Encryption Isn't Enough: Compromising a Payment Processor using Math
 Max Maass
Max Maass
During a security engagement with my employer, iteratec, I found and reported a security issue that allowed me to completely compromise the internal customer service frontend of a payment processor, which would have let us steal customer information or trigger payments.
What makes this issue interesting is both the internal mechanisms of the issue (an entertaining case of incorrect use of cryptography) and the things it can teach us about secure system design, and how seemingly small architecture decisions can exacerbate the severity of a vulnerability. In this article, we will start with a high-level view of the system, and then drill down into one part until we reach the problem. We will then discuss how and why the attack works, before zooming back out and discussing how a more robust system design could have mitigated the issue.
So, without further ado, let's dig in.
The System
The software under test was part of a larger system that, taken together, handled payment processing, accounting, refunds, customer service, and several other features. It was using a microservice architecture, with the individual components linked together through REST and message queueing APIs. A central identity management (IDM) system was handling identities for both users and service accounts (the latter being used by microservices when communicating with each other). Individual users and accounts could have roles assigned to them, and these roles would be checked by the REST interfaces of the individual microservices to verify authentication and authorization. All REST communication was routed via two API gateways, one for external APIs, and one for internal use between microservices.
The scope of the security check was a single application, which was used by the internal staff of the company to (among other things) inspect the state of payments (e.g., when a customer was asking if their payment had come through), and trigger repayments (e.g., when a customer was canceling an order or had accidentally overpaid). It consisted of a frontend running in a browser, that communicated with a Backend-for-Frontend (BFF) which would receive requests from the frontend, ensure the users' session was valid and the user was allowed to use the requested functionality, and translate them to REST calls to other services (via an API gateway) which were authenticated with the service account of the BFF by including an access token obtained from the IDM as part of the request. The use of an API gateway allows the system to keep the actual microservices behind a firewall and only expose the API gateway, reducing the attack surface and providing a single place for authenticating, logging, and auditing incoming requests.

The Feature
Today, we are interested in one specific feature of the system: the file download. In some cases, a customer service representative would need to be able to look at an invoice or another document in the system. These documents were managed by a different microservice, so this required a call via the API gateway, triggered by the BFF. The developers chose to model this by having the BFF retrieve the list of documents as part of their backend call that retrieved information about a specific payment. The list of documents provided convenient download links that could be retrieved when in possession of the correct access token - however, since the users didn’t have an access token for the API gateway, any download would have to be proxied through the BFF.
The trivial solution would have been to simply provide these links to the frontend and create an endpoint on the BFF of the form /api/file_download?url=https://api.company.com/files/abc.pdf. However, the developers were (rightly) wary of creating an API like this, as it could be abused for an attack called server-side request forgery (SSRF), where an attacker could provide arbitrary URLs and trick the server into requesting them. This can be prevented by performing detailed checks of the requested URLs, but there is always a residual risk that you got something wrong and an attacker can slip through the cracks.
The developers decided to instead encrypt these links and provide an API endpoint that received these base64-encoded ciphertexts, decrypted them, and downloaded the linked files to provide them to the users. In the end, the full sequence of requests and responses would look like this (a key signifies that a request is authenticated with a service account access token that the API gateway understands):

With this strategy, the developers figured that there should be no risk of accidentally introducing an SSRF vulnerability, as the attacker would need to know the secret key the application is using for encryption and decryption to insert a different URL.
Taking A Closer Look
I am a sucker for any kind of cryptography, so I always take a closer look when I see something like this. In 99% of the cases, you won't find anything, but thinking through all of the subtle ways cryptography may go wrong brings me joy. As this was a "whitebox" engagement (with full access to the source code of the system), I decided to take a closer look.
The BFF was written in Javascript, and the encryption function looked something like this:
// this.key contains the cryptographic key
cipher(text: string) {
// Generate a 16-byte random initialization vector (IV)
const iv = crypto.randomBytes(16);
// Initialize the cryptographic API
const cipheriv = crypto.createCipheriv("aes-128-cbc", this.key, iv);
// Encrypt the data
const encrypted = Buffer.concat([cipheriv.update(text), cipheriv.final()]);
// Return base64(IV).base64(ciphertext)
return iv.toString("base64") + "." + encrypted.toString("base64");
}
Roughly speaking, the system would generate a so-called initialization vector (IV - more on that below) using a cryptographic randomness function, do some basic setup for encrypting data with AES 128 in Cipher Block Chaining (CBC) mode under a fixed key, encrypt the data, and then return the IV and encrypted string (ciphertext), separated using the dot as a separator character. This is the result that is given out to the frontend.
To decrypt, the same is done in reverse: The data is sent from the frontend to the BFF, split on the dot, the IV and ciphertext decoded from its base64 representation, and the result is decrypted using the fixed cryptographic key in the application. The BFF then retrieves the decrypted URL, attaching its access token to authenticate against the API gateway.
Since not everyone reading this will be intimately familiar with the ins and outs of cryptography, I will quickly recap some basics of cryptography that will be required to understand how this setup poses a security risk. Feel free to skip over any parts that you are already familiar with.
Cryptography 101: Symmetric Encryption
The system uses AES to en- and decrypt the data. AES is a so-called symmetric encryption algorithm - the same key is used for encryption and decryption. In mathematical notation, you generally say that the plaintext \(P\) is encrypted under the key \(k\) to create a ciphertext \(C\) (in short: \(C = Enc(k, P)\)), and can be decrypted using the same key (so that \(Dec(k, C) = P\) - I'm giving these notations as it will make understanding the attack easier down the line).
Symmetric ciphers have the advantage that they are quite fast, and in a setup like this, where the same machine is encrypting and decrypting all data, you also don't have to worry about how to make sure that \(k\) is distributed to the right machines. So, this seems like a good choice for the scenario.
Cryptography 102: Block Cipher Modes
Now, AES (like any other cryptographic primitive) has one drawback: It can only encrypt a limited amount of data. In the case of AES-128, that is 128 bits or 16 bytes. However, most data that you may want to encrypt are longer than 16 bytes. Your first intuition may be to simply split the data into blocks of 16 bytes and encrypt each block separately under the same key:
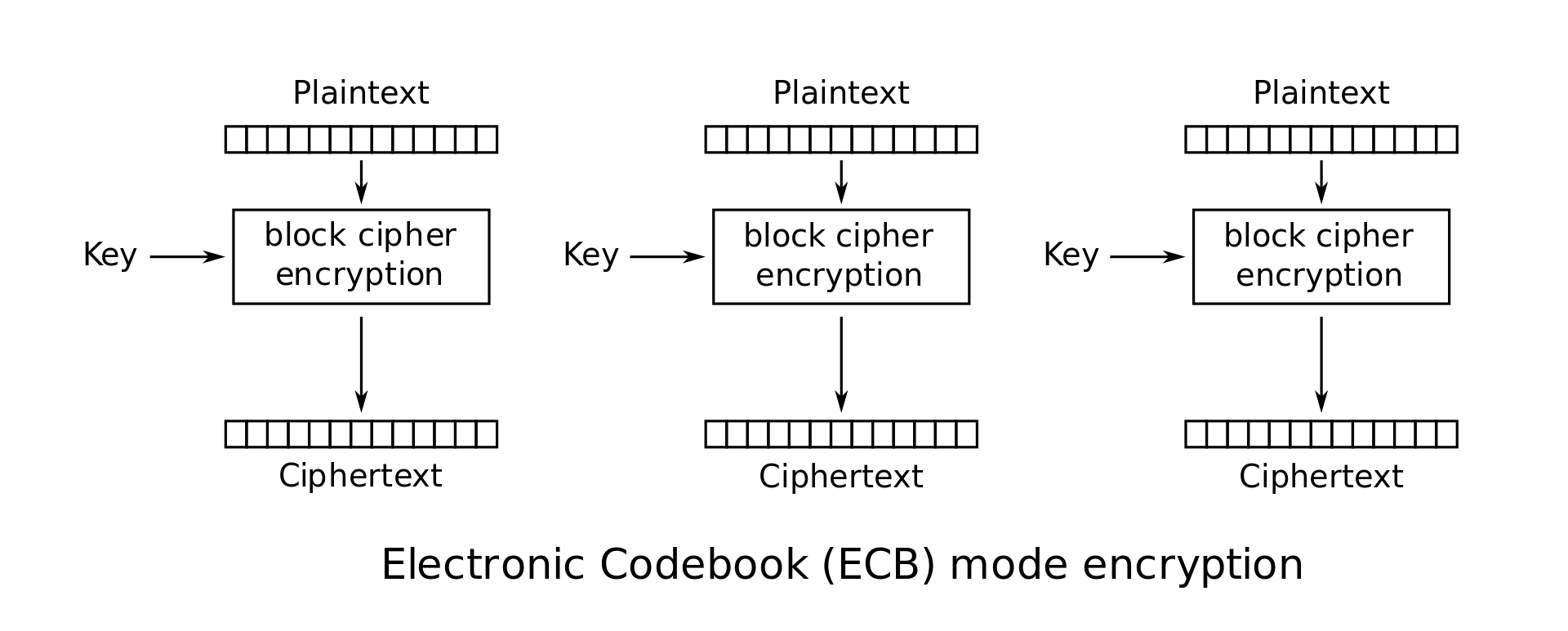
(This image, and the following similar illustrations, were all created by WhiteTimberwolf and placed in the public domain. You can find the originals in this Wikipedia article)
This approach is called the "Electronic Codebook" (ECB) mode, and is insecure, as it reveals patterns in the encrypted data if specific blocks of the plain text are identical (you may be familiar with this famous illustration of the problem).
Now, this isn't great, so, several alternatives were designed. The one we are interested in here is called Cipher Block Chaining (CBC). In this mode, the ciphertext of the previous block is combined with the plaintext of the to-be-encrypted block using the exclusive OR (XOR, denoted \(\oplus\) in mathematical notation) operation.

Or, written in a more mathematical way: \(C_n = Enc(k, P_n \oplus C_{n-1})\). This ensures that repeating patterns of data in the plaintext do not result in repeating ciphertext blocks. This leaves us with an edge case: What happens with the first block, for which no previous block of ciphertext exists? Here, we instead use a string of random bytes called the Initialization Vector (IV) in place of the ciphertext of the previous block, i.e. \(C_0 = Enc(k, P_0 \oplus IV)\). This IV is sent together with the ciphertext (i.e., it isn't secret), and is needed to properly decrypt the data.
To decrypt, the process is done in reverse:

Or, written as a formula: \(P_n = Dec(k, C_n) \oplus C_{n-1}\), with \(P_0 = Dec(k, C_0) \oplus IV\). This works because if you XOR a value with itself, it will cancel out, leading to the original plaintext. So, the decryption looks like this:
$$\begin{align} P_n &= Dec(k, C_n) \oplus C_{n-1} \\ &= P_n \oplus C_{n-1} \oplus C_{n-1} \\ &= P_n \\ \\ P_0 &= Dec(k, C_0) \oplus IV \\ & = P_0 \oplus IV \oplus IV \\ & = P_0 \end{align}$$
And that's all there is to it - CBC mode is a fairly straightforward encryption mode that addresses the problems of ECB mode without adding a ton of extra complexity.
Encrypting data like this is all well and good if your goal is to keep the data confidential. However, in this system, the secrecy of the data isn't actually the most important part - making sure that the data remains unchanged is. This property, called authenticity, is what we really want to achieve.
Looking at it from this lense, we begin to see a problem: Using encryption does not, in itself, provide any authentication of the ciphertext - we can simply change the ciphertext and the server will happily try to decrypt the data (and receive garbage as the resulting plaintext).
This, in itself, isn't very useful to us as an attacker. But what if we could figure out a way to change the data we provide to the server in a specific way, so that a predictable, targeted change in the plaintext occurs during decryption?
Cryptography 201: Malleable Encryption
Let's take another look at CBC mode decryption, specifically that of the first block of data. To refresh your memory, here's the formula:
$$\begin{align} P_0 &= Dec(k, C_0) \oplus IV \\ & = P_0 \oplus IV \oplus IV \\ & = P_0 \end{align}$$
Recall that neither \(C_0\) nor the \(IV\) are protected against modification. Now, let's assume for a moment that we know the value of \(P\_0\), and our goal is to ensure that the decryption will result in a different value, denoted \(P\_0'\). How can we achieve this?
The answer is: fairly easily. First, we need to determine the difference (i.e., the XOR) between the two values - let's call it \(D\) for "difference":
$$D= P_0 \oplus P_0'$$
Now, let's take this difference, and XOR it on the initialization vector (IV) we have, to obtain a new IV:
$$IV'=IV\oplus D$$
If we now provide the (unchanged) ciphertext together with the new IV to the server to decrypt, it will compute the following:
$$P_0^? = Dec(k, C_0) \oplus IV'$$
First, let's resolve the decryption operation
$$P_0^? = P_0 \oplus IV \oplus IV'$$
Now, we know what \(IV'\) is from the earlier formula, so let's substitute it in.
$$P_0^? = P_0 \oplus IV \oplus IV \oplus D$$
And we know the value of \(D\) as well, as we computed it earlier, so let's put that into the formula as well:
$$P_0^? = P_0 \oplus IV \oplus IV \oplus P_0 \oplus P_0'$$
Now, since we know that a value XORed with itself will cancel out, we can simplify the formula in two steps:
$$\begin{align} P_0^? &= P_0 \oplus IV \oplus IV \oplus P_0 \oplus P_0' \\ &= P_0 \oplus P_0 \oplus P_0'\\ &= P_0' \end{align}$$
And... that's it - we have just tricked the server into decrypting the ciphertext to a different value under our control.
What does this allow us to do?
We now have full control over the first block (128 bits = 16 bytes) of the plaintext - what can we do with this? Well, remember how we talked about the possibility of server-side request forgery (SSRF) earlier? Looking at the URL, we have control over the first 16 characters, so the highlighted part of https://api.company.com/v1/… - the rest of the URL will remain constant. That is actually enough to redirect the request to a different server, assuming we have a sufficiently short domain name!
For this example, let’s assume I own the domain atk.me. I could manipulate the first 16 bytes of the address to make it decrypt to http://atk.me?q=any.com/v1/…, by computing the XOR of the original 16 bytes and my target. In this case, the plaintext URL was known to me due to the whitebox approach in the pentest (and due to an unrelated information leak where it was contained in an error message), so this was trivial. If the URL isn’t known, it could either be guessed, or another cryptographic attack could be applied (a so-called padding oracle attack), which would allow you to recover the full plaintext of the encrypted message under certain conditions (you can find an explanation of this attack in this article by NCC Group).
The request to the new target still contains the access token that the BFF is using to authenticate against the API gateway, and the BFF will happily send it over to us. So now we are in possession of a valid access token for the API gateway.
How System Architecture made this Worse
Now, so far, all of this is bad, but recoverable. However, we will now see a series of seemingly trivial architectural decisions that turn this from a nuisance into a disaster for the whole system.
Violation of the “Cryptographic Doom Principle”
First of all, all of this is only possible because the system uses unauthenticated ciphertext. This violates the aptly-named “Cryptographic Doom Principle” by Moxie Marlinspike (Creator of the Signal messenger, among other things):
If you have to perform any cryptographic operation before verifying the MAC on a message you’ve received, it will somehow inevitably lead to doom.
(Quoted from The Cryptographic Doom Principle, by Moxie Marlinspike)
Authenticating the ciphertext (and IV!) would have prevented this entire attack, rendering all the following points moot.
No URL Target Checks
A major tool for preventing server-side request forgery is to check the accessed domain by parsing it (using a dedicated URL parser that understands the structure of URLs) and matching the target domain of the request against a list of allowed domains. Done correctly, this can completely prevent SSRF attacks (although it is admittedly hard to do correctly). However, since the data was assumed to be trustworthy due to the use of encryption, no such protections were in place.
However, even if outgoing requests had been restricted to the domain of the API gateway, the more advanced padding oracle attacks (linked above) would have allowed making arbitrary changes to the requested path, and at least made it possible to access arbitrary GET endpoints and retrieve the results, which could lead to data leaks. So, while this would have made the attack less severe, it would have still been damaging.
Allowing Outbound Traffic
Another seemingly trivial question is: why is the BFF even allowed to contact servers that aren’t the API gateway? Its only job is to access the API gateway, so access to the internet at large would not be necessary and could be prevented using firewall rules. This would have prevented the request to the attackers server from being made, and thus the access token from being leaked.
Lack of Network Segmentation
However, the network situation is even worse in practice: The system architecture actually places the firewall behind the API gateway, not the BFF, meaning that I can access the API gateway from the open internet. This allows me to actually use my access token to authenticate against the API gateway and make arbitrary requests with it.
Overprivileged Tokens
Additionally, it turns out that the access token was the same for all requests made by the BFF. This was done so that the token could be cached and the BFF didn’t have to obtain a new access token from the IDM for every request, thereby reducing load on the IDM and decreasing latency. This is a valid architectural choice, but it means that for any given request to the API gateway, the token is overprivileged, as it always contains the roles necessary to access all API endpoints used by the BFF, not just the one it is currently accessing. So, our stolen access token is not just valid for the file download endpoint, but also to the ones for querying customers and orders, crediting customer accounts with refunds, and many more. We call these tokens “god tokens”, as they have practically unlimited power, and losing one of them is often catastrophic.
No Trustworthy Audit Logs
This also means that the API gateway cannot determine which specific user is actually using the system right now - it only sees a generic access token. This makes the BFF the only instance that can enforce user-based permissions and maintain trustworthy audit logs about which user performed what action. Other services had to rely on the representations made by the BFF, which would include information about the users’ identity (for audit logging), but which could be trivially changed if we are accessing the API gateway directly, as this identity is not cryptographically signed. So, not only could I take arbitrary actions, I could also place the blame for them on arbitrary employees by including their identity in the requests.
What Can We Learn From This?
There are probably a lot more things that I could mention here, but this article is already getting out of hand, so let’s wrap up. What can we learn from this? Well, first of all, I hope that if you take just one thing from this, it is this: authenticate your ciphertexts. But if you take a second thing from it: architecture matters! The way you separate your system into different components, decide which component is responsible for what, and which of them are allowed to talk to each other, matters! Reducing the access that each service has, matters! Getting this wrong may not, in isolation, lead to a security incident, but it will make any incident caused by errors in implementation, vulnerable dependencies, or whatever other reason, much worse.
Defense in depth can be a powerful tool to reduce the blast radius of any single vulnerability you have. These things are often easiest to find by conducting a threat modeling session with an experienced security team. However, if this isn’t possible for you, simpler methods for threat modeling exist that do not rely on having an experienced security professional on staff (I recommend the “Threat Modeling Fast, Cheap and Good” whitepaper by Adam Shostack for more on this).
The bad news is: Building 100% secure systems is hard. But the good news is: building systems that don’t immediately fall apart when a single vulnerability is discovered is actually a lot easier. Keep Defense in Depth in mind during design and implementation. Think about what would happen if any one of your assumptions is invalid, then design countermeasures for that - just in case. Most of them will never get tested, but if they do, you’ll be glad you spent the time.
Acknowledgements
This article (and the german-language conference talk it is based on) would not be the way they are today if it hadn’t been for my (now former) team lead at iteratec, Robert Felber, and for my colleagues from our internal security community. I was presenting an early version of the talk at our internal meetup, and after I described the initial architecture of the system he interrupted me and asked a very simple question: “Is this actually a good architecture?”. This question and the subsequent discussion completely changed how I looked at this vulnerability, and turned it from an entertaining cryptographic bug into a lesson in defensive system design.
Subscribe to my newsletter
Read articles from Max Maass directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Max Maass
Max Maass
Security Expert at iteratec. I break your software before other people do, and then help you secure it afterwards :).