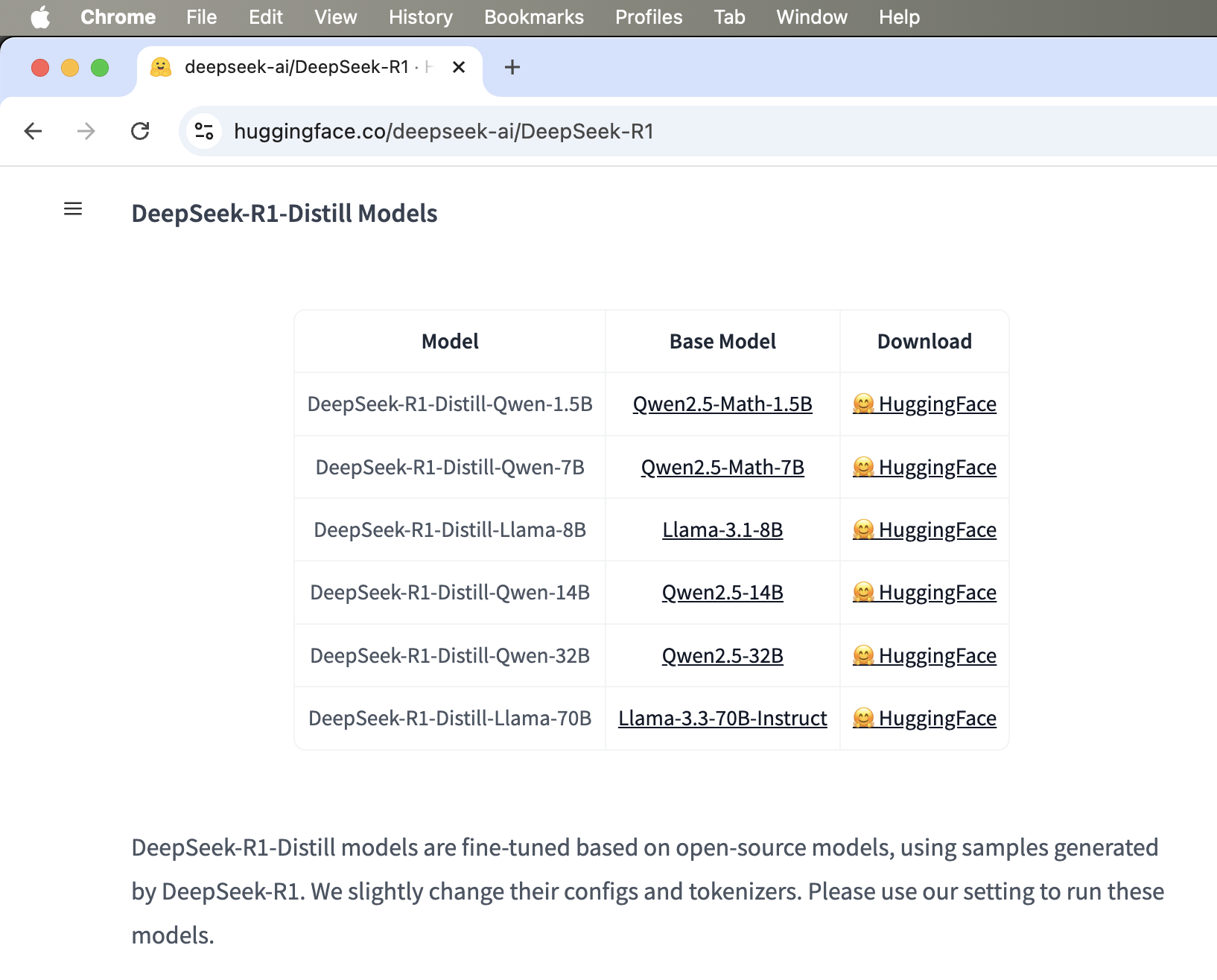
DeepSeek lokal dengan versi distilled: 70, 32, 14, 8, 7, atau 1,5 B parameter
Kalau DeepSeek yang aslinya yang memiliki 671 B itu bisa kita ibaratkan sebagai “biang AI” nya, anggaplah kita bikin AI itu seperti bikin parfum, maka versi distilled nya ini bisa kita ibaratkan sebagai biang yang sudah diencerkan, sehingga hasilnya lebih kecil, sesuai dengan keperluannya dan ia mau dipasang di sistem seperti apa.
Kalau diibaratkan anak sekolah, DeepSeek R1 yang dirilis dan bikin heboh ini adalah ilmu yang dimiliki oleh orang yang sudah bersekolah tinggi dengan kapasitas otak sekelas doktor atau profesor. Kalau ilmu nya profesor ini diberikan kepada anak sekolah dasar, tentu saja tidak akan masuk, bakal bengong dia. Maka ilmu ini harus diencerkan dahulu, modelnya dikecilkan, beberapa komponen nya dikurangi dengan tidak mengurangi esensi keilmuannya, agar bisa diserap oleh orang yang kapasitas otaknya tidak sehebat profesor. Maka dari itu muncullah model DeepSeek “distilled”, yaitu parameter yang sebelumnya ada 671 B ini dikecilkan menjadi 70 B, 32 B, 14 B, 7 B, bahkan 1,5 B. Diibaratkan seperti anak kuliah S1 bisa menyerap 70 B, anak SMA bisa menyerap 32 B, anak SMP bisa menyerap 14 B, anak SD bisa menyerap 7 B, dan anak TK A/B bisa menyerap 1,5 B. Kalau GPU anda di sistem itu ada 8 buah NVidia H100, artinya ini hardware kelas profesor. Kalau GPU anda itu 4 buah NVidia P40, artinya ini hardware kelas anak S1, kalau hanya 1 buah NVidia P40 itu hardware anak SMA/SMP, kalau hanya 1 buah NVidia Tesla P4 seperti yang saya pakai ini kelas anak SD, dan kalau nggak pakai GPU itu kelas anak TK, yang bakal bingung dan ngehang kalau dikasih pengetahuan melebihi kapasitas.
Barangnya yang mana sih? ini dia:
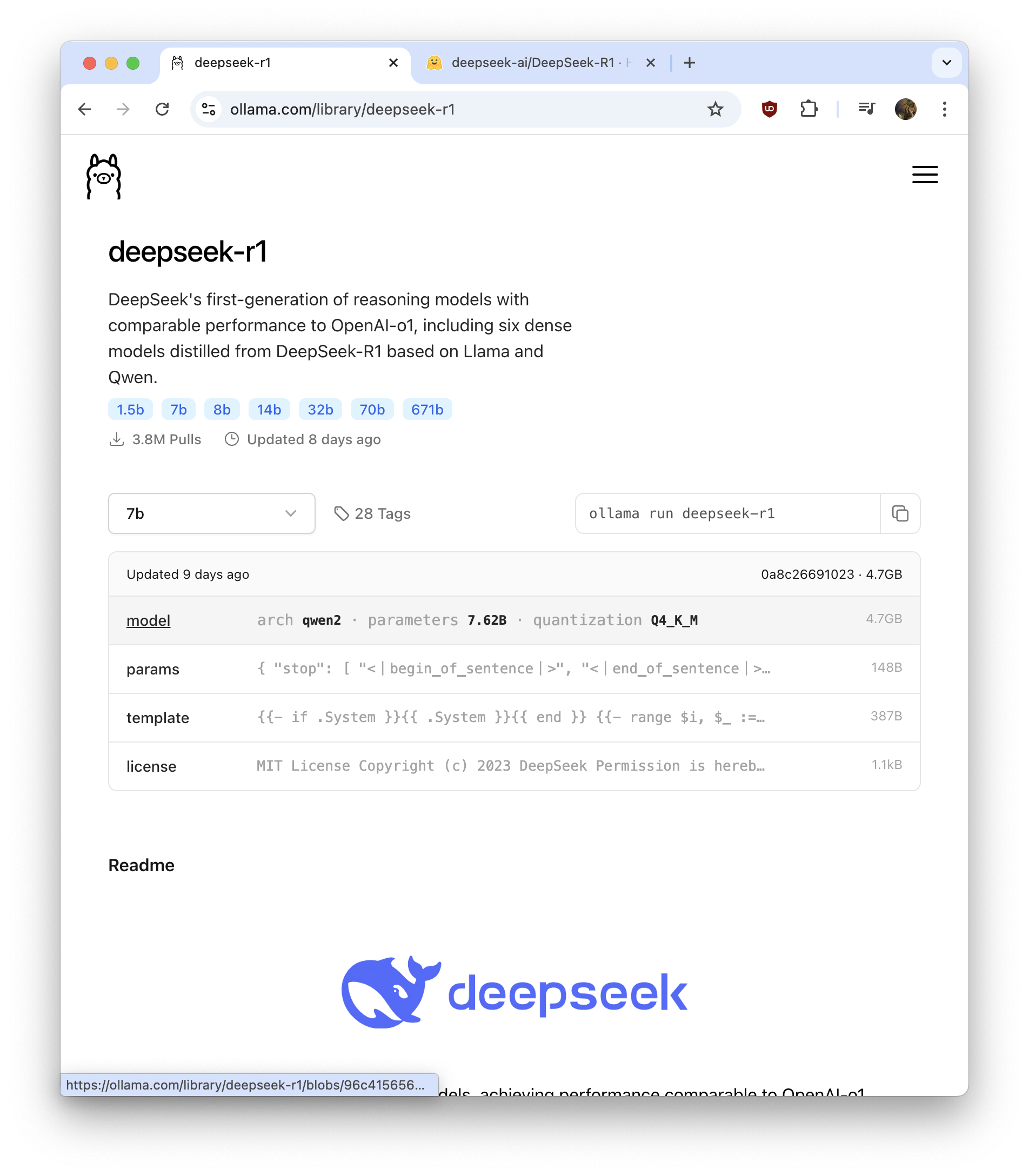
Kalau yang sudah saya coba yaitu menjalankan pada server dengan GPU NVidia. Saya sudah tulis di sini:
Basically saya pasang server dengan GPU NVidia Tesla P4, lalu buat VM yang dikonfigurasi PCI passthrough agar GPU tadi terbaca oleh VM, lalu menginstall Docker engine di atas OS Ubuntu LTS di VM tadi, lalu jalankan image Docker Compose yang berisi Ollama + WebUI dengan integrasi driver GPU. Tentu saja sebelumnya driver NVidia harus sudah terinstall terlebih dahulu. Lalu setelah Ollama terinstall, kita bisa pilih model deepseek-r1 yang tersedia dari Ollama. Kita pilih model tadi dengan prosedur yang saya tulis di artikel sebelumnya.
Kalau DeepSeek itu sudah dipasang di Ollama + WebUI nya, maka kita bisa bertanya ke DeepSeek lokal dengan interface WebUI nya, jadilah DeepSeek di lokal sendiri.
Kalau anda agak ganteng sedikit dan mau habis listrik agak banyak, anda bisa cari GPU sekelas Tesla K40, P40, atau M40 yang memiliki VRAM sebesar 24 GB. Tapi power consumption nya jadi naik, sebuah nya bisa makan 250 W, apalagi kalau anda pasangkan 4 buah, maka bisa jadi 1 kW sendiri. Tapi enaknya anda bisa pasang model yang ukurannya 70B, yang sudah bisa dipakai membantu anda melakukan coding. Kalau mau lihat caranya gimana, bisa lihat blog nya mas Ariya Hidayat yang pakai Tesla P40/K40 secondhand. Ya iyalah barangnya pasti secondhand, cari aja di toko oren atau toko hijau, kadang-kadang ada yang jual. Blog nya bisa dibaca di sini:
Kalau mau bikin pilihan mendang-mending kepada GPU mana yang mau anda pakai untuk bikin AI di lokal, anda bisa buka situs ini, basically dia membandingkan GPU mana yang VRAM nya (dan spesifikasi lainnya) dibandingkan dengan harganya, baik beli bekas di eBay atau beli baru. Kalau dilihat secara spek dan harga, ya NVidia Tesla seri K- atau seri M- itu yang paling oke. Kalau GPU NVidia Tesla P4 yang saya pakai dikira agak lumayan.
Ada juga video orang di luar sana yang bikin sistem K40 digabung ada 4 biji. Kalau ketemu barangnya bisa jalankan DeepSeek dengan 70 B, sudah cukup lumayan buat coding assistant. Video nya di sini: https://www.youtube.com/watch?v=dHTvpUlWFbk
Kalau Jeff Geerling yang secara de facto dianggap sebagai brand ambassador Raspberry Pi bahkan menjalankan DeepSeek di Raspberry Pi dibantu dengan external GPU, video nya di sini: https://www.youtube.com/watch?v=o1sN1lB76EA
Bisa nggak jalankan DeepSeek di lokal server/komputer tanpa GPU?
Pasang di PC yang nggak pakai GPU juga bisa, tapi CPU nya ngeden dia, dipanjer semua core nya menyala, utilisasi semua core jadi 100 persen. jadinya operasinya hanya dapat beberapa token per detik. Dan ini kejadian juga di VM saya kalau entah kenapa si Ollama itu nggak nyambung ke NVidia driver ke GPU nya, jadinya dia pakai semua CPU core di VM nya itu.
Ada sih yang coba dengan WebGPU atau tools-tools lain untuk menjalankan DeepSeek di lokal, tapi sampai tulisan ini saya buat, saya belum sempat mengeksplorasi lebih lanjut.
Penutup
Sebenarnya semua gonjang-ganjing dengan DeepSeek ini adalah memperingati munculnya sebuah alternatif LLM yang modelnya terbuka, dapat dipasang sendiri di sistem yang nggak “phone home”, walaupun masih cukup mahal, tapi setidaknya ada oportuniti untuk membuat sistem AI sendiri, walaupun foundation model nya masih pakai bikinan luar. Dan ini akan mentrigger orang-orang yang bikin foundation model AI yang sebelumnya tertutup seperti OpenAI untuk membuka model nya agar orang lain juga pakai. Ini persis seperti jaman OS closed source seperti Windows NT atau UNIX berbayar yang berhadapan dengan OS opensource seperti Linux dan Free/Net/OpenBSD, yang akhirnya memaksa OS closed source itu mengembrace open model, yang akan memberikan manfaat kepada semua orang, bukan hanya kepada pemodal besar saja.
Mudah-mudahan tulisan saya ini berguna bagi anda yang ingin mendapat sedikit gambaran tentang bagaimana mendeploy AI di infrastruktur lokal milik sendiri, dalam kasus ini menggunakan model AI DeepSeek yang sedang populer.
Wassalam.
Subscribe to my newsletter
Read articles from Affan Basalamah directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by