Defogging the basics of Fog Computing
 Shrish Lahiri
Shrish Lahiri
In today's ever-evolving world, unlocking the true power of cloud technology is not merely an option but an essential strategy. A process called “fog computing” has been working behind the scenes to assist the cloud in exactly this task. As the fog descends on our homes this January, let's learn about fog computing and how it has helped shaped the diverse and complex system of high-speed networks that exist today.
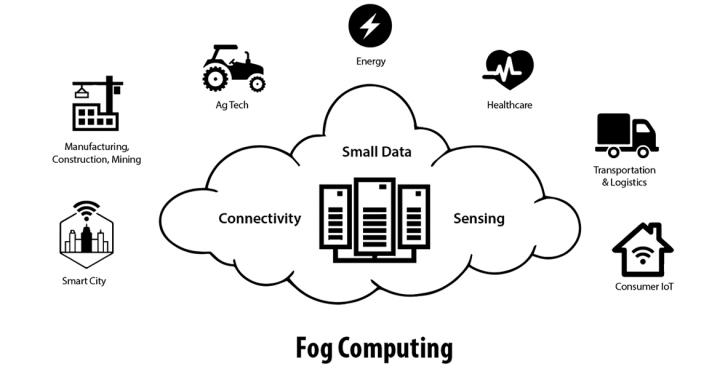
What exactly is fog computing?
Coined by Cisco's product line manager Ginny Nichols in 2014, fog computing (or fogging), as the name implies, refers to a segregated computing infrastructure in which computing resources are located between a data source and the cloud (or) another data centre. In simple words, Fog is an extension of cloud computing that consists of multiple edge nodes directly connected to physical devices.
In nature, Fog is closer to Earth than clouds; In the tech world, it's the same; Fog is closer to end-users, bringing cloud capabilities to the ground.
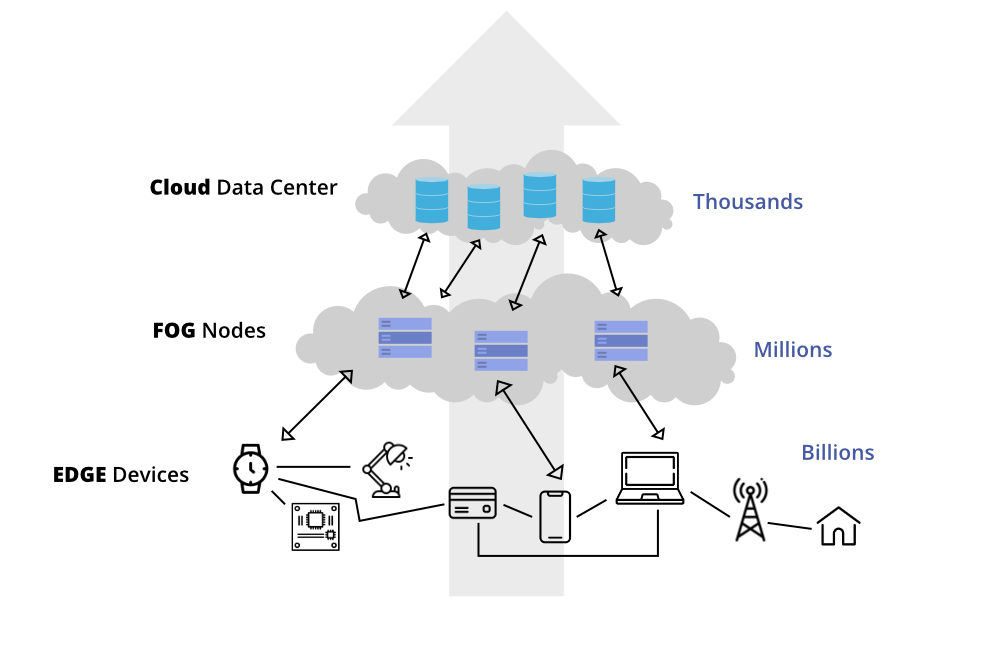
What are the benefits?
Fog computing brings the advantages and power of the cloud closer to where data is created and acted upon. This is often done to improve efficiency, bolster security and increase compatibility.
Fog networking complements cloud computing, enabling short-term analytics at the edge, while the cloud performs resource-intensive, longer-term analytics. Although edge devices and sensors are where data is generated and collected, they sometimes don't have the compute and storage resources to perform advanced analytics and machine learning tasks. Though cloud servers have the power to do this, they are often too far away to process the data and respond in a timely manner.
In addition, having all endpoints connecting to and sending raw data to the cloud over the internet can have privacy, security and legal implications, especially when dealing with sensitive data subject to regulations in different countries.
Fog computing helps by being much closer to devices than centralized data centres so that they can provide instant connections. The considerable processing power of edge nodes allows them to compute large amounts of data without sending them to distant servers.
Where can we see it in action?
One increasingly common use case for fog computing is traffic control. Because sensors -- such as those used to detect traffic -- are often connected to cellular networks, cities sometimes deploy computing resources near the cell tower. These computing capabilities enable real-time analytics of traffic data, thereby enabling traffic signals to respond in real time to changing conditions.
This basic concept is also being extended to autonomous vehicles. Autonomous vehicles essentially function as edge devices because of their vast onboard computing power. These vehicles must be able to ingest data from a huge number of sensors, perform real-time data analytics and then respond accordingly.
Because an autonomous vehicle is designed to function without the need for cloud connectivity, it's tempting to think of autonomous vehicles as not being connected devices. Even though an autonomous vehicle must be able to drive safely in the total absence of cloud connectivity, it's still possible to use connectivity when available. Some cities are considering how an autonomous vehicle might operate with the same computing resources used to control traffic lights.
Such a vehicle might, for example, function as an edge device and use its own computing capabilities to relay real-time data to the system that ingests traffic data from other sources. The underlying computing platform can then use this data to operate traffic signals more effectively.
Few more applications are illustrated below:

Any Pros/Cons?
Fog computing has its fair share of pros and cons as illustrated below:

Fact checks in a snap:
Fog computing vs. Edge computing:
According to the OpenFog Consortium started by Cisco, the key difference between edge and fog computing is where the intelligence and compute power are placed. In a strictly foggy environment, intelligence is at the local area network (LAN), and data is transmitted from endpoints to a fog gateway, where it's then transmitted to sources for processing and return transmission. In edge computing, intelligence and power can be in either the endpoint or a gateway.
Fog Computing vs. Cloud Computing:
The main difference between fog computing and cloud computing is that Cloud is a centralized system, whereas Fog is a distributed decentralized infrastructure. It should be noted however that fog networking is not a separate architecture. It does not replace cloud computing but complements it by getting as close as possible to the source of information.
The Takeaway:
As the demand for faster and efficient communication increases with the rise of smart technologies, Fog computing is likely only the first step to ensuring a smarter tomorrow. Let us appreciate the beauty of nature that continues to inspire bright minds across the globe; for a keen eye will easily notice that almost all innovations, large or small, originate from the infinite mysteries of Mother Earth.
Subscribe to my newsletter
Read articles from Shrish Lahiri directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by