Building an Async Similarity Search System from scratch with FastAPI and Qdrant VectorDB
 Pruthviraj Mahalunge
Pruthviraj MahalungeTable of contents
- Introduction
- Technologies We’ll use
- Why Use Qdrant for Semantic Search?
- Why Use Async?
- Understanding the Workflow
- Prerequisites
- Project Structure
- Adding Data to Qdrant via CSV
- Building the Semantic Search API
- Running and Testing the Application
- Example Query & Result Breakdown
- Advantage with Semantic Search
- Improvements
- Conclusion
Introduction
Search engines and retrieval systems have evolved to become remarkably intelligent. They no longer rely on exact keyword matches or rigid rules to find what you're looking for. Instead, they understand the context and meaning behind your query, allowing you to retrieve information or objects from a database with just a vague hint. For example, consider an e-commerce platform where users search for products. A traditional keyword-based search might struggle if the search terms do not exactly match product descriptions. However, with semantic search, a user looking for "comfortable running shoes for long-distance" can receive relevant results, even if the product descriptions contain phrases like "marathon-ready sneakers with superior cushioning.”
The capabilities of semantic search systems extend far beyond text-based queries. By taking it a step further, you can enable users to search not just with text, but also with images, voice, and other forms of input. Semantic search relies on vector embeddings, which capture the deeper relationships between different data points to deliver highly relevant and contextually accurate results. This makes it a powerful tool for a wide range of applications, from E-commerce and Media & Entertainment to Smart Assistants. Let’s explore the key components needed to build such a system and unlock its potential across diverse industries.
Implementing a Semantic Search system
In this blog, we’ll walk you through implementing a semantic search system using Async FastAPI, Qdrant, and Sentence-Transformers to deliver efficient, context-aware search capabilities. Among the many vector database options available, we’ve chosen Qdrant for its exceptional support for fast, asynchronous retrieval, ensuring high performance and scalability—perfect for real-time applications. Let’s understand how it goes.
Technologies We’ll use
To build this system, we’ll leverage:
Qdrant: A powerful, open-source vector database for efficient similarity searches.
Sentence-Transformers: For generating high-quality embeddings from text data.
Async FastAPI: To create a lightweight, asynchronous API for seamless query handling.
Qdrant
Qdrant is an advanced vector database designed to store and search high-dimensional vector embeddings. Its scalability and efficiency make it ideal for semantic search use cases, providing powerful support for similarity-based queries. We are using Qdrant, not only for it’s speed and accuracy, but also because of it’s async nature. That allows us to reduce memory usage, allow support for multiple users simultaneously, improving the number of concurrent requests that can be handled. You can read more about the Qdrant Async API and what it bring to the table in this Documentation.
After thoroughly evaluating Qdrant and adopting it into FutureSmart AI's workflows, we’ve seen the value it brings firsthand. We encourage you to explore Qdrant further and visit their official page to learn more about their offerings and capabilities.
Sentence-Transformers
Sentence-Transformers is a powerful library designed to transform text into dense vector embeddings, enabling a deeper semantic understanding of textual data. These high-dimensional vectors are essential for tasks like semantic search, similarity matching, and clustering.
Want to explore Sentence-Transformers in action? YouTube Tutorial , for a hands-on guide to dive deeper into real-world applications. 🚀
Fastapi
FastAPI is a cutting-edge, high-performance web framework for building APIs with Python. It leverages asynchronous programming for creating fast, scalable applications and uses Python type hints to ensure clarity, robustness, and developer productivity.
Want to master FastAPI? FastAPI Tutorial for step-by-step guidance to understand its core features and best practices. 🌟
Why Use Qdrant for Semantic Search?
Qdrant is a high-performance vector database designed specifically to power semantic search systems. It allows efficient and scalable storage and retrieval of embeddings, which represent the meaning of data points as vectors.
Key Advantages of Using Qdrant :
Efficient Vector Search: 🚀 Qdrant is optimized for handling large-scale vector search queries with low latency, making it ideal for real-time semantic search applications.
Scalable Architecture: 🌍 Built for horizontal scaling, Qdrant can support massive datasets while maintaining quick query responses, ensuring it handles growing data demands efficiently.
Real-Time Updates: 🔄 Qdrant supports real-time indexing and updating of vector embeddings, allowing quick integration of new data points as they become available.
Advanced Indexing Techniques: 🔍 Qdrant uses efficient indexing algorithms like HNSW (Hierarchical Navigable Small World), making vector searches fast even with a huge volume of data.
Seamless Integration: 🔗 Qdrant integrates easily with frameworks like FastAPI, enabling smooth deployment of semantic search systems in modern applications.
Why Use Async?
Incorporating asynchronous processing enhances the efficiency and scalability of semantic search. By allowing multiple search queries to be processed concurrently without blocking the system, async offers significant benefits, particularly for large-scale applications.
Benefits of Async in Semantic Search with Qdrant:
High-Volume Applications: 📈 Async enables high-throughput systems, allowing efficient handling of large numbers of simultaneous search queries—critical for large-scale or enterprise-level applications.
Low Latency and Seamless User Experience: ⏱️ Non-blocking asynchronous operations reduce response times, improving the user experience by minimizing delays in real-time semantic search, especially when powered by Qdrant.
Optimized Resource Utilization: ⚙️ Async operations maximize system efficiency by handling multiple tasks concurrently, leveraging non-blocking I/O, and minimizing resource wastage.
Native Support in FastAPI: 🌐 FastAPI’s built-in async support makes it a natural fit for building scalable, high-performance semantic search systems.
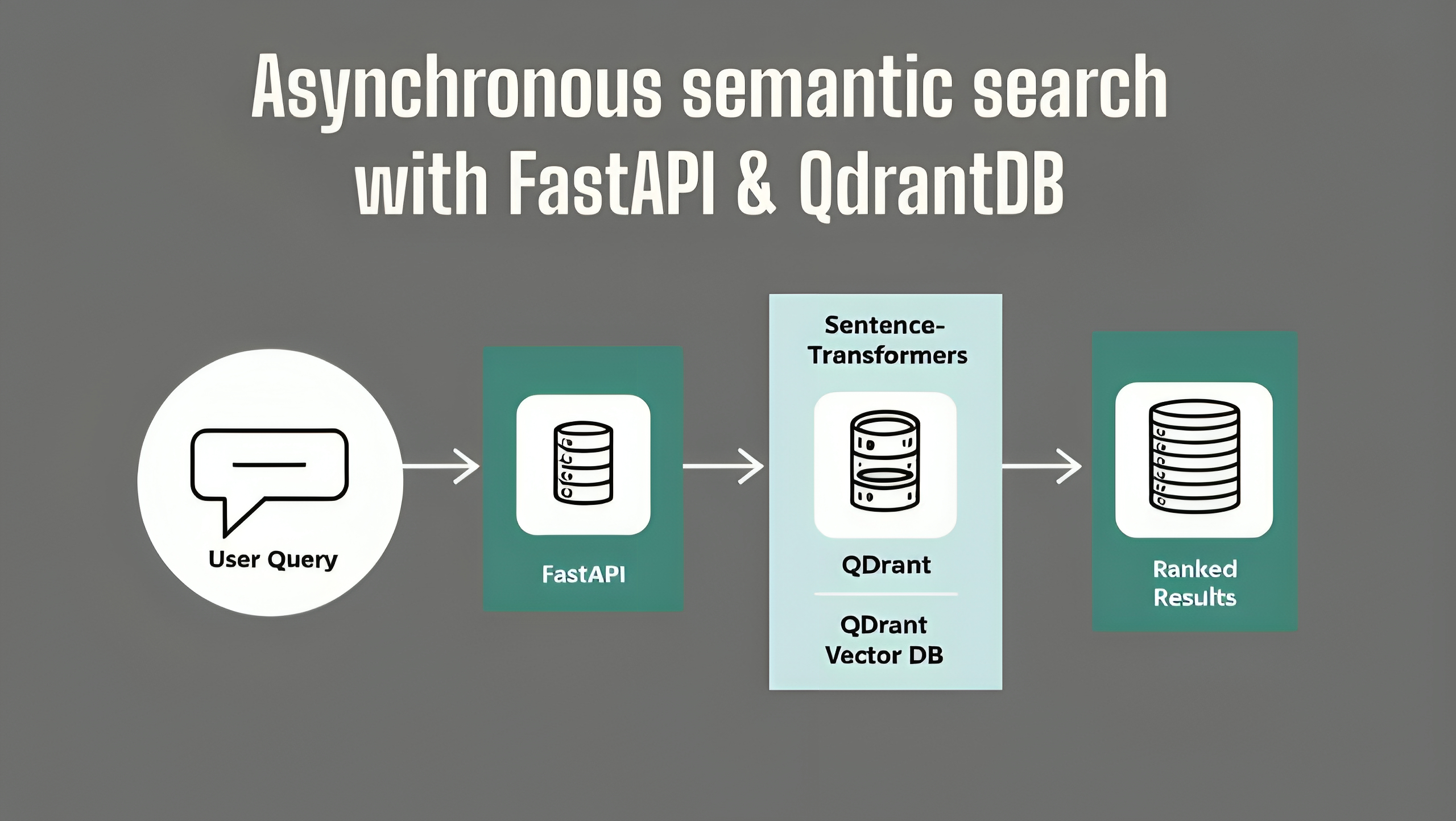
Understanding the Workflow
The user submits a search query via an asynchronous FastAPI endpoint.
Qdrant processes the query and performs semantic similarity matching using precomputed embeddings.
Results are ranked by relevance, ensuring accurate information delivery.

Prerequisites
1. System Setup
Before you begin, ensure that the following components are installed:
1.1 Python
- Ensure you're using Python 3.8 or later.
1.2 Qdrant
Qdrant should be up and running, either locally or hosted on a cloud service.
If you're unfamiliar with Qdrant or need assistance with its setup, check out this in-depth guide we wrote as first part of our series. Comprehensive Guide to Installing and Using Qdrant VectorDB with Docker Server and Local Setup.
1.3 Required Libraries
Install the necessary libraries using the following command:
pip install fastapi uvicorn sentence-transformers qdrant-client
Project Structure
Here’s the project structure:
plaintextCopy code
semantic-search-system/
├── app/
│ ├── __init__.py
│ ├── main.py # FastAPI application and routes
│ ├── utils.py # Helper functions (e.g., read_and_store_data)
│ ├── qdrant_utils.py # Helper function to upsert data to Qdrant
│ └── models.py # Define Pydantic models
├── vehicle.csv # CSV file with vehicle data
└── requirements.txt # List of dependencies
Adding Data to Qdrant via CSV
1. CSV File Preparation
The data from the CSV file will populate Qdrant for semantic search vectors. Here is a sample of the vehicle.csv file, which contains the following columns:
| id | name | category | description |
| 1 | Toyota Camry | Sedan | A reliable and fuel-efficient car |
| 2 | Ford Explorer | SUV | A spacious SUV ideal for family trips |
| 3 | Chevrolet Silverado | Pickup Truck | A rugged and versatile pickup truck, perfect for heavy-duty tasks |
This .csv file should be saved in your project directory for easy access during data import.
2. Initializing the Qdrant Client
Before inserting data into Qdrant, initialize the Qdrant client with the AsyncQdrantClient from the qdrant-client library. The create_qdrant_collection function will connect to Qdrant and create a collection for your data, provided one doesn't already exist. A vector size and a distance metric (Cosine similarity in this case) need to be defined for accurate semantic search.
app/qdrant_utils.py:
import qdrant_client
from qdrant_client.models import VectorParams
from app.config import QDRANT_COLLECTION
# Initialize Qdrant client
qdrant = AsyncQdrantClient("<http://localhost:6333>")
# Create collection in Qdrant vector database
async def create_qdrant_collection():
await qdrant.create_collection(
collection_name="vehicles",
vectors_config=VectorParams(size=384, distance="Cosine")
)
Vector Size: The dimensionality of the embedding vector, which should match the output from the Sentence-Transformer model. Here, we choose 384 dimensions for the model.
Cosine: A similarity measure used to compute how similar two vectors are, which is perfect for comparing semantic meaning.
3. Async Data Insertion
Now that we have set up the Qdrant collection, it's time to insert data from the CSV file. Each textual column in the CSV (name, category, description) is passed through the Sentence-Transformer model to create vector embeddings, which are then stored in Qdrant.
app/utils.py:
import pandas as pd
from sentence_transformers import SentenceTransformer
# Initialize the Sentence-Transformer model globally
model = SentenceTransformer("all-MiniLM-L6-v2")
def generate_vector(text: str):
"""Generate vector embeddings for a given text."""
return model.encode(text).tolist()
async def upsert_data_to_qdrant(qdrant, df):
"""Upsert data from DataFrame to Qdrant vector database."""
vectors = [
generate_vector(f"{row['name']} {row['category']} {row['description']}")
for _, row in df.iterrows()
]
try:
# Insert the data into Qdrant
await qdrant.upsert(
collection_name="vehicles",
points=[{
"id": int(row['id']),
"vector": vector,
"payload": {"name": row['name'],
"category": row['category'],
"description": row['description']}
}
for vector, (_, row) in zip(vectors, df.iterrows())
]
)
except Exception as e:
print(f"Error inserting data into Qdrant: {e}")
raise e
async def read_and_store_data(csv_file_path, qdrant):
"""Reads CSV and upserts into Qdrant."""
df = pd.read_csv(csv_file_path) # Load CSV into a DataFrame
# Upsert to Qdrant
await upsert_data_to_qdrant(qdrant, df)
This approach ensures efficient handling of large datasets with asynchronous processing. The generate_vector function utilizes the all-MiniLM-L6-v2 Sentence-Transformer model to create meaningful vector embeddings by combining the name, category, and description fields. These embeddings capture the semantic meaning of each vehicle, improving search accuracy.
By using Qdrant's upsert operation, we prevent duplicate entries while allowing seamless data updates. Additionally, you can manage and inspect your Qdrant collection using the Qdrant dashboard, where you can view inserted data, monitor collection health, and perform advanced searches.
For learning more about accessing the Qdrant Web UI, you can refer to our previous blog : Comprehensive Guide to Qdrant Vector DB: Installation and Setup.
Building the Semantic Search API
Pydantic Model
Pydantic models provide a robust way to validate and serialize data, and they are integral to FastAPI's request handling. We define a QueryRequest model to structure incoming data for the search endpoint. This model will specify the expected query string and the limit for the number of search results:
app/models.py:
from pydantic import BaseModel
class QueryRequest(BaseModel):
query: str # The search query entered by the user
limit: int # The number of search results to return
Qdrant Search Function
For semantic search, we leverage Qdrant, a vector database. The function generates a query vector from the input query using the SentenceTransformer model, which translates the user's query into a vector representation. We then search Qdrant for vectors similar to the query vector.
app/search.py:
from app.qdrant_utils import qdrant
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
async def qdrant_search(query: str, limit: int):
# Convert the user's query into a vector
vector = model.encode(query).tolist()
search_result = await qdrant.search(
collection_name="vehicles", # The collection we're searching in
query_vector=vector,
limit=limit # Limit the number of results returned by Qdrant
)
# Format the search results for consistency
results = [{
"id": res.id,
"name": res.payload.get("name"),
"category": res.payload.get("category"),
"description": res.payload.get("description"),
"score": res.score # Semantic similarity score
} for res in search_result]
return results
FastAPI Endpoint for Search
Now, we implement the FastAPI endpoint that ties everything together. This endpoint listens for a POST request at /semantic_search, where it receives a query and a limit for the results. It fetches results from Qdrant using vector-based semantic search.
API Definition:
app/main.py:
from fastapi import FastAPI, HTTPException
from app.search import qdrant_search
from app.models import QueryRequest
from app.qdrant_utils import qdrant
from app.utils import read_and_store_data
# FastAPI lifecycle event to initialize Qdrant
async def async_lifespan(app: FastAPI):
await create_qdrant_collection() # Ensures the Qdrant collection exists
await read_and_store_data('vehicle.csv', qdrant) # Load initial data
yield # Yield control, FastAPI will now handle incoming requests
app = FastAPI(lifespan=async_lifespan)
@app.post("/semantic_search")
async def search(query_request: QueryRequest):
# Perform semantic search in Qdrant
results = await qdrant_search(query_request.query, query_request.limit)
# Return the results
return {"results": results}
How This Works:
Qdrant Search: The function queries Qdrant for results based on semantic similarity using vector-based search.
Return Results: The search results from Qdrant are returned, respecting the limit set by the user.
Running and Testing the Application
To run the application, use Uvicorn, a fast ASGI server:
uvicorn main:app --reload
Once the server is running, you can use the /semantic_search endpoint to query the Qdrant database.
If everything is configured correctly, you will receive semantic search results similar to the example shown below.
Demo :
Example Query & Result Breakdown
Sample Query :
Make a POST request to/semantic_search with the following payload:
{
"query": "sporty bikes",
"limit": 3
}
Expected Output :
{
"results": [
{
"id": 17,
"name": "Ducati Monster",
"category": "Motorcycle",
"description": "A sporty motorcycle with a distinctive design and powerful performance.",
"score": 0.5491828
},
{
"id": 29,
"name": "Yamaha YZF-R3",
"category": "Motorcycle",
"description": "A lightweight sport motorcycle ideal for beginners and experienced riders alike.",
"score": 0.52757794
},
{
"id": 9,
"name": "Harley-Davidson Street 750",
"category": "Motorcycle",
"description": "A cruiser motorcycle with a classic design and powerful engine.",
"score": 0.47901446
}
]
}
Advantage with Semantic Search
Unlike traditional keyword-based search, which depends on exact keyword matches, vector search retrieves results based on semantic similarity. This means the system focuses on the intent behind queries and the contextual meaning of terms, providing a more intelligent and effective search experience for modern applications.
Example Query: "sporty bikes "
Traditional Keyword Search:
Returns only results that explicitly include the word "bikes" in their name or description.
Misses relevant items such as Ducati Monster, a motorcycle not explicitly labeled as "sporty bikes."
Vector Search (Semantic Approach):
Recognizes that "bikes" and "motorcycles" are semantically similar and retrieves items that are contextually related, like sporty motorcycles, even when the word "bikes" is not directly mentioned.
The system also ranks results using relevance scores, indicating how closely each result aligns with the intent behind the query.
Comparison of Search Approaches
| Search Type | Search Process | Result Quality |
| Keyword-Based (Traditional) | Matches only exact terms in queries and results | Limited, misses semantically related results |
| Vector Search (Semantic) | Focuses on contextual and semantic meaning | Relevant, context-aware results |
Improvements
You can enhance the performance of the semantic search system by fine-tuning the embedding model on domain-specific data to improve result relevance.
You can experiment with multimodal search, allowing for querying with images, voice, or other media types, expanding the search functionality.
Adding filtering capabilities would allow for more precise search results, enabling users to refine searches based on metadata like date ranges.
Conclusion
Through this step-by-step guide, you've learned how to build a semantic search system with FastAPI and Qdrant, integrating modern vector-based search techniques to create an efficient and scalable solution. By leveraging embeddings, you can enhance search relevance and deliver more accurate results for your applications.
But this is just the beginning. As you continue exploring Qdrant, consider diving into its advanced capabilities, such as hybrid search and large language model integrations, to further refine your search experience.
At FutureSmart AI, we specialize in developing AI-driven solutions tailored to your business needs, from semantic search to custom AI Solutions. If you're looking for expert guidance or custom AI solutions, reach out to us at contact@futuresmart.ai.
Let’s build the future of AI together! 🚀
Subscribe to my newsletter
Read articles from Pruthviraj Mahalunge directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by