Unlocking AI Potential: A Deep Dive into NPU, GPU, TPU and FPGA
 Harshit Sharma
Harshit Sharma
We have witnessed significant advancements in AI-specific hardware, ranging from the widespread adoption of GPUs to the emergence of specialized NPUs and TPUs. Each development has brought us closer to realizing the full potential of AI at the edge. However, I believe we are on the verge of something even more groundbreaking. Intel has introduced its ‘Lunar Lake’ processors with enhanced NPU capabilities. Meanwhile, outside the ‘PC’ realm, Apple recently announced an upgraded NPU in the M4 chip, which powers their latest products.
The first Apple Neural Engine that debuted within Apple’s A11 chip in 2017’s iPhone X was powerful enough to support Face ID and Animoji.
As we push the boundaries of what’s possible with artificial intelligence at the network edge, I find myself wondering: what truly transformative breakthroughs lie just beyond the horizon? Perhaps the next leap forward will come from novel architectures that fundamentally reimagine how we process AI workloads. Let’s explore the details of Neural Processing Units (NPUs) and compare them with other AI-specific processors, such as Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs).
The Next Wave of AI-Optimized Compute
When choosing the SoC for 56 AI One camera, understanding memory utilization and compute efficiency was crucial for handling multiple AI workflows. Want to know how to measure efficiency in AI SoCs? Read my blog for more details.
In-memory computing tackles the von Neumann bottleneck directly by performing computations within memory units. This approach significantly reduces data movement, resulting in substantial improvements in both speed and energy efficiency for AI workloads. Reconfigurable AI accelerators are emerging. These chips can dynamically adapt their architecture to optimally suit various AI tasks, providing unparalleled flexibility and efficiency across a wide range of applications..
As we strive for more powerful and efficient AI systems, the distinctions between different types of specialized processors are becoming less clear. The future may not lie in discrete GPUs, TPUs, or NPUs, but in highly integrated, multi-paradigm chips that seamlessly combine various computational approaches to address the most challenging AI problems.
NPU : Neural Processing Units

NPUs are specialized chips designed specifically for AI tasks, particularly those involving neural networks. Their architecture is optimized to handle the parallelism and efficiency required for AI computations, often outperforming traditional CPUs and even GPUs in certain tasks.
Key Characteristics of NPUs:
Optimized Parallel Processing: Designed to handle multiple AI operations simultaneously.
Energy Efficiency: Lower power consumption compared to GPUs, making them ideal for mobile and edge computing.
Synaptic Weight Mechanism: This principle enhances learning efficiency by strengthening frequently used pathways, akin to synaptic activity in the human brain.
Some of the NPUs worth checking out : Qualcomm Hexagon, Apple Neural Engine.
TPU : Tensor Processing Unit
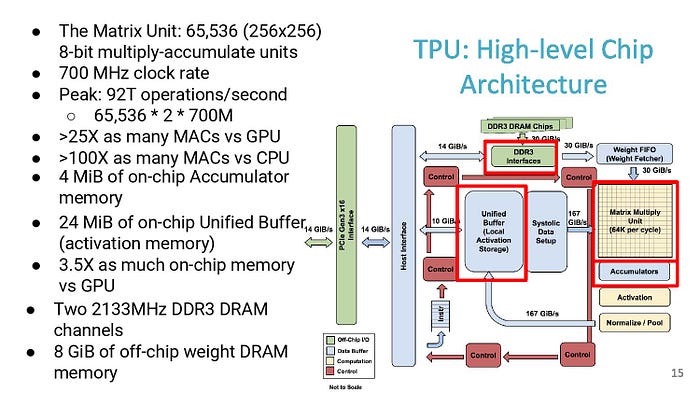
TPU : High Level Architecture
In mathematics, a tensor is an algebraic object that describes a multilinear relationship between sets of algebraic objects related to a vector space. Tensors may map between different objects such as vectors, scalars, and even other tensors.
A tensor may be represented as a (potentially multidimensional) array.
So, depending on the nature of the tensor, it can be represented as an array of n dimensions where n is 0,1,2,3 and so on. Some of these representations have more familiar, names:
Dimension 0 — scalar
Dimension 1 — vector
Dimension 2 — matrix
Why is a Tensor Processing Unit so called? Because it is designed to speed up operations involving tensors. Precisely, what operations though? The operations that are referred to in our original Wikipedia definition which described a tensor as a “map (multilinear relationship) between different objects such as vectors, scalars, and even other tensors”.
GPU
Graphics Processing Units (GPUs) have become indispensable in the field of artificial intelligence. Originally designed to accelerate graphics rendering, their highly parallel structure makes them ideally suited for handling the extensive computations required in AI workloads. GPUs excel in performing numerous calculations simultaneously, which is crucial for training deep neural networks and processing large datasets. NVIDIA, a leader in GPU technology, has significantly enhanced the capabilities of GPUs for AI through its CUDA platform, which allows developers to exploit the parallel processing power of GPUs for a variety of machine learning tasks. This flexibility makes GPUs an attractive option for researchers and companies looking to perform both AI training and inference.
Their mature ecosystem, supported by robust software frameworks and tools, has facilitated widespread adoption and continuous optimization. This extensive support network helps in achieving higher performance and ease of use for developers and researchers alike. Despite the emergence of more specialized processors like TPUs and NPUs, GPUs continue to be a cornerstone of AI hardware, balancing flexibility, power, and accessibility.
FPGA ?
Field-Programmable Gate Array (FPGA)

Vaaman, an edge computing board developed by Indian Startup Vicharak ( Computer Hardware Startup)
Field-Programmable Gate Arrays (FPGAs) offer a unique and powerful solution in the AI hardware landscape. Unlike GPUs and TPUs, which have fixed architectures, FPGAs can be reprogrammed to optimize performance for specific tasks, providing a high degree of customization. This reconfigurability allows developers to tailor the hardware to their exact needs, achieving significant performance improvements for specialized AI applications. FPGAs can be optimized for low latency, making them particularly suitable for real-time AI processing where quick response times are critical.
Do checkout Vicharak, their high-performance edge computing board looks promising.
In addition to their adaptability, FPGAs are known for their potential energy efficiency. By customizing the hardware configuration, it is possible to achieve a balance between power consumption and performance that is difficult to match with fixed-architecture processors. This makes FPGAs an attractive choice for edge computing, where energy efficiency is often as important as computational power. Moreover, their flexibility makes them valuable in the prototyping and development stages, allowing for rapid testing and iteration of new AI algorithms before committing to a specific hardware design. As AI applications continue to diversify, the role of FPGAs in providing customizable, efficient, and high-performance solutions is likely to expand.
Summary of Differences:
Functionality: GPUs are versatile, TPUs are specialized for tensor operations, and NPUs are tailored for neural network tasks.
Parallelism: All three excel in parallel processing but differ in their optimization focus.
Use Cases: GPUs dominate in data centers, TPUs in Google’s infrastructure, and NPUs in mobile and edge devices.
Energy Efficiency: TPUs and NPUs are generally more energy-efficient than GPUs, suitable for their respective applications.
Conclusion:
Choosing the right processor for AI applications depends on the specific requirements of the task. GPUs offer flexibility, TPUs provide specialized acceleration for tensor operations, and NPUs deliver efficient neural network processing. As AI technology advances, so will the hardware, driving innovation and efficiency in this exciting field. We do face many limitations while optimizing the AI pipeline for specific NPU/SOC architectures, but we hope for seamless development as the industry moves forward in designing new architectures.
Subscribe to my newsletter
Read articles from Harshit Sharma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by