The Failure of the Socratic Method in AI Research
 Gerard Sans
Gerard SansTable of contents
- The UPFT Paradox: Reasoning Without Reasoning?
- The Elephant in the Room: Statistical Correlation
- The Missed Opportunity: Ignoring the Evidence Within
- The Seduction of Shiny Keywords and Benchmark Scores
- The Missing Due Diligence: A Call for Intellectual Honesty
- The Call to Action
- Conclusion: Rekindling the Socratic Flame in AI Research

The field of Artificial Intelligence, particularly Large Language Models (LLMs), is experiencing a gold rush. Papers flood conferences, benchmarks fall weekly, and the hype machine runs at full throttle. Yet amid this frenzy, we've abandoned the very foundation of scientific progress: the Socratic method of rigorous questioning.
Socrates taught us that knowledge begins not with answers, but with questions – specifically, with questioning our own assumptions and subjecting them to ruthless scrutiny. This approach has driven scientific breakthroughs for millennia. But in modern AI research, it's increasingly absent.
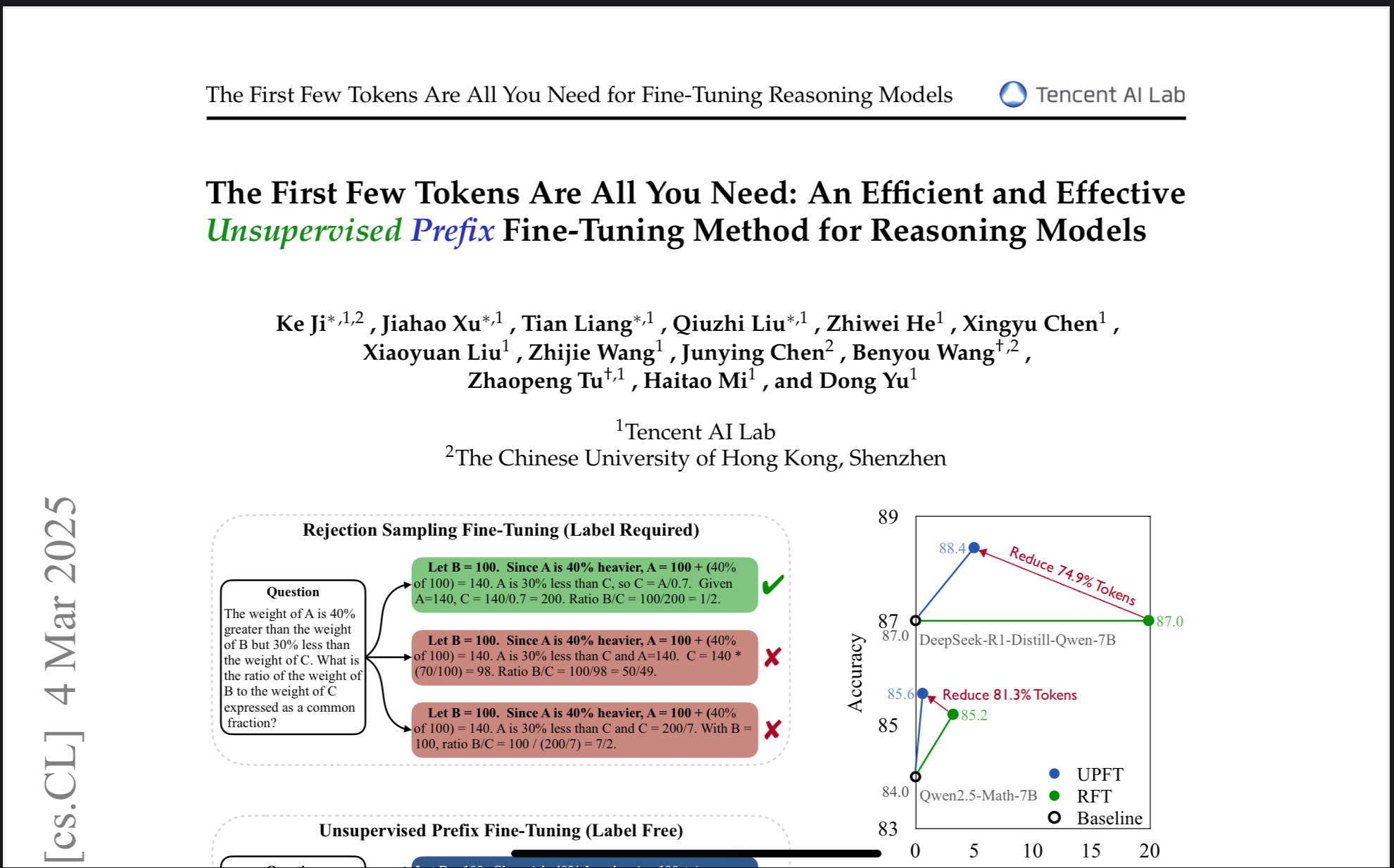
A recent paper titled "The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models" serves as an illustrative case study. To be clear, this paper isn't uniquely problematic – it's simply a convenient lens through which to examine a pervasive issue. The authors' work is technically sound and innovative. But like many contributions in the field, it inadvertently highlights how we've strayed from foundational scientific principles in favor of incremental advances that don't challenge our fundamental assumptions.
The UPFT Paradox: Reasoning Without Reasoning?
The core idea of UPFT is surprisingly simple (and that's where the trouble begins). The authors observed that LLMs, even when they get the final answer to a reasoning problem wrong, often start their "reasoning" process in a consistent way. These initial steps – the "prefix" – are often remarkably similar across multiple attempts. So, they decided to train LLMs exclusively on these prefixes, completely ignoring the rest of the "reasoning" chain, and even the correctness of the final answer.
And it worked! They achieved state-of-the-art results on several reasoning benchmarks. This is, on the surface, a triumph of efficiency and ingenuity. But dig a little deeper, and a profound paradox emerges: they're claiming to improve "reasoning" by discarding the very thing they're supposed to be improving.
The Elephant in the Room: Statistical Correlation
The UPFT paper, like many others in the field, dances around the elephant in the room: LLMs are fundamentally based on statistical correlation. They learn to predict the next word in a sequence based on the patterns in their training data. There's no inherent understanding of logic, causality, or the meaning of the words they're manipulating.
Pretraining, the foundation of LLM capabilities, is entirely about statistical correlation. Fine-tuning, even for "reasoning," is just a refinement of these pre-existing correlations. The "reasoning crutch" – Chain-of-Thought prompting, step-by-step solutions – is an attempt to impose a human-like structure on this fundamentally statistical process.
The success of UPFT, ironically, exposes the flimsiness of this "reasoning" edifice. It suggests that much of what we call "reasoning" in LLMs is just statistical fluff, window dressing on a core of pattern matching. The emperor, it turns out, has no clothes (of reasoning).
The Missed Opportunity: Ignoring the Evidence Within
Perhaps the most intriguing aspect of the UPFT paper is not what it claims, but what it implies. The authors have stumbled upon a significant piece of evidence that directly contradicts the prevailing narrative about LLM reasoning, yet they fail to fully acknowledge or explore its implications. This represents a missed opportunity for genuine scientific progress, a chance to challenge the status quo and redirect research efforts towards a more fruitful path.
Here's the core contradiction:
The Premise: The paper is ostensibly about improving LLM reasoning capabilities. The entire field of LLM reasoning is built on the assumption that explicit, step-by-step reasoning chains are crucial for achieving human-level performance on complex tasks.
The Finding: The paper demonstrates that you can achieve state-of-the-art results by discarding the vast majority of the reasoning chain, focusing solely on the initial "prefix." This finding directly undermines the premise. It suggests that the "reasoning" part is largely irrelevant, at least for the benchmarks used in the study.
Even better: The paper demonstrates it can achieve good results without labeled data, an important point that's often overlooked.
The Response: Instead of acknowledging this contradiction, the authors frame their findings as a positive result – a new, efficient method for fine-tuning LLMs. They emphasize the practical benefits (reduced computational cost, no need for labeled data) while downplaying the theoretical implications.
It's as if a physicist discovered that gravity doesn't actually work the way Newton described it, but instead of publishing a groundbreaking paper overturning centuries of established theory, they simply said, "Look, we've found a new, more efficient way to calculate the trajectory of projectiles!"
The Question That Should Have Been Asked
The central question the authors should have asked is this:
If the vast majority of the reasoning chain is unnecessary for achieving high performance on these benchmarks, what does that tell us about the nature of "reasoning" in LLMs (and the validity of these benchmarks)?
Instead of asking this fundamental question, they've opted for a more incremental, less disruptive approach. They've found a clever way to improve performance within the existing paradigm, without challenging the paradigm itself.
The Implications (That Were Largely Ignored)
The implications of their findings are far-reaching:
The "Reasoning" Illusion: The success of UPFT suggests that much of what we call "reasoning" in LLMs is just a sophisticated form of pattern matching, a statistical mimicry of human reasoning processes. The actual "understanding" may be minimal, or even absent.
The Benchmark Problem: The fact that UPFT can achieve state-of-the-art results on these benchmarks suggests that the benchmarks themselves may be flawed. They may be rewarding superficial pattern matching rather than genuine reasoning abilities.
The Need for a Paradigm Shift: The findings point to the need for a fundamental re-thinking of how we approach LLM reasoning. We may need to move beyond the current focus on explicit, step-by-step reasoning chains and explore alternative architectures and training methods.
The Seduction of Shiny Keywords and Benchmark Scores
The AI research landscape is, unfortunately, often driven by factors other than pure scientific inquiry. The pressure to publish, the allure of funding, and the desire for recognition can lead to a focus on "shiny new things" – novel techniques, impressive benchmark scores, and fashionable keywords.
Critical thinking, the careful questioning of assumptions, and the rigorous testing of hypotheses can take a backseat to the pursuit of novelty and "impact." This is not to say that all research is driven by these factors, but the incentives are certainly there, and the temptation to take shortcuts can be strong.
The Missing Due Diligence: A Call for Intellectual Honesty
What's often missing is a fundamental sense of due diligence. Before embarking on a complex research project, it's crucial to:
Question Assumptions: What are the underlying assumptions of your work? Are they justified? Have you considered alternative perspectives?
Test Hypotheses Rigorously: Don't just look for evidence that supports your hypothesis; actively seek evidence that contradicts it.
Embrace Negative Results: A negative result – a finding that disproves your hypothesis – can be just as valuable as a positive one. It can point you in a more fruitful direction.
Prioritize Understanding Over Performance: Don't just chase higher benchmark scores; strive to understand why your models are succeeding (or failing).
Be Honest About Limitations: Every method has limitations. Acknowledge them openly and honestly.
The UPFT paper, while a clever piece of engineering, inadvertently highlights the lack of this due diligence in much of the current LLM research. It's a symptom of a broader trend: the tendency to pile on more techniques without addressing the fundamental limitations of the underlying technology.
The Call to Action
The UPFT paper, despite its limitations, provides a valuable service to the research community. It inadvertently exposes a fundamental flaw in the current approach to LLM reasoning. It's up to us, the researchers, the critics, the "pamphleteers," to seize this opportunity, to challenge the prevailing narrative, and to push for a more honest and rigorous approach to AI research. We need to stop chasing butterflies and start digging for deeper understanding. The evidence is there, staring us in the face; we just need to have the courage to see it.
Conclusion: Rekindling the Socratic Flame in AI Research
The pursuit of artificial intelligence is a noble endeavor. But to make genuine progress, we must rekindle the Socratic flame that once illuminated scientific inquiry. This means returning to first principles: questioning assumptions, embracing contradictory evidence, and prioritizing understanding over performance metrics.
The UPFT paper, like many others, reveals symptoms of our collective departure from scientific rigor. It's not the authors' fault – they're responding to the incentives and norms of the current research environment. But recognizing this pattern gives us an opportunity to change course.
Socrates famously claimed that wisdom begins with acknowledging what we don't know. Perhaps true progress in AI requires a similar humility – an admission that our understanding of "reasoning" in these systems remains profoundly limited, and that our benchmarks may be measuring statistical mimicry rather than genuine comprehension.
Let us move beyond the illusion of progress measured in leaderboard positions. Let us ask the uncomfortable questions that challenge prevailing narratives. Let us build AI on foundations of evidence and intellectual honesty rather than hype and incremental optimization. The future of the field depends not on how quickly we can improve performance metrics, but on whether we have the courage to question what those metrics truly mean.
The time has come to revive the Socratic method in AI research – not just as a prompt engineering technique, but as the philosophical cornerstone of genuine scientific progress.
Subscribe to my newsletter
Read articles from Gerard Sans directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Gerard Sans
Gerard Sans
I help developers succeed in Artificial Intelligence and Web3; Former AWS Amplify Developer Advocate. I am very excited about the future of the Web and JavaScript. Always happy Computer Science Engineer and humble Google Developer Expert. I love sharing my knowledge by speaking, training and writing about cool technologies. I love running communities and meetups such as Web3 London, GraphQL London, GraphQL San Francisco, mentoring students and giving back to the community.