AI 室內設計工作流教學 (三):ComfyUI實際應用
 Wayne Huang
Wayne Huang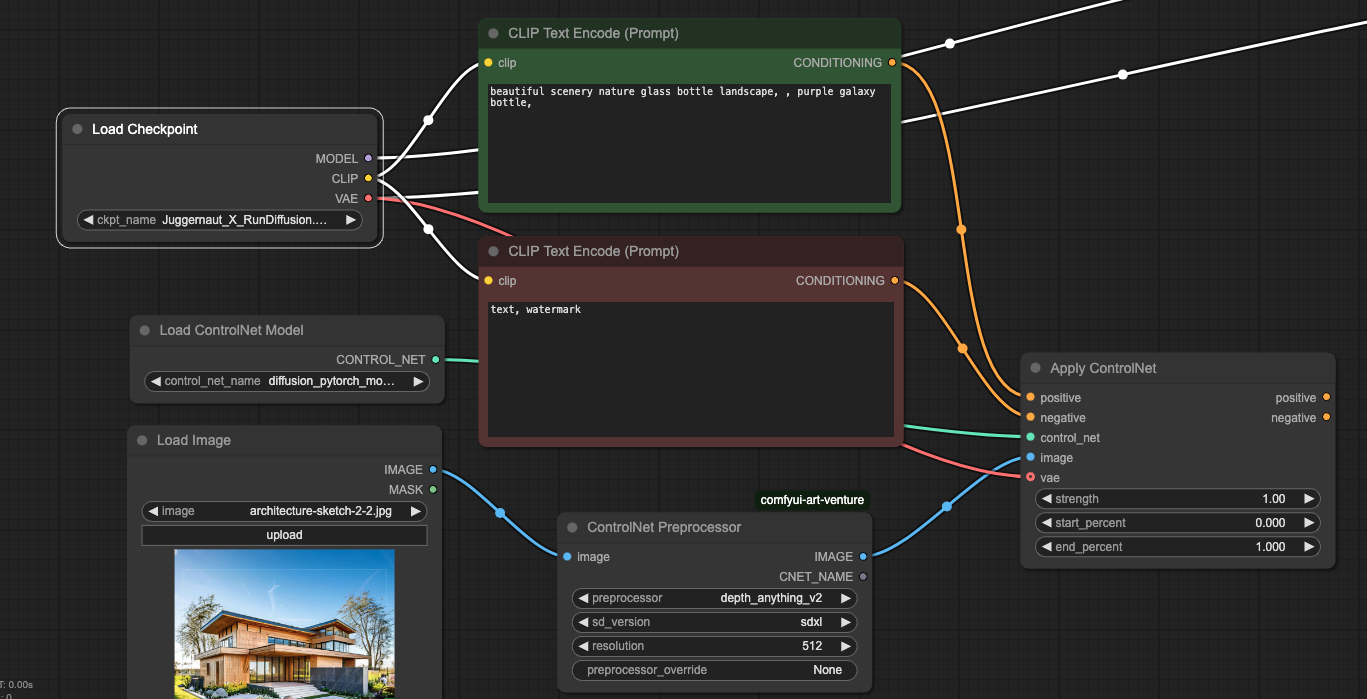
生成第一張圖
安裝完ComfyUI、也下載完模型之後,應該會看到以下的畫面:

我們可以直接點擊下方的藍色按鈕Queue來生成我們的第一張圖片:

等待一段時間後,就會生成出圖片,但在這同時,我們可以先點擊左上角的時間按鈕,或者按下快捷鍵Q來打開圖片生成隊列(下圖紅色框線部分)。

點下後就可以看到目前圖片處理的情況。如果按下多張圖,會依照先後順序一張張處理、生成。處理完後會顯示生成花費的時間(圖片左下綠色數字)。


生成一張AI圖片沒有想像中難吧,接下來會開始詳細介紹各個元件的功能。
重要資訊:Mac版的ComfyUI如果遇到生成不出圖片只生成黑畫面,請依照下圖圈選的方式設定Ksampler:
sampler_name : dpmpp_2m_sde
scheduler : beta

在剛剛生成第一張圖的過程中,我們在介面上能夠看到很多的方塊被連結起來,這些方塊被稱為節點(Node)
節點(Node)
ComfyUI就是一個節點式的工作流工具,在comfyUI裡節點是最基礎的單位,如下圖所示:

黃色框起來的部分是一個節點(Node)

節點(Node)之間能夠連結起來,連結就代表著資料從節點到節點的傳輸,上圖的意思就是將Clip節點(文字節點)中的文字作為輸出,輸入到連結的KSampler節點的positive輸入中。
在節點左側連接點 : 輸入(input)、例如:Ksampler節點的positive,negative輸入。
在節點右側連結點 : 輸出(Output)、例如:Ksampler節點的Latent輸出。

滑鼠移動到輸出點的上方時按下滑鼠左鍵拖曳即可拉出一條連結線,同顏色的輸出可以連結到同顏色的輸入,把連結線連到其他節點的輸入即可完成兩個節點的資料串接。

這個流程有防呆機制,只有可連接的點會被顯示,讓你可以簡單判斷可以連到哪裡。如果連到無效的輸入點就不會產生連結。
自訂節點 (Custom Node)
除了一般內建的節點,想要使用更多功能,如Inpaint / controlnet的時候,就必須針對功能下載相應的自訂節點(Custom Node),關於Custom Node的詳細介紹,會在這篇教學文章的後半段提到。
工作流
理解了節點之後,我們來說說工作流:藉由連接這些功能各異的節點,我們可以將這些節點依照我們想要的工作流程串接成一個工作流(workflow)。我們可以自行建立,也可以下載其他人建立的工作流。
文生圖workflow
比如這個ComfyUI最基礎的文生圖工作流(Text-to-Image workflow)。

在一個文生圖的流程中,我們的目標是輸入一組提示詞來產出一張圖片。要達成這個目標,我們需要串接節點來達成這件事情。
文生圖流程解說:
在(1)Checkpoint Loader節點載入生成圖像的模型。
在**(2)CLIP Text Encode**節點中輸入 提示詞:
正向提示詞(Prompt):描述希望在圖片中呈現的元素。
負向提示詞(Negative Prompt):排除不希望出現的元素。
在 (5) Latent Image 節點中設定 圖片尺寸、 需要生成幾張。
這些參數會一同傳送到 (3)KSampler 節點進行處理。KSampler 節點負責 控制模型的生成過程,包括:
步數(Steps):決定去噪的次數,影響細節與品質。
提示詞影響程度(CFG Scale):控制 AI 對提示詞的依從程度。
採樣器(Sampler):選擇不同的演算法影響風格與細節。
經過 KSampler 節點運算後,會產生一張 潛在圖像(Latent Image),這還不是最終人類可以理解的圖像。
需要透過 (4)VAE節點解碼,將其轉換為可見圖像。
最後,生成的圖片可以輸出至(5) Preview(預覽) 或 Save Image(儲存) 節點,以便查看或保存。
節點詳細介紹(Node Introduction):
Load Checkpoint:
這個節點的功能就是載入大模型,任何放在Checkpoint資料夾中的大模型都可以被這個節點讀取到。而最常見的就是SD模型,其他的還有Flux,模型本身會直接影響生成時間和生成影像的品質、VRAM使用量,這些模型可以從某些特定網站下載:常見的有Civitai、Github、Hugginface 等等,之後會再說明。
 💡關於SD(Stable Diffusion)模型:SD模型是一種Diffusion 模型,這是一種深度學習模型,主要用於 圖像生成、修復、風格轉換等任務。它的基本概念是:1. 先將圖片逐步添加隨機雜訊(Forward Process),讓其變成完全無法辨識的雜訊圖。2. 再透過 AI 逐步去除雜訊(Reverse Process),讓圖片回到清晰的狀態。這種方式讓 Diffusion 模型 能夠學習如何從雜訊中恢復高品質的圖片,最終可以根據提示詞(Prompt)來生成圖像。
💡關於SD(Stable Diffusion)模型:SD模型是一種Diffusion 模型,這是一種深度學習模型,主要用於 圖像生成、修復、風格轉換等任務。它的基本概念是:1. 先將圖片逐步添加隨機雜訊(Forward Process),讓其變成完全無法辨識的雜訊圖。2. 再透過 AI 逐步去除雜訊(Reverse Process),讓圖片回到清晰的狀態。這種方式讓 Diffusion 模型 能夠學習如何從雜訊中恢復高品質的圖片,最終可以根據提示詞(Prompt)來生成圖像。 💡在ComfyUI中最常見的是SD模型,常見的SD模型版本有:SD 1.5, SD 3, SDXL,通常會標注在模型的名稱上,比如說圖中的Juggernaut XL 就是一種SDXL模型。
💡在ComfyUI中最常見的是SD模型,常見的SD模型版本有:SD 1.5, SD 3, SDXL,通常會標注在模型的名稱上,比如說圖中的Juggernaut XL 就是一種SDXL模型。CLIP :
上面在介紹節點的時候就有提過,Clip這個節點是讓使用者輸入提示詞的地方,為了要讓模型能夠更精確地理解人類的意思,除了我們想描述的正向提示詞 **(Positive Prompt)**之外,我們也可以特別註明我們不想要模型生成的特質、東西、類型,也就是:負向提示詞(Negative Prompt)。
 💡通常正向提示詞的clip會用綠色標示、負向則用紅色標示。
💡通常正向提示詞的clip會用綠色標示、負向則用紅色標示。這個節點會將人類的文字轉換成模型能夠理解的形式,再用這些參數來生成最終的圖像。
KSampler:
KSampler 是 ComfyUI 內的一個 核心節點(Node),負責將 Prompt(提示詞)、模型、噪聲數據等資訊組合起來,生成最終的圖像。

Seed:固定的Seed會產生相同的圖片
Control_after_generate :在生成後,隨機(Randomize)、增加(increment)、減少(decrement)、種子值,也有固定(fixed)選項可以生成同張圖像。
步數(Steps):決定去噪的次數,影響細節與品質和生成時間,一般會以20起始,依需求品質增減。
提示詞影響程度(CFG Scale):控制 AI 對提示詞的依從程度,越高越符合提示詞,但會影響畫面自然度,標準會設定在6-9。
採樣器(Sampler):影響風格與細節,依使用的模型調整,各種模型往往會有最佳的設定。
降噪強度(Denoise):用於控制圖生圖的改變幅度,越低越保持原圖細節,越高AI重繪幅度越大。
Latent Image:

Latent Image(潛在圖像) 是 AI 圖像生成過程中的中間數據表示,它不像一般的圖片由 RGB 像素點組成,而是由數學向量(Latent Space Representation) 來表示圖像的特徵。簡單來說,Latent Image 是 AI 理解的「隱藏圖像」,而不是人眼可見的圖片。這是 AI 在生成最終圖像前的一種壓縮表示形式。
在文生圖流程中,這個節點能夠先生成一個空的laten Image,用來決定圖片的尺寸。Batch size則可決定一次生成圖片的數量。
VAE:
VAE(Variational Auto Encoder,變分自動編碼器) 是 Stable Diffusion 和 ComfyUI 中負責圖像壓縮與解碼 的節點。它的主要作用是將圖像轉換為潛在空間(Latent Space),並在 AI 生成後解碼回可見圖像。
Decode - 將 AI 生成的潛在圖像(Latent Image)轉換為可見圖片。
Encode - 將可見圖片轉換成潛在圖像(Latent Image),用在圖生圖的流程中。

Preview Image
轉換過後的圖片會出現在這個節點中。另外有Save Image節點會直接儲存影像。

圖生圖workflow
詳細介紹完節點和工作流之後,我們來實際練習更改工作流:
有時候我們需要使用一張圖片作為生成圖片的參考,這時候我們就會需要一個**圖生圖(image-to-image)**的工作流。這個工作流大部分都和文生圖工作流相同,只需多傳入一張參考圖片到模型中即可。
具體該怎麼做呢?
由於Ksampler只能接受latent Image作為輸入, 所以我們必須要先將傳入的圖片轉換成Latent Image:這時候就用到上面說的VAE Encode這個節點,他能將輸入的圖片轉換成Latent Image後傳入Ksampler。
輸入圖片的流程就如同下圖,是不是很容易?輸入的參考圖片經過VAE編碼後就可以傳入Ksampler中。

將原本輸入圖片尺寸的Empty Latent Image節點替換掉後,就形成的新的圖生圖工作流。新生成的圖片會依照輸入圖片的尺寸生成,調整Denoise數值則可以調整AI重繪的幅度。

接下來我們可以點擊Workflow → Save將做好的工作流命名儲存下來,儲存的工作流會顯示在側邊的工作流欄位(資料夾圖示)中。


之後要重複使用工作流的時候,可以直接點擊叫出。
複雜的工作流都是由這樣一步步慢慢加上控制形成的。接下來會介紹一些實用控制生成圖片的方法。順便學習如何下載使用自訂節點(Custom Node)、模型(Model)。
控制生成圖片
AI生成圖片是一個強大的功能,但要實際應用到室內設計的領域中,就必須盡可能消除生成圖片的隨機性。藉由特殊的Custom Node節點和模型,我們就能夠控制AI生成我們需要的圖片。
常見的控制方式
LoRA(Low-Rank Adaptation) :
是一種輕量AI 訓練方式,需搭配Checkpoint模型使用。加載後能夠特化Checkpoint模型,讓模型能夠精準產出指定的角色、特定物品、風格,而不需要重新訓練整個模型。
- EX:水墨風格、動漫風格、室內設計、商品拍攝圖、電影質感,等等LoRA

ControlNet :
可以讓 AI 根據一張參考圖的**「結構」**來控制生成的新圖
- 指定的形狀、人物姿勢、線稿圖、深度圖 等等

IPAdapter :
可以讓 AI 模仿一張參考圖的風格、顏色、臉部特徵來控制生成的新圖,適合:
讓 AI 生成相似風格的圖(如某個插畫師的畫風)。
根據某張臉生成相似的 AI 角色(但不會完全相同)。
自動匹配顏色與光影,讓 AI 畫出更自然的效果。
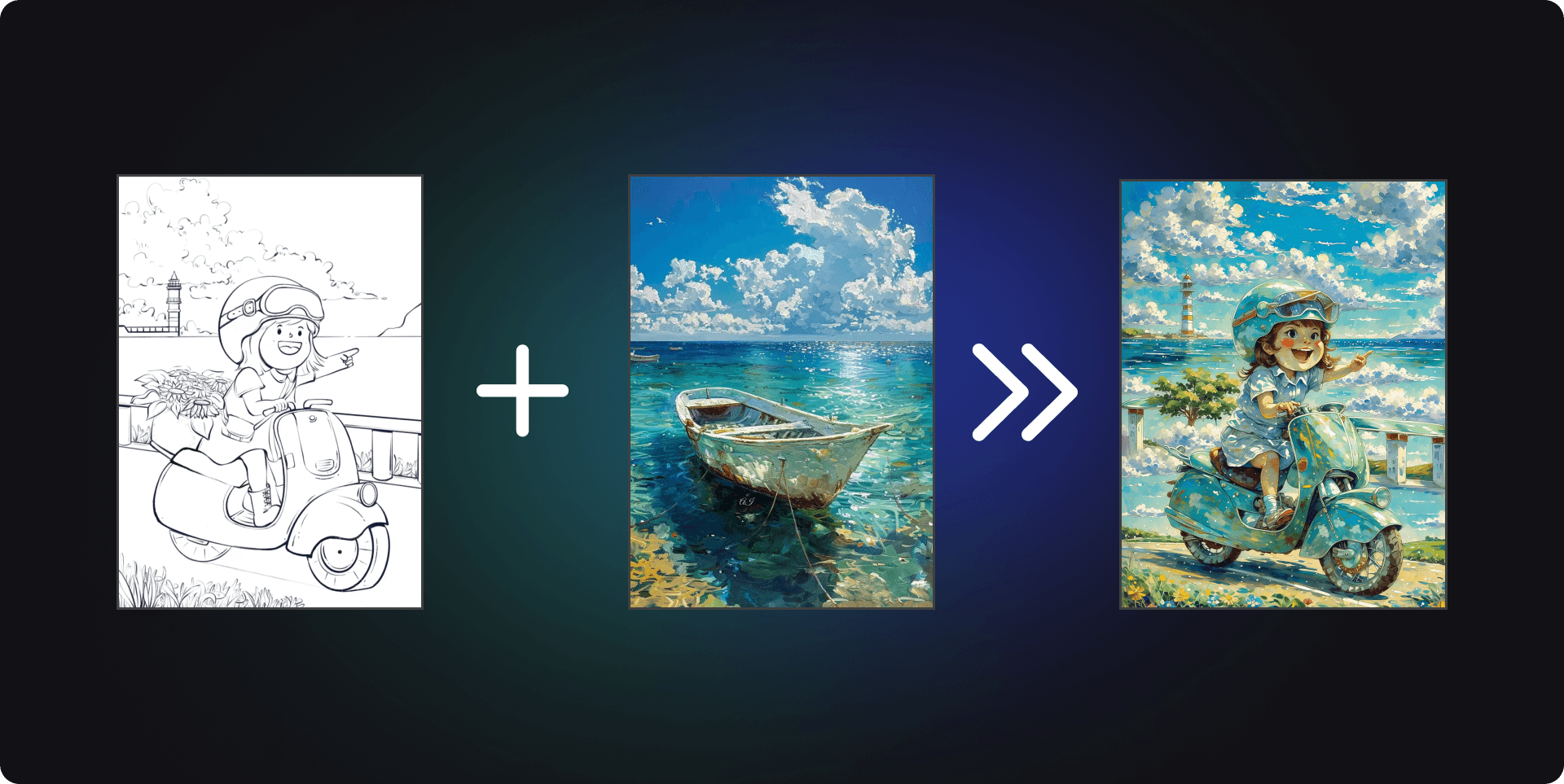
礙於篇幅關係,我們用ControlNet來舉例,剩下的控制,我們可以透過Krita + ComfyUI的插件來實現,當然有興趣的話,讀者可以嘗試自行安裝,每個功能的頁面底下都有詳細的說明。
SDXL 模型下載
在開始使用ControlNet之前,我們先來下載SDXL模型,XL意思代表他能夠生成比SD 1.5更大的圖像。
Civitai
Civitai是一個專門用來分享、下載、交流 Stable Diffusion(SD)相關 AI 模型與資源的開放平台。在這裡,你可以找到各種風格的 Stable Diffusion 模型(Checkpoint)、LoRA(輕量風格微調模型)、ControlNet、Textual Inversion、VAE 等 AI 擴展,是一個AI 藝術家和開發者的交流社群。

直接在搜尋欄搜尋Juggernaut XL,並點擊進去。

這邊我選擇下載 Jugg_X_byRunDiffusion 這個版本,你可以挑你喜歡的版本下載,每個版本有不同的特性,可以閱讀一下說明欄位。

側邊欄有模型的細節,在About this vesion這個欄位中,我們可以看到模型的種類、上傳時間、建議的設定等等資訊,之後使用這個模型的時候就可以依照這些設定去生成模型。
按下載,並將模型儲存到:comfyUI(你的安裝位置)/ models / checkpoints 資料夾中

其餘的模型也是以這樣的方式下載,再放入Checkpoints這個資料夾中就可以使用,在使用模型前可以先看一下建議的參數,來獲得最好的生成品質。
ControlNet 模型下載和安裝
每個不同的生成模型,比如 SDXL, FLUX會有不同的ControlNet,在下載使用前需要注意一下模型版本。
Hugging Face
Hugging Face是一個專門提供 AI、機器學習(ML)與自然語言處理(NLP)工具的開放平台。它不只是 AI 開發者社群,更是 全球最大的 AI 模型庫,讓使用者可以免費下載 AI 模型。我們要下載的Controlnet模型就分享在HugginFace上。
從 https://huggingface.co/xinsir/controlnet-union-sdxl-1.0/tree/main這個網址
下載 diffusion_pytorch_model_promax.safetensors 這個檔案。
注意到這個頁面的sdxl這個名稱了嗎?這就代表這個controlnet模型是sdxl專用的controlnet。

將檔案儲存到: comfyUI(你的安裝位置)/ models / controlnet 裡面,這個資料夾專門在存放你下載下來的controlnet。

到這邊預備動作就做好了,現在可以開始安裝Custom nodes。
使用 ComfyUI Manager 安裝 Custom Node
要使用這些新的功能,我們必須要安裝新的、專門為這些功能製作的自訂節點(Custom Node)。如果是透過桌面版的安裝程式安裝ComfyUI的話,ComfyUI Manager已經預先安裝好了,使用portable版本或者手動下載版本的讀者則需要額外安裝,這邊就不贅述。
點擊右上角的Manager,就可以開啟ComfyUI Manager:

ComfyUI Manager 是一款 專為 ComfyUI 設計的擴展管理工具,可以讓使用者輕鬆安裝、更新、移除各種擴充功能(Custom Nodes),無需手動下載或修改設定檔。
他的功能有:
一鍵安裝擴充插件(Custom Nodes)。
自動更新擴充功能,確保最新版本。
簡單管理所有安裝的插件,避免衝突。
我們點擊中間上方的Custom Node Manager:

進到這個頁面後,我們直接搜尋並且安裝以下三個Custom Nodes:
ComfyUI ArtVenture
Comfyui_controlnet_aux
Comfyroll Studio

安裝完三個custom nodes 之後, 我們再按下Restart,重新啟動ComfyUI來完成安裝。
ControlNet 工作流
ControlNet主要目的是讓 AI 生成圖片時可以「遵循特定的圖像結構」,而不是只靠文字提示詞(Prompt)。至於哪種controlNet提供怎麼樣的控制效果,可以參考這個表格:
| 控制類型 | 作用 | 應用場景 |
| Pose Control(OpenPose) | 控制人體姿勢 | 生成與參考照片相同動作的角色 |
| Canny Edge(邊緣線) | 控制輪廓結構 | 讓 AI 照著手繪線稿生成圖片 |
| Depth Map(深度圖) | 保持場景的立體感 | 讓 AI 生成與參考圖片相同視角的場景 |
| Scribble(塗鴉) | 依據簡單手繪創作 | 快速畫出大概構圖,讓 AI 自動填充細節 |
| MLSD(直線檢測) | 保持建築結構 | 適合繪製建築、機械場景 |
我們先來看controlNet的工作流:

相較於圖生圖的工作流,Controlnet多了以下幾個節點。
Load ControlNet Model - 可以加載ControlNet模型,這邊選擇我們剛下載好的模型
ControlNet Preprocessor - 參考上方表格,選擇控制的方式
Apply ControlNet - 連接各ControlNet節點到工作流中
要新增節點,請滑鼠左鍵連點空白處,可以叫出搜索欄:

剩下來的就是簡單的連連看,將同名、同顏色的輸出連到輸入

連接Checkpoint模型的VAE,連接正負向提示詞、連結control_net、連接IMAGE

將Apply ControlNet的輸出連結到Ksampler,就完成工作流的編輯。

Ksampler 的 latent Image 輸入要傳入空白的 Latent Image或者參考圖都可隨意調整
但要記得denoise的程度會影響原圖的控制力度,可以多嘗試幾次,看看不同的參數會對整個工作流造成什麼影響。

我們通過控制,將魔法瓶生成出了房屋的形狀,這個就是controlnet的控制效果。ComfyUI的有趣之處就在於,只要符合基本的遊戲規則,就有無限的可能性 。

關於控制圖片生成就說明到這邊,其餘像IPadapter其實也是很有趣的控制手段,有興趣的朋友可以去找其他的教程或者自行研究github、hugginface頁面上的說明。
結語
在這篇文章中,我們入門了ComfyUI的節點、工作流、自訂節點、並使用了進階的控制手段,相信經過這個教程,有了一點基礎之後,讀者就可以自行去探索ComfyUI的各種有趣應用。接下來我們就可以連結ComfyUI到繪圖軟體Krita上去做實際的應用了。
點擊這個連結:https://tw.reroom.ai/ 或者直接搜尋ReRoom AI就可以找到我們。
也歡迎追蹤我們的Threads,我們會將最新的功能和使用心得放到上面,分享一些有趣的使用經驗。
之後的教學文章將會很快更新,歡迎訂閱我們的部落格。
Subscribe to my newsletter
Read articles from Wayne Huang directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by