Vector databases: Revolutionizing AI and search
 Opcito Technologies Pvt Ltd
Opcito Technologies Pvt Ltd
In the ever-evolving world of data management, vector databases have emerged as a powerful tool for transforming how we handle and interact with complex data. But what exactly is a vector database, and why is it becoming a hot topic in fields like artificial intelligence, machine learning, and search technology? Let's explore the inner workings of this system and its place in today's data architecture.
What is a vector database?
To grasp the concept of vector databases, it's essential first to understand what vectors are. A vector is a mathematical entity that represents data as a list or an array of numbers, commonly referred to as dimensions. You can think of a vector as a point in multi-dimensional space, where each number in the array corresponds to a specific dimension.
For example, let's consider representing an image. The image can be transformed into a vector encoding features such as color, shape, texture, and more. This transformation enables comparisons with other images that go beyond exact pixel matches, instead reflecting the deeper, nuanced features of the content. In other words, vectors capture the essence of data—whether it's text, images, or audio—by converting it into a numerical form.
Characteristics of vector databases
High-dimensional data representation: Vector databases represent complex data (text, images, audio) as multi-dimensional vectors, capturing nuanced features for analysis.
Similarity-based search: Instead of exact matches, they prioritize finding semantically similar results by measuring vector distances, which is ideal for recommendations and semantic search.
Efficient search algorithms: Leveraging algorithms like Approximate Nearest Neighbor (ANN) search enables fast and scalable queries across massive datasets.
Scalability and flexibility: Designed for large-scale data, they efficiently scale with growing data volumes and support diverse data types.
Optimized for Machine Learning and AI: Storing machine learning model outputs as vectors, they are inherently optimized for AI tasks, facilitating rapid retrieval and integration.
Context-aware retrieval: They enhance search precision by considering the context of queries, going beyond keyword matching to understand intent.
Robust handling of unstructured data: Effectively managing unstructured data like images, audio, and free text they are essential for applications like image recognition and social media analysis.
Vector database flow diagram

The role of vectors in modern applications:
Enhancing search engines with semantic understanding: Vector databases power search engines that understand meaning, not just keywords, delivering more relevant results (e.g., Google's use of vectors).
Powering recommendation systems: Platforms like Netflix and Spotify use vectors to represent user preferences and content features, enabling highly tailored recommendations.
Improving Natural Language Processing (NLP): NLP applications leverage vector embeddings to understand language context and nuances, improving chatbots, translation, and more.
Revolutionizing image and video search: Vector-based image recognition and search platforms (like Pinterest and Google Images) find visually similar content, even without matching metadata.
Boosting fraud detection in finance: Financial institutions use vectors to identify fraudulent transaction patterns by analyzing millions of data points.
Personalizing healthcare with genomic data: Vectors analyze genomic data for personalized medicine, tailoring treatments based on individual genetic profiles.
Optimizing voice assistants and virtual agents: Siri, Alexa, and other voice assistants use vectors to interpret spoken language and respond accurately.
Empowering autonomous vehicles with vision and decision-making: Self-driving cars rely on vectors to process sensor data, enabling object recognition and real-time decision-making.
Retrieval-Augmented Generation (RAG): Vector databases are the backbone of RAG, enabling efficient retrieval of contextually relevant information by using similarity search algorithms. They retrieve the most contextually similar items based on the query vector, improving AI systems where semantic meaning is more important than literal keyword matching.
Leveraging vector databases for semantic search in Python
One of the most exciting advancements in developing a search system is the transition from keyword-based to semantic search. Instead of simply looking for exact matches to user queries, we can utilize vector representations of text to capture the meaning behind the words. This approach allows us to find contextually similar results rather than just lexicographically similar ones.
Step-by-step guide to building a semantic search system
Let’s break down the task of creating a vector-based search system using some simple yet effective Python tools. We’ll be working with product descriptions, converting them into numerical vectors, and using FAISS for efficient similarity search.
Step 1. Prepare your data: First, we need some sample data. For this example, imagine we have a set of product descriptions, like "leather jacket," "cotton t-shirt," and so on.
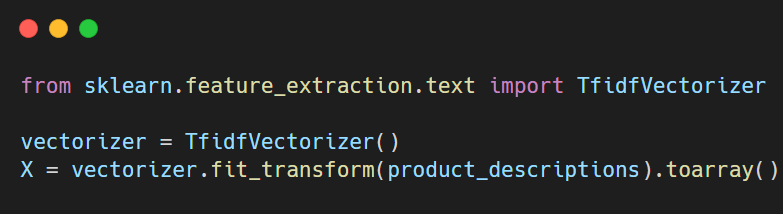
Step 2. Convert text to vectors: We need to convert these product descriptions into vectors to allow for a meaningful search. This step requires transforming the text into a numerical representation that captures the essence of each description. We'll use TF-IDF (Term Frequency-Inverse Document Frequency) to do this. It's a common technique that weighs words based on their importance across documents.
This X variable now contains the vectorized form of our text. It’s essentially a matrix where each row represents a product, and each column corresponds to a term from the vocabulary we extracted from the descriptions.

Step 3. Create the FAISS Index: Next, we’ll set up FAISS, which is a powerful library for efficient similarity searches. FAISS helps us find the most similar vectors in a high-dimensional space — perfect for our use case.
To get started, we need to create an index for our vectors. For simplicity, we'll use a flat index (meaning no approximation in search) and rely on L2 distance (Euclidean distance) for measuring similarity.
At this point, our vectorized data is indexed, and we’re ready to start performing similarity searches.

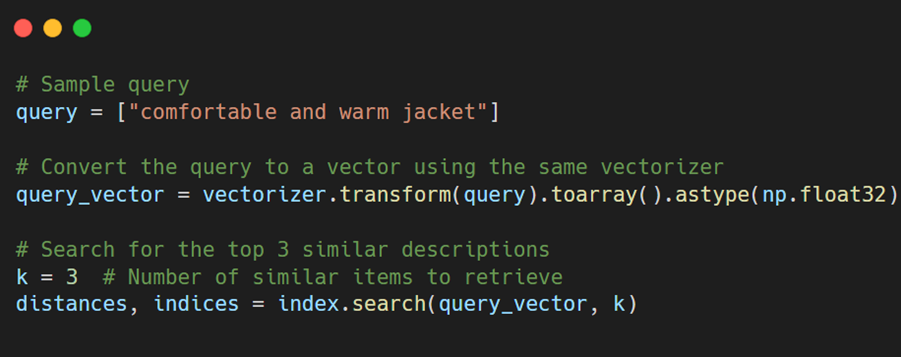
Step 4. Query the vector database: Let’s now simulate a user query. Suppose a user types in “comfortable and warm jacket.” We’ll convert this query into a vector and use FAISS to find the most similar product descriptions from our indexed data.
Here, distances tell us how close the vectors are, and indices gives us the positions of the most similar product descriptions.
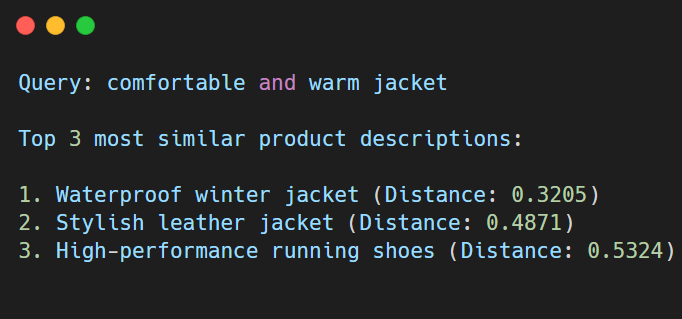
Step 5. Display the results: Finally, we can display the top k most similar product descriptions. This is the key part — presenting the results in a way that’s meaningful to the user.
Expected output:

What’s happening under the hood?
Vector representation: Each product description is transformed into a vector using TF-IDF, a method that highlights important terms in the text.
FAISS indexing: These vectors are added to a FAISS index for fast, scalable similarity search.
Querying: When a user submits a query, it is converted into a vector, and FAISS is used to find the most similar vectors in our dataset, giving us the most relevant results.
Why are vector databases so useful?
Implementing vector search like this allows for much more sophisticated query handling. Instead of relying solely on keyword matches, we can understand the meaning behind queries and content, leading to more accurate results. Whether it’s recommending products, providing search results, or even filtering content, vector databases and semantic search systems are powerful tools in modern applications.
Vector databases are a game-change for modern development
By implementing vector search in your applications, you open the door to more intelligent and context-aware systems. Whether it’s personalized recommendations, improved search results, or even content discovery, vector databases are a game-changer in how we interact with digital content.
With the simplicity of FAISS and the flexibility of Python, adding this functionality to your app or website can significantly improve user experience. And as vector search grows in popularity, it’s a powerful tool every developer should have in their toolkit. Need assistance on vector databases? Our data engineering experts will guide you in successfully building a semantic search system. Contact us to know more.
Subscribe to my newsletter
Read articles from Opcito Technologies Pvt Ltd directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Opcito Technologies Pvt Ltd
Opcito Technologies Pvt Ltd
Opcito helps startups and enterprises build cutting-edge products with Software Product Engineering, QA and Test Engineering, Cloud, DevOps and SRE expertise.