FTP automated/scheduled file downloads using AWS Batch/EventBridge
 Pradeep AB
Pradeep AB
Introduction
It is a common use case whereby organizations set up FTP servers for external parties to access. Typically, the users which have access to this would download files from these servers on demand using some kind of FTP client such as WinSCP or FileZilla. This can be a very manual and tedious task whereby all that is required is for these files to exist on your own desired file store. On top of this, file transfers can take a long time for many/large files.
In this blog post, I will go through how you can set up a mechanism using AWS Batch and Eventbridge which would download files automatically from an FTP server, on a set schedule, and store them into S3. We also utilize the paramiko python implementation to interface with the FTP server
AWS Batch
The solution
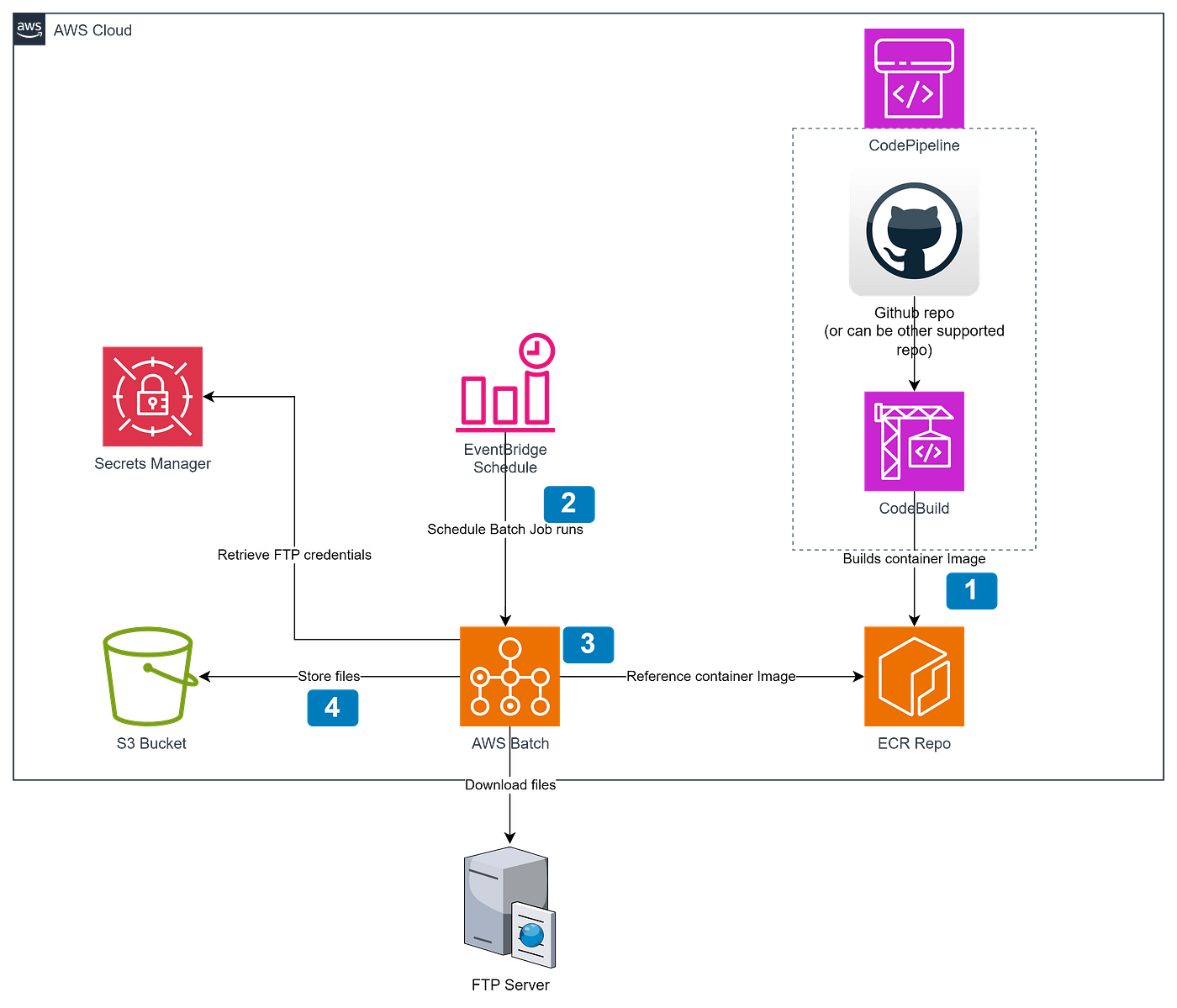
What we are building
The above outlines the solution we are building
We have a CodePipeline pipeline that uses a Github repo (or similar) as a pipeline source which triggers the pipeline to start on a git push. This then triggers a CodeBuild step which contains steps to build a container image (uses Docker in the code provided below) to ECR. There is a Python (.py) file built into this image which contains the code to download files and store them
An EventBridge rule runs on a schedule that triggers a Batch job e.g. can set it to run daily if files are expected to be in sync by the day
The Batch job runs and references the built image in ECR to run the python file which retrieves the FTP credentials from Secrets Manager and uses these credentials to download the files from the FTP Server. AWS Batch is used instead of something like Lambda as there is no timeout which can easily be reached if there are many/large files
These files are then stored to an S3 bucket partitioned by
{year}/{month}/{day}/{filename}to be consumed at will
Step-by-step
We will now go through the steps to build this solution in your own environment
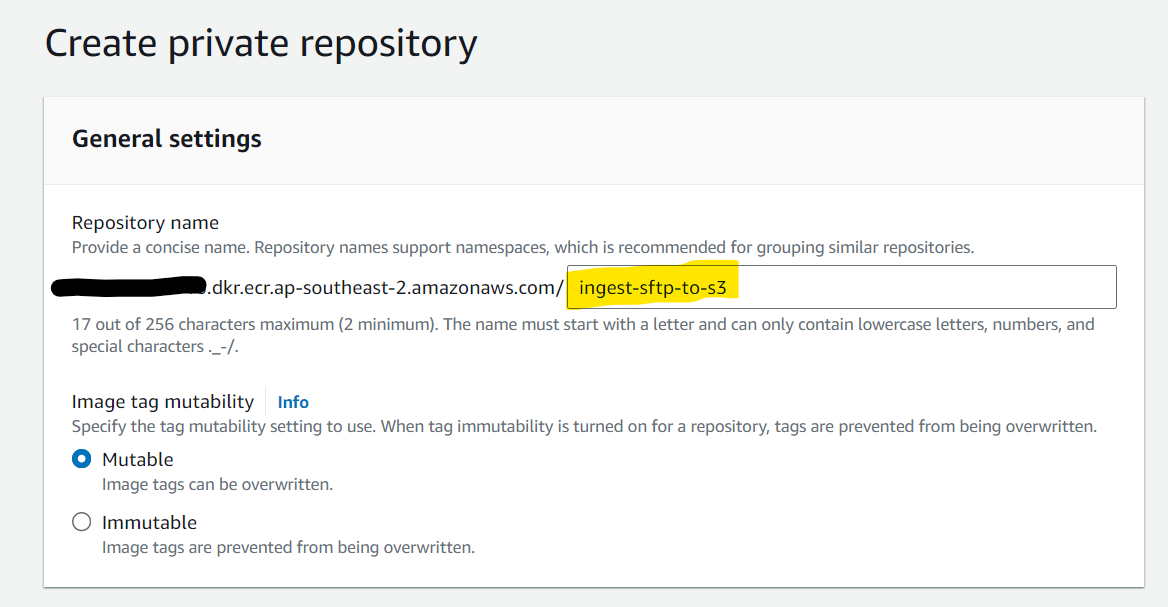
- Create a private ECR repository for storing image builds which we will later reference in our code and take note of its name e.g.
ingest-sftp-to-s3
2. Clone/fork the code @ https://github.com/devsecopsulting/aws-sftp-automation which contains the Dockerfile for building the image along with a script for the build commands and finally the python code for downloading and storing files to s3 ingest-sftp-to-s3.py . Store this in your own git repo of choice that CodePipeline supports (Github/Gitlab/Bitbucket). Update the build.sh file with the correct account number/region/ECR repo name of the ECR repo created in the first step
accountNo=123456789012 # enter account number to use here
region=ap-southeast-2 # enter region of ecr repo created
ecrRepoName=ingest-sftp-to-s3 # enter name of ecr repo created
3. Create a CodePipeline resource and reference the code repo from the previous step in the ‘Source’ step. Add a CodeBuild step to create a new CodeBuild project and use the following for the ‘Build commands’. Use ‘New service role’ and create the codebuild project and continue to CodePipeline
version: 0.2
phases:
build:
commands:
- chmod +x build.sh
- ./build.sh
4. Create the CodePipeline resource and go to the created CodeBuild project to find the referenced IAM role. We want to add some extra permissions here to allow the build.sh file to push images to the ECR repo created in the first step. Add the following permissions to the role either in a new policy or inline policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowPushImagesToECR",
"Effect": "Allow",
"Action": [
"ecr:CompleteLayerUpload",
"ecr:GetAuthorizationToken",
"ecr:UploadLayerPart",
"ecr:InitiateLayerUpload",
"ecr:BatchCheckLayerAvailability",
"ecr:PutImage"
],
"Resource": "*"
}
]
}
5. Click ‘Release Change’ on the CodePipeline which should now look something like the below and check the ECR repo for a built image
CodePipeline
ECR Repo
6. Now create an S3 Bucket where the files will be stored and take note of its name
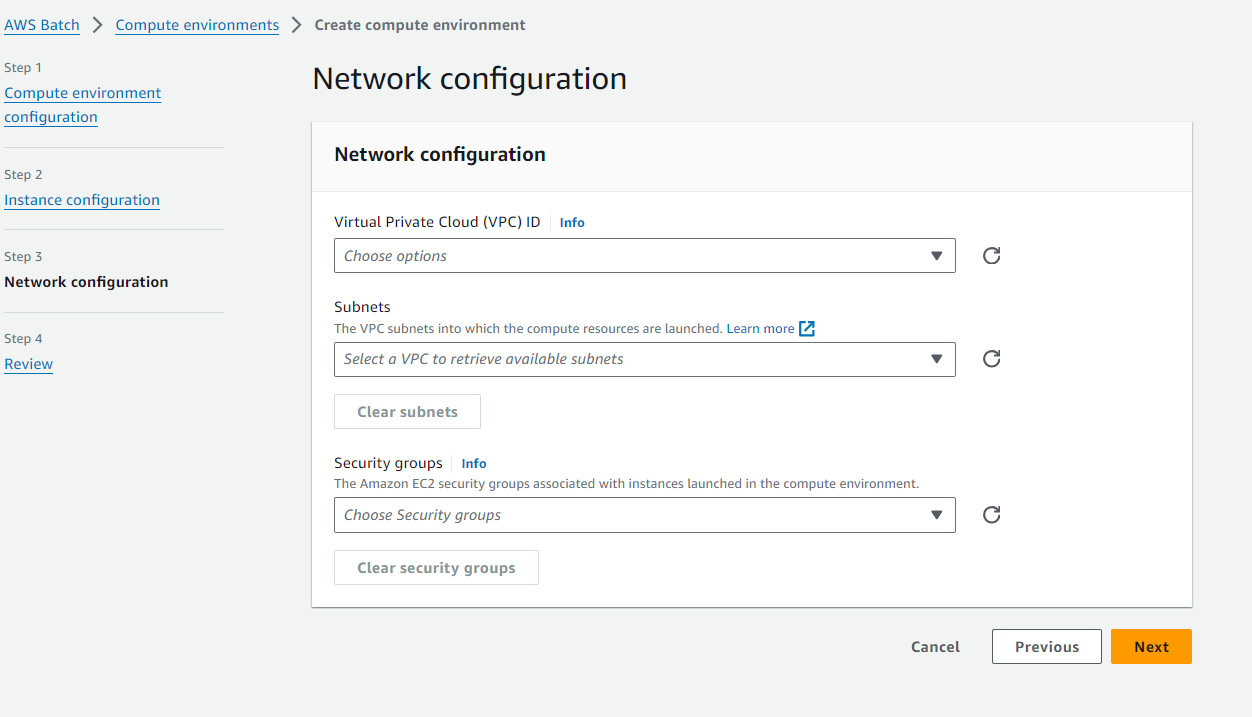
7. Now we will create the Batch Compute Environment under
AWS Batch->Compute environments. For this you can make this to your liking e.g. Fargate compute time with 2vCPU but the main thing is to make sure it is in subnets that will have internet access and an appropriate Security Group with outbound rules for the FTP server. Create a Job queue that references this computer environment
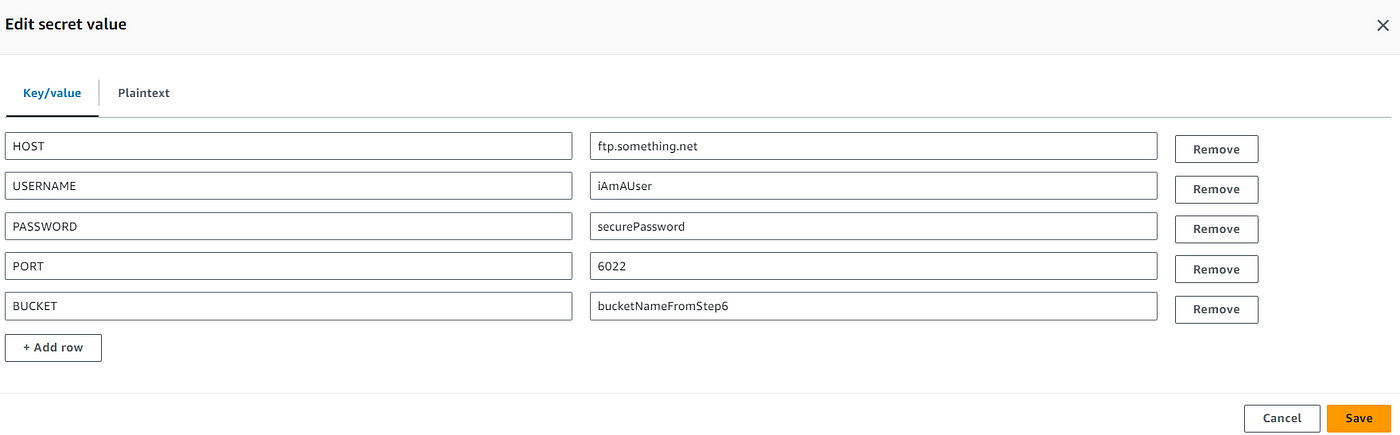
8. Create a Secrets Manager secret called sftp-secret and enter in the keys and values for HOST USERNAME PASSWORD PORT BUCKET (bucket name from step 6). The first 4 keys are the FTP details
9. Create the role for the Batch Job Definition. You can refer to the doc here for this and in addition to this it should have the s3:PutObject action on the bucket from step 6 and the secretsmanager:GetSecretValue action on the secret from the previous step
10. Now create the batch job definition in AWS Batch > Job definitions. Make sure you set:
Execution timeout — maximum number of seconds the job should time
Runtime platform — Linux
Execution role — choose role from previous step
Image — {accountNo}.dkr.ecr.{region}.amazonaws.com/{ecrRepoName}:latest
Container configuration command should be:
["python","/ingest/ingest-sftp-to-s3.py"]
This will run the python file built into the container image
11. Now create an EventBridge schedule on a desired schedule that selects the batch job queue, definition and a role that allows the batch:SubmitJob action on the ARNS of the job queue and definition on the previous steps with a trust relationship of
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowEventsServiceStatement",
"Effect": "Allow",
"Principal": {
"Service": "events.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
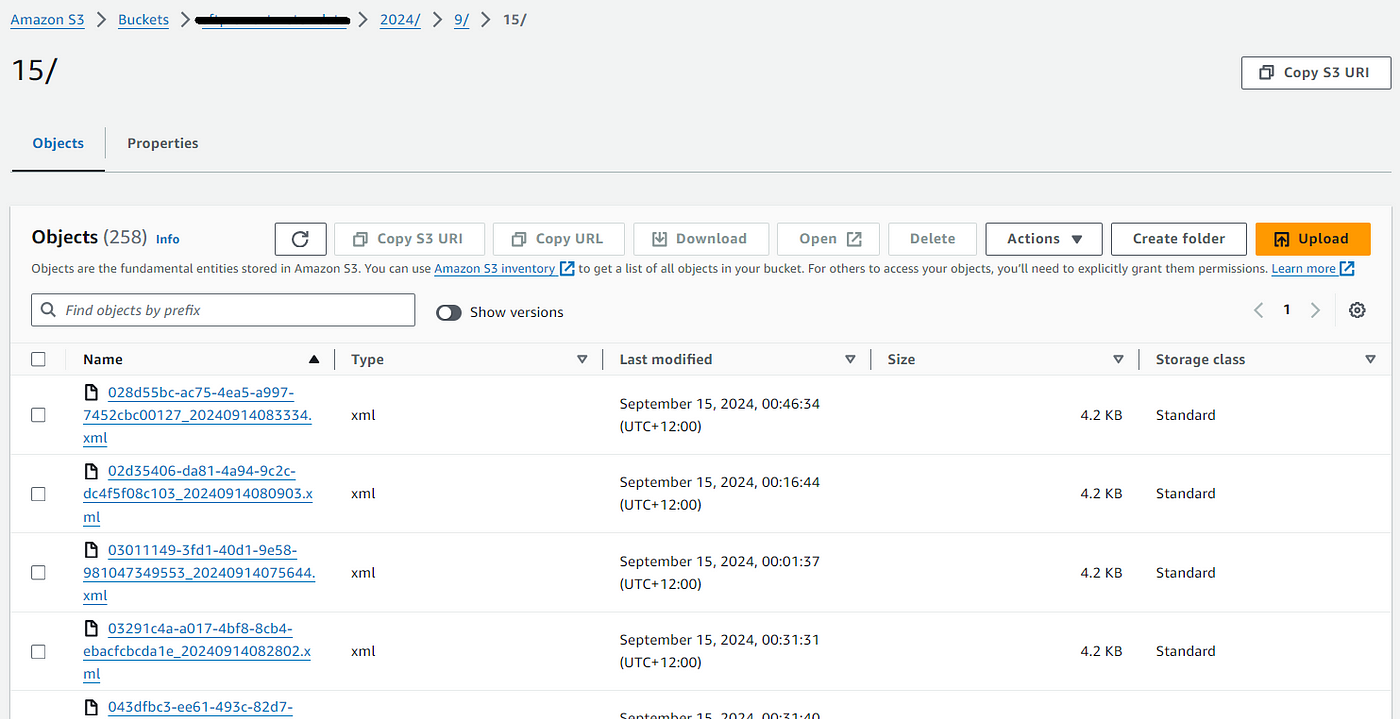
12. After the EventBridge schedule runs you should see the files come through to your bucket in the format year/month/date/filename as shown in the below example for 2024/9/15
Conclusion
We have an effective and simple solution for automated and scheduled file downloads/storage from FTP. This has been achieved by using the following:
CodePipeline — any changes to code will be built into the latest ECR image to be referenced by the Batch Job definition
AWS Batch — long running jobs for large and numerous file downloads
S3 Bucket — for effective object file storage
Secrets Manager — to store the FTP server credentials securely
EventBridge — schedule batch runs for file downloads at your desired frequency
Subscribe to my newsletter
Read articles from Pradeep AB directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pradeep AB
Pradeep AB
Passionate Cloud Engineer | AWS Certified Solutions Architect | Multi-Cloud Expertise in AWS, Azure, GCP & Oracle | DevSecOps Enthusiast | Proficient in Linux, Docker, Kubernetes, Terraform, ArgoCD & Jenkins | Building Scalable & Secure CI/CD Pipelines | Automating the Future with Python & Github