Getting Started with IBM Storage Ceph Multisite Replication.
 Daniel Parkes
Daniel ParkesIntroduction
When considering Replication, Disaster Recovery, Backup, and Restore, we choose from multiple strategies with varying SLAs for data and application recovery: Recovery Time Objective (RTO) and Recovery Point Objective (RPO). Synchronous replication provides the lowest RPO, which means zero data loss. IBM Storage Ceph can implement synchronous replication among sites by stretching the Ceph cluster across multiple data centers.
Asynchronous replication inherently implies a non-zero RPO. With Ceph, async multisite replication involves replicating data to another Ceph cluster. Each IBM Storage Ceph storage access method (object, block, and file) has its own asynchronous replication method implemented at the service level.
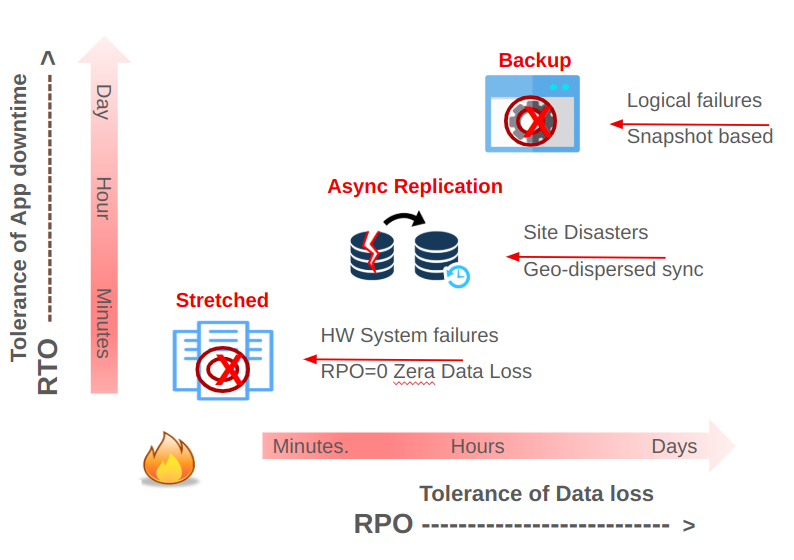
Asynchronous Replication: Replication occurs at the service level (RBD, CephFS, or RGW), typically across fully independent Ceph clusters.
Synchronous Replication (“Stretch Cluster”): Replication is performed at the RADOS (cluster) layer, so writes must be completed in every site before an acknowledgment is sent to clients.
Both methods have distinct advantages and disadvantages, as well as different performance profiles and recovery considerations. Before discussing IBM Storage Ceph stretch clusters in detail, here is an overview of these replication modes.
Replication Options in IBM Storage Ceph
Asynchronous Replication
Asynchronous replication is driven at the service layer. Each site provisions a complete, standalone IBM Storage Ceph cluster and maintains independent copies of the data.
Object / RGW Multisite: Each site deploys one or more independent RGW zones. Changes are propagated asynchronously between sites using the RGW multisite replication framework. This replication is not journal-based. Instead, it relies on log-based replication, where each RGW tracks changes through a log of operations (sync logs), and these logs are replayed at peer sites to replicate data.
RBD Mirroring: Block data is mirrored either using a journal-based approach (as with Openstack) or a snapshot-based approach (as with ODF/OCP), depending on your requirements for performance, crash consistency, and scheduling.
CephFS Snapshot Mirroring (in active development): Uses snapshots to replicate file data at configurable intervals.
Asynchronous replication is well-suited for architectures with significant network latency between locations. This approach allows applications to continue operating without waiting for remote writes to complete. However, it's important to note that this method carries a non-zero Recovery Point Objective (RPO), meaning there will be some delay before remote sites are consistent with the primary. As a result, a site failure could lead to (minimal) loss of recently written data that is still in flight.
To explore Ceph's asynchronous replication, please check out the blog posts we released in a dedicated series to Object storage Multisite Replication.
Synchronous Replication (Stretch Cluster)
A stretch cluster is a single IBM Storage Ceph cluster deployed across multiple data centers (or availability zones). Write operations return to clients only once persisted at all sites (or enough sites to meet each logical pool's size replication schema requirement). This provides:
RPO = 0: No data loss if one site fails since every write is synchronously replicated and will be replayed when a failed site comes back online.
Single cluster management: No special client-side replication configuration is needed; regular Ceph tools and workflows are applied.
A stretch cluster imposes more strict networking requirements: a maximum 10ms RTT. Because writes to OSDs must travel between sites before an acknowledgment is returned, latency becomes critical. Network instability, insufficient bandwidth, and latency spikes can degrade performance and risk data integrity.
IBM Storage Ceph Stretch cluster
Introduction.
IBM Storage Ceph Stretch Clusters provide benefits that make them a good option for critical applications that require maximum uptime and resilience:
Fault Tolerance, a stretch cluster will bear the failure of an entire site transparently without impacting client operations. It can sustain a double site failure without data loss.
Strong Consistency, In a three-site setup, data uploaded online immediately becomes visible and accessible to all AZs/sites. Strong consistency enables clients to be in different locations to always see the latest data.
Simple setup and day two operations: One of the best features of stretched clusters is their straightforward operation. They are like any standard, single-site cluster in most ways. Also, no manual intervention is required to recover from a site failure, making them easy to manage and deploy.
Stretch clusters can be complemented with multisite asynchronous replication for cross-region data replication.
But it’s essential to take into consideration that Ceph stretched clusters also have their caveats:
Networking is pivotal: Inter-site networking shortcomings (flapping, latency spikes or insufficient bandwidth) will impact performance and data integrity.
Performance. Write operation latency is increased by the RTT of the two most distant sites. When deploying across three sites pool replication ideally should be configured for replication with a replica schema of six, which means write amplification of six OSD operations per client write. We must set workload-specific expectations accordingly. For example, a high IOPS, low-latency OLTP database workload would probably struggle on a stretch cluster deployment.
Replica 6(or Replica 4 two-site stretch) is recommended for reliability. We keep six(or four) copies of the data. Using Erasure coding is not an option at the moment because of performance and intersite network resource usage. Total RAW capacity overhead considerations.
Single Cluster across all sites: If data gets damaged due to a software issue or deleted on the single stretch cluster, the data on all sites will be affected
Networking: The Foundation of a Stretch Cluster
A stretch cluster depends on robust networking to operate optimally; a suboptimal network configuration will impact performance and data integrity.
Equal Latency Across Sites: The sites are connected through a highly available L2 or L3 network infrastructure, where the latency between all the data availability zones/sites is similar. The RTT is ideally less than 10ms. Inconsistent network latency will degrade cluster performance.
Reliable L2/L3 network with minimal latency spikes, Inter-site networking path diversity for redundancy (full mesh or redundant transit).
Sufficient Bandwidth: The network should have adequate bandwidth to handle the replication, client request, and recovery traffic. Network bandwidth must scale with cluster growth: as we add nodes, we must also increase inter-site network throughput to maintain performance.
Networking QoS is required: Without QoS, a noisy neighbor generating a lot of cross-site traffic can degrade cluster stability.
Global Load Balancer: With object storage that uses S3 RESTful endpoints we need a GLB to redirect client requests in case of a site failure.
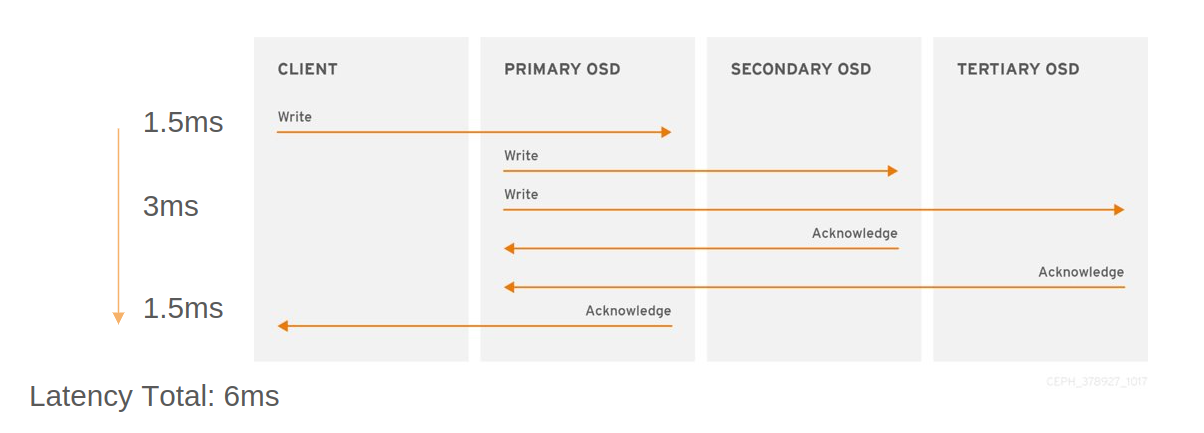
Performance. Each write will take, at a minimum, the slowest RTT between sites. The following diagram shows an example of a three-site stretch cluster with a 1.5ms RTT between sites, with a client and primary OSD at different sites:
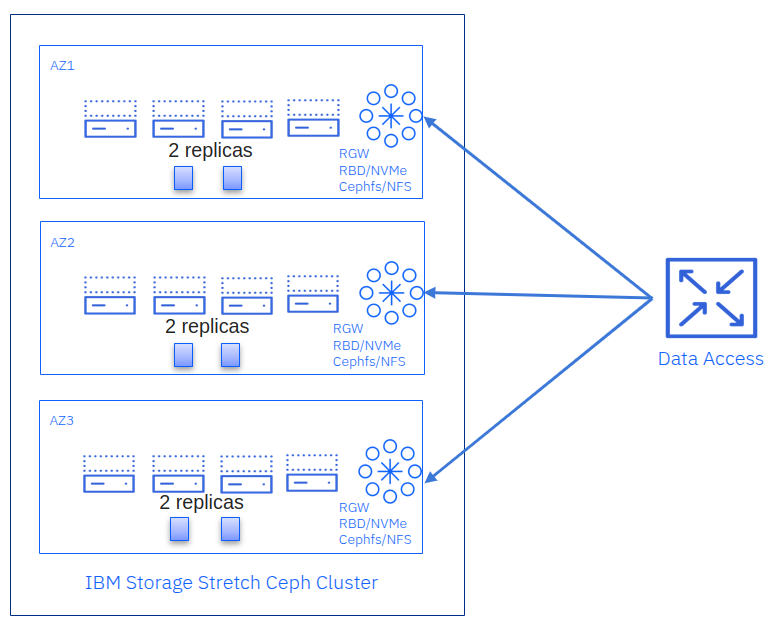
Three Site Stretch Cluster
Each data center (or availability zone) holds a portion of the OSDs in a three-site stretch cluster. You store two replicas of the data in each zone for a total pool size parameter of 6. This allows the cluster to serve client operations with zero data unavailability or loss if an entire site goes offline. Some highlights:
No Tiebreaker: Because there are three full data sites (OSDs in all sites), the cluster can form a quorum with any two.
Enhanced Resilience: Survives a complete site failure plus one additional OSD / node-level failure at surviving sites.
Network Requirements: L3 routing is recommended, and <10 ms RTT is required among the three sites.
If you want to delve deeper into Ceph 3-site stretch configurations, check out this excellent Cephalocon video from Kamoltat Sirivadhna, covering all the details.
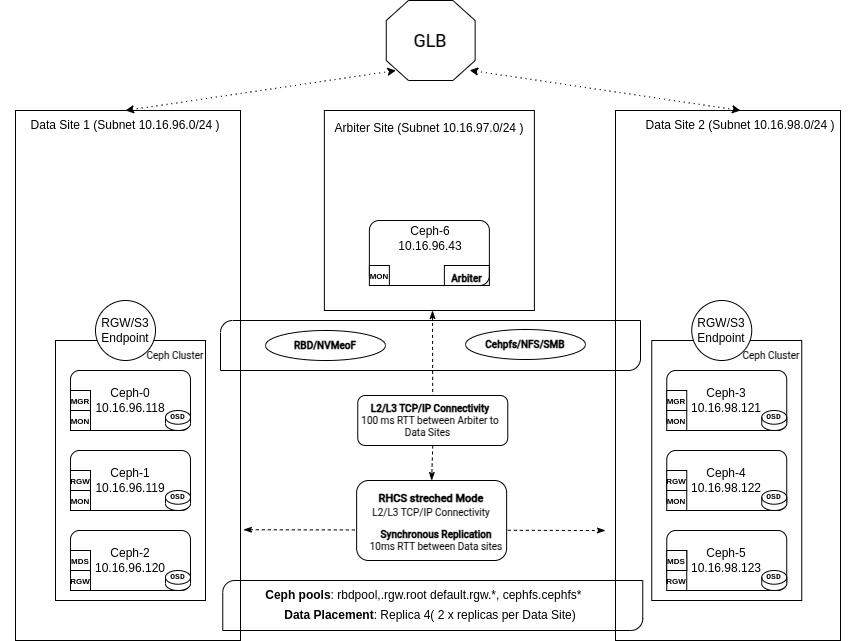
Two-Site Stretch Cluster with Tie-Breaker
For deployments where only two data centers have low-latency connectivity, you can place your Ceph OSDs in those two data centers with a smaller tie-breaker site elsewhere. This may even be a cloud VM hosting the tie-breaker Monitor. This ensures that the cluster maintains a quorum if a single site fails.
Two low latency main sites, each hosting half of the total OSD capacity.
One tie-breaker site hosting a a tie-breaker Monitor.
Replica Size: Pool replication size=4 (two replicas per data center).
Latency ~<10 ms RTT between main data centers. The tie-breaker can tolerate much higher latency (e.g., 100 ms RTT).
Improved netsplit handling: Prevents a "split-brain" scenario "
NVMe OSDs required. HDD OSDs are not supported.
Conclusion
IBM Storage Ceph supports both asynchronous and synchronous replication methods, each with its trade-offs for recovery objectives, operational complexity, and networking demands. Asynchronous replication (RBD Mirroring, RGW Multisite, or CephFS Snapshot Mirroring) provides flexibility and easy geo-deployment but carries a non-zero RPO. In contrast, a stretch cluster delivers RPO=0 by synchronously writing to multiple data centers, ensuring no data loss but requiring robust, low-latency inter-site connectivity and increased replica overhead.
Whether you choose a three-site or two-site with a tie-breaker design, a stretch cluster can seamlessly handle the loss of an entire data center with minimal operational intervention. However, it is crucial to factor in the stricter networking requirements (latency and bandwidth) and the higher capacity overhead of multiple replicas. For many critical applications where continuous availability and zero RPO are top priorities, the additional planning and resources for a stretch cluster may be well worth the investment.
In our next post (Part 2 of this series), we will explore two-site stretch clusters with a tie-breaker. We’ll provide practical steps for setting up Ceph across multiple data centers, discussing essential network and hardware considerations. Additionally, we will conduct a hands-on deployment, demonstrating how to automate the bootstrap of the cluster using a spec file. We will also cover how to configure CRUSH rules and enable stretch mode.
Subscribe to my newsletter
Read articles from Daniel Parkes directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by