Speeding Up Llama 3.3 70B with Affordable Cloud GPUs
 NovitaAI
NovitaAI
Key Highlights
Llama 3.3 70B: Meta’s advanced 70B-parameter language model, excelling in multilingual tasks and efficiency.
Cloud GPUs: Scalable, cost-effective resources for deploying and fine-tuning models like Llama 3.3 70B.
Novita AI: A flexible, affordable platform offering powerful GPUs and tools to easily utilize Llama 3.3 70B.
Cloud-based solutions offer a cost-effective alternative to expensive local hardware. You can use GPU Instances from Novita AI — Upon registration, there are 60GB free in the Container Disk and 1GB free in the Volume Disk, and if the free limit is exceeded, additional charges will be incurred.The release of Meta’s Llama 3.3 70B model signifies a major advancement in accessible and powerful language models. This article presents a technical overview of Llama 3.3 70B, detailing its capabilities and how to effectively leverage it using cloud GPU resources, with a focus on solutions available through Novita AI.
What is Llama 3.3 70B?
Llama 3.3 70B is a large language model (LLM) with 70 billion parameters developed by Meta, optimized for text-based tasks such as multilingual chat, code generation, and synthetic data generation. It is available for both commercial and research purposes and excels in multilingual dialogue scenarios, outperforming many open-source and proprietary chat models on industry benchmarks.
Key Features
Model Architecture: Built on an optimized transformer architecture, Llama 3.3 employs supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF). It utilizes Grouped-Query Attention (GQA) for enhanced inference scalability.
Context Window Size: Supports a 128k token context window, ideal for processing extensive documents and complex conversations.
Supported Languages: Natively supports eight major languages: English, French, German, Italian, Portuguese, Spanish, Hindi, and Thai, while also being trained on a broader range of languages.
Benchmark
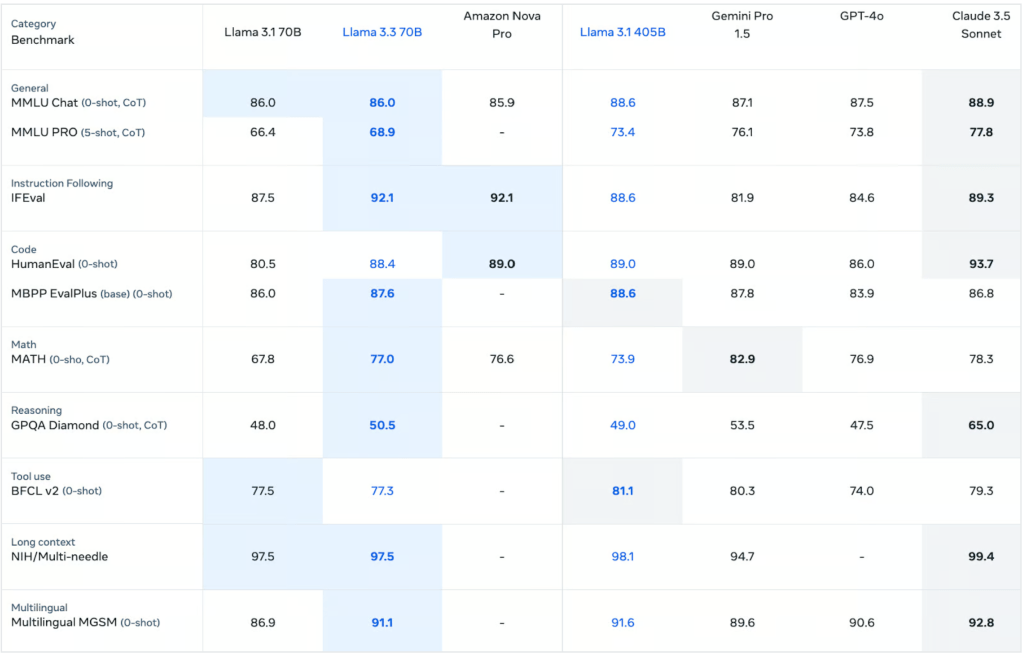
Compared with Other Models
Compared with Other Llama Models
Llama 3.2 3B: This smaller model with only 3 billion parameters is less capable of handling complex tasks but may be more efficient for simpler applications where resource constraints are a consideration.
Llama 3.1 405B: The Llama 3.3 70B provides similar performance to the Llama 3.1 405B model while being smaller in size and incurring reduced computational costs.
Llama 3.1 70B: The Llama 3.3 70B exhibits performance improvements in benchmarks such as MMLU (CoT), MATH (CoT), and HumanEval compared to the Llama 3.1 70B.
Llama 3 70B: Similar in size to the Llama 3.3, it offers high performance but lacks some optimizations present in the newer model.
Compared with Other Models
- Llama 3.3 70B excels in several categories, notably in instruction following (IFEval) and coding (HumanEval and MBPP EvalPlus). GPT-4o performs well in general conversation (MMLU Chat and MMLU PRO) and tool use (BFCL v2), but lags in some reasoning and coding tasks. Claude 3.5 Sonnet outperforms in most categories, especially in coding (HumanEval), reasoning (GPQA Diamond), and multilingual capabilities (Multilingual MGSM).
Applications
Llama 3.3 70B can be utilized in various applications:
AI assistants and chatbots
Content generation
Code generation and debugging assistance
Multilingual applications including translation tools
Synthetic data generation
Industry Applications: It can be applied in sectors such as customer support, healthcare, finance, and education.
Limitations: The model may produce inaccurate or biased responses; therefore, developers should conduct safety testing tailored to their specific applications.
Understanding Cloud GPUs

What is Cloud GPUs?
Definition: A cloud GPU is a high-performance graphics processing unit provided as a service by cloud providers, allowing remote access to substantial computational resources without upfront hardware investments.
How it Works: Cloud GPUs offer virtualized resources through virtual machine instances or containerized environments.
Benefits of Using Cloud GPUs
Scalability based on computational needs
Cost-efficiency through pay-as-you-go models
Accessibility to powerful resources for AI tasks
Flexibility in choosing GPU types
How to Choose Cloud GPUs
Key Selection Criteria
GPU Types:
- Opt for high-performance GPUs such as NVIDIA A100 or V100, which excel in handling large-scale model.
Memory Capacity:
- Ensure that the selected GPU has sufficient video memory (typically 32GB or more) to load and run 30B models efficiently.
Computational Power*:*
- Review the GPU’s computational capability (in TFLOPS) offered by the cloud service to ensure it meets the demands of model inference and training.
Pricing Models*:*
- Compare the billing methods (hourly, usage-based, etc.) of different cloud services and select the one that best aligns with your budget and usage frequency.
Community and Ecosystem*:*
- Opt for a cloud service with an active community and abundant resources, making it easier to find use cases and technical support.
Comparison of Access Methods
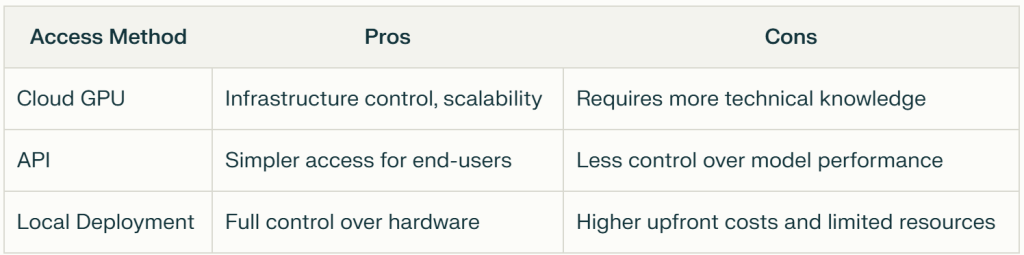
In conclusion, accessing Llama 3.3 offers various options tailored to different user needs.
Cloud GPU is best for casual users looking for quick and easy interaction with the model without technical barriers.
API access is ideal for developers seeking cost-effective integration and flexibility for fine-tuning models without heavy hardware investments.
Local access provides researchers and developers with complete control and customization, suitable for those who prioritize privacy and data security.
Each method has its strengths, allowing users to choose the most appropriate approach based on their specific requirements and resources.
Recommended Cloud GPUs and Providers
Recommended GPUs
NVIDIA A100 (80GB):
Full Fine-tuning (float32 precision): Recommended configuration is 8x NVIDIA A100.
The A100 is designed for high-performance computing and offers exceptional memory bandwidth and computational power, making it ideal for large language models.
NVIDIA H100:
- This GPU is even more powerful than the A100 and is suitable for intensive AI workloads, including training large models like LLaMA 3.3. It features high memory capacity and bandwidth, facilitating efficient processing of large datasets.
NVIDIA RTX 3090:
- For lighter fine-tuning tasks or reduced precision scenarios, the RTX 3090 can be used, especially for models that have been quantized. It provides 24GB of GDDR6X memory, which can handle smaller-scale fine-tuning tasks effectively.
NVIDIA RTX 4090:
- This GPU also offers substantial performance with 24GB of GDDR6X VRAM, making it suitable for medium to large LLMs. It can be utilized for fine-tuning smaller variants of LLaMA or in scenarios where cost efficiency is a priority.
Recommended Providers
Compared with other GPU providers, Novita AI has some advantage.
cost-efficient: reduce cloud costs by up to 50%
flexible GPU resources that can be accessed on-demand
instant Deployment
customizable templates
large-capacity storage
various the most demanding AI models
get 100GB free

How to Access Llama 3.3 70b on Cloud GPUs
Step1: Click on the GPU Instance
If you are a new subscriber, please register our account first. And then click on the GPU Instance button on our webpage.
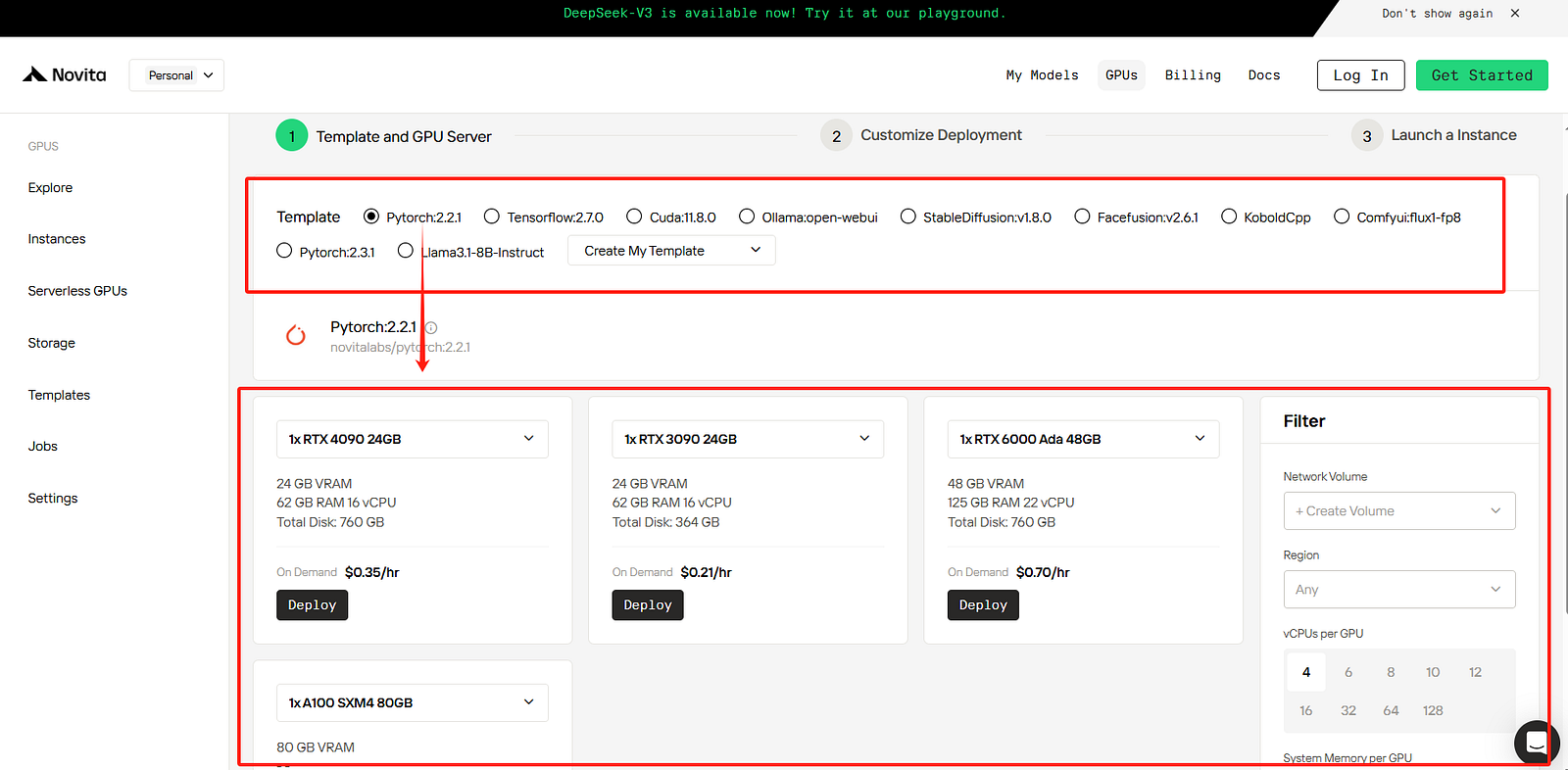
STEP2: Template and GPU Server
You can choose your own template, including Pytorch, Tensorflow, Cuda, Ollama, according to your specific needs. Furthermore, you can also create your own template data by clicking the final bottom.
Then, our service provides access to high-performance GPUs such as the NVIDIA RTX 4090, each with substantial VRAM and RAM, ensuring that even the most demanding AI models can be trained efficiently. You can pick it based on your needs.
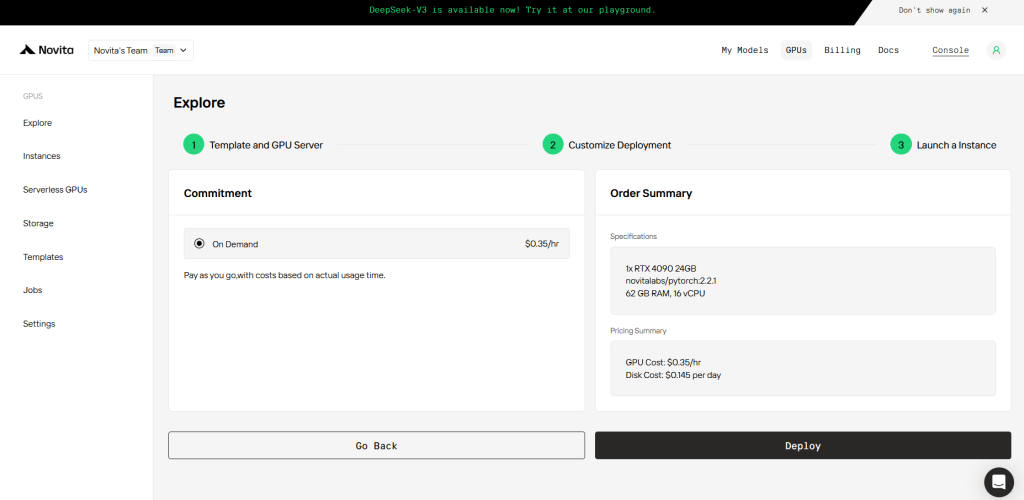
STEP3: Customize Deployment
In this section, you can customize this data according to your own needs. There are 60GB free in the Container Disk and 1GB free in the Volume Disk, and if the free limit is exceeded, additional charges will be incurred.

STEP4: Launch an instance
Whether it’s for research, development, or deployment of AI applications, Novita AI GPU Instance equipped with CUDA 12 delivers a powerful and efficient GPU computing experience in the cloud.
Conclusion
Llama 3.3 70B represents a significant advancement in language modeling, delivering high performance and efficiency for tasks such as multilingual chat, code generation, and synthetic data creation. Deploying this model via cloud GPUs ensures scalability, cost-efficiency, and accessibility, making it suitable for both commercial and research purposes. Platforms like Novita AI simplify the process by providing powerful GPU resources, customizable templates, and cost-effective solutions, enabling developers and researchers to harness the full potential of Llama 3.3 70B with ease.
Frequently Asked Question
Why should I use cloud GPUs for Llama 3.3 70B?
Cloud GPUs provide scalable computational resources, cost-efficiency through pay-as-you-go models, and accessibility to high-performance hardware without the need for upfront investments.
Which GPUs are recommended for running Llama 3.3 70B?
GPUs like NVIDIA A100, H100, RTX 3090, and RTX 4090 are recommended, depending on the scale of your task and budget.
Why should I use cloud GPUs for Llama 3.3 70B?
Cloud GPUs provide scalable computational resources, cost-efficiency through pay-as-you-go models, and accessibility to high-performance hardware without the need for upfront investments.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommend Reading
Subscribe to my newsletter
Read articles from NovitaAI directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by