QuOTE: More Effective Retrievals with Question-Driven Text Embeddings
 Irene Burresi
Irene BurresiTable of contents
- 1. Contextual background: The RAG Paradigm
- 2. QuOTE Core Idea and Architecture
- 3. Implementation Details
- 4. Empirical Evaluation: Benchmarks and Key Metrics
- 5. QuOTE Disadvantages and Limitations
- 6. Best Practices and Tips in Action
- 7. Future Directions & Limitations
- 10. Conclusion: QuOTE's Role in the Evolving RAG Landscape
- Closing Thoughts

Over the last year, Retrieval-Augmented Generation (RAG) has evolved from a promising research concept to a core component in LLM products. The idea is appealing: instead of making language models memorise everything in their head, we provide context at inference time. However, as is often in the AI field, many things that seem simple in theory end up being quite complicated in practice.
In a typical RAG setup, we split our documents into little chunks. This chunking step is already a bit of an art form - too small and you lose context, too large and you dilute relevance. Once we've got our chunks, we embed them using whichever embedding model is appropriate to our budget and needs. These embeddings are indexed in a vector database to be searched. When the user poses a question, we embed the user's question, retrieve the most similar segments based on embedding similarity, and then pass those segments along with the question to our LLM.
This approach has definitely cut down on hallucinations, but I have been seeing a consistent limitation shared by most RAG implementations: there usually is a fundamental misalignment between our chunk representation and how users formulate their questions.
Let's take an example. A document chunk stating "The Basel III framework established a minimum Common Equity Tier 1 (CET1) ratio of 4.5%, a Tier 1 capital ratio of 6%, and a total capital ratio of 8% of risk-weighted assets for financial institutions" contains the answer to a user's question "How do regulations prevent banks from collapsing?" The semantic distance between these statements is vast. The document chunk uses technical ratios, specific percentages, and regulatory terminology, while the user question employs everyday language about prevention and failure. Vector similarity alone struggles to connect these conceptually related but lexically divergent texts.
Enter QuOTE (Question-Oriented Text Embeddings). This groundbreaking approach, proposed by Andrew Neeser, Kaylen Latimer, Aadyant Khatri, Chris Latimer and Naren Ramakrishnan, turns the conventional RAG upside down, starting from the questions instead of the answers. Rather than simply embedding chunks in the way they appear in the source text, QuOTE supplements each chunk with questions that it would be capable of answering effectively. This produces a set of embeddings for each chunk, each of which is based on the content from a question-oriented perspective. The outcome? Far greater alignment with the types of queries that users really pose.

I have been trying out this approach on several proof of concepts and have found the gains in retrieval accuracy to be remarkable, which motivated me to share the technique with a larger group of people. There is elegance in how QuOTE solves the semantic gap problem—not by resorting to more complex models or endless parameter tuning, but by redefining how we encode our data.
In this article, we will explore:
The fundamentals of naive RAG vs. QuOTE – Understanding the limitations of standard Retrieval-Augmented Generation (RAG) and how QuOTE (Question-Oriented Text Embeddings) addresses them.
QuOTE's core design and indexing strategy – A deep dive into how QuOTE restructures chunk embeddings by generating question-based representations and improves retrieval alignment.
Empirical results comparing QuOTE to naive RAG and HyDE – Evaluating QuOTE's effectiveness using benchmark datasets and real-world retrieval scenarios.
Implementation tips and best practices – Practical guidance on setting up QuOTE, optimizing question generation, and fine-tuning retrieval performance.
Future directions for question-based retrieval – Exploring enhancements to QuOTE, potential integrations with multi-hop reasoning, and new frontiers in AI-driven information retrieval.
1. Contextual background: The RAG Paradigm
What is Retrieval-Augmented Generation, anyway? If you've been keeping up with advances in artificial intelligence over the past few years, you would have witnessed Retrieval-Augmented Generation (RAG) evolve from a specialised research topic to a fundamental paradigm for production-ready applications of large language models.
Essentially, RAG operates on a simple principle: for every user query, relevant segments of text are retrieved from your knowledge base and then passed through a language model such as GPT-4 or Claude, which produces the final output.
The charm of RAG is that it can give you the best of both worlds. It gives you the reasoning power and eloquent output typical of large language models, yet is grounded in specific, retrievable content that you control. This grounding reduces those frustrating hallucinations where models claim false facts with excessive certainty. In addition, it enables you to incorporate proprietary or up-to-date information without having to finetune the base model.
But as with most matters in machine learning, the devil is in the details. RAG implementations also bring a lot of devilish complexities to contend with.
The Limitations of Naive RAG
When I started implementing RAG systems last year, I quickly ran into a succession of ongoing problems that pure embedding similarity alone could not completely fix. Most common among these were:
Ambiguous or brief queries. If a user enters a query such as "Titanic casualties?" rather than "How many people died when the Titanic sank?" the semantic connection to pertinent information is far weaker. Brief queries lack the context that is needed for high similarity in embeddings.
Multi-hop situations in which it takes joining pieces of information across several documents to answer the question. For instance, one document may say that Marie Curie found radium, and another that the finding of radium contributed to improving cancer treatment. To answer "How did Marie Curie's work contribute to medicine?" is to link these disparate facts together.
Context mismatch happens when a passage contains the relevant information but is taken from a completely different perspective than the user's question implies. For instance, a passage about "NASA's budget for the 1969 moon landing" might not be very relevant to the question, "How much did it cost to put a man on the moon?"
In all cases, the underlying issue is the same: embedding similarity between queries and chunks collapses, as they are fundamentally different types of text, each with its own semantic structure.
The concept of 'Question-Aligned' Indexing
This brings us to something that, in retrospect, is quite obvious: questions are structured differently from statements. Why, then, are we trying to compare question embeddings and statement embeddings directly?
The concept behind QuOTE is very straightforward. Rather than just adding raw chunks—such as "The Titanic sank in 1912, claiming more than 1,500 lives"—we first generate hypothetical questions that the chunk might answer, such as "When did the Titanic sink?" or "How many people died on the Titanic?" We then generate and store embeddings for these question pairs and chunks.
This method creates a smart overlap. When a user asks a query, it is far more likely that it will semantically match one of our idealized questions instead of one of the raw chunks of text. It is as if we are creating many "semantic entry points" to each article and thus are increasing the chances of a strong match.
I have discovered this concept to be particularly fascinating, as it takes advantage of the way humans naturally explore information. We naturally come to knowledge with questions in mind, rather than attempting to get in sync with simple statements. QuOTE successfully introduces that human-centered approach into our embedding strategy.
2. QuOTE Core Idea and Architecture
The central hypothesis in QuOTE is straightforward:
"Chunks are better represented by the questions they can answer than by their content alone."
This idea is interesting to me because it's how we handle information in real conversation. The worth of valuable content is not just what it says, but what questions it can answer.
The Three Steps of QuOTE
Let's discuss how QuOTE actually works. The process consists in three main steps:
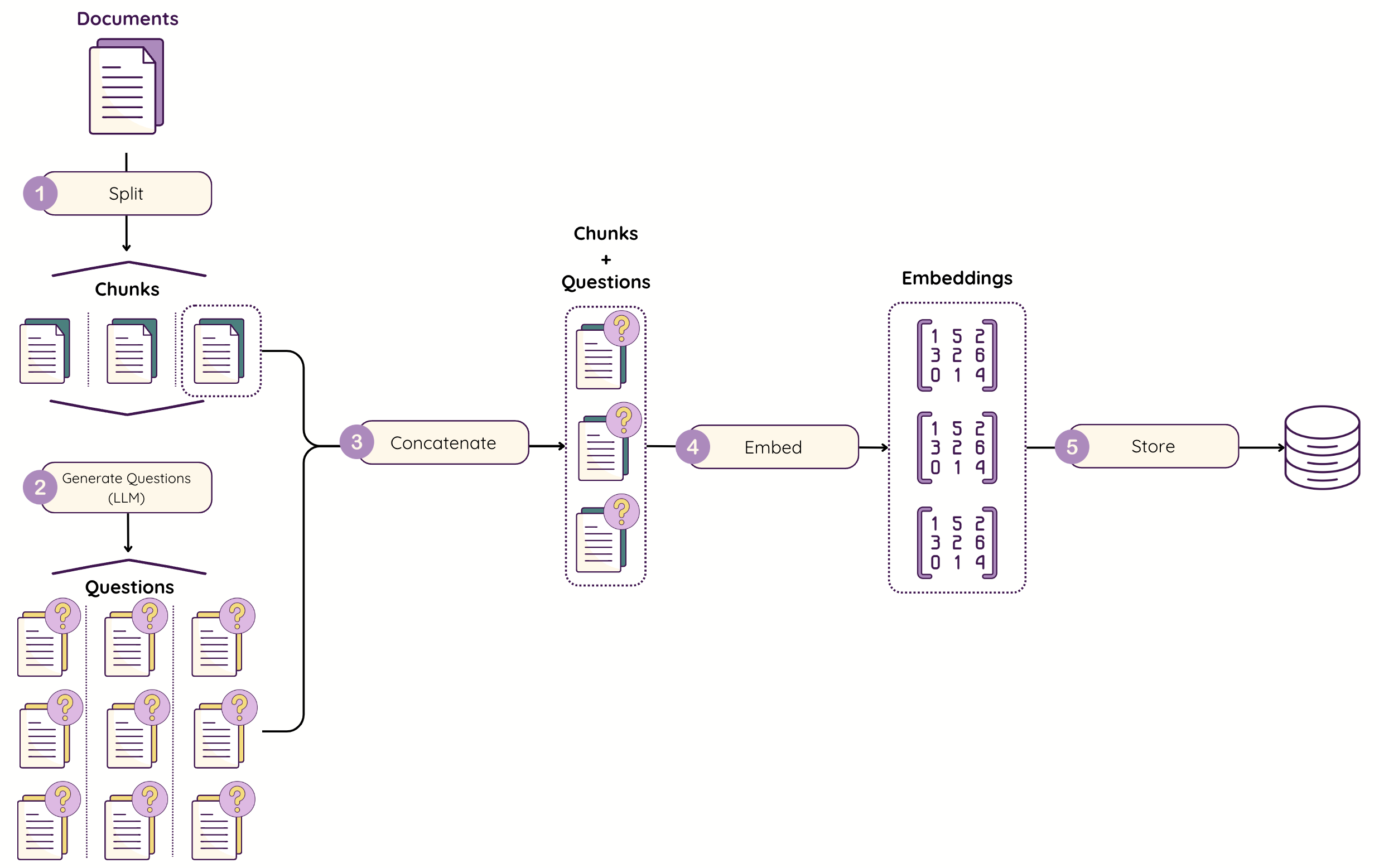
Dividing the Corpus and Generating Questions. We first split our documents into manageable pieces, similar to what is done in conventional RAG. However**,** for every piece, we use an LLM to generate multiple different questions that this specific piece may reasonably answer. These are not arbitrary questions, but instead thoughtful, well-considered**,** and realistic questions that shed light on different facets and aspects of the content of the piece.
Embedding and Storage. After we have our questions, we create a set of "mini-documents" by pairing each generated question with its relevant chunk. We then embed the question-chunk pairs using our target embedding model. This means that rather than a single embedding per chunk, we now have multiple (typically 5-15) embeddings of the same chunk, each being associated with a different question point of view.
Retrieval and Deduplication. When the user submits a query, we embed it and search for the nearest neighbours in our vector database. Because we've generated several question-chunk pair embeddings per underlying chunk, we can now retrieve various question views all pointing to that same chunk. In order to not have redundancy, we do a deduplication step so that our final output contains only the top-k distinct chunks regardless of whether they were retrieved using varying question-based embeddings or not.
3. Implementation Details
Having worked through the conceptual framework, let's roll up our sleeves and look at how to implement QuOTE in practice.
Algorithmic Walkthrough
Algorithm 1: QuOTE Index Construction
The indexing phase is where most of the unique QuOTE work happens.
Step by step:
Chunk your corpus: Begin by breaking up your documents into chunks. Chunk sizes of 200-500 tokens work well in my experience for the majority of use cases, but you may need to vary this based on the nature of your content. Chunks that are too small won't contain sufficient information to answer key questions. Chunks that are too large will mean the questions that get created end up being too broad.
Generate questions: For every chunk, prompt a cheap LLM (I use GPT-4o-mini) to generate 5-15 fictional questions the chunk could potentially answer. These questions should be high quality, and it is worth taking the time to craft a good prompt for them. You are looking for varied, specific, representative questions of what users would actually ask regarding this information.
Concatenate every question with its corresponding chunk of text. I simply use a straightforward format, such as "QUESTION? CHUNK", but you can experiment with different delimiters or formats if you wish. The key is consistency.
Embed and store: Pass each question-chunk pair through your embedding model, and save the resultant vector in your vector database. Be sure to add metadata that identifies the original chunk ID; this will be important for the deduplication step to follow.
def build_quote_index(corpus, llm, embed_model, vectorDB, num_questions=10):
chunks = split_corpus(corpus)
for chunk_id, chunk_text in enumerate(chunks):
questions = llm.generate_questions(chunk_text, num=num_questions)
for q in questions:
combined = f"{q.strip()} [SEP] {chunk_text}"
emb = embed_model(combined)
metadata = {"chunk_id": chunk_id, "original_text": chunk_text, "question": q}
vectorDB.add_embedding(emb, metadata)
return vectorDB
In practice, question generation is typically the most time expensive step in the process, particularly for large corpora. It is a good practice to batch these operations.
Algorithm 2: Querying the QuOTE Index
The query time is where we get to reap the benefits of our question-augmented indexing:
Embed the user query using the same embedding model you've used during indexing.
Over-retrieve the top
k * Mmatches from the vector database. The multiplierM(typically 2-4) is employed to compensate for the fact that we will be removing duplicate results afterward. If you want 5 final chunks, you might retrieve 15-20 question-chunk pairs to start.Deduplicate results that point to the same underlying chunk. This provides a richness in your final results, even if various question angles from one chunk matched well with the query.
Pick the final k unique chunks that will serve as prompts to your LLM. These contexts will be used for generating the final answer.
def quote_query(user_query, embed_model, vectorDB, k=5, M=3):
q_emb = embed_model(user_query)
# Over-retrieve
retrieved = vectorDB.search(q_emb, limit=k*M)
# Deduplicate by chunk_id
unique = deduplicate_by_chunk_id(retrieved)
# Pick final K after dedup
final_contexts = unique[:k]
# Combine top-k contexts with user query
answer = call_LLM(user_query, final_contexts)
return answer
Deduplication is necessary; otherwise, you could be left with numerous question-chunk pairs, all pointing to the same underlying content, thereby limiting the diversity and range of your retrieved contexts.
Prompt Engineering for Question Generation
The performance of the retrieval is directly affected by the quality of your generated questions, so it's worth taking the time to craft good prompts. Here the two prompts used in the official paper:
Basic Prompt:
Generate numerous questions to properly capture all the important parts of the text. Separate each question-answer pair by a new line only; do not use bullets. Format each question-answer pair on a single line as 'Question? Answer' without any additional separators or spaces around the question mark. Text:\{chunk_text\}
Complex Prompt:
Read the following text and generate numerous factual question-answer pairs designed to resemble authentic user search queries and natural language variations. Each question should accurately and semantically capture important aspects of the text, with varying lengths and complexities that mirror real-world search patterns. Include both shorter, keyword-focused questions such as 'who founded Tesla Motors' and longer, natural style questions like 'when did Elon Musk first start Tesla company'. Incorporate 'how' and 'why' questions to reflect genuine user curiosity. Avoid using phrases like 'according to the text' and abstain from pronouns by specifying names or entities. Ensure questions are not overly formal or artificial, maintaining a natural query style. Immediately follow each question with its precise answer on the same line, formatted as 'Question? Answer', without any additional formatting or commentary. Each pair should be on its own line. Text:\{chunk_text\}
MultiHop Complex Prompt
Read the following text and generate complex, multi-hop questions that require integrating multiple pieces of information from the text to answer. The questions should involve reasoning and synthesis, referring to different parts or aspects of the text. Do not use phrases like 'according to the text', 'mentioned in the text', or 'in the text'. All questions should be one sentence long. Never use pronouns in questions; instead, use the actual names or entities. Format each question on a single new line as Question? Answer without any additional separators or spaces around the question mark. Text:\{chunk_text\}
Remember that some domains may require different types of questions. Technical writing may require more "How to" questions, but history may require "Why" and "What impact" questions.
Deduplication: Why It Matters
Since each chunk is embedded as a huge number of question-based embeddings, you'll likely encounter the same underlying chunk multiple times during search. That redundancy is not a flaw but a virtue—it means that you've established multiple pathways to find the same pertinent content. But you certainly don't wish to deluge your final results with duplicates. A straightforward deduplication technique is to store a chunk_id in the metadata for each question-chunk embedding. During retrieval, you can group by chunk_id and only return the top-scoring match for each unique chunk.
def deduplicate_by_chunk_id(results):
seen_chunks = set()
unique_results = []
for result in results:
chunk_id = result.metadata["chunk_id"]
if chunk_id not in seen_chunks:
seen_chunks.add(chunk_id)
unique_results.append(result)
return unique_results
In some cases, you might prefer a more sophisticated path that also considers relevance score along with chunk diversity. For instance, if two chunks have highly similar content (e.g., overlapping paragraphs in the same document), you would prefer to deduplicate based on content similarity rather than raw chunk ID.
Implementation Tips
Embedding Model Selection: I've tested QuOTE with various embedding models (OpenAI's
text-embedding-ada-002,text-embedding-large-3and Cohere's embeddings). While performance varies, the relative improvement of QuOTE over naive RAG remains consistent across all of them. This is confirmed in the paper evaluations and suggests the approach is robust to your choice of embedding backend.Index Growth Management: Since each chunk is now represented by N question-based embeddings, your index will be approximately N times larger than with naive RAG. This can impact storage requirements and search latency. I typically recommend starting with 5-10 questions per chunk and only increasing as needed.
Prompt Quality: Time spent perfecting your question generation prompt pays dividends. Analyze the generated questions periodically to ensure they're diverse and representative of real user queries. Don't hesitate to refine your prompt based on user queries.
Chunk Size Considerations: QuOTE works best if chunks are properly sized for question generation. If too small, there isn't enough content to create helpful questions. If too large, questions end up too general.
Generation Models: Any skilled LLM can be a question generation model, but I have found it works best with models that have good instruction-following ability (like GPTs models or Claude), as they produce more diverse and naturally phrased questions, especially for non-english texts.
4. Empirical Evaluation: Benchmarks and Key Metrics
Theory is one thing, but does QuOTE actually deliver better results in practice? Let's look at the evaluations provided in the paper.
Datasets and Benchmarking
To test QuOTE thoroughly, the paper authors ran it on a number of popular question answering datasets:
SQuAD (Stanford Question Answering Dataset) is a very popular single-hop QA dataset, where questions are drawn from specific passages of Wikipedia. This evaluates simple retrieval skills, as answers are properly articulated within a single paragraph.
Natural Questions (NQ): A dataset of real Google search queries with Wikipedia answers. The questions here weren't created with target paragraphs like in SQuAD, thus more accurately capturing real-world questions.
MultiHop-RAG: It is a dataset that is specially created to test the situations where answering necessitates linking information between various documents. It is utilized to test QuOTE on more intricate information needs.
For each dataset, they compared three approaches:
Naive RAG with default chunk embeddings
HyDE, Hypothetical Document Embeddings
QuOTE with varying number of generated questions per chunk
Metrics
In order to accurately measure performance, standard retrieval evaluation measures were employed:
Context Accuracy (C@k): The percentage of questions for which the correct paragraph containing the answer is within the top-k retrieved documents. This is a direct measure of retrieval performance.
Title Accuracy (T@k): The percentage of questions where the correct article title appears in the top-k responses. This is useful for data like Natural Questions where the specific paragraph is not always provided, but the correct article is known.
Full/Partial Match Precision: For multi-hop tasks, I tracked whether all required documents were retrieved (full match) or some of them (partial match).
Additionally, they measured:
Index size increase
Indexing time overhead
Query latency impact
Performance Highlights
The performance remained very strong throughout datasets and settings:
On SQuAD, QuOTE obtained a +5–17% increase in top-1 context accuracy over naive chunk embeddings. This dramatic improvement implies that for well-formed questions with clear answers, the question-oriented approach establishes considerably stronger semantic connections.
On Natural Questions, gains were lower but still substantial, with a gain of +1–3%. This reduced gain likely explains the heterogeneity and occasional ambiguity of real search queries. But even here, QuOTE outperformed the naive approach consistently.
On multi-hop tasks, QuOTE demonstrated considerable improvements under both partial and full match conditions. This makes sense intuitively; by formulating questions that address the content at different angles, QuOTE increases the likelihood of covering the various components necessary for multi-hop reasoning.
Comparison with HyDE
It's worth explaining how QuOTE differs from HyDE (Hypothetical Document Embeddings), a different approach to bridging the semantic gap of retrieval. HyDE takes a different strategy. When it receives a query, it first asks a large language model to generate a hypothetical document that would answer the question. It then embeds this fictional document and uses that embedding for retrieval. This strategy encourages better alignment with the real documents in the corpus compared to embedding the query itself. Although HyDE and QuOTE are trying to address similar issues, they incur their computational costs at different times:
| Approach | Pros | Cons |
| Naive RAG | No overhead, simple implementation | Weaker retrieval performance on ambiguous queries |
| HyDE | Strong coverage of query semantics, generated on-demand | Higher query latency, per-query LLM generation cost |
| QuOTE | High coverage of content semantics, low query overhead | Larger index size, one-time question generation cost |
In my experiments, QuOTE tended to equal or out-performed in terms of accuracy versus HyDE at nearly identical query latency versus naive RAG. QuOTE is thereby particularly appropriate for application domains in which query response time is particularly vital.
5. QuOTE Disadvantages and Limitations
Although QuOTE has been successful in my testing, it is not flawless:
In highly specialised domains, general LLMs may create questions that are too general or fail to grasp the specific nuances of the field. Think of highly technical domains such as quantum physics or intricate legal documents; the questions generated may not grasp the exact manner in which experts would inquire about this knowledge. In such instances, you may have to adjust your question generation model or use more specialised prompts.
For keyword-based queries only or very broad topical searches, the advantage of question-based embeddings might be less pronounced. If individuals are merely searching for "python tutorial" or "climate change," the semantic aspect of questions takes a back seat. Traditional information retrieval techniques might work just as well for these use cases.
QuOTE introduces additional complexity into the indexing pipeline. This additional complexity needs to be traded off against retrieval improvement, especially for smaller or less complicated applications. The growth in the index size—roughly N times larger for N questions per chunk—can be undesirable, particularly for very large corpora or in resource-constrained environments.
When to Use QuOTE
From my experience of using QuOTE on various proof of concepts, I've found it most useful when:
Your application includes single or multi-hop question answering tasks in which users are trying to find specific information instead of perusing topics.
You see users typing brief or vague queries that, although semantically similar, do not match the documents' content very well.
You are faced with query latency requirements that render query-time approaches such as HyDE far less feasible.
Your search query would be enhanced by more precision in the top-ranked retrieved documents.
QuOTE is not the answer to every retrieval issue, but it is a solution to one of the significant flaws in plain RAG implementations and provides a simple solution to enhance retrieval with no query-time overhead.
6. Best Practices and Tips in Action
Having implemented QuOTE across different proof of concepts, I've accumulated some practical insights that might help you get the most out of this approach. Here are my best practices for effective implementation:
1. Optimal Number of Generated Questions
One of the first decisions you will be making is how many questions to generate per chunk. More questions have better coverage of the content of the chunk, but also larger index size and indexing cost.
In my empirical analysis, I routinely find that 5–10 questions per chunk is the sweet spot for most applications. As we go beyond this, I routinely find diminishing returns on retrieval performance even as storage requirements increase linearly.
That being said, the ideal number would depend on:
The depth and sophistication of the data in your segments.
The variety of possible queries from users.
- Your computational and storage resources
If your chunks are packed with heavily loaded information on several subtopics, you might require additional questions. If your chunks contain individual concepts, fewer questions might be adequate.
I recommend starting at 5 questions per batch and performing A/B testing with different quantities to figure out what will work optimally for your specific use case.
2. Ensuring Diversity in Generated Questions
It is crucial to the success of QuOTE that questions are of high quality and varied. You require questions that address various aspects of the content from numerous angles.
Here's a prompt strategy I've found especially useful:
Prompt:
"You are an expert in educational content development. For the following text passage, generate 10 diverse questions that this passage can answer.
Your questions should include:
- 2-3 basic factual questions (who, what, when, where)
- 2-3 analytical or explanatory questions (why, how)
- 2-3 questions that connect concepts within the passage
- 1-2 questions about implications or applications of the information
Make sure the questions vary in complexity and phrasing, and that they cover different aspects of the passage. Phrase them naturally as a human would ask."
Occasionally check the questions produced to make sure they're varied and representative of how users may actually ask for your content. If you find repetition patterns or coverage gaps, adjust your prompt accordingly.
7. Future Directions & Limitations
Although QuOTE is a great improvement over naive RAG, there are numerous promising ways to improve it.
Adaptive Question Generation
An intriguing next step would be to learn from real user queries and increasingly improve your generated questions. Imagine the process of analyzing your query logs to identify patterns in the manner in which users actually ask about your content, and subsequently using those patterns to improve subsequent question generation. This might create a feedback cycle where your retrieval system becomes better and better informed about the distinctive tastes of your particular user community.Hybrid Approaches
Hybridizing QuOTE with classical retrieval systems such as BM25 or entity linking can create even more powerful retrieval pipelines. For example, a weighted combination of semantic similarity from QuOTE and keyword matching from BM25 can combine the best of both approaches.Another promising direction involves integrating QuOTE with reranking approaches. By utilizing QuOTE for the initial retrieval, one can then apply a more computationally intensive reranker to refine the results.
Scaling & Index Efficiency
As mentioned earlier, QuOTE increases your index size by a factor roughly equal to the number of questions per chunk. In large applications, this increase can be troublesome. More advanced deduplication methods, compression methods, or even more careful question generation could mitigate this increase.An intriguing approach to explore is to generate questions just for those portions which have complex or unclear information, and utilizing normal embeddings for more straightforward factual portions.
Limitations to Consider
Domain Complexity: General LLMs might not be able to generate appropriate questions for highly technical or specialised domains without domain-specific fine-tuning.
Multi-hop Complexity: Although QuOTE enhances multi-hop retrieval, more complex chains of reasoning may still necessitate additional specialised retrieval methods.
Long-tail Queries: Very unusual queries might still struggle if they don't align well with the generated questions.
Computational Cost: There is a potentially high cost to generating questions for large corpora upfront but amortized over all future queries. As with any method, it is critical to continually examine if QuOTE is delivering value for your specific use case and your users' requirements
As with any technique, it's important to continually evaluate whether QuOTE is delivering value for your specific use case and user needs.
10. Conclusion: QuOTE's Role in the Evolving RAG Landscape
When I first implemented RAG systems last year, I was struck by how significantly they enhanced LLM outputs, yet I found myself frustrated by the ongoing limitations in retrieval. QuOTE emerged as one of those concepts that, in hindsight, appears obvious but proves to make a remarkable difference in practice.
Key Takeaways
Core Value: QuOTE revolutionizes our strategy for representing content for retrieval by focusing on "what questions can this content answer" rather than simply "what is this content about". This shift aligns our index more closely with how users actually search for information.
Index Once, Query Fast: By shifting the cost of generation to index time, QuOTE allows for low query latency while still reaping the rewards of the semantic richness afforded by LLM-generated content. This characteristic makes it ideally suited for production applications demanding high standards of latency.
Empirical Validation: QuOTE shows substantial improvements in retrieval effectiveness, especially for hard queries, on a number of benchmarks and in real use.
QuOTE's Larger Implications
Apart from its immediate practical utility, QuOTE represents a fundamental conceptual shift in our retrieval approach for AI utilisation. It implies that index-time enrichment can be just as valuable as advanced prompt engineering at query time. In many ways, QuOTE represents a broader direction in AI engineering: finding clever ways to move complexity to where it is less expensive - e.g., index time instead of query time - to maintain or improve quality. It is a template for the next generation of retrieval systems that interact more consonantly with how humans search for information.
As large language models are evolving, the bottleneck in most AI applications is moving away from generation quality to retrieval accuracy. Techniques such as QuOTE, which target this bottleneck specifically, can be expected to assume a more critical position in the context of AI applications
Closing Thoughts
As you integrate RAG into your systems, I would suggest that you ask yourselves if question-targeted embeddings could be utilised to close the gap between questions asked by your users and the content of your knowledge base. The extra effort at the indexing stage is often rewarded in the quality of retrieval much greater than the initial effort.
Good luck, and happy building!
Subscribe to my newsletter
Read articles from Irene Burresi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Irene Burresi
Irene Burresi
🚀 𝗗𝗮𝘁𝗮 𝗦𝗰𝗶𝗲𝗻𝘁𝗶𝘀𝘁 | 𝗔𝘀𝗽𝗶𝗿𝗶𝗻𝗴 𝗔𝗜/𝗔𝗜𝗢𝗽𝘀 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿 I am Data Scientist. With a strong technical background, I am currently specializing in AIOps. 👩💻 𝗧𝗲𝗰𝗵𝗻𝗶𝗰𝗮𝗹 𝗦𝘁𝗮𝗰𝗸 𝗗𝗮𝘁𝗮 𝗦𝗰𝗶𝗲𝗻𝗰𝗲: I have worked on various time series analyses and classification tasks. My main focus is on NLP and advanced use of Large Language Models (LLMs) with RAG and fine-tuning techniques. 𝗣𝗿𝗼𝗴𝗿𝗮𝗺𝗺𝗶𝗻𝗴 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲𝘀: Following a bottom-up approach, I laid a solid foundation by studying low-level languages (C) and then moved on to Java, Typescript, and Python. 𝗗𝗲𝘃𝗲𝗹𝗼𝗽𝗺𝗲𝗻𝘁 𝗠𝗲𝘁𝗵𝗼𝗱𝗼𝗹𝗼𝗴𝗶𝗲𝘀: I am a strong advocate of Test-Driven Development (TDD) and the application of SOLID and DRY principles. I also enjoy studying and applying design patterns wherever possible. 𝗖𝗹𝗼𝘂𝗱 𝗣𝗹𝗮𝘁𝗳𝗼𝗿𝗺𝘀: I have experience with both AWS (especially for developing serverless microservices using Lambda, SQS queues, and API Gateway) and Azure (mainly OpenAI and Document Intelligence). 🔍 𝗖𝘂𝗿𝗿𝗲𝗻𝘁𝗹𝘆 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴: 𝗔𝗜: AI is such a vast field that I can never fully explore it. Currently, I am focusing on various papers that illustrate the progress made in recent months with LLMs. 𝗔𝗜𝗢𝗽𝘀: This is the area of AI that I am most passionate about and where I feel I am most suited. I am acquiring specific certifications and strengthening my skills in Infrastructure as Code (IaC) and Continuous Integration/Continuous Deployment (CI/CD). 💡 𝗣𝗿𝗼𝗳𝗲𝘀𝘀𝗶𝗼𝗻𝗮𝗹 𝗣𝗵𝗶𝗹𝗼𝘀𝗼𝗽𝗵𝘆: I firmly believe in the importance of an agile and "production-first" approach, even for AI projects. By applying agile methodologies, I promote the rapid development and release of functional MVPs to accelerate stakeholder feedback, clarify misunderstandings that often lead AI projects to fail prematurely, and refine products through continuous iterations. My mission focuses on bridging the gap between the development of AI models and their operational implementation, emphasizing feedback loops and retraining.