API Integration Patterns
 Tuan Tran Van
Tuan Tran Van
API stands for Application Programming Interface. The “I“ in the API is the key part that explains its purpose.
The interface is what the software presents to other humans or programs, allowing them to interact with it.
A good analogy for an interface is a remote control. Imagine you have a universal remote that controls your TV, lights, and fans.

Let’s break down what a universal remote control can do:
The remote control has various buttons, each serving a different purpose. One button might change the channel, while another can dim the light of the chandelier, and another can turn on the fan.
When you press a button, it sends a specific signal via infrared, Bluetooth, or wifi to the object you are controlling, instructing it to perform a particular action.
The key feature of the remote is that it allows you to interact with the TV, chandelier, and fan without understanding their internal workings. All that complexity is abstracted away. You simply press a button, and you get a response that you can observe immediately.
APIs work in the similar way.
APIs can have various endpoints, each designed to perform a specific action. For example, one endpoint might retrieve data while another updates or deletes it.
When you send a request to an endpoint, it communicates with the server using HTTP methods—GET, POST, PUT, and DELETE—to instruct it to perform a particular action(such as retrieving, sending, updating, or deleting data).
The key thing about APIs, as with remote controls, is that APIs abstract away the inner workings of the server or the database behind the API. The API allows users, developers, and applications to interact with a software application or perform without needing to understand its internal code or database structure. You simply send a request, and the server processes it and provides a response.
The analogy holds true as long as APIs are more complex than a remote control. However, the basic principle of operation of an API and a universal remote is quite similar.
This article will explain API integration patterns, which can be divided into two categories: Request-Response (SOAP, REST, RPC, and GraphQL) and event-driven APIs (Pooling, WebSockets, and WebHooks).
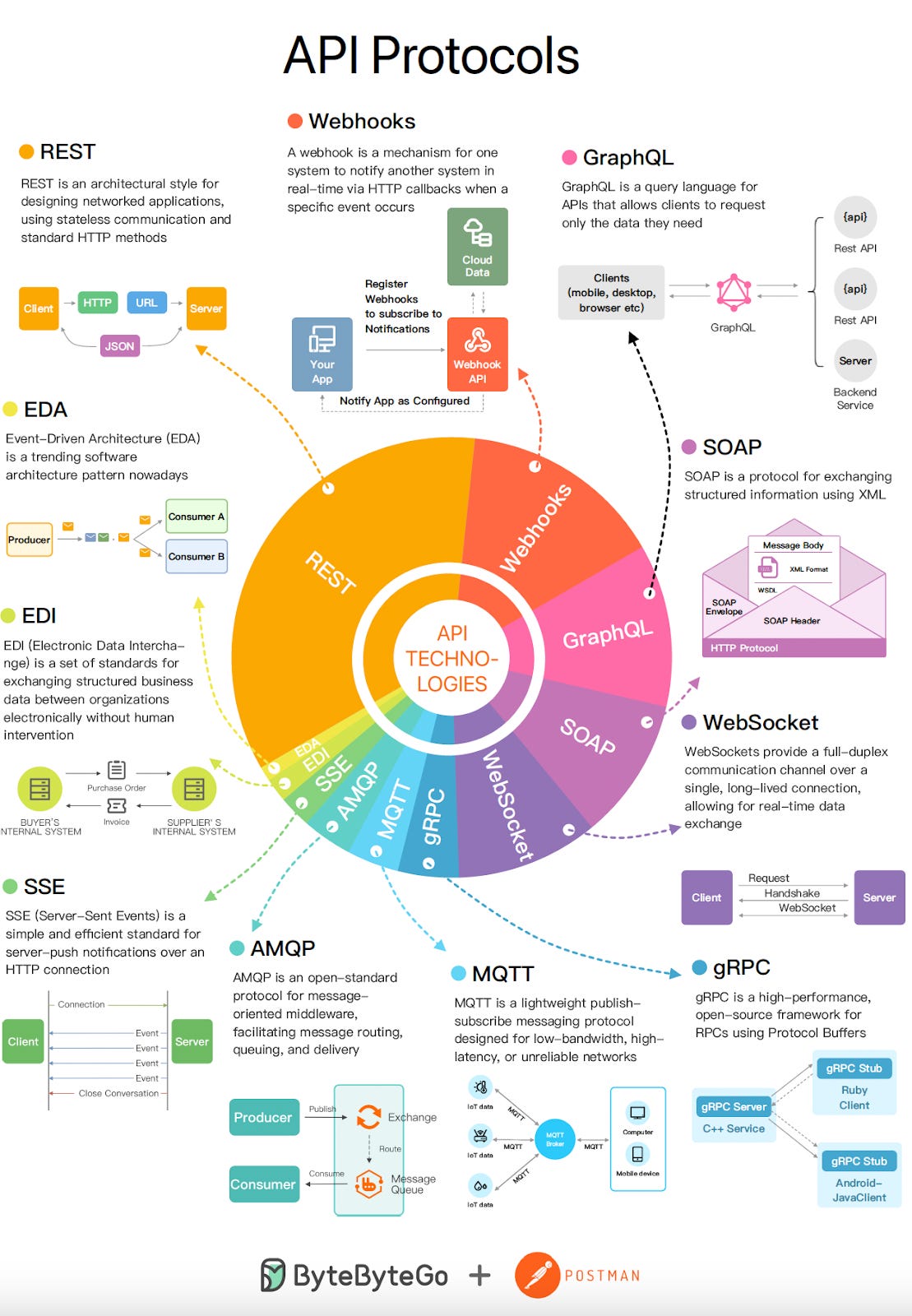
Request-Response Integration
In a request-response integration, the client initiates the action by sending a request to the server and then waits for the response.
Different patterns of request-response integration exist, but at a high level, they all conform to the same rule of the client initiating a request and waiting for a response from the server.

RPC
RPC stands for Remote Procedure Call. Unlike REST APIs, which are all about resources, RPC is all about actions. With RPC, the client executes a block of code on the client.
Think of a restaurant without a menu. There is no dish you can request in this restaurant. Instead, you request a specific action to be performed by the restaurant.

With a REST API, the guest would have simply asked for some fish and chips. With RPC, they have to give instructions on what they want the kitchen to prepare.
In the RPC pattern, the client calls a specific procedure on the server and waits for the result. The procedure to prepare and what gets prepared are tightly bound together. This might give the client very specific and tailored results, but it lacks the flexibility and ease of use of REST.
Most restaurants use menus instead of following their customers' custom requests. This partly explains why RPC is a less popular integration pattern than REST.
SOAP
Simple Object Access Protocol (SOAP) is a messaging protocol used for exchanging structured data between different systems over the Internet. SOAP is an XML-based protocol and is considered one of the earliest web service protocols. SOAP was first introduced in 1998 by Microsoft as a successor to Common Object Request Broker Architecture (CORBA) and Distributed Component Object Model (DCOM). SOAP was designed to provide a platform-independent way to exchange data between different systems over the Internet. SOAP was later standardized by the World Wide Web Consortium (W3C) in 2003.
SOAP APIs were widely used in the early days of web services and are still used in several industries and sectors today, although REST and GraphQL have become more popular in recent years. SOAP might be the most beneficial option for developing an API when sensitive data needs to be transmitted, complex data structures need to be supported, or a reliable and standardized protocol is needed.
SOAP APIs use XML as the main format for data transmission. XML stands for Extensible Markup Language. It’s a markup language that allows users to create custom tags and attributes to describe the structure and content of data. XML uses a set of rules for encoding documents in a format that is both human-readable and machine-readable. This is achieved by using tags to define elements of a document, similar to HTML.
For example, an XML document may have a tag called <person> to define an element representing a person, with nested tags for properties such as <name>, <age>, and <address>. XML also allows users to define custom tags to describe their data in a way that is specific to their needs. XML is widely used in various industries, including finance, healthcare, and government. It is often used for data exchange between different applications and systems, as it provides a standardized way of representing data that can be easily parsed by computers. XML is also used to store configuration files and metadata for various applications.
Overall, XML provides a flexible and extensible way of describing and exchanging data that computers can easily process. However, its use has declined in recent years due to the rise of more modern formats such as JSON and YAML, which are lighter and easier to use for many applications.
Here is an example of how you can make a simple request to a SOAP API from a JavaScript front-end application:
// specify the URL of the SOAP API endpoint
const url = 'http://www.example.com/soap-api';
// specify the SOAP message to send
const soapMessage = '<?xml version="1.0" encoding="UTF-8"?>' +
'<SOAP-ENV:Envelope xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/" xmlns:ns1="http://example.com">' +
'<SOAP-ENV:Header/>' +
'<SOAP-ENV:Body>' +
'<ns1:GetData>' +
'<ns1:Id>123</ns1:Id>' +
'</ns1:GetData>' +
'</SOAP-ENV:Body>' +
'</SOAP-ENV:Envelope>';
// set the content type of the SOAP message
const contentType = 'text/xml';
// make the fetch request
fetch(url, {
method: 'POST', // SOAP uses the HTTP POST method to send requests to a server.
headers: {
'Content-Type': contentType,
'SOAPAction': 'http://example.com/GetData'
},
body: soapMessage
})
.then(response => response.text())
.then(xml => {
// handle the XML response
const parser = new DOMParser();
const xmlDoc = parser.parseFromString(xml, 'text/xml');
const value = xmlDoc.getElementsByTagName('Value')[0].childNodes[0].nodeValue;
console.log(value);
})
.catch(error => console.error(error));
A typical response might look like this:
<?xml version="1.0" encoding="UTF-8"?>
<SOAP-ENV:Envelope xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/">
<SOAP-ENV:Body>
<ns1:GetDataResponse xmlns:ns1="http://example.com">
<ns1:Result>
<ns1:Id>123</ns1:Id>
<ns1:Value>42</ns1:Value>
</ns1:Result>
</ns1:GetDataResponse>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
The following code extracts the value of the Value element from the XML document object:
const parser = new DOMParser();
const xmlDoc = parser.parseFromString(xml, 'text/xml');
const value = xmlDoc.getElementsByTagName('Value')[0].childNodes[0].nodeValue;
console.log(value); // output: 42
Overall, SOAP responses tend to be more verbose and complex than responses from RESTs and GraphQL APIs due to their use of XML and the envelope format. However, this format provides a standardized way of exchanging information that can be useful in certain industries or use cases.
REST
REST (Representational State Transfer) is not a framework or library but an architectural style for building web services or APIs. In REST, everything is a resource identified by a unique URL, and these resources are manipulated using HTTP methods such as GET (to retrieve the resource), POST (to create a new resource), PUT or PATCH (to update a resource), and DELETE (to remove a resource).
To understand REST APIs, consider the following analogy. Imagine you go to a restaurant and order some food. The menu is extensive, and items are categorically organised. Each item on the menu can be equated to a resource.
First, you call a waiter to get attention, then you place an order. Each request receives a response before you can proceed with another request, like ordering a dish.

In REST API terms, the client initiates requests to the server by specifying exactly what it wants using HTTP methods such as GET, POST, PUT, and DELETE on specific URLs (the menu items). Each interaction is stateless, meaning that each request from the client to the server must contain all the information needed to understand and process the request. The server does not store client contexts between requests, simplifying design and improving scalability. The client and server’s HTTP request and response bodies carry JSON and XML representations of a resource’s status.
Benefits of REST APIs:
Simplicity: Using standard HTTP methods and common data formats makes REST APIs easy to understand and implement.
Interoperability: REST APIs promote interoperability, as different applications can interact seamlessly regardless of the programming language or platforms used.
Scalability: The stateless nature of REST APIs allows for easy scaling to handle large columns and requests.
Flexibility: REST APIs can be updated to various use cases due to their versatile design principles.
Drawbacks of REST APIs
Statelessness: REST relies on stateless transactions, meaning each request must complete all the information independently. This can be cumbersome for workflows that require maintaining state across multiple requests, like shopping carts on e-commerce sites.
Limited payload size: Data Transfer in REST often happens through JSON or XML payloads, which can become quite large if you are dealing with complex data or many queries. This can lead to performance issues.
Lack of discoverability: REST APIs don’t inherently make it easy for users to understand the functionality or how to interact with them, which can add complexity for new users.
Performance for complex queries: REST might not be ideal for retrieving specific data points from a large source. Other options, like GraphQL, can be more efficient in such cases.
REST defines six architectural constraints an API should follow to be considered genuinely RESTful:
Client-Server: This separation of concerns separates the client (the application using the API) from the server (the application providing the API). The client initiates requests, and the server processes them and sends the response.
Stateless: Each request from the client to the server must contain all the information necessary to understand the request. The server doesn’t store any context about the client between requests. This simplifies communication and improves scalability.
Uniform interface: This constraint defines a set of rules for how clients interact with the server. These rules include:
Resource-based: APIs expose resources that clients can interact with. URLs identify resources.
Standard Methods: Clients use standard HTTP methods (GET, POST, PUT, DELETE) to perform operations on resources.
Representation: Data is exchanged between client and server in a standard format like JSON or XML.
Cacheable: The client may mark the server responses as cacheable. This allows clients to store frequently accessed data locally, reducing server loads and improving performance.
Layered System: The architecture may consist of multiple layers (proxies, caches, load balancers) between the client and server. These layers can improve performance, security, and scalability.
Code on Demand (Optional): While not strictly mandatory, a RESTful API may optionally transfer executable code to the client. Clients can use this code to extend its functionality or process data locally.

An example of a REST API call for the API on the https://api.example.com address when you want to get the information about the user ID 500 is the following, using the curl command-line tool curl -X GET https://api.example.com/users/500 -H "Accept: application/json . The last part (Accept: application/json) is a header that indicates that the client expects to receive the data in JSON format. A response would be a result in the JSON format, and 200 would be the response status code.

Even though REST is not the best choice when performances are essential, we can do a few things here, such as caching, pagination, payload compression, and more.
GraphQL
GraphQL is a query language for APIs released and open-sourced in 2015 by Meta. The GraphQL Foundation now oversees it. GraphQL is a server-side runtime environment that enables clients to request the data they need from an API. Unlike traditional REST APIs, which often require multiple requests to get different pieces of data, GraphQL allows you to specify all the data you need in a single request. The GraphQL specification was open-sourced in 2015.
Think of a restaurant that allows you to customize your own dish by specifying exact quantities or ingredients you want.

This may look similar to the RPC pattern, but notice that the customer is not saying how the food should be made; they are just customizing their order by removing some ingredients (no salt) and reducing the number of some items (two pieces of fish instead of four)
Because GraphQL doesn't over- or under-fetch results when queries are sent to your API, it guarantees that the app built with GraphQL is scalable, fast, and stable. It also allows for combining multiple operations into a single HTTP request.
GraphQL APIs are organized in terms of type and field, not endpoints. Using the GraphQL Schema Definition Language (SDL), you define your data as a schema. This schema serves as a contract between the client and the server, detailing precisely what queries can be made, what types of data can be fetched, and what the response will look like.
Benefits of GraphQL:
Efficient data fetching: You only request the exact data you need, eliminating the issue of over-fetching and under-fetching that can happen with REST. This can significantly improve performance, especially for complex data models.
Flexible and Declarative: GraphQL uses a schema that defines the available data and how to access it. This schema allows developers to write clear and concise queries that specify their exact data needs.
Single request for multiple resources: Unlike REST, which requires multiple API calls to fetch data from different endpoints, GraphQL allows combining queries into a single request for improved efficiency.
Versioning and Backward Compatibility: GraphQL schema changes can be improved with versioning, ensuring existing clients aren’t affected while allowing for future growth.
Drawbacks of GraphQL:
Complexity in query structure: While flexibility is a strength, writing complex GraphQL queries can be challenging and requires careful planning for readability and maintainability.
Caching: Caching data with GraphQL is generally more complex than REST APIs, which leverage built-in HTTP cache mechanisms.
Security: GraphQL exposes your entire data schema, so proper security measures are crucial to prevent unauthorized access to sensitive data.
Learning Curve: For developers unfamiliar with GraphQL, understanding schema and query syntax involves a learning curve.
Error Handling: If the library doesn’t parse errors with a status of 200 in the response body, the client must use more intricate logic to handle them.
How it works:
The client defines a query in GraphQL syntax, specifying exactly how the data should be structured and what fields are needed.
The GraphQL server uses a predefined schema to determine the available data and its relationship to other data. This schema defines types, fields, and the relationships between types.
The server executes the query against the schema. For each field in the query, the server has a corresponding resolver function that fetches the data for that field.
The server returns a JSON object where the shape directly mirrors the query, populated with the requested data.

GraphQL supports three core operations that define how the client interacts with the server:
Queries: Used to retrieve data from the server. This is the most common operation used in GraphQL.
Mutations modify data on the server. This could involve creating new data, updating existing data, or deleting data.
Subscriptions are used to establish real-time communication between the client and the server. The server can then update the client whenever the requested data changes.
An example of a GraphQL request consists of an operation and the data you are requesting and manipulating.

This query retrieves data for a user with ID 1. It also fetches nested data for the user’s posts, including their IDs and titles.
The response is a JSON object containing actual data requested by the query or mutation or optional errors.

So, when to choose each of those protocols:
✅ Use REST when you are building a CRUD-style web application or when you work with well-structured data. It’s a go-to for public APIs and services that need to be consumed by a broad range of clients.
✅ Use gRPC if your API is private about actions or if performance is essential. Low latency is critical for server-to-server communication. Its use of HTTP/2 and ProtoBuf optimizes efficiency and speed.
✅ Use GraphQL if you have a public API that needs to be flexible in customizing requests and you want to add data from different sources into a public API. Use it in client-server communication, while we must get all the data on a single round trip.

Event-Driven Integration
This integration pattern is ideal for services with fast-changing data.
Some of these integration patterns are also asynchronous and initiated by the server, unlike the request-response patterns, which are synchronous and initiated by the client.
Polling
Let’s use the restaurant analogy again. When you order food, it takes some time for it to be prepared.
Asking the waiter if your order is ready can update you on its status. The more frequently you ask, the closer you will be to having real-time information about your order.
However, this puts unnecessary strain on the waiters, who have to constantly check the status of your order and update you whenever you ask.

Polling is when the client continuously asks the server if there is new data available with a set frequency. It’s not efficient because many requests may return no new data, thus unnecessarily consuming resources.
The more frequently you poll (make requests), the closer the client gets to real-time communication with the server.

Most of the requests during the polling are wasted since they only return something useful to the client once there is a change on the server.
There is, however, another version of polling called long polling. With long polling, the waiter doesn’t respond to the guest straightaway about the status of the order. Instead, the waiter only responds if there is an update.
Naturally, this only works if the guest and the waiter agree beforehand that a slow response from the waiter doesn’t mean that the waiter is being rude and the guest is being ignored.

With long polling, the server does not respond to the client immediately. It waits until something has changed before responding.
As long as the server and the client agree that the server will hold on to the client’s requests and the connection between the client and the server remains open, this pattern works and can be more efficient than simply polling.
These two assumptions for long polling may be unrealistic, though - the server can lose the client’s requests and/or the connection can be broken.
To address these limitations, long polling adds extra complexity to the process by requiring a directory of the server that contains the connection to the client, which is used to send data to the client whenever the server is ready.
Standard polling, on the other hand, can remain stateless, making it more fault-tolerant and scalable.
WebSockets
WebSockets provide a persistent, two-way communication channel between the client and server. Once a WebSocket connection is established, both parties can communicate freely, which enables real-time data flows and is more resource-efficient than polling.
Using the restaurant analogy again, a guest orders a meal and then establishes a dedicated communication channel with the waiter so they can freely communicate back and forth about updates and changes to the order until the meal is ready. This means the waiter can also initiate the communication with the guest, which is not the case for the other integration patterns mentioned so far.

WebSockets are similar to long polling. They both avoid the wasteful requests of polling, but WebSockets have the added benefit of having a persistent connection between the client and the server.
WebSockets are ideal for fast, live streaming data, like real-time chat applications. The downside of WebSockets is that the persistent connection consumes bandwidth, so it might not be ideal for mobile applications or in areas with poor connectivity.
WebHooks
WebHooks allow the server to notify the client when new data is available. The client registers a callback URL to the server, and the server sends a message to that URL when there is data to send.
With WebHooks, the client sends requests as usual but can also listen and receive requests like a server.

Using the restaurant analogy, when the guest orders the meal, they give the waiter a bell (analogous to the callback URL). The waiter goes to the kitchen and rings the bell as soon as the meal is ready. That allows the client to know, in real time, about the progress of his order.
WebHooks are superior to polling because you get real-time updates from the server once something changes, without having to make frequent, wasteful requests to the server about that change.
They are also superior to long polling because long polling can consume more client and server resources as it involves keeping connections open, potentially resulting in many open connections.
Conclusion
APIs are crucial tools in software development, allowing users and applications to interact with software without understanding its inner workings.
They come in different integration patterns, such as REST, RPC, GraphQL, Polling, WebSockets, and WebHooks.
If you need a simple request-response integration, then REST, RPC, or GraphQL could be ideal. For real-time or near-real-time applications, polling, WebSockets, or WebHooks are ideal.
As with any design problem, the right choice depends on the business case and what tradeoffs you are willing to tolerate.
References
https://www.freecodecamp.org/news/api-integration-patterns/
https://medium.com/@techworldwithmilan/when-to-use-graphql-grpc-and-rest-9d541c0bcfe0
https://blog.bytebytego.com/p/a-crash-course-in-graphql?utm_source=substack&utm_medium=email
Subscribe to my newsletter
Read articles from Tuan Tran Van directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Tuan Tran Van
Tuan Tran Van
I am a developer creating open-source projects and writing about web development, side projects, and productivity.