Scaling Metadata Extraction with AI: My Experiment with Google Colab, Internet Archive & IGSL at UC Berkeley
 Nick Norman
Nick Norman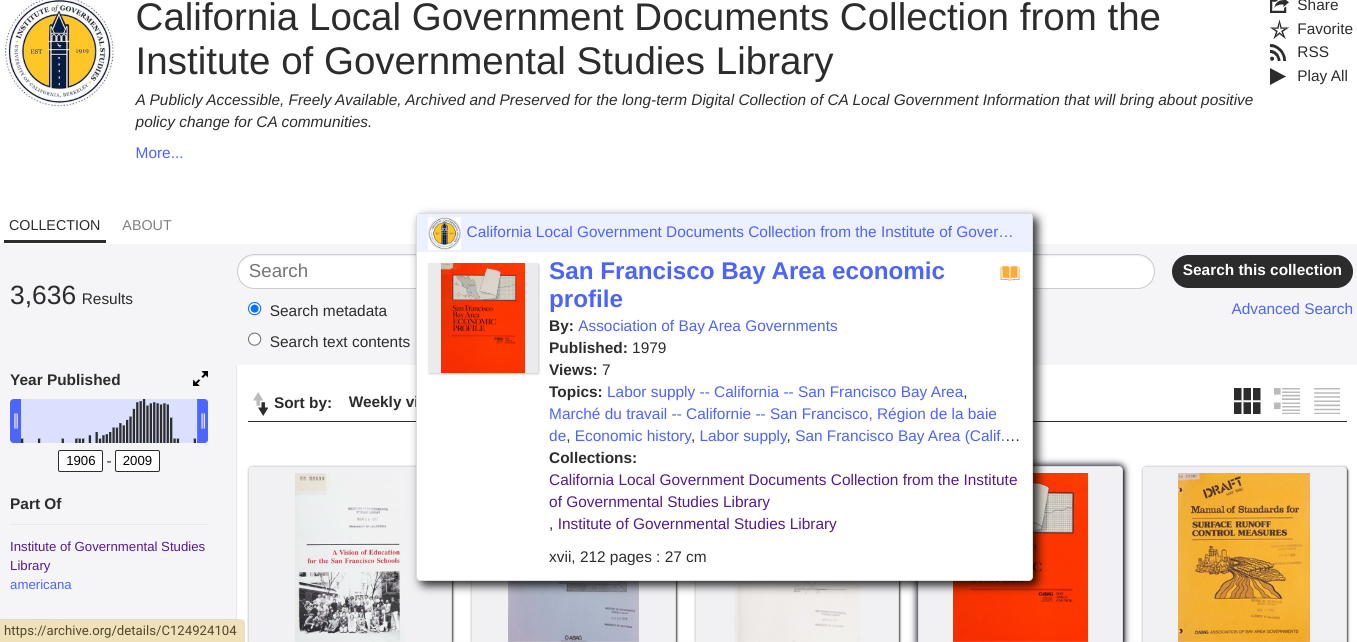
While AI tools like ChatGPT can do a lot for an individual, the real power lies in automating and scaling these capabilities into workflows for universities, libraries, organizations, and large projects—and metadata extraction is a perfect example.
To test this, I’ve been experimenting with UC Berkeley’s Institute of Governmental Studies Library (IGSL), which houses a large collection of historical documents. However, this approach isn’t limited to one library or one collection—it can be applied broadly to any large-scale document archive.
The Challenge: Extracting Metadata at Scale
Within the Berkeley collection—archived at the Internet Archive—there are thousands of documents, and more are being added regularly. Manually extracting metadata for all these files would be impossible—this is where automation comes in. By leveraging APIs and AI, we can continuously scan, extract, and store metadata without human intervention.
To solve this challenge, I used Internet Archive’s Developer Page. They provide APIs that allow developers to access metadata, search collections, and automate retrieval. From there, I used Google Colab—a cloud-based Python environment—to write and test scripts that:
Scans all documents in the collection (from the first ever added to the most recent)
Extracts relevant metadata from each item or document in the collection
Continuously tracks new additions and automatically processes them
Stores the metadata in Google Sheets for easy access
With this setup, I don’t have to manually check for new documents—the script runs daily, fetches metadata for new items, and logs everything automatically.
Customizing Metadata Extraction with AI
The cool part? Rather than relying on metadata provided by any-given organization, I can define exactly what metadata I want to extract. For example, I can either grab basic details such as title, author, date. Or, I can mix it up and also …
Categorize document relevance (Who is this useful for? Historians? Policy researchers?)
Extract in-document keywords (searching inside the document for key terms)
Generate SEO or marketing-focused keywords (targeting specific research audiences)
This means metadata can go beyond basic cataloging—it can be optimized for searchability, researcher discovery, and AI-driven analysis.
The Power of Real-Time Prompt Engineering in Google Colab
One of the unexpected benefits of using Google Colab is its ability to support real-time prompt engineering.
Since everything runs within the same environment, I can test, refine, and tweak prompts on the fly without switching between tools. This makes a huge difference when working with AI-generated metadata, because prompts can be adjusted in real time to get different results.
For example:
Instead of extracting general metadata, I could customize it by cultural perspective—pulling metadata that aligns with how different countries structure and prioritize information.
This ties into my previous work on knowledge profiles, where prompts can be adjusted to better cater to global collaboration and cross-cultural research needs. (Read more on that here.)
This ability to dynamically modify how AI interprets metadata opens up a lot of possibilities, from fine-tuning data extraction for specific fields to building culturally adaptive metadata systems.
Final Thoughts: A Simple Framework for Big Projects
This is just one example of how AI and APIs can scale workflows. Whether it’s metadata extraction, document analysis, or research tracking, this same approach can be applied to any large digital collection.
Special thanks to the Internet Archive staff, its volunteers and developer team for creating an easy-to-navigate resource that made this process possible. Also, a special thanks to IGSL at UC Berkeley for their work in the LoCalDig project, making these historical documents accessible for researchers like me.
If you're working with large-scale digital collections, I'd love to hear how you're thinking about AI-powered research automation! 🚀
Subscribe to my newsletter
Read articles from Nick Norman directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by