DeepSeek Native Sparse Attention 對產業的長遠影響
 KS Mooi
KS Mooi
摘要
DeepSeek Native Sparse Attention (NSA) 是一種創新的稀疏注意力機制,旨在解決大型語言模型 (LLM) 在處理長文本時面臨的高計算成本問題。本報告深入探討 NSA 的技術原理、與現有注意力機制的差異、應用案例以及對產業的長遠影響,同時展望其未來發展趨勢。
研究方法
為了深入研究 DeepSeek Native Sparse Attention 對產業的長遠影響,本報告參考了多篇學術論文、技術文件及部落格文章,並依據下列步驟進行:
文獻搜尋
搜尋與 DeepSeek Native Sparse Attention 相關的論文、技術文件和部落格文章,以深入理解其技術原理、優缺點和應用場景。機制比較
調查目前產業中常用的注意力機制(例如 Transformer 中的 Self-Attention),並比較 Native Sparse Attention 與這些機制的差異與優勢。應用案例分析
探索 Native Sparse Attention 在不同產業中的應用案例,如自然語言處理、電腦視覺、推薦系統等,分析其實際效果與潛在影響。產業影響評估
評估 Native Sparse Attention 是否能提升模型效率與準確度,降低計算成本與能源消耗;探討其是否能促進新的應用場景和商業模式出現,並對現有產業格局及競爭態勢造成影響。未來發展趨勢
關注 Native Sparse Attention 未來可能出現的新技術突破、應用擴展及競爭對手和替代方案的情況。
DeepSeek Native Sparse Attention 技術原理
DeepSeek NSA 為一種原生可訓練的稀疏注意力機制,結合演算法創新與硬體優化,實現高效長文本建模。其特點包括:
動態分層稀疏策略
結合粗粒度 token 壓縮與細粒度 token 選擇,平衡全局上下文感知與局部信息精確性。算術強度平衡的設計
針對現代硬體(如 GPU)進行優化,顯著提升計算速度。端到端可訓練
支援端到端訓練,可減少預訓練計算量,同時保持模型性能。分層稀疏、逐層優化
採用分層 Token 建模,透過多個注意力分支處理輸入序列,達到更精細的控制與優化。
NSA 的工作原理
壓縮關鍵值對
將關鍵值對壓縮,使其更緊湊且易於處理。三種注意力路徑
包括壓縮的粗粒度 token、細粒度 token 及滑動窗口三種路徑。硬體對齊的稀疏注意力核心
包含專為硬體優化而設計的稀疏注意力核心。查詢頭取樣與索引共享
對查詢頭及其共享的稀疏鍵/值塊索引進行取樣。連續載入以最小化記憶體載入
採用連續載入鍵/值塊的方式,以降低記憶體存取成本。
此外,NSA 支援端到端訓練,不僅提升推理效率,同時減少預訓練計算量而不犧牲模型性能。
Native Sparse Attention 與 Self-Attention 的比較
Transformer 中的 Self-Attention 機制
Self-Attention 為 Transformer 模型核心組成部分,能夠在處理序列數據時,同時考慮各位置之間的關聯,捕捉全局依賴關係。其工作流程包括:
每個輸入元素經過不同線性轉換後產生 Query(查詢)、Key(鍵)、Value(值)。
計算 Query 與所有 Key 的點積,得出每個元素的關聯得分。
將得分除以縮放因子,再應用 softmax 函數轉換為概率分佈。
將概率分佈與 Value 向量相乘,獲得加權平均結果作為輸出。
目前產業中常用的注意力機制
除了 Transformer 的 Self-Attention 外,其他常見的變體和改進包括:
多頭注意力 (Multi-Head Attention)
將 Self-Attention 擴展到多個頭,以從不同表示子空間學習信息。相對位置編碼 (Relative Position Encodings)
融入 token 之間的相對位置信息,提高模型對位置信息的敏感度。稀疏注意力 (Sparse Attention)
僅計算部分 token 之間的注意力權重,以降低計算成本。
Native Sparse Attention 的差異與優勢
相較於 Self-Attention,Native Sparse Attention 主要具有以下優勢:
稀疏性
只計算部分 token 間的注意力權重,相對於 Self-Attention 的全計算模式,能大幅降低計算量。計算效率
稀疏性大幅提升處理長序列文本時的計算效率。硬體優化
針對現代硬體進行專門優化,進一步提升運算速度。端到端可訓練
減少預訓練計算量,確保高效訓練。
現有稀疏注意力方法的局限性
階段限制的稀疏性
部分方法僅於自回歸解碼時應用稀疏性,預填充階段仍需大量計算。與先進 Attention 架構的不兼容性
某些方法難以適配現代高效解碼架構,導致記憶體存取瓶頸。可訓練稀疏性的限制
過度關注推理階段稀疏性可能導致訓練性能下降和反向傳播效率低下。
總體而言,NSA 在維持模型性能的同時,顯著提高計算效率,降低計算成本及能源消耗。
Native Sparse Attention 的性能比較
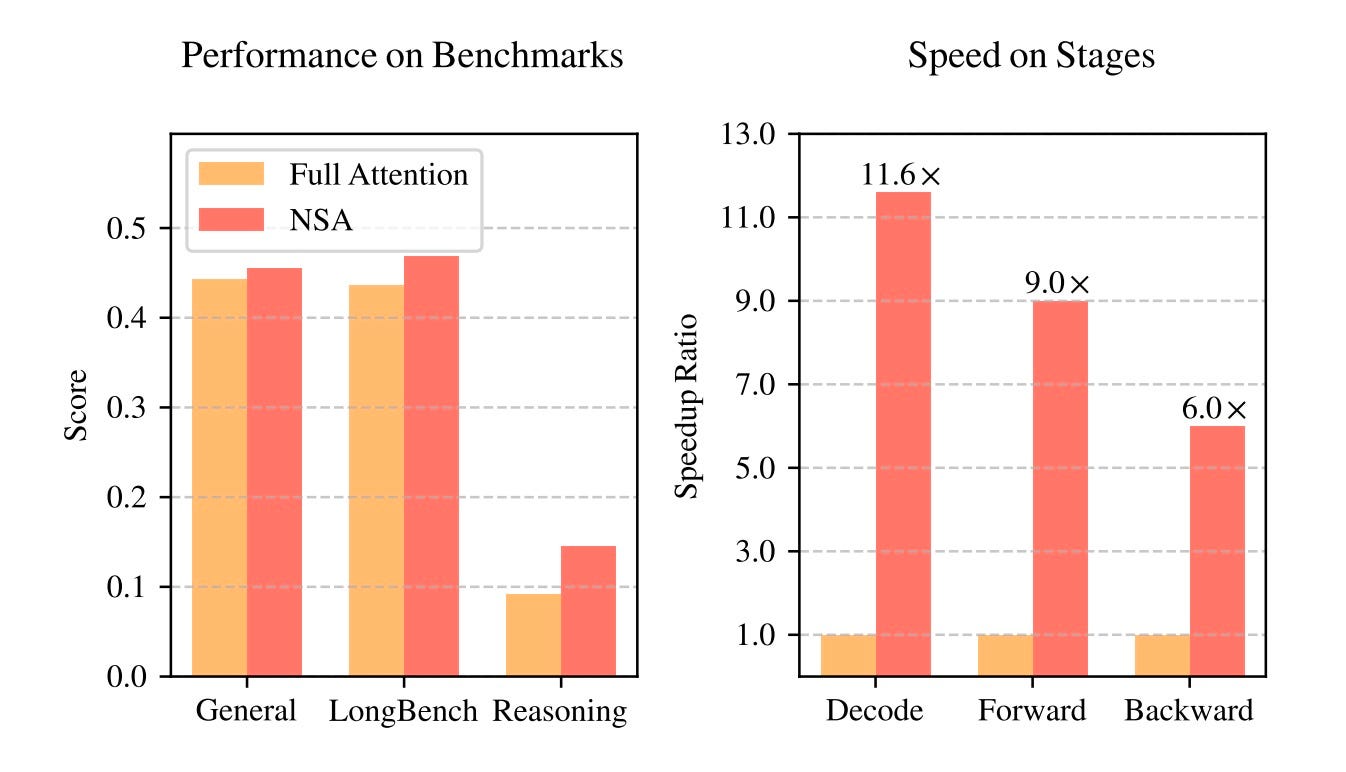
Native Sparse Attention (NSA) 在性能上的優勢可從以下兩個方面來說明:
1. 基準測試表現(左圖)
NSA 在「General(一般場景)」、「LongBench(長文本處理)」和「Reasoning(推理)」等測試中,都與 Full Attention 模型表現相當,甚至在某些情境下更優。例如:
在 General 和 LongBench 測試中,NSA 與 Full Attention 幾乎持平。
在 Reasoning(推理) 方面,NSA 的表現明顯優於 Full Attention,顯示其在推理能力上有顯著提升。
2. 計算速度優勢(右圖)
NSA 在不同計算階段(Decode、Forward、Backward)均顯示了明顯的加速效果:
解碼(Decode) 階段,NSA 相較於 Full Attention 提供 11.6 倍 的加速。
前向傳播(Forward) 階段,NSA 提供 9.0 倍 的加速。
反向傳播(Backward) 階段,NSA 提供 6.0 倍 的加速。
這顯示 NSA 在計算效率上的大幅提升,尤其是在處理長文本和複雜計算時,能夠顯著降低計算成本,同時保持競爭力的準確度。NSA 在推理能力上的提升,搭配計算效能的大幅加速,使其成為 Full Attention 的高效替代方案,特別適合長文本處理及大規模計算場景。
Native Sparse Attention 的應用案例
自然語言處理 (NLP)
NSA 在 NLP 領域具有廣泛應用前景,包括:
長文本建模
有效處理整本書、程式碼庫或多輪對話等長序列文本。文檔分析
分析法律文件、研究論文及新聞報導等長文檔。程式碼生成
用於程式碼補全及程式碼摘要。複雜推理
適用於問答和文本摘要等複雜推理任務。
NSA 不僅在性能上超越傳統全注意力模型,更在效率上取得顯著提升。
電腦視覺
雖然目前尚未有 NSA 在電腦視覺領域的具體應用案例,但其潛在應用包括:
圖像識別: 識別自動駕駛中的交通標誌、行人等目標。
目標檢測: 用於安防監控中檢測可疑人物和物品。
圖像分割: 在醫學影像分析中分割器官和病灶。
推薦系統
NSA 在推薦系統中的應用潛力:
個性化推薦: 根據用戶歷史行為與偏好推薦相關商品或服務。
商品排序: 根據商品特徵及用戶興趣進行排序,提升推薦準確性。
DeepSeek Native Sparse Attention 對產業的長遠影響
提升模型效率和準確度
NSA 可顯著提升 LLM 的運算效率與準確度,降低計算成本與能源消耗。採用 NSA 預訓練的 27B 參數模型在預訓練損失上表現穩定且低於全注意力機制,進一步促進 LLM 在以下領域的應用:
客服: 快速且準確回應客戶問題,提高客戶滿意度,並提供個性化解決方案。
教育: 提供個性化學習體驗,根據學生進度推薦適合資源和練習題。
醫療保健: 協助醫生診斷,通過分析病歷與影像資料提供準確治療方案。
促進新的應用場景和商業模式
NSA 的出現將推動新的應用場景與商業模式,例如:
基於 LLM 的 SaaS 服務
提供自動生成文案、翻譯文件及摘要會議記錄等服務。AI 驅動的內容創作
利用 LLM 生成新聞報導、小說及劇本,輔助創作者進行內容創作。個性化 AI 助手
根據用戶需求,提供行程規劃、餐廳推薦與資訊查詢等個性化服務。
降低 AI 技術的門檻
NSA 能夠降低預訓練所需計算資源,進而降低企業開發大模型的資金與技術門檻,推動更多企業採用 AI 技術。
對產業格局與競爭態勢的影響
NSA 的引入可能改變現有產業格局,具體表現為:
降低技術門檻: 更多企業可進入 LLM 開發與應用領域。
加劇 AI 領域競爭: 驅動企業持續創新與技術提升。
新競爭者崛起: 為新興 AI 公司提供挑戰現有巨頭的契機。
合作與整合: 促使 AI 公司之間進行技術合作,共同推動 NSA 應用的發展。
儘管 NSA 有潛力降低訓練與推理成本,但市場上對 AI 晶片(如 Nvidia、TSMC)的需求依然強勁,NSA 的普及反而可能促進 AI 晶片的應用。此外,DeepSeek 採取與 xAI 不同的發展策略,專注於壓縮計算與推理成本,展現更具永續性與可及性的 AI 發展路徑。但需注意,NSA 的效率提升在很大程度上依賴硬體優化,可能對特定 GPU 設備產生依賴。
Native Sparse Attention 的未來發展趨勢
新的技術突破和改進
更稀疏的注意力機制
研究人員將持續探索更稀疏的注意力策略,以進一步降低計算成本,並嘗試新的稀疏模式與壓縮方法。與其他技術的結合
NSA 可與強化學習、知識圖譜等技術結合,進一步提升模型性能與推理能力。
更廣泛的產業應用
隨著 NSA 技術的成熟,其應用領域將更為廣泛,包括:
金融
用於風險管理、欺詐檢測及投資分析,如預測股票走勢、評估貸款風險與識別金融詐騙。製造
促進生產流程優化、品質控制及預測性維護,如優化生產排程、檢測產品缺陷和預測設備故障。零售
改善客戶關係管理、個性化推薦及庫存管理,如分析消費行為、提供促銷活動及預測商品需求。
DeepSeek 的其他貢獻與競爭局勢
DeepSeek 的其他貢獻
除 NSA 外,DeepSeek 亦在其他 AI 領域取得進展,如開發 Earth-2 地球氣候數位孿生模型,並與中央氣象署合作,該模型可模擬地球氣候系統並預測氣候變化與自然災害。
新的競爭對手和替代方案
隨著 NSA 技術發展,可能會出現新的競爭者及替代方案:
其他稀疏注意力機制
可能會有基於圖神經網路的更高效稀疏注意力機制出現。非注意力機制
如圖神經網路 (GNN) 也能處理長序列數據,可用於長文本理解與生成。
結論
DeepSeek Native Sparse Attention 是一種具有巨大潛力的稀疏注意力機制,不僅能顯著提升 LLM 的效率與準確度,降低計算成本與能源消耗,還將推動 LLM 在多個領域的廣泛應用,創造新的應用場景與商業模式。隨著技術進一步成熟,NSA 將在不同產業中扮演更重要的角色,並改變現有產業格局與競爭態勢。
展望未來,NSA 的發展同時也引發了一些值得關注的議題:
道德考量:如何確保 LLM 負責任地使用,避免濫用於生成虛假信息或侵犯隱私?
社會影響:LLM 的普及將如何影響工作與生活?是取代人類工作,還是成為人類的有力助手?
AI 的未來:NSA 能否引領 AI 技術邁向更智能、更可持續的未來?
這些問題值得我們持續關注與探討,以確保 NSA 技術的發展真正造福人類社會。
Subscribe to my newsletter
Read articles from KS Mooi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
KS Mooi
KS Mooi
AI Enthusiast Exploring the forefront of AI with a focus on deep learning, reinforcement learning, and agentic AI. Passionate about creating intelligent, adaptive models and applying retrieval-augmented generation (RAG) techniques to push the boundaries of what's possible in real-world applications.