The ultimate guide to building scalable, reliable web scraping, monitoring, and automation apps
 Kamil Kowalczyk
Kamil Kowalczyk
Whether you’re a business owner, marketer, or software developer, there’s a good chance you’ve worked with a web automation tool at some point. Everyone wants to work smarter, spend less time on repetitive tasks, and use more efficient, innovative solutions. Standing out from the competition with custom, smart approaches often determines whether your business or project will succeed.
The goal of web automation is simple: you want to save time and gather useful, unique data. These are undoubtedly some of the most important factors for any business today. However, automating your desired process can be challenging and may lead to a lot of frustration. With so many tools to choose from, it can be difficult to decide where to start or which solution is best to ensure successful implementation.
Broadly speaking, there are two ways to approach automation:
No-code/low-code tools: For instance, using Zapier to quickly build automated workflows without writing much code. This can be great for smaller projects or rapid prototypes.
Bespoke solutions: Building a custom automation tool that can handle complex processes, integrate with your existing systems, and scale to meet your demands.
In this article, we’ll focus on how to build a reliable, bespoke automation tool that won’t fail at the first sign of trouble — especially when it comes to handling the complexities of the modern web. I’ve gone through this process firsthand while overseeing development at monity.ai, and I hope these insights will save you time and help you build a great tool.
Plan your app: outline and define your goals
Before you start coding, it’s crucial to define exactly what you want to achieve with your automation or web scraping project. Ask yourself:
Do you need to scrape websites to collect important data (e.g., pricing, product availability, content)?
Do you want to automate specific tasks that you’d otherwise perform manually (e.g., form submissions, data entry)?
Do you want to monitor website changes for compliance, content updates, or competitor analysis?
Having a clear goal helps you determine the scope of your application and what level of management or control you need. For the simplest scenario, you could start with a Google spreadsheet that contains URLs and columns for the scraped data. However, for larger projects, you may need a dedicated user interface for adding and managing automations, viewing logs, handling errors, and storing collected output.
The best tool to start with is probably Figma, but you can speed up your project by using AI to generate wireframes or even full designs. You can explore AI-powered features built into Figma or try other fantastic tools like Uizard.io or UXPilot.ai. Having some form of outline or UI concept is absolutely essential if you’re building a more complex solution.
Choose your tech stack wisely
Choosing the right tools for the right task can help you build a more robust app, save you tons of time, and minimize maintenance overhead. This is an exciting time for developers, but ultimately, the choice depends on you or your team’s expertise and knowledge.
I always recommend using the tools and programming languages you’re most comfortable with (assuming you have that freedom). At monity.ai, our team primarily uses Node.js (our favorite for backend JavaScript) and Python (fantastic for machine learning). However, if you’re a PHP, C#, or Go developer, you can likely achieve similar results with those stacks. Don’t feel pressured to switch languages unless there’s a compelling reason.
To give you a concrete example, here’s a quick overview of our tech stack. We’ll reference these tools in later sections:
Frontend
We’re using Angular for our web app, while our marketing website runs on Next.js. As always, it’s best to use the tools you’re most familiar with. In some cases, you might not need a JavaScript framework at all-traditional HTML, CSS, and JavaScript could be more than enough.
Speaking of the AI boom, you might want to check out tools like Bolt.new, Loveable, or v0 to speed up frontend development. As a developer who was quite skeptical about these tools not long ago, I have to admit I’m amazed at how much they’ve evolved recently-but that’s probably a topic for another post.
Backend
We use Nest.js, a TypeScript-based framework built on top of Node.js. If you prefer Python, Django is an excellent choice. For PHP lovers, Laravel is highly popular. Pick the framework you can develop and maintain the fastest.
Database
We use PostgreSQL. It’s a robust relational database with excellent support for JSON fields, which can be handy for storing scraped data. However, any database — relational or NoSQL — could work, depending on your needs.
Hosting and deployment
We rely heavily on AWS, utilizing services like EC2, Elastic Container Service, S3, and RDS for our databases. We’ll discuss scalability considerations in a later section.
Automations
To create robust website automations and interactions, we use Playwright with headful browsers (Firefox and Chromium). If you’re working on any automation-related tasks, I highly recommend Playwright-it’s a powerful and reliable tool.
Machine learning
We leverage Python’s extensive AI/ML ecosystem for tasks like data classification and advanced text processing. Countless Python libraries such as TensorFlow, PyTorch can be extremely helpful if you want to integrate machine learning into your scraping or monitoring pipelines.
What data do you want to collect?
There are several types of data you might want to collect when interacting with a webpage. Below, I’ll outline key approaches for capturing screenshots, HTML snapshots, and extracted text, along with best practices to ensure accuracy and reliability.
Screenshots: How to capture the perfect screenshot?
Taking a screenshot may seem trivial, but in practice, it can be quite tricky. Websites are built in vastly different ways, and you often need to deal with challenges like scrolling elements, animations, lazy loading, and pop-ups.
Playwright provides built-in screenshot functionality, but in many cases, capturing a high-quality screenshot requires preprocessing or manipulating the website to ensure the final image is accurate.
Playwright offers two main screenshot options:
Viewport screenshot — Captures only what is currently visible.
Full-page screenshot — Attempts to capture the entire page.
However, taking a full-page screenshot is particularly tricky, as many websites load additional content dynamically.
Ensuring the page is fully loaded
For a reliable screenshot, the page must be completely loaded. Playwright offers the page.waitForLoadState() function-which you can call with, for example, page.waitForLoadState('domcontentloaded') -to ensure all essential resources are in place before proceeding.
Many websites load images and elements only when they are scrolled into view. This means you need to scroll down the page before taking a screenshot. Additionally, websites often use CSS or JavaScript-based animations (e.g., fade-ins), which can cause issues.
To handle lazy-loaded images, one approach is to repeatedly check each image at set intervals to confirm it has fully loaded. For full-page screenshots, you generally have two options.
The first is to scroll through the page and capture multiple images-one per visible viewport-then stitch them together later. However, this method often leads to layout shifts and inconsistencies.
The second option is to use the “fullPage” screenshot API in Playwright (or Puppeteer), which typically yields better results, provided you properly prepare the webpage beforehand.
Preparing the webpage for a perfect screenshot
To get a clean, accurate screenshot, you may need to inject custom CSS and JavaScript to disable animations and transitions.
To ensure elements appear instantly without animations use this CSS:
* { transition: none !important; }
Some websites use JavaScript animation libraries like GSAP. Even if you disable CSS transitions, elements might still be animated. To handle this scroll down the page gradually in small steps (randomized pixel amounts to avoid bot detection). Then wait for elements to fully load before continuing.
Another common issue occurs when scrolling-if an element moves out of view, it may revert to its original state before the animation. To capture a perfect screenshot, all elements should remain visible in their final state. A good approach is to use a MutationObserver to ensure animated elements do not reset when they re-enter the viewport.
On some websites (e.g., Facebook, Instagram), scrolling loads more content dynamically, expanding the screenshot area indefinitely. To prevent this disable further HTTP requests by intercepting network requests in Playwright.
By applying these techniques, you should be able to capture high-quality screenshots on most websites. For stubborn cases, minor CSS or JavaScript tweaks might still be needed.
HTML snapshot: preserving a webpage
Another valuable type of data to collect is a snapshot of the webpage’s HTML, including all assets (images, CSS, JavaScript, fonts, etc.).
Two approaches to saving a full webpage copy
Saving HTML and all requested assets separately
This method creates an offline replica of the website, allowing later viewing. However, all asset references in the saved HTML must be updated to point to the downloaded versions rather than the original online sources.Saving everything in a single HTML file (recommended)
To avoid dealing with multiple files, you can embed all assets directly into a single HTML file using Base64 encoding. This approach is used by the popular Chrome extension SingleFile (check its GitHub repository for implementation ideas).
Extracting text: getting structured data
Extracting valuable text from websites depends on the use case. Sometimes, pulling text directly from HTML isn’t ideal, as it may include visually hidden elements or unwanted content. In such cases, it can be more effective to extract text from a screenshot using an OCR (Optical Character Recognition) library like Tesseract.
Performing human-like actions
An essential part of web automation is the ability to perform actions on a webpage, such as clicking buttons or interacting with forms. Often, navigating through a site is necessary to reach the data you want to scrape. You may also find yourself repeatedly performing certain actions manually, which makes automating your workflow a logical next step. This is where Playwright shines. As an end-to-end testing library, it excels at mimicking user interactions.
With well-written code, you can automate any action that a user would typically perform. The concept is straightforward: you provide a selector for the element you want to interact with-such as a button-and then trigger an action like a click. Besides basic interactions, Playwright also supports mouse movements, keyboard inputs, scrolling, and essentially anything a user could do on a webpage.
However, automation isn’t always that simple. Locating the right element to interact with can be challenging. You need a unique selector to ensure your automation targets the correct element. If multiple elements match the same selector, the script may behave unpredictably. On some websites, CSS classes change frequently or are generated dynamically by frameworks, making XPath a more reliable alternative in such cases.
Another common challenge is dealing with elements that aren’t immediately visible or don’t respond to standard events like mouse clicks. In such situations, workarounds may be needed. Additionally, websites are built in various ways, and some elements-such as iframes and web components-pose extra difficulties due to encapsulation and the Shadow DOM.
Luckily, with a good understanding of JavaScript and how the DOM works, you should be able to adjust your script to overcome common challenges.
Data processing and notifications
Once you collect data, you’ll likely want to process it, store it somewhere, compare snapshots, generate insights, or notify your team when something changes.
Web automation often involves handling large amounts of data, and storing it on a local disk or a small droplet may not be the best choice. We use Amazon S3, which allows you to store scraped data as text files, HTML snapshots, or screenshots.
Depending on your application, you may also need to perform specific operations on your data.
If you are building a website change monitoring service, you might need to perform image differencing. A useful library for this is pixelmatch, which enables you to compare screenshots and detect changes down to the pixel level. If you require a high level of customization, you can develop your own algorithm, as we did in our app.
Based on the collected data, you may need to trigger specific actions, call webhooks, or send alerts via email, Slack, or any other communication channel.
Scalability and schedulling considerations
Automation workflows often run on schedules, whether hourly, daily, or weekly. In our case, we use the rrule library in Node.js, which simplifies defining complex recurrence rules, such as “run on the last weekday of the month” or “run every 15 minutes on weekends.”
Beyond scheduling, a reliable job queue system is essential for handling large-scale tasks efficiently. We use BullMQ, a Redis-based queue system, to distribute tasks and prevent resource overload.
The architecture of an automation system varies significantly depending on its scalability requirements. A simple application that runs known automations at fixed times is fundamentally different from a scalable system designed to handle hundreds of thousands of users.
To maximize automation efficiency and minimize bot detection, we use headful Firefox and Chromium browsers along with an xvfb graphical interface. This setup has proven far more effective than running browsers in headless mode. However, browser-based automation is resource-intensive, requiring careful architectural planning. At monity.ai, we rely on AWS services and a containerized approach using AWS Fargate. The number of active users and automation tasks varies over time, so we leverage Fargate step scaling with AWS CloudWatch to dynamically adjust resources-scaling up when demand increases and scaling down when it decreases..
Since our service is schedule-based, we can predict peak demand on Fargate resources and proactively increase the number of running services at specific times. While this level of infrastructure might not be necessary for every application, using a queue system like BullMQ, AWS SQS, or a custom implementation is highly recommended. If your server or machine can handle only a fixed number of concurrent tasks — say, 10 — you can use a queue to ensure that tasks are processed in controlled batches, preventing server overload and potential crashes.
AWS Fargate works well for us, but other solutions like Kubernetes or AWS Lambda are also viable options. However, if you’re dealing with frequent, long-running tasks, Lambda might not be cost-effective, as serverless solutions can become prohibitively expensive for such workloads.
Common obstacles and how to solve them
Anyone working with automation has inevitably encountered issues with applications blocking requests due to anti-bot protections. Websites employ various techniques to detect and prevent automated access, making it one of the biggest challenges in web automation.
Bot protection mechanisms range from simple measures like rate limiting to more advanced techniques such as browser fingerprinting, behavioral analysis, and CAPTCHAs. Many sites track request patterns, monitor mouse movements, and even analyze typing speed to distinguish between humans and bots. If an automation script makes too many requests in a short time or fails to replicate human-like interactions, it’s likely to get flagged.
One of the most effective ways to bypass these restrictions is using residential proxies, which make automated requests appear as if they’re coming from real users across different locations. Rotating proxies can further help by ensuring each request originates from a different IP address, reducing the likelihood of detection. However, even with proxies, websites may detect suspicious behavior if requests follow unnatural patterns or lack sufficient delays between actions.
CAPTCHAs present another major obstacle. Many sites use them to challenge suspected bots, making automation more difficult. While third party services can solve CAPTCHAs programmatically, relying on them extensively can slow down workflows and introduce additional costs. In monity.ai, we are using headful browsers with realistic user interactions-such as moving the mouse, to reduce CAPTCHA triggers.
Advanced anti-bot protections, such as browser fingerprinting, pose an even greater challenge. Websites analyze browser characteristics, screen resolution, installed fonts, and even hardware configurations to detect automation tools.
Despite using advanced techniques in our app, we cannot support all websites, and a small percentage of them do not load properly.
Beyond technical solutions, it’s essential to consider ethical and legal aspects. Some websites explicitly prohibit automated access in their terms of service, and persistent scraping can result in IP bans or legal consequences. Whenever possible, using official APIs is a more sustainable approach. When automation is necessary, it should be designed carefully to minimize disruption, avoid overloading servers, and ensure compliance with site policies.
AI-driven browser agents: current limitations and practical ML usage
AI-driven “browser agents” are still evolving, and their reliability can be questionable. As mentioned earlier, there are numerous pitfalls in rendering webpages and extracting data, and today’s AI agents don’t reliably overcome all of these challenges. At monity.ai, we’re actively developing similar solutions with the goal of reducing UI-based configurations in favor of prompt-driven interactions. However, because our flagship feature is website monitoring-and we must ensure the data we collect is both accurate and reliable-we can’t yet rely on fully automated AI agents in production.
That said, there are many other ways to incorporate machine learning into your workflow. For instance, Natural Language Processing can summarize or categorize scraped content, and image recognition can label or detect objects in screenshots. In some scenarios, you can even build adaptive automations that change their behavior based on the page’s content. Still, it’s important to keep an eye on performance constraints and costs. Sometimes, simpler heuristics or rule-based systems are enough.
A great example of AI in action is creating “AI summaries”-short, human-readable explanations of exactly what changed on a monitored page. You might consider passing two screenshots to a large language model to identify differences, but this can be prohibitively expensive when dealing with many large images-and the results aren’t always high-quality.
Instead, we use a robust set of algorithms and logic to handle changes more reliably. For instance, we ensure the page is fully loaded, take a screenshot, store the HTML, construct a DOM map, and extract only the relevant text-all while minimizing false positives. We then feed this processed information into our AI models for deeper analysis and richer understanding. This approach balances thorough data capture with cost efficiency and reliable performance.
How monity.ai does it
Now, let’s see these techniques in action. We’ll use a simple Nike shoes price-monitoring example in monity.ai to demonstrate how the platform handles web scraping, automation, and alerts in a real-world scenario.
1. Define what you want to monitor
Monity.ai offers several monitoring modes-each corresponding to the approaches we discussed above:
Visual Monitoring: Select a resizable box on the webpage (using a screenshot overlay with a DOM representation) to watch for changes in layout or specific elements.
HTML Element Monitoring: Track changes in a particular HTML element’s content.
Text Monitoring: Get notified only when specific text changes (useful for price drops or product availability).
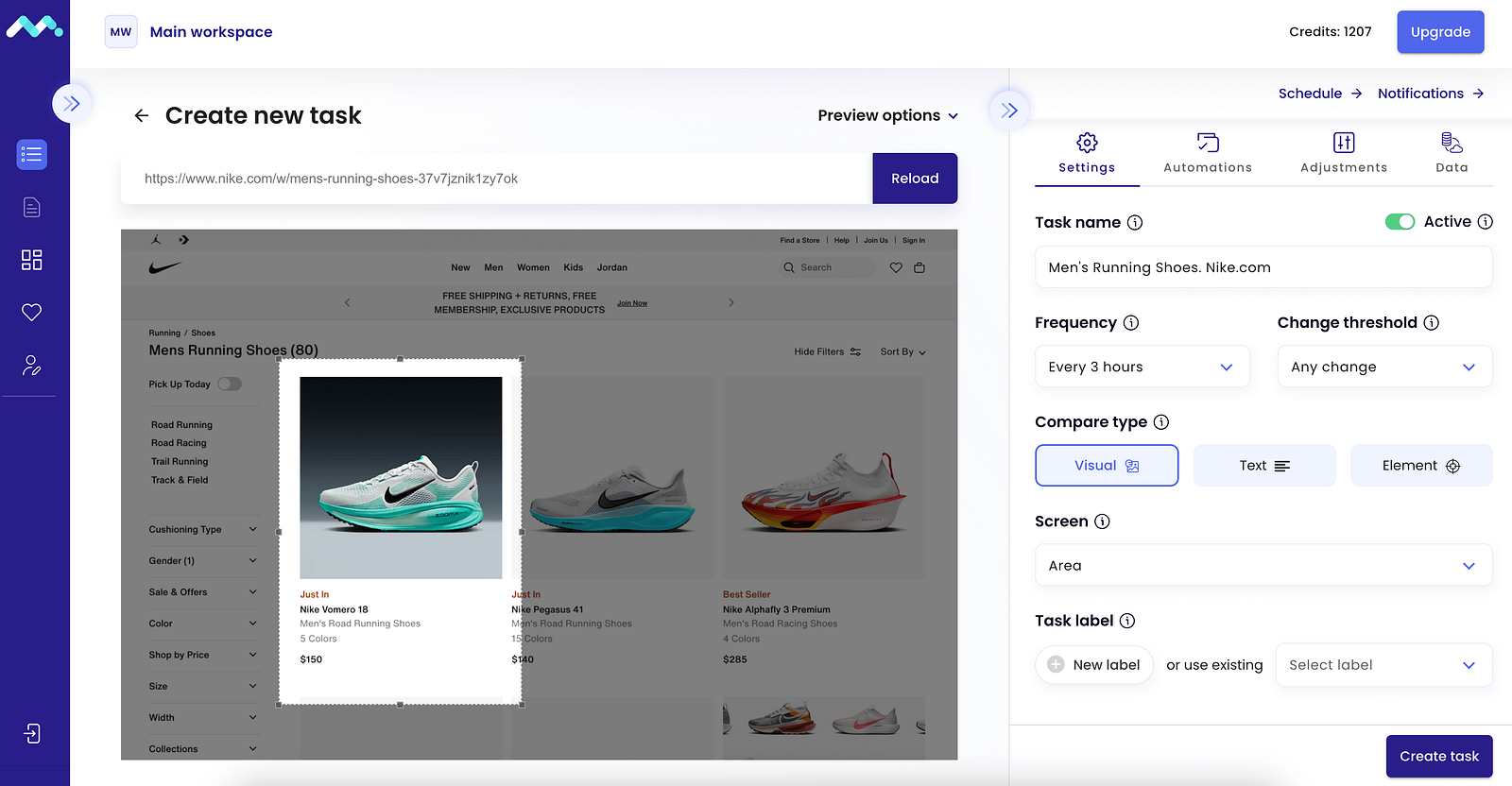
Visual selector
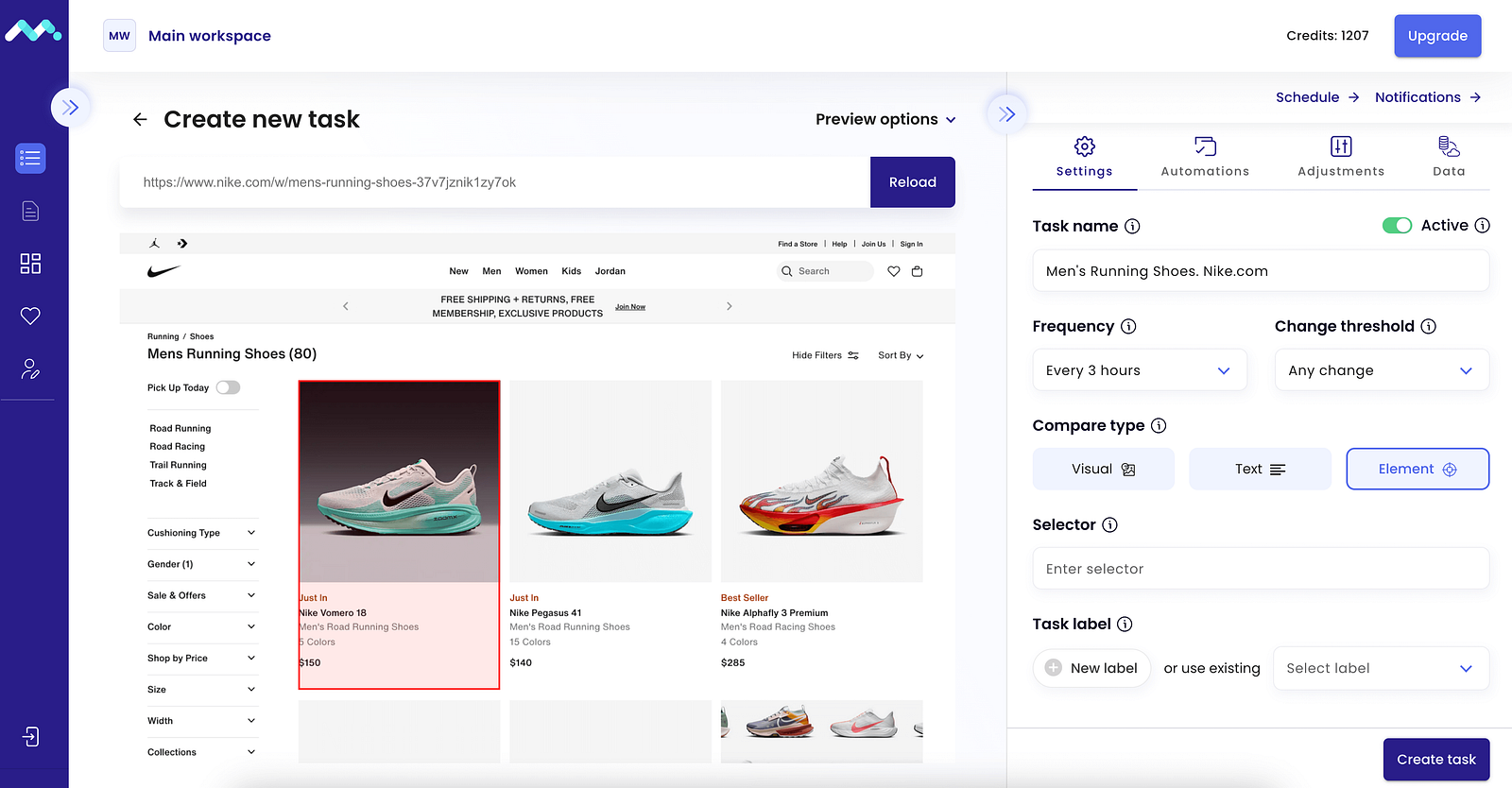
Element selector
2. Wait for an alert
Once you’ve configured your monitoring criteria, the system periodically checks for changes. If it detects a difference-such as a lower price-it sends you an email notification with a screenshot and an AI-based summary of what changed.
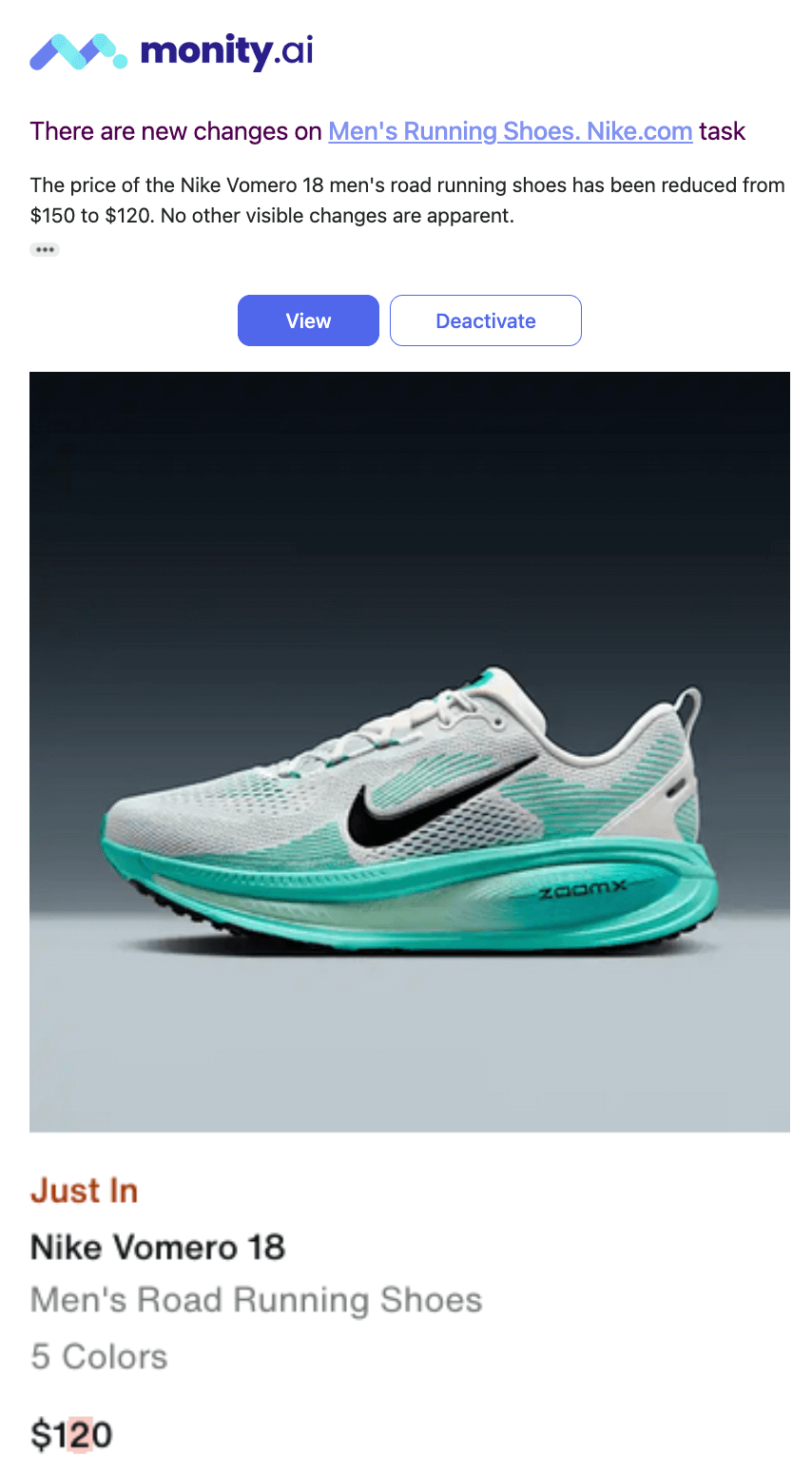
monity.ai email alert
3. Review and adjust
If you no longer need to monitor a particular item, simply deactivate the task. Otherwise, you can refine your settings to better capture the data you want. For instance, you can set conditions so that you only receive an alert if the price falls below $100. By default, the system also stores an HTML snapshot and text output of the monitored area, giving you a detailed record of every change.

Tasks sidebar

Task check preview
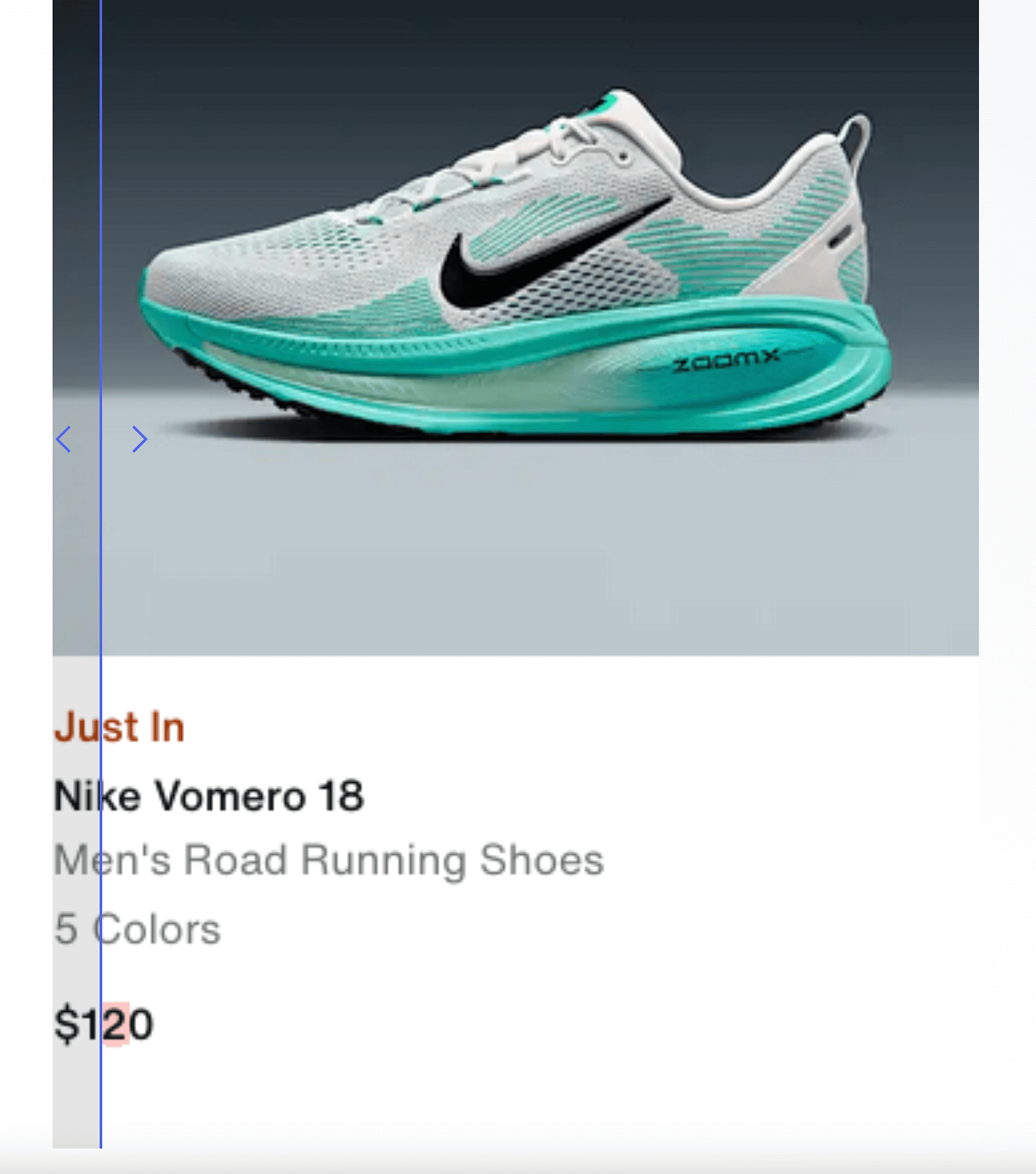
Comparison slider
Use cases to inspire you
The Nike shoes example is just the tip of the iceberg. Here are a few other ways you can leverage website automation:
Layout and Visual Checks
Keep a close eye on critical webpages for your business. If something breaks or looks off, you’ll get an instant notification-saving you headaches and potentially a lot of money.Price Tracking
Monitor competitor pricing or products on marketplaces. Know the moment a price changes so you can react quickly.E-commerce Inventory Checks
Track stock levels and product variations across multiple online stores.Compliance & Legal Monitoring
Ensure your site-or your partners’ sites-remain compliant with relevant laws and regulations.SEO & Content Monitoring
Watch for content updates and brand mentions, and stay on top of any important changes that might affect your search rankings.Lead Generation
Automate form submissions, gather contact details, or build targeted prospect lists more efficiently.Error Monitoring
Get notifications if your webpage experiences errors or downtime.
Final Thoughts
Building a scalable, reliable web scraping, monitoring, and automation app can unlock tremendous value for your business. By starting with a well-defined plan, selecting the right technologies, and focusing on robust scheduling and job management, you’ll be on a clear path to success.
Remember to plan for common pitfalls like bot protections and unexpected website changes. If you need AI-driven insights-such as text summarization or image recognition-there are many frameworks and libraries available to help elevate your automations.
Ready to take your web automation game to the next level? Consider these steps, experiment with various tools, and apply the best practices discussed. If you’d like a head start, feel free to explore Monity.ai or any other platform that suits your project needs.
If you enjoyed or disliked this article, have any suggestions, or want more code examples, let me know-I’d love to hear your feedback!
Thanks for reading, and best of luck on your journey to building a more automated, data-driven future!
Subscribe to my newsletter
Read articles from Kamil Kowalczyk directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by