A Guide to BlueSky Post Collection via API
 Shreyansh Agarwal
Shreyansh Agarwal
Introduction
Here, we will discuss how to collect posts from the BlueSky Social Media Platform using a search term. In this tutorial, we will understand how these BlueSky APIs work and how to collect many posts using the cursor concept of APIs.
For this blog, I will show you how I collected around 20,000+ unique posts from BlueSky based on the “wildfire” keyword in the search. Here, I have not only collected text in the post but metadata related to the post with metadata related to that post author.
What is BlueSky
BlueSky is a young emerging microblogging social media platform. This platform emerges as an alternative to Twitter(𝕏). It is becoming very popular in the US because of the apparent biases of Twitter(𝕏) because of Elon Musk. This platform also gives its users a unique feature to choose their custom algorithm for their feed.
Interesting Fact : Jack Dorsey is the founder of BlueSky (Yes, the same guy who founded Twitter)
You can read this paper to learn more about BlueSky and its architecture : https://arxiv.org/pdf/2402.03239
Requirements
Python 3.8 or higher (API SDK requirements)
AT Protocol SDK (install it using
pip install atproto)BlueSky Account (since you will need an account email and password to access “cursor” feature of the APIs)
Pandas Library (install it using
pip install pandas)
Understanding the APIs we need in this tutorial
BlueSky offers a large number of APIs to interact with its platform. The list is vast, and here won’t talk about all those APIs, we will restrict ourselves to only 2 APIs. If you want to know more about BlueSky APIs from their official documentation : https://docs.bsky.app/
Also, due to some restrictions with public APIs without login restrictions on BlueSky, we need to use SDK and in my case, I am using Python SDK. Documentation for Python SDK : https://atproto.blue/en/latest/
Now, let’s about those 2 APIs.
1. app.bsky.feed.searchPosts
This API is used to search posts on BlueSky based on a search query string. This API has q(search query string) as the required parameter. There are many optional parameters like limit, cursor, sort, since, until, etc. You can read about them in the Documentation mentioned below.
Look at this HTTP request example for Search Posts :
https://public.api.bsky.app/xrpc/app.bsky.feed.searchPosts?q=wildfire&limit=25
Response Looks Like :
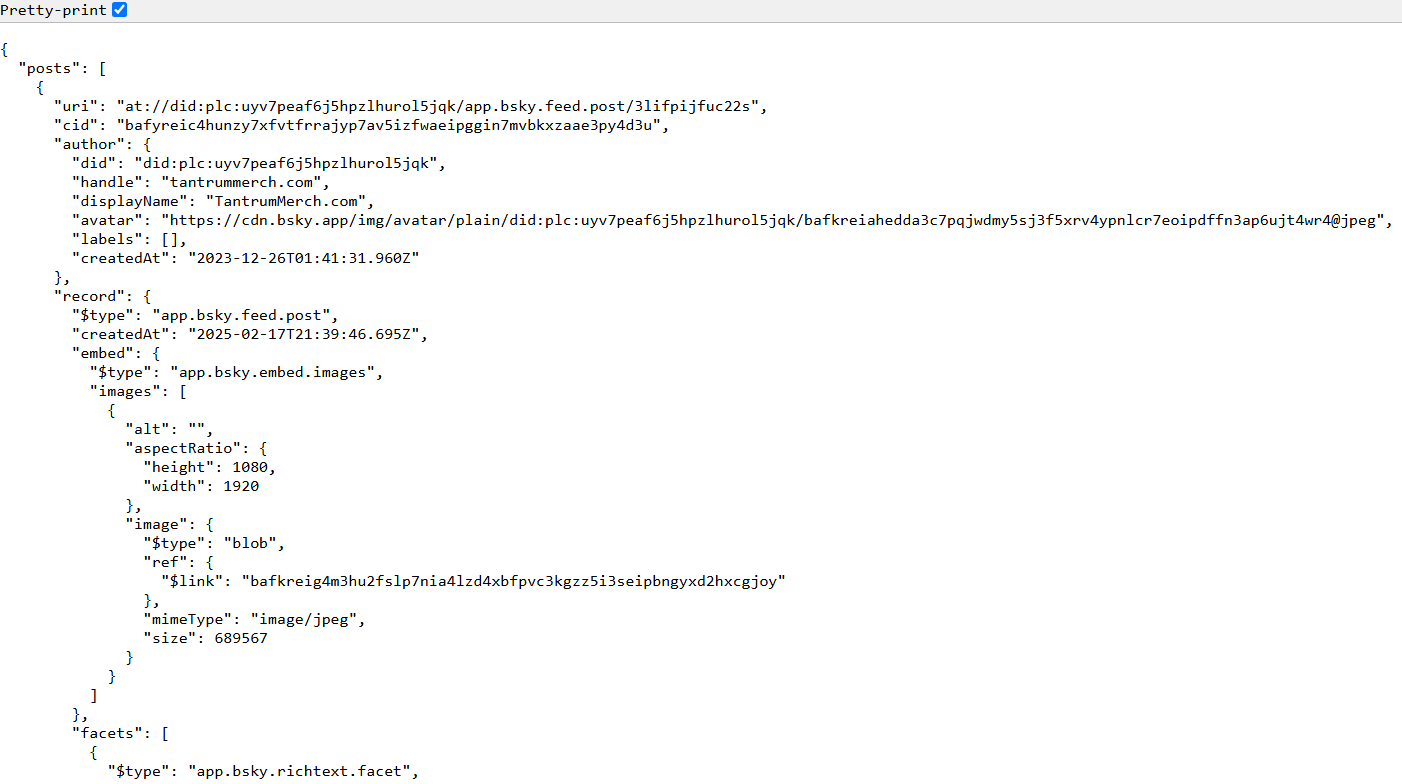
Here, we are simply making an HTTP request to fetch 25 posts based on “wildfire” as the search query. Also, there could be a case you mentioned limit = 25 but you got less number of posts in the response (but never more than the limit).
Also, their a problem with the cursor parameter in this API. If you include cursor parameter in this API, like
https://public.api.bsky.app/xrpc/app.bsky.feed.searchPosts?q=wildfire&limit=25&cursor=50
You will get 403 Error
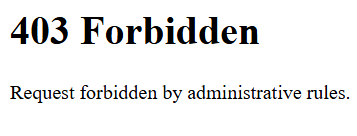
This is because BlueSky developers have restricted users from using this API without authentication. You can learn more about this here : https://github.com/bluesky-social/atproto/issues/2838
To easiest way to solve this issue is to use an SDK where you will authenticate first and then use the API. We will look into this in the code part of this blog.
Documentation :
https://docs.bsky.app/docs/api/app-bsky-feed-search-posts (HTTP reference)
https://atproto.blue/en/latest/atproto/atproto_client.models.app.bsky.feed.search_posts.html (Python SDK reference)
2. app.bsky.actor.getProfiles
This API is used to receive information of Profiles based on a list of handles provided as input. This API only has one input parameter (which is a required parameter) which is actors (a list of profile handles).
Also, sometimes the response has fewer number or profile details than the number of handles sent in the input parameter. Eg. you sent 25 handles in the actors input parameter, but you may only receive only 23 profile details. You should handle this case in your code.
We will see how to make this request in the SDK code part.
Documentation :
https://docs.bsky.app/docs/api/app-bsky-actor-get-profiles (HTTP reference)
https://atproto.blue/en/latest/atproto/atproto_client.models.app.bsky.actor.get_profiles.html (Python SDK reference)
Rate Limits
https://docs.bsky.app/docs/advanced-guides/rate-limits
Understand how to scrape tweets
CSV File Header
Here, you can see how CSV Files Columns look like.
User_DID,User_Handle,Username,Account_Created_At,Followers,Follows,Post_Count,User_Description,Created_At,CID,Text,Image1,Image1_Alt,Image2,Image2_Alt,Image3,Image3_Alt,Image4,Image4_Alt,Likes,Quotes,Reply_Count,Reposts
Import libraries
from atproto import Client # For Python SDK (if not installed, do : pip install atproto)
import time # For time.sleep(t_seconds)
import pandas as pd # For efficiently storing the data
Authenticating your BlueSky Profile
client = Client() # Making the Client Object
username = #Fill Username (account email in string)
password = # Fill Password (account in string)
profile = client.login(username, password)
print('Welcome,', profile.display_name) # If successfully auth, print welcome message
Crafting Input Parameters header (for Search Posts API)
# This is a sample input parameter header, you can change it based on your requirements
params = {
"q": "wildfire",
"limit": 25,
"sort" : 'latest',
"since": "2025-01-21T00:00:00Z",
"until": "2025-01-22T00:00:00Z"
}
# API LIKE : https://api.bsky.app/xrpc/app.bsky.feed.searchPosts?q=wildfire&since=2025-01-07T00:00:00Z&until=2025-01-07T23:59:00Z
Data Template
It is a template dictionary where we store data for an iteration, it is also of the same format as the Pandas DataFrame and how the data is stored in the CSV File.
data_template = {
"User_DID" : [],
"User_Handle" : [],
"Username" : [],
"Account_Created_At" : [],
"Followers" : [],
"Follows" : [],
"Post_Count" : [],
"User_Description" : [],
"Created_At" : [],
"CID" : [],
"Text" : [],
"Image1" : [],
"Image1_Alt" : [],
"Image2" : [],
"Image2_Alt" : [],
"Image3" : [],
"Image3_Alt" : [],
"Image4" : [],
"Image4_Alt" : [],
"Likes" : [],
"Quotes" : [],
"Reply_Count" : [],
"Reposts" : [],
}
Initializing some variables
cursor = None # Initially it's None but after the 1st iteration it gets a value
last = "0" # To handle the situation if cursor becomes None in between
entires_fetched = 0 # Keeps the track of number of posts fetched
data = data_template.copy() # In this data dictionary we fill the data in every iteration
Collecting Data through a Loop
for loop in range(200): # Assumme that I want to collect 200*25 = 5000 posts (at maximum)
if cursor:
params["cursor"] = cursor # Adding CURSOR in the Search Post API input header
else:
cursor = last # Basic Exceptional handling (code will work perfectly fine it this was not there)
params["cursor"] = cursor
last = str(int(last) + 25)
print(f"Loop {loop} started")
try: # Proceed only if API fetches data successfully else break the llop
response = client.app.bsky.feed.search_posts(params) # Collecting Posts (limit = 25 means 25 posts at max)
print(f"Post Fetched : {len(response.posts)}")
except:
print("Posts Not Fetched")
break
cursor = response.cursor
# Making a list of profile handles for which we want the info
pa = {
"actors" : [post.author.handle for post in response.posts]
}
try:
pfp_raw = client.app.bsky.actor.get_profiles(pa) # Collecting Profiles Info (<= 25 profiles in my case)
except:
print("Profiles Not Fetched")
break
pfp_raw = pfp_raw.profiles
if len(pfp_raw) != len(response.posts):
print(f"Less Number of Profiles Fetched : {len(pfp_raw)}")
pfp = {}
for curr_pfp in pfp_raw: # To handle if we have the case where less number of profiles are fetched as compared to the posts
pfp[curr_pfp.handle] = curr_pfp
entires_fetched += min(len(pfp_raw), len(response.posts))
pfp_raw = None
# Looping over each profile in the API response
for (i,post) in enumerate(response.posts):
if post.author.handle not in pfp:
print(post.author.handle, "Not Found in pfp dictionary")
continue
# Saving each profile data in the the data dictionary
data["User_DID"].append(post.author.did)
data["User_Handle"].append(post.author.handle)
data["Username"].append(post.author.display_name)
data["Account_Created_At"].append(post.author.created_at)
data["Followers"].append(pfp[post.author.handle].followers_count)
data["Follows"].append(pfp[post.author.handle].follows_count)
data["Post_Count"].append(pfp[post.author.handle].posts_count)
data["User_Description"].append(pfp[post.author.handle].description)
data["Created_At"].append(post.record.created_at)
data["Text"].append(post.record.text)
data["Likes"].append(post.like_count)
data["Quotes"].append(post.quote_count)
data["Reply_Count"].append(post.reply_count)
data["Reposts"].append(post.repost_count)
data["CID"].append(post.cid)
# The code below is used to collect images URL in the posts
try: # Try for Images (All 4 Images)
l = len(post.embed.images)
for j in range(1,5):
if (j - 1) >= l:
data[f"Image{j}"].append("")
data[f"Image{j}_Alt"].append("")
else:
data[f"Image{j}"].append(post.embed.images[j - 1].thumb)
data[f"Image{j}_Alt"].append(post.embed.images[j - 1].alt)
except:
try: # Try for Video and if present save videos thumbnail
data["Image2"].append("")
data["Image2_Alt"].append("")
data["Image3"].append("")
data["Image3_Alt"].append("")
data["Image4"].append("")
data["Image4_Alt"].append("")
data["Image1"].append(post.embed.thumbnail)
data["Image1_Alt"].append("")
except: # Try for News Article present as Media in the Post
try:
xx = post.embed.external
data["Image1_Alt"].append(xx.title)
data["Image1"].append(xx.thumb)
except: # Means no media present in this post
data["Image1"].append("")
data["Image1_Alt"].append("")
# This helps Garbage collector to delete unwanted data (these variables had API response in raw format)
response = None
pfp = None
print(f"Loop {loop} ends with {params["cursor"] if loop > 0 else 0}, {cursor}, {last}")
print("\n\n")
time.sleep(3) # To give time to Python to handle background tasks
Saving data in a CSV File
df = pd.DataFrame(data) # Converting dictionar into DataFrame
# Also, this code assumes that header is already present in the CSV file
df.to_csv('data_21_01_1.csv', index=False, mode='a', header=False) # Save the dataframes in the CSV File
print(f"Written {entires_fetched} rows in CSV File") # Prints how many rows are written in the CSV File
Note :
Both APIs (Search Posts and Get Profiles) sometimes get less number of items in the response (eg. you asked for
limit = 30but you may get 28 posts in the response). So, remember to handle these types of cases.This code is not the most efficient way to collect data from APIs. Due to this while collecting a large amount of data your code memory usage could get very high (in >100 MB size).
The code assumes the CSV File already has the column (headers) present.
You can also collect more information present in the response. You need to understand the responses to know what could be useful for you.
This code won’t work if you don’t have a BlueSky Account.
[IMPORTANT] In the Image URL collection portion, I am using try-catch to find the type of media present in a post. I am not collecting the video URL but its thumbnail and for the News Article I am collecting its title as ALT text.
Complete Code
from atproto import Client
import time
import pandas as pd
client = Client()
username = #Fill Username (account email in string)
password = # Fill Password (account in string)
profile = client.login(username, password)
print('Welcome,', profile.display_name)
params = {
"q": "wildfire",
"limit": 25,
"sort" : 'latest',
"since": "2025-01-21T00:00:00Z",
"until": "2025-01-22T00:00:00Z"
}
# CSV File Header :
# User_DID,User_Handle,Username,Account_Created_At,Followers,Follows,Post_Count,User_Description,Created_At,CID,Text,Image1,Image1_Alt,Image2,Image2_Alt,Image3,Image3_Alt,Image4,Image4_Alt,Likes,Quotes,Reply_Count,Reposts
# API LIKE : https://api.bsky.app/xrpc/app.bsky.feed.searchPosts?q=wildfire&since=2025-01-07T00:00:00Z&until=2025-01-07T23:59:00Z
data_template = {
"User_DID" : [],
"User_Handle" : [],
"Username" : [],
"Account_Created_At" : [],
"Followers" : [],
"Follows" : [],
"Post_Count" : [],
"User_Description" : [],
"Created_At" : [],
"CID" : [],
"Text" : [],
"Image1" : [],
"Image1_Alt" : [],
"Image2" : [],
"Image2_Alt" : [],
"Image3" : [],
"Image3_Alt" : [],
"Image4" : [],
"Image4_Alt" : [],
"Likes" : [],
"Quotes" : [],
"Reply_Count" : [],
"Reposts" : [],
}
cursor = None
last = "0"
entires_fetched = 0
data = data_template.copy()
for loop in range(200):
if cursor:
params["cursor"] = cursor
else:
cursor = last
params["cursor"] = cursor
last = str(int(last) + 25)
print(f"Loop {loop} started")
try:
response = client.app.bsky.feed.search_posts(params)
print(f"Post Fetched : {len(response.posts)}")
except:
print("Posts Not Fetched")
break
cursor = response.cursor
pa = {
"actors" : [post.author.handle for post in response.posts]
}
try:
pfp_raw = client.app.bsky.actor.get_profiles(pa)
except:
print("Profiles Not Fetched")
break
pfp_raw = pfp_raw.profiles
if len(pfp_raw) != len(response.posts):
print(f"Less Number of Profiles Fetched : {len(pfp_raw)}")
pfp = {}
for curr_pfp in pfp_raw:
pfp[curr_pfp.handle] = curr_pfp
entires_fetched += min(len(pfp_raw), len(response.posts))
pfp_raw = None
for (i,post) in enumerate(response.posts):
if post.author.handle not in pfp:
print(post.author.handle, "Not Found in pfp dictionary")
continue
data["User_DID"].append(post.author.did)
data["User_Handle"].append(post.author.handle)
data["Username"].append(post.author.display_name)
data["Account_Created_At"].append(post.author.created_at)
data["Followers"].append(pfp[post.author.handle].followers_count)
data["Follows"].append(pfp[post.author.handle].follows_count)
data["Post_Count"].append(pfp[post.author.handle].posts_count)
data["User_Description"].append(pfp[post.author.handle].description)
data["Created_At"].append(post.record.created_at)
data["Text"].append(post.record.text)
data["Likes"].append(post.like_count)
data["Quotes"].append(post.quote_count)
data["Reply_Count"].append(post.reply_count)
data["Reposts"].append(post.repost_count)
data["CID"].append(post.cid)
try:
l = len(post.embed.images)
for j in range(1,5):
if (j - 1) >= l:
data[f"Image{j}"].append("")
data[f"Image{j}_Alt"].append("")
else:
data[f"Image{j}"].append(post.embed.images[j - 1].thumb)
data[f"Image{j}_Alt"].append(post.embed.images[j - 1].alt)
except:
try:
data["Image2"].append("")
data["Image2_Alt"].append("")
data["Image3"].append("")
data["Image3_Alt"].append("")
data["Image4"].append("")
data["Image4_Alt"].append("")
data["Image1"].append(post.embed.thumbnail)
data["Image1_Alt"].append("")
except:
try:
xx = post.embed.external
data["Image1_Alt"].append(xx.title)
data["Image1"].append(xx.thumb)
except:
data["Image1"].append("")
data["Image1_Alt"].append("")
response = None
pfp = None
print(f"Loop {loop} ends with {params["cursor"] if loop > 0 else 0}, {cursor}, {last}")
print("\n\n")
time.sleep(3)
df = pd.DataFrame(data)
df.to_csv('data_21_01_1.csv', index=False, mode='a', header=False)
print(f"Written {entires_fetched} rows in CSV File")
Problems
There are some problems I noticed in the code, which you may change this code to handle them if needed :
I have collected the thumbnail of the video, not the whole video. Similarly, I have collected news articles as images and article titles as ALT text of Image 1.
This code is not the most efficient way to collect data from APIs. Due to this while collecting a large amount of data your code memory usage could get very high (in >100 MB size). You may need to make changes in the code to collect data on a very large scale.
This is a very simple code for collecting, you may need more types of APIs to collect data based on your use case, this is a simple example that I have shown you.
Motivation
Some Context: Following Elon Musk's acquisition of Twitter, the platform implemented stricter regulations. One such regulation pertains to API access; previously, APIs were free, but now a free account allows access to only 100 tweets per month, a significant reduction. This change aims to limit data collection by AI companies, permitting only xAI to utilize Twitter data for training their language model.
I aim to gather social media data concerning natural disasters to train neural networks, which could enhance our ability to manage such events more effectively. Additionally, this is a requirement for my BTech Project to fulfill my degree requirements. My project faculty mentor at college assigned this task to me and a friend.
Twitter APIs restricted us from collecting data from its platform. I was looking for alternatives of similar platforms to collect data, then I got to know about BlueSky. Then I also got to know that BlueSky is very new and very little data is present on its platform. But confidently there was a wildfire struck in Los Angeles (US) and since BlueSky is very popular in the US, there were a lot of tweets related to Los Angeles Wildfire. Because of this, I became interested in collecting data from BlueSky.
I also had the option of other social media platforms, but some were restrictive and some were very new. But, there also exists Reddit which also has a very high amount of data but the data related to Natural disasters is very little.
Conclusion
In this, we learned about how to use Search Post and Get Profiles APIs in BlueSky. How can these APIs be used to collect data related to a search query? We have also seen how Python SDK for BlueSky can be used. And at last, we see some limitations related to my code.
Now, you can also learn how to make bots, make custom posts using APIs, or do something by learning how other APIs work.
Thank you for reading till the end! 🙌 I hope you found this blog enjoyable and interesting. You can also read my other blogs on my profile.
You can contact me on Twitter(𝕏).
Subscribe to my newsletter
Read articles from Shreyansh Agarwal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shreyansh Agarwal
Shreyansh Agarwal
👩💻 Computer Science Enthusiast | 🚀 Programmer | 🐍 Python | Always 🌱 learning and 📝 blogging about tech