How to Design a Rate Limiter: Token Bucket vs. Leaky Bucket Explained
 Saumil Hukerikar
Saumil HukerikarIntroduction
A rate limiter is a mechanism that is used to control the number of requests an entity (user, API client, service) can make within a specific timeframe. Rate limiters have two primary responsibilities:
Protect servers against excessive traffic
Ensure fair usage among different clients, by limiting traffic from clients driving high traffic thereby consuming majority of server resources.
An example of rate limiting is to allow 100 requests from a user per minute. If the user were to send more than 100 requests, all subsequent requests within the minute would be rejected.
Rate Limiting Algorithms
Rate Limiting Algorithms are responsible for tracking the traffic sent by clients, on the basis of which rate limiting is applied. While there are many rate limiting algorithms, in this article, we will take a look at two of most common algorithms used.
Token Bucket Algorithm
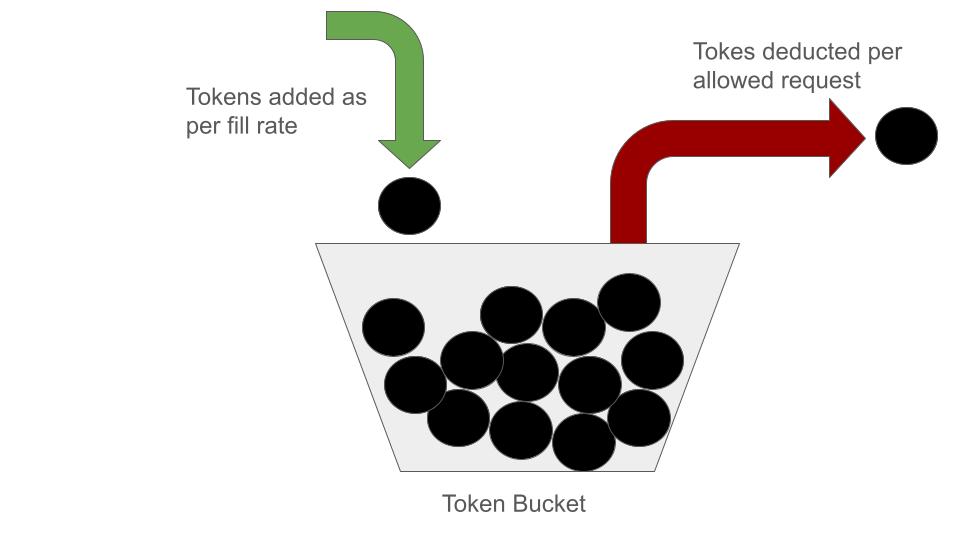
The “Token Bucket” algorithm relies on availability of “token” in a “bucket” assigned to track user requests.
A “bucket”(i.e. any data structure representing collection of objects) is filled with “tokens”(i.e. objects) at a fixed rate (e.g., 1 token per second).
Each request consumes certain number of tokens (e.g., 1 request consumes 1 token)
Requests are allowed as long as sufficient tokens are present in bucket. Number of token are deducted from bucket after requests is allowed to execute. If there are no tokens in the bucket, we block all requests till additional tokens are filled into the bucket.
To prevent unlimited accumulation of tokens in a bucket, we associate a maximum size to the bucket.
In addition to simplicity, the ability to handle burst of traffic is one of the major benefits of this algorithm.
import time
class TokenBucket:
def __init__(self, rate, capacity):
self.fill_rate = rate
self.bucket_capacity = capacity
self.tokens = capacity
self.last_refill_time = time.time()
def allow_request(self):
now = time.time()
self.tokens += (now - self.last_refill_time) * self.fill_rate
self.tokens = min(self.tokens, self.bucket_capacity)
self.last_refill_time = now
if self.tokens >= 1:
self.tokens -= 1
return True
else:
return False
bucket = TokenBucket(rate=1, capacity=5)
for x in range(0, 20):
if bucket.allow_request():
print("Allowed for Request No. %d" % (x))
else:
time.sleep(0.5)
print("Blocked for %d" % (x))
Lets take a look at how the algorithm works. The token bucket is configured to refill at 1 token per second with maximum capacity of 5 tokens in the bucket. On executing the code, the first 5 requests are allowed, after which a request is allowed after blocking every 2 requests. Every time a request is blocked, we sleep the process for half-a-second. Therefore, blocking 2 requests results in process sleeping for 1 second which is sufficient time to fill the bucket with 1 token which is consumed when allowing the subsequent request.
Leaky Bucket Algorithm
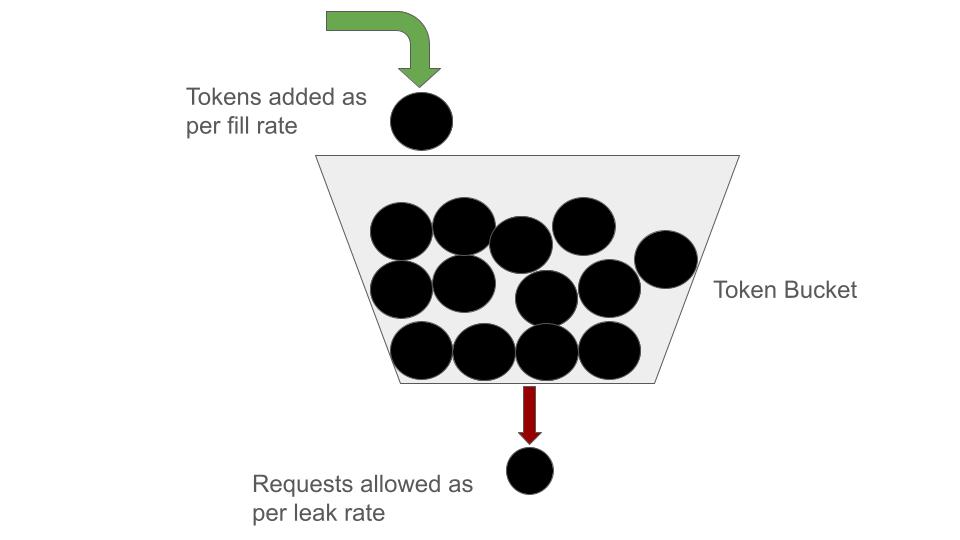
The “leaky bucket” algorithm is a technique intended to smooth out bursty traffic. Bursty tokens are stored in the bucket and sent out at an average rate.
Requests are added to a bucket (i.e. “queue”).
The bucket "leaks" (processes requests) at a fixed rate. If the bucket is full, new requests are discarded.
import time
class LeakyBucket:
def __init__(self, leak_rate, capacity):
self.bucket_capacity = capacity
self.leak_rate = leak_rate
self.bucket_size = 0
self.last_updated = time.time()
def insert_data(self, number_of_tokens):
current_time = time.time()
time_elapsed = current_time - self.last_updated
self.last_updated = current_time
self.bucket_size -= self.leak_rate * time_elapsed
self.bucket_size = min(self.bucket_size + number_of_tokens, self.bucket_capacity)
# Check if data can be sent
if self.bucket_size >= number_of_tokens:
self.bucket_size -= number_of_tokens
return True
else:
return False
bucket = LeakyBucket(leak_rate=1, capacity=5)
for x in range(0, 20):
time.sleep(1)
if bucket.insert_data(3):
print(f"3 tokens inserted successfully.")
else:
print(f"Bucket overflow. Unable to insert 3 tokens.")
Lets take a look at how the algorithm works. An empty queue is initialized with maximum of 5 tokens. We attempt to insert 3 tokens into the queue every 2 seconds. On execution of the algorithm, you will notice after initial inserts into the queue, every 3rd request gets blocked after successful inserts into the queue. On the other end, the queue leaks at the constant rate of 1 token per seconds.
Comparison: Token Bucket vs. Leaky Bucket
| Feature | Token Bucket | Leaky Bucket |
| Goal | Allows bursts, but enforces limit over time | Ensures steady request flow |
| Queueing | No queuing; excess requests are denied | Requests queue up if bucket isn't full |
| Ideal Use cases | APIs, rate-limiting users | Traffic shaping in networks |
| Efficiency | Efficient for burst handling | Good for smoothing out traffic |
Conclusion
Rate limiting stands as a cornerstone in system design, wielding significant influence over stability, performance, and security. By selecting the most appropriate algorithm and employing strategies to mitigate sudden traffic surges, engineers can achieve two critical objectives: ensuring equitable resource allocation and safeguarding your system against potential abuse and excessive load.
Subscribe to my newsletter
Read articles from Saumil Hukerikar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by