How to Configure and Deploy an IBM Storage Ceph Stretch Cluster
 Daniel Parkes
Daniel ParkesIntroduction
In Part One we introduced the concepts behind IBM Storage Ceph’s replication strategies, emphasizing the benefits of a stretch cluster for achieving zero data loss (RPO=0). In Part Two, we will focus on the practical steps for deploying a two-site stretch cluster plus a tie-breaker monitor using cephadm.
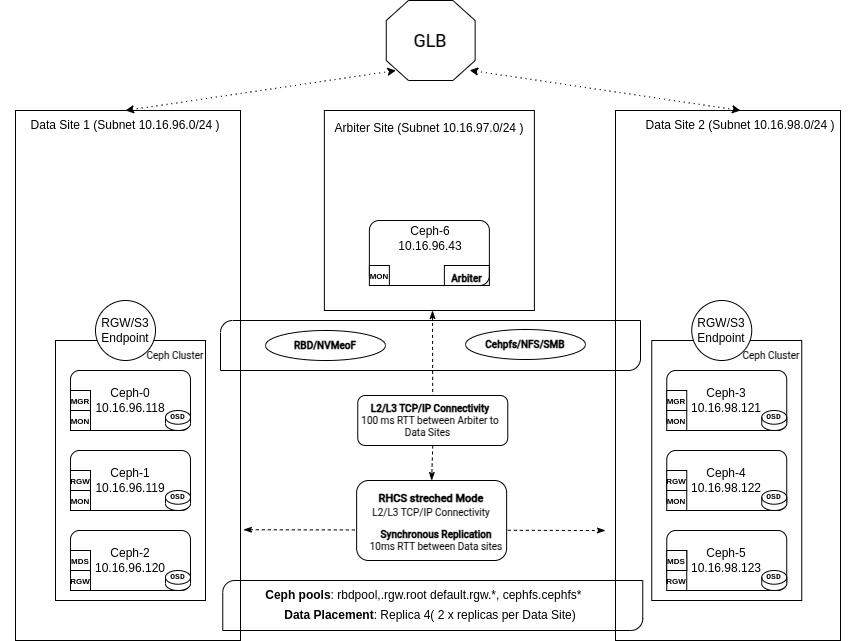
Network Considerations.
Network Architecture
In a stretch architecture, the network plays a vital role in maintaining the overall health and performance of the cluster.
IBM Storage Ceph features Level 3 routing, enabling communication between Ceph servers and components across different subnets and CIDRs at each DC/site.
Ceph standalone or stretch can be configured with two distinct networks:
Public Network: Used for communication across all Ceph services, including Monitors, OSDs, RGWs.
Cluster Network: When provisioned(the cluster network is optional), it will be used by OSDs for recovery and replication only at the data sites where OSDs are located.
Public & Cluster Network Considerations
The public network must be accessible across all three sites, including the tie-breaker site, since all IBM Storage Ceph services rely on it.
The cluster network is only needed at the two sites that house OSDs and should not be configured at the tie-breaker site.
Network Reliability
Unstable networks between the OSD sites will cause availability and performance issues in the cluster.
The network must not only be accessible 100% of the time but also provide consistency in latency(jitter).
Frequent spikes in latency can lead to unstable clusters, affecting client IO performance with issues like OSD flapping.
Latency Requirements
A maximum of 10ms RTT (Round Trip Time) is supported between the data sites (sites where OSDs are located).
Up to 100ms RTT is acceptable for the tie-breaker site (which can be deployed in a cloud provider if security policies allow)
If the tie-breaker node is in the cloud or on a remote network that uses a WAN, it is recommended to:
Set up a VPN between the data sites and the tie-breaker site.
Enable encryption in transit using Messenger v2 encryption, which secures communications among Monitors and other Ceph components.
Impact of Latency on Performance
Every write operation in Ceph follows a strong consistency model. It must be persisted to all configured OSDs in the placement group acting set before being acknowledged back to the client.
This adds RTT (Round Trip Time) between sites to the latency of every client write IO. Note that these replication writes, aka sub-ops, happen in parallel.
Throughput & Recovery Considerations
The inter-site bandwidth determines:
Maximum client throughput.
Speed of recovery after a node or site failure.
When a node fails, 67% of recovery traffic will be remote, meaning it will read from the other site and utilize the shared inter-site bandwidth alongside client IO.
Ceph designates a “primary” OSD for each placement group (PG). All writes go through this primary OSD, which may reside in a different data center than the client or RGW instance.
Optimizing Reads with read_from_local_replica
By default, all reads go through the primary OSD, which can increase cross-site latency.
The
read_from_local_replicafeature allows RGW and RBD clients to read from a local replica instead of constantly querying the primary OSD(that could reside on a different site).This minimizes cross-site latency, reduces inter-site bandwidth usage, and improves the performance for read-heavy workloads.
Available since Ceph 8.0 for both block (RBD) and object (RGW) storage.
Hardware requirements.
The hardware requirements and recommendations for IBM Storage Ceph Nodes are identical to those for standard (non-stretch) deployments, with a few exceptions that will be discussed below. For more information, please refer to the Hardware section in the IBM Storage Ceph documentation.
IBM Storage Ceph, in stretch mode, only supports all-flash configurations. HDD spindles are not supported.
IBM Storage Ceph, in stretch mode, only supports four replicas as the replication policy. Any other replication or erasure coding scheme is not supported. So, we need to plan our raw and usable storage capacities accordingly.
Device Class is unsupported; a crush rule containing, for example, `type replicated class hdd` will not work.
Local-only non-stretch pools are not supported.
Component placement
Ceph services, including Monitors, OSDs, and RGWs, must be placed to eliminate single points of failure and ensure that the cluster can withstand the loss of an entire site without impacting client access to the storage.
Monitors: At least five Monitors are required, two per data site and one on the tie-breaker site. This configuration ensures that quorum is maintained by ensuring that more than 50% of the configured Monitors are available even when an entire site is lost.
Manager: We can configure two or four Managers per data site. Four managers are recommended to provide high availability with an active/passive pair on a surviving site in case of a data site failure.
OSDs: They are distributed equally across data sites. Custom CRUSH rules must be created when configuring stretch mode, providing two copies in each site (four total for a two-site stretch cluster).
RGWs: Four RGW instances, two per data site, are recommended at minimum to ensure high availability for object storage from the remaining site in case of a site failure.
MDS: The minimum recommended number of CephFS Metadata Server instances is four, two per data site. In the case of a site failure, we will still have two MDS services on the remaining site, one active and the other acting as a standby.
NFS: Four NFS server instances, two per data site, are recommended at minimum to ensure high availability for the shared filesystem in case of a site failure.
Hands-on. Two Data Center Stretch Mode Deployment.
During the cluster bootstrap process with the cephadm deployment tool, we can utilize a service definition YAML file to handle most of the cluster configuration in a single step.
The stretched.yaml file provides an example of employing a template for deploying an IBM Storage Ceph Cluster configured in stretch mode. This is just an example and should be customized to fit your specific deployment needs.
service_type: host
addr: ceph-node-00.cephlab.com
hostname: ceph-node-00
labels:
- mon
- osd
- rgw
- mds
location:
root: default
datacenter: DC1
---
service_type: host
addr: ceph-node-01.cephlab.com
hostname: ceph-node-01
labels:
- mon
- mgr
- osd
- mds
location:
root: default
datacenter: DC1
---
service_type: host
addr: ceph-node-02.cephlab.com
hostname: ceph-node-02
labels:
- osd
- rgw
location:
root: default
datacenter: DC1
---
service_type: host
addr: ceph-node-03.cephlab.com
hostname: ceph-node-03
labels:
- mon
- osd
location:
root: default
datacenter: DC2
---
service_type: host
addr: ceph-node-04.cephlab.com
hostname: ceph-node-04
labels:
- mon
- mgr
- osd
- mds
location:
root: default
datacenter: DC2
---
service_type: host
addr: ceph-node-05.cephlab.com
hostname: ceph-node-05
labels:
- osd
- rgw
- mds
location:
root: default
datacenter: DC2
---
service_type: host
addr: ceph-node-06.cephlab.com
hostname: ceph-node-06
labels:
- mon
---
service_type: mon
service_name: mon
placement:
label: mon
spec:
crush_locations:
ceph-node-00:
- datacenter=DC1
ceph-node-01:
- datacenter=DC1
ceph-node-03:
- datacenter=DC2
ceph-node-04:
- datacenter=DC2
ceph-node-06:
- datacenter=DC3
---
service_type: mgr
service_name: mgr
placement:
label: mgr
---
service_type: mds
service_id: cephfs
placement:
label: "mds"
---
service_type: osd
service_id: all-available-devices
service_name: osd.all-available-devices
spec:
data_devices:
all: true
placement:
label: "osd"
With the specification file in place, run the cephadm bootstrap command. Notice that we pass the YAML specification file (--apply-spec stretched.yml) so that all services are deployed and configured in one step.
# cephadm bootstrap --registry-json login.json --dashboard-password-noupdate --mon-ip 192.168.122.12 --apply-spec stretched.yml --allow-fqdn-hostname
Once complete, verify that the cluster recognizes all hosts and their appropiate labels:
# ceph orch host ls
HOST ADDR LABELS STATUS
ceph-node-00 192.168.122.12 _admin,mon,osd,rgw,mds
ceph-node-01 192.168.122.179 mon,mgr,osd
ceph-node-02 192.168.122.94 osd,rgw,mds
ceph-node-03 192.168.122.180 mon,osd,mds
ceph-node-04 192.168.122.138 mon,mgr,osd
ceph-node-05 192.168.122.175 osd,rgw,mds
ceph-node-06 192.168.122.214 mon
Add the _admin label to at least one node in each datacenter so that you can run Ceph commands from each. This way, even if you lose an entire datacenter, you can execute Ceph admin commands from a surviving host.
# ceph orch host label add ceph-node-03 _admin
Added label _admin to host ceph-node-03
# ceph orch host label add ceph-node-06 _admin
Added label _admin to host ceph-node-06
# ssh ceph-node-03 ls /etc/ceph
ceph.client.admin.keyring
ceph.conf
Hands-on. How does Ceph write two copies of the data per site?
IBM Storage Ceph, when configured in stretch mode, requires a replica configuration of four. This means two copies of data at each site, ensuring availability if an entire site goes down.
Ceph uses the CRUSH map to determine where to store object replicas. The CRUSH map logically represents the physical hardware layout, organized in a hierarchy of bucket types, including datacenters, rooms, racks, and hosts. To configure a stretch mode CRUSH map, we define two datacenters under the default CRUSH root, then place the host buckets within the appropriate datacenter CRUSH bucket.
The following example shows a stretch mode CRUSH map featuring two datacenters, DC1 and DC2, each with three Ceph OSD hosts. We get the following configuration right out of the box, thanks to the spec file we used during bootstrap, where we specify the location of each host in the CRUSH map.
# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.58557 root default
-3 0.29279 datacenter DC1
-2 0.09760 host ceph-node-00
0 hdd 0.04880 osd.0 up 1.00000 1.00000
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-4 0.09760 host ceph-node-01
3 hdd 0.04880 osd.3 up 1.00000 1.00000
7 hdd 0.04880 osd.7 up 1.00000 1.00000
-5 0.09760 host ceph-node-02
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
-7 0.29279 datacenter DC2
-6 0.09760 host ceph-node-03
4 hdd 0.04880 osd.4 up 1.00000 1.00000
6 hdd 0.04880 osd.6 up 1.00000 1.00000
-8 0.09760 host ceph-node-04
10 hdd 0.04880 osd.10 up 1.00000 1.00000
11 hdd 0.04880 osd.11 up 1.00000 1.00000
-9 0.09760 host ceph-node-05
8 hdd 0.04880 osd.8 up 1.00000 1.00000
9 hdd 0.04880 osd.9 up 1.00000 1.00000
Here, we have two datacenters (DC1 and DC2). A third datacenter, DC3 holds the tie-breaker monitor (ceph-node-06) but does not host OSDs.
To achieve our goal of having two copies per site, we need to define a stretched crush rule that will be assigned to our Ceph RADOS pools.
Install the ceph-base RPM to get the crushtool binary
# dnf -y install ceph-base
Export the CRUSH map to a binary file
# ceph osd getcrushmap > crush.map.bin
Decompile the CRUSH map to a text file
# crushtool -d crush.map.bin -o crush.map.txt
Edit the crush.map.txt file to add a new rule at the end of the file; we need to add
rule stretch_rule {
id 1
type replicated
step take default
step choose firstn 0 type datacenter
step chooseleaf firstn 2 type host
step emit
}

Inject the CRUSH map to make the rule available to the cluster
# crushtool -c crush.map.txt -o crush2.map.bin
# ceph osd setcrushmap -i crush2.map.bin
Validate the new rule is available:
# ceph osd crush rule ls
replicated_rule
stretch_rule
Hands-on. Configure our Monitors for Stretch mode.
Thanks to our bootstrap spec file, the monitors have been labeled according to the data center to which they belong. This labeling ensures Ceph can maintain quorum even if one data center experiences an outage. In such cases, the tie-break monitor in data center three(DC 3) can assist one of the other data centers in achieving the required MON quorum.
# ceph mon dump | grep location
0: [v2:192.168.122.12:3300/0,v1:192.168.122.12:6789/0] mon.ceph-node-00; crush_location {datacenter=DC1}
1: [v2:192.168.122.214:3300/0,v1:192.168.122.214:6789/0] mon.ceph-node-06; crush_location {datacenter=DC3}
2: [v2:192.168.122.138:3300/0,v1:192.168.122.138:6789/0] mon.ceph-node-04; crush_location {datacenter=DC2}
3: [v2:192.168.122.180:3300/0,v1:192.168.122.180:6789/0] mon.ceph-node-03; crush_location {datacenter=DC2}
4: [v2:192.168.122.179:3300/0,v1:192.168.122.179:6789/0] mon.ceph-node-01; crush_location {datacenter=DC1}
When running a Stretch Cluster with three sites, only the communication between one site and another is affected if we have an asymmetrical network error. We can get into an infinite monitor re-election issue, where no monitor can get selected as the leader.

To avoid this problem, we will change our election strategy from a classic approach to a connectivity-based one. The connectivity mode assesses the connection scores each monitor provides for its peers and elects the monitor with the highest score. This model is specifically designed to handle better network partitioning, known as netsplits. Network partitioning may occur when your cluster is spread across multiple data centers, and all links connecting one site to another are lost.
# ceph mon dump | grep election
election_strategy: 1
# ceph mon set election_strategy connectivity
# ceph mon dump | grep election
election_strategy: 3
You can check monitor scores with the following:
# ceph daemon mon.{name} connection scores dump
If you want to know more about the MON connectivity election strategy, check out this excellent video from Greg Farnum. Further information is also available at this link.
Hands-on. Enabling Ceph Stretch Mode
To enter stretch mode, run the following command:
# ceph mon enable_stretch_mode ceph-node-06 stretch_rule datacenter
Where:
ceph-node-06 is the tiebreaker (arbiter) monitor in DC3.
stretch_rule is the CRUSH rule that enforces two copies in each data center.
datacenter is our failure domain
Check the updated MON configuration:
# ceph mon dump
epoch 20
fsid 90441880-e868-11ef-b468-52540016bbfa
last_changed 2025-02-11T14:44:10.163933+0000
created 2025-02-11T11:08:51.178952+0000
min_mon_release 19 (squid)
election_strategy: 3
stretch_mode_enabled 1
tiebreaker_mon ceph-node-06
disallowed_leaders ceph-node-06
0: [v2:192.168.122.12:3300/0,v1:192.168.122.12:6789/0] mon.ceph-node-00; crush_location {datacenter=DC1}
1: [v2:192.168.122.214:3300/0,v1:192.168.122.214:6789/0] mon.ceph-node-06; crush_location {datacenter=DC3}
2: [v2:192.168.122.138:3300/0,v1:192.168.122.138:6789/0] mon.ceph-node-04; crush_location {datacenter=DC2}
3: [v2:192.168.122.180:3300/0,v1:192.168.122.180:6789/0] mon.ceph-node-03; crush_location {datacenter=DC2}
4: [v2:192.168.122.179:3300/0,v1:192.168.122.179:6789/0] mon.ceph-node-01; crush_location {datacenter=DC1}
Ceph specifically disallows the tie-breaker monitor from ever assuming the leader role. The tie-breaker’s sole purpose is to provide an additional vote to maintain quorum if one primary site fails, preventing a split-brain scenario. By design, it resides in a separate, often smaller environment (for example, a cloud VM) and may have higher latency or fewer resources. Allowing it to become the leader could undermine performance and consistency if it were geographically distant or less stable. Therefore, Ceph marks the tie-breaker monitor as “disallowed_leader,” ensuring that the main data sites retain primary control of the cluster while benefiting from the tie-breaker quorum vote.
Hands-On. Verifying Pool Replication and Placement when stretch mode is enabled
When the stretch mode is enabled, the Object Storage Daemons (OSDs) will only activate Placement Groups (PGs) when they peer across datacenters, provided both are operational. The following constraints apply:
The number of pools will increase from the default of 3 to 4, with the expectation of having two copies at each site.
OSDs are permitted to connect only to monitors within the same datacenter.
New monitors cannot join the cluster unless their location is specified.
# ceph osd pool ls detail
pool 1 '.mgr' replicated size 4 min_size 2 crush_rule 1 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 199 lfor 199/199/199 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 12.12
pool 2 'rbdpool' replicated size 4 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 199 lfor 199/199/199 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd read_balance_score 3.38
Inspect the placement groups (PGs) for a specific pool ID and confirm which OSDs are in the acting set:
# ceph pg dump pgs_brief | grep 2.c
dumped pgs_brief
2.c active+clean [2,3,6,9] 2 [2,3,6,9] 2
In this example, PG 2.c has OSDs 2 and 3 from DC1, and OSDs 6 and 9 from DC2.
You can confirm the location of those OSDs with the ceph osd tree command:
# ceph osd tree | grep -Ev '(osd.1|osd.7|osd.5|osd.4|osd.0|osd.8)'
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.58557 root default
-3 0.29279 datacenter DC1
-2 0.09760 host ceph-node-00
-4 0.09760 host ceph-node-01
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host ceph-node-02
2 hdd 0.04880 osd.2 up 1.00000 1.00000
-7 0.29279 datacenter DC2
-6 0.09760 host ceph-node-03
6 hdd 0.04880 osd.6 up 1.00000 1.00000
-8 0.09760 host ceph-node-04
-9 0.09760 host ceph-node-05
9 hdd 0.04880 osd.9 up 1.00000 1.00000
Hence, each PG has two replicas in DC1 and two in DC2—the core concept of stretch mode.
Conclusion.
By deploying a two-site stretch cluster (with a third-site tie-breaker monitor), you ensure that data remains highly available even during an entire data center outage. Leveraging a single custom specification file allows for automatic and consistent service placement across both sites—covering monitors, OSDs, and other Ceph components. The connectivity election strategy also helps maintain a stable quorum by prioritizing well-connected monitors. Combining these elements—careful CRUSH configuration, correct labeling, and an appropriate replication factor—results in a resilient storage architecture that handles inter-site failures without compromising data integrity or service continuity.
In the final part of our series (Blog 3), we will test the stretch cluster under real-world failure conditions. We will investigate how Ceph automatically shifts into a degraded state when a complete site goes offline, the impact on client I/O during this outage, and the recovery process once the site is restored—ensuring zero data loss.
Subscribe to my newsletter
Read articles from Daniel Parkes directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by