Spring Batch and How to Implement It Effectively
 Tuanhdotnet
Tuanhdotnet4 min read

1. Introduction to Spring Batch
1.1 Why You Should Use Spring Batch
Spring Batch offers several compelling reasons for its use:
- Efficiency: Spring Batch allows developers to process massive volumes of data efficiently and quickly, utilizing features like chunk processing, parallel execution, and retry mechanisms.
- Scalability: It enables horizontal scaling to handle massive data loads, ensuring that batch jobs run smoothly even under heavy loads.
- Fault-tolerant: With built-in features like transaction management, error handling, and job restarts, Spring Batch ensures robustness and reliability.
- Ease of use: The framework simplifies repetitive tasks such as reading/writing data from different sources (e.g., files, databases, queues), managing transactions, and handling errors.
1.2 What Makes Spring Batch Stand Out
One key feature that makes Spring Batch unique is its chunk-oriented processing model, where records are processed in chunks. This model allows for easier management of large datasets, as data is split into manageable portions, processed in memory, and written out when necessary.
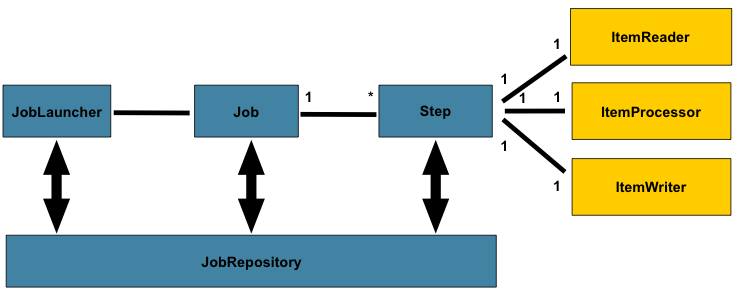
Moreover, Spring Batch’s modular architecture allows developers to plug in various components such as different data sources, job schedulers, and transaction management systems to meet the specific needs of their project.
2. Steps to Implement Spring Batch
Now, let’s get into the heart of the matter—how do you implement Spring Batch in a real-world scenario? I’ll take you through the necessary steps and demonstrate how to process a CSV file in a batch job.
2.1 Setting Up the Project
First, you need to set up a Spring Boot project that includes Spring Batch dependencies. You can do this using Maven or Gradle. For Maven, the following dependencies are essential:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
In this setup:
- Spring Batch provides the framework for batch processing.
- Spring Data JPA helps manage database operations.
- H2 is an in-memory database, ideal for quick testing and demos.
2.2 Writing the Batch Configuration
Next, you need to create a Batch Configuration class. This is where you define the steps of your job, including reading, processing, and writing data.
Here’s a simple example of reading from a CSV file, processing each row, and writing it to a database:
@Configuration
@EnableBatchProcessing
public class BatchConfig {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public FlatFileItemReader<Person> reader() {
return new FlatFileItemReaderBuilder<Person>()
.name("personItemReader")
.resource(new ClassPathResource("people.csv"))
.delimited()
.names(new String[]{"firstName", "lastName"})
.fieldSetMapper(new BeanWrapperFieldSetMapper<Person>() {{
setTargetType(Person.class);
}})
.build();
}
@Bean
public PersonItemProcessor processor() {
return new PersonItemProcessor();
}
@Bean
public JdbcBatchItemWriter<Person> writer(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<Person>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO people (first_name, last_name) VALUES (:firstName, :lastName)")
.dataSource(dataSource)
.build();
}
@Bean
public Job importUserJob(JobCompletionNotificationListener listener, Step step1) {
return jobBuilderFactory.get("importUserJob")
.incrementer(new RunIdIncrementer())
.listener(listener)
.flow(step1)
.end()
.build();
}
@Bean
public Step step1(JdbcBatchItemWriter<Person> writer) {
return stepBuilderFactory.get("step1")
.<Person, Person>chunk(10)
.reader(reader())
.processor(processor())
.writer(writer)
.build();
}
}
2.3 Processing the Data
The ItemProcessor is where the transformation logic happens. You can customize this class to filter, modify, or enrich the data before it’s written to the database. Here’s a simple example:
public class PersonItemProcessor implements ItemProcessor<Person, Person> {
@Override
public Person process(Person person) throws Exception {
final String firstName = person.getFirstName().toUpperCase();
final String lastName = person.getLastName().toUpperCase();
return new Person(firstName, lastName);
}
}
2.4 Running the Batch Job
To run the job, you need to configure the JobLauncher and run the application. Spring Batch will execute the job defined in your configuration, processing the CSV data, transforming it, and saving the result to your database.
Here is an example log of the job execution:
2024-09-19 12:00:00 INFO - Starting Job: importUserJob
2024-09-19 12:00:01 INFO - Processing record: John Doe
2024-09-19 12:00:02 INFO - Record processed: JOHN DOE
2024-09-19 12:00:03 INFO - Job finished successfully.
3. Conclusion
In this article, we explored the reasons why Spring Batch is an essential tool for processing large volumes of data. We also walked through a practical, step-by-step implementation using a CSV file as the input source, with Spring Batch handling everything from reading the file to saving the processed data into a database.
Spring Batch offers tremendous flexibility, scalability, and reliability, making it an excellent choice for batch processing in Java applications. It’s easy to configure, robust in handling failures, and efficient in handling large datasets.
If you have any questions or need further clarification, feel free to comment below, and I’ll be happy to help!
Read more at : Spring Batch and How to Implement It Effectively
0
Subscribe to my newsletter
Read articles from Tuanhdotnet directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Tuanhdotnet
Tuanhdotnet
I am Tuanh.net. As of 2024, I have accumulated 8 years of experience in backend programming. I am delighted to connect and share my knowledge with everyone.