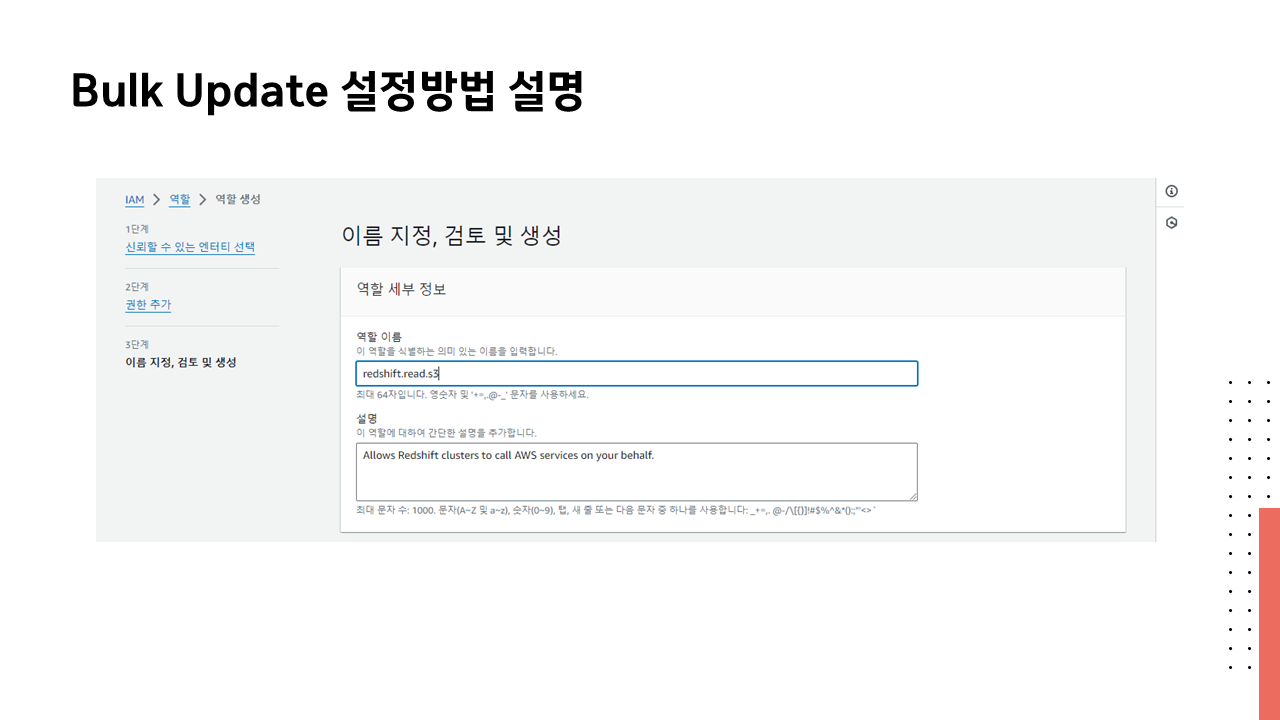
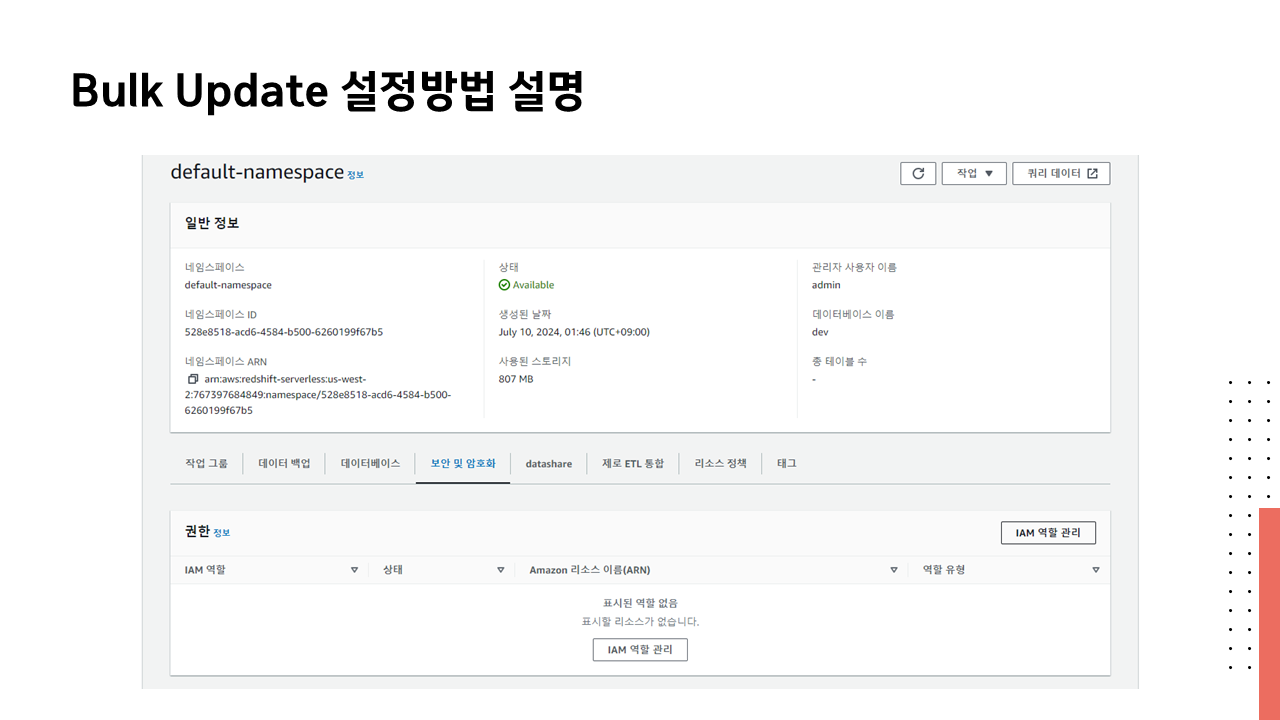
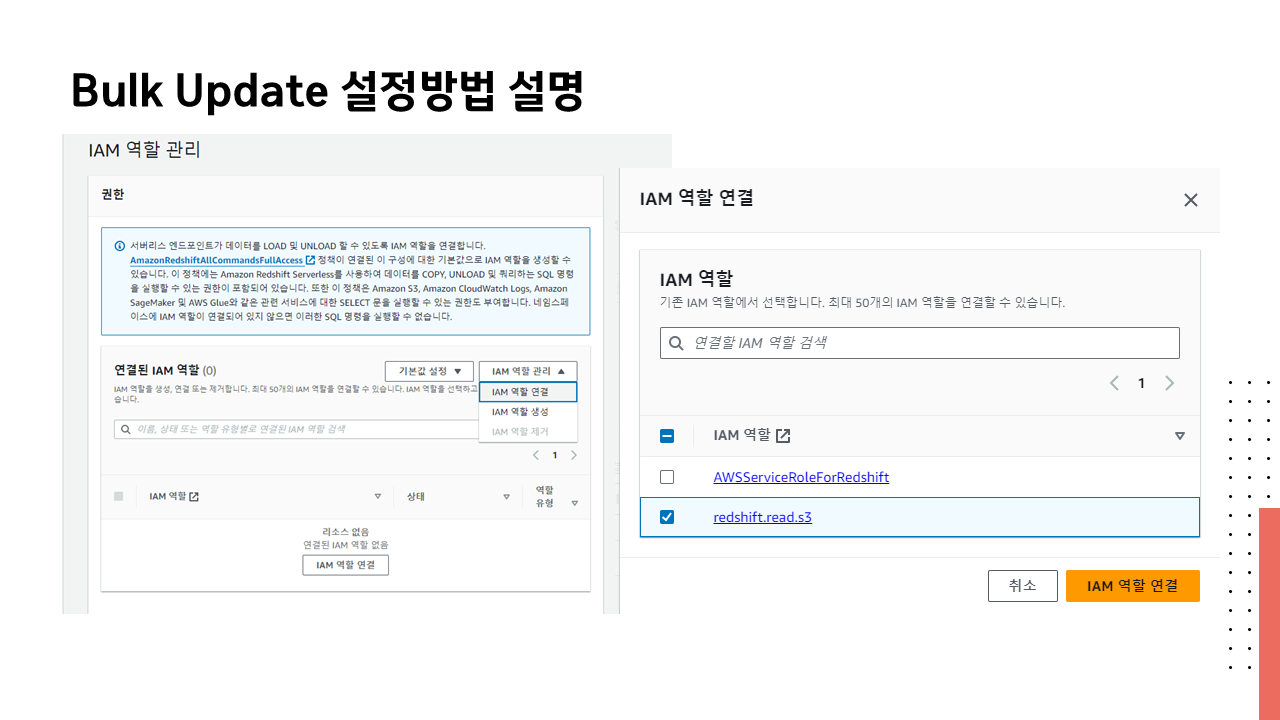
[Makers 멘토링] 2 주차 강의자료 : 데이터 웨어하우스와 SQL
 정세욱
정세욱



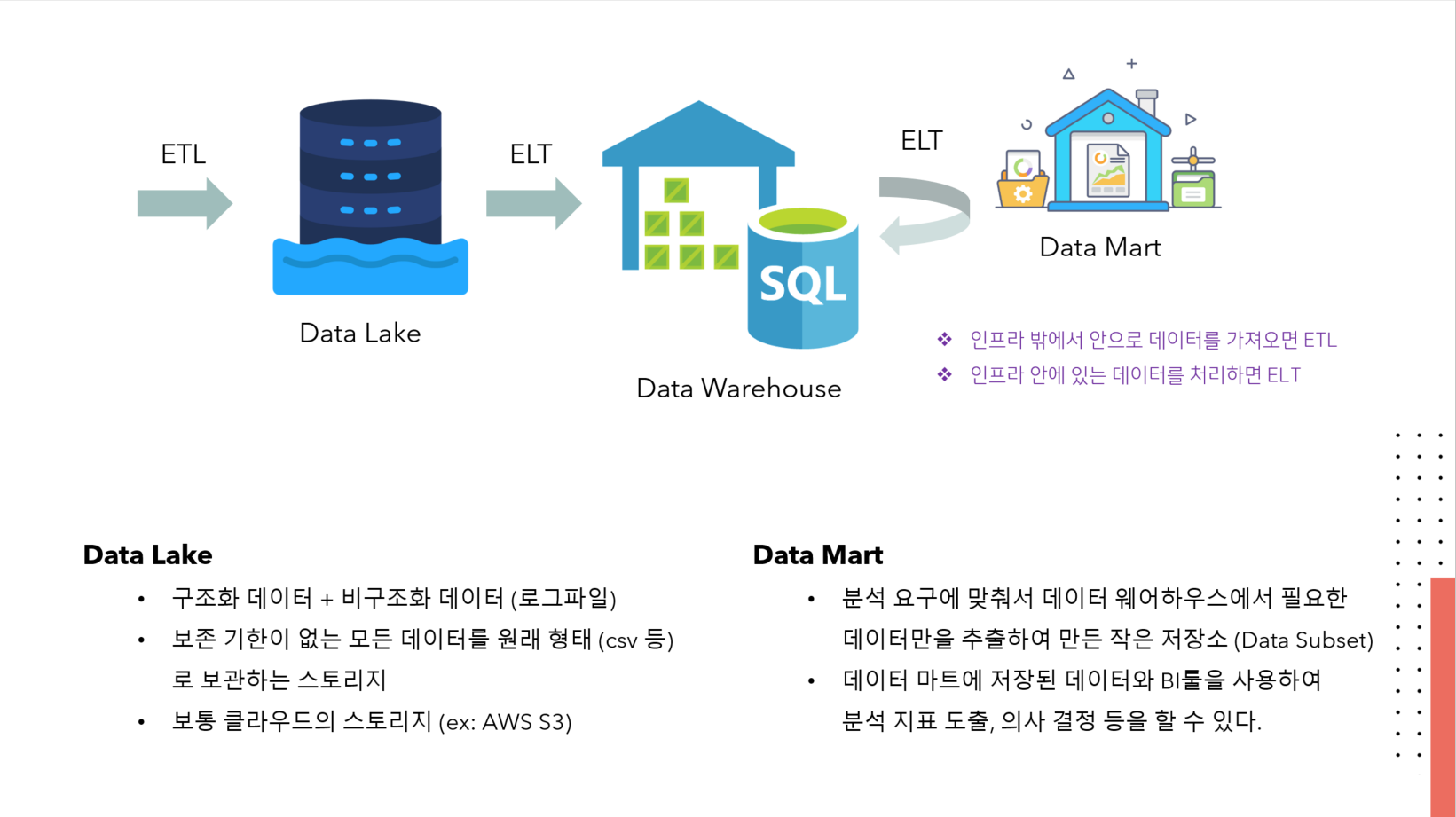
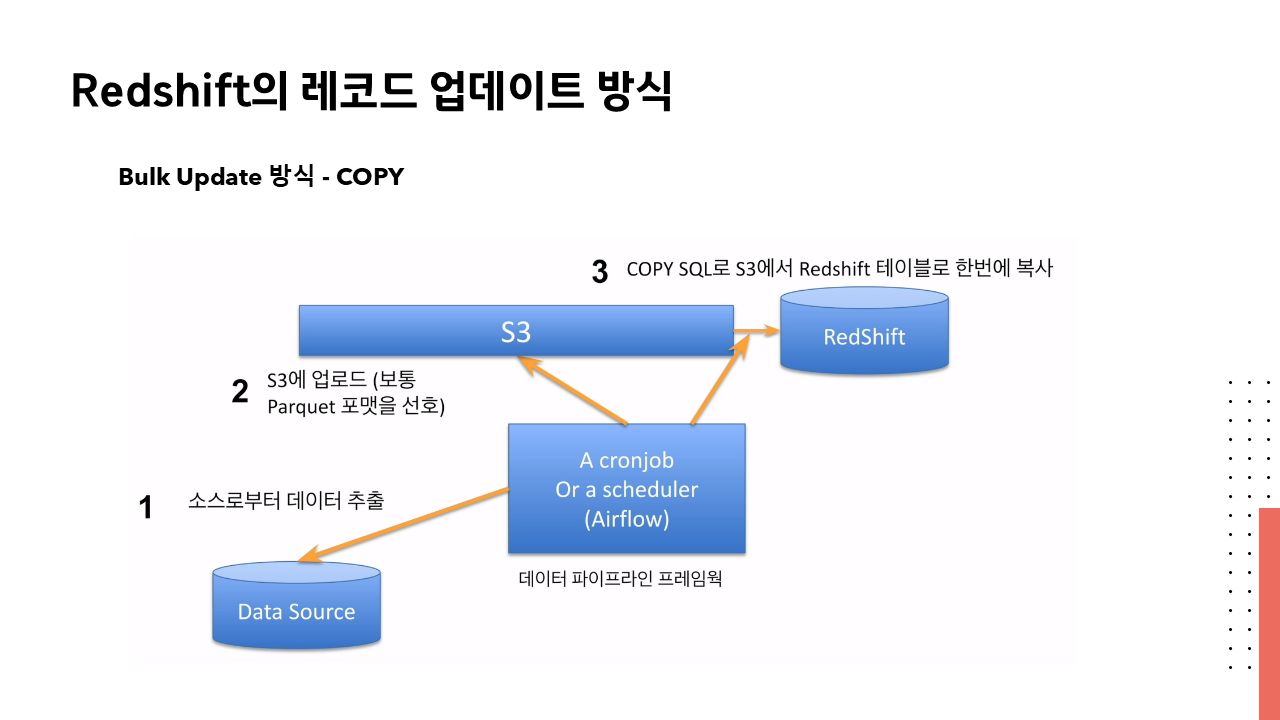
ETL은 변환(정제) 과정을 먼저 거친 후에 적재한다는 점에서 저장효율이 좋아 처음 인프라에 갖고 들어올 때 유리
ELT는 추출과 적재를 먼저 한 후에 변환은 필요할 때 진행한다. 따라서 이미 변환이 되어있는 데이터를 많이, 빠르게 가져올 때 일반적으로 사용되는 것이다. (DW에서 DM로 이동할 때 등)
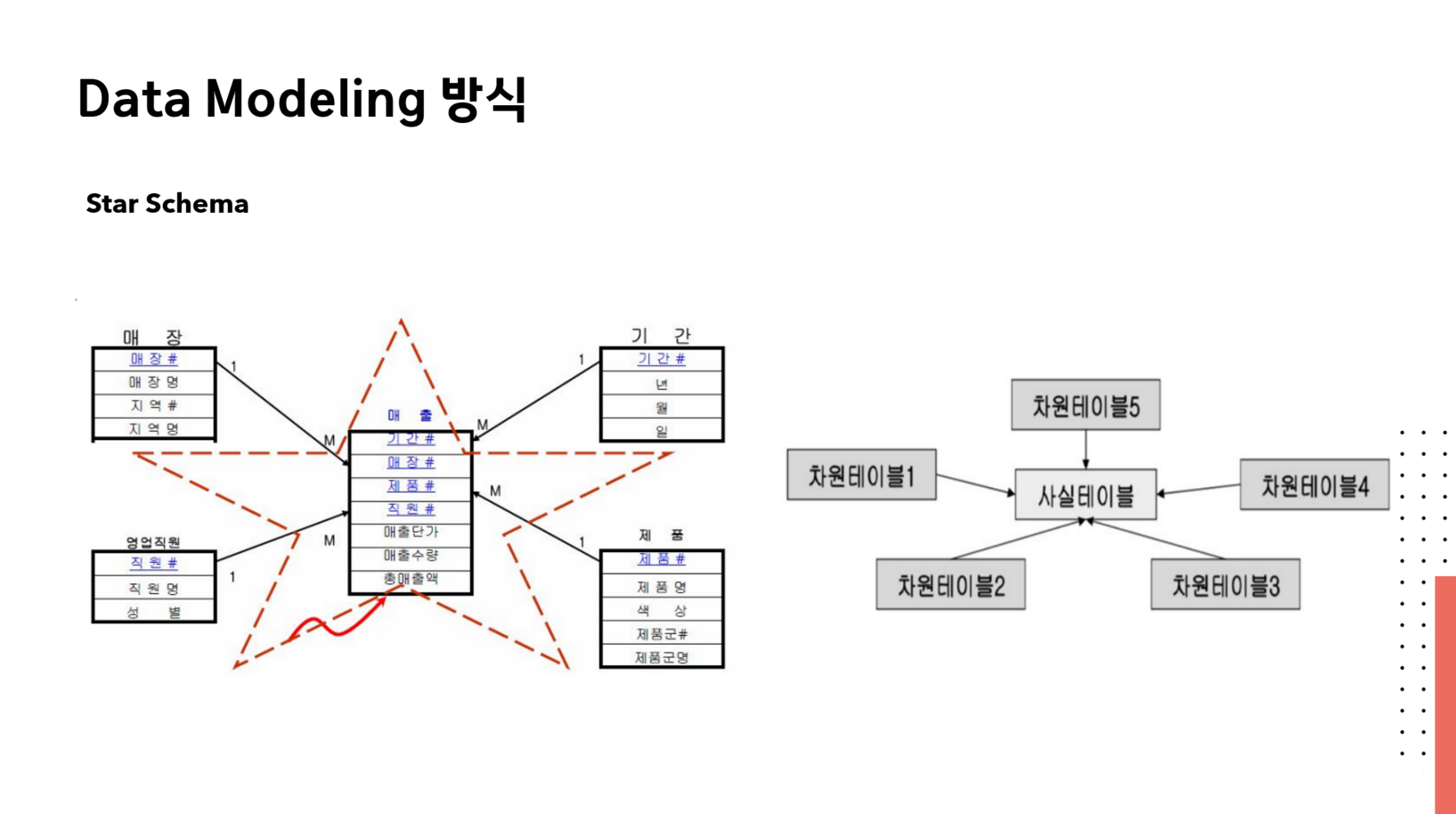

Star schema는 데이터 웨어하우스에서 가장 널리 사용되는 차원 모델링 기법 중 하나로, 중앙에 사실 테이블이 위치하고 이를 둘러싼 차원 테이블들이 별 모양으로 연결되어 있는 구조이다. → 데이터 구조를 쉽게 이해할 수 있다.
데이터 웨어하우스의 모델인만큼 데이터 분석 효율성 기준에 맞추어서 쿼리를 쉽고 빠르게 할 수 있도록 데이터의 중복을 허용하는 비정규화가 적용되어 있다.
좀 더 자세한 내용은 이곳에서 :

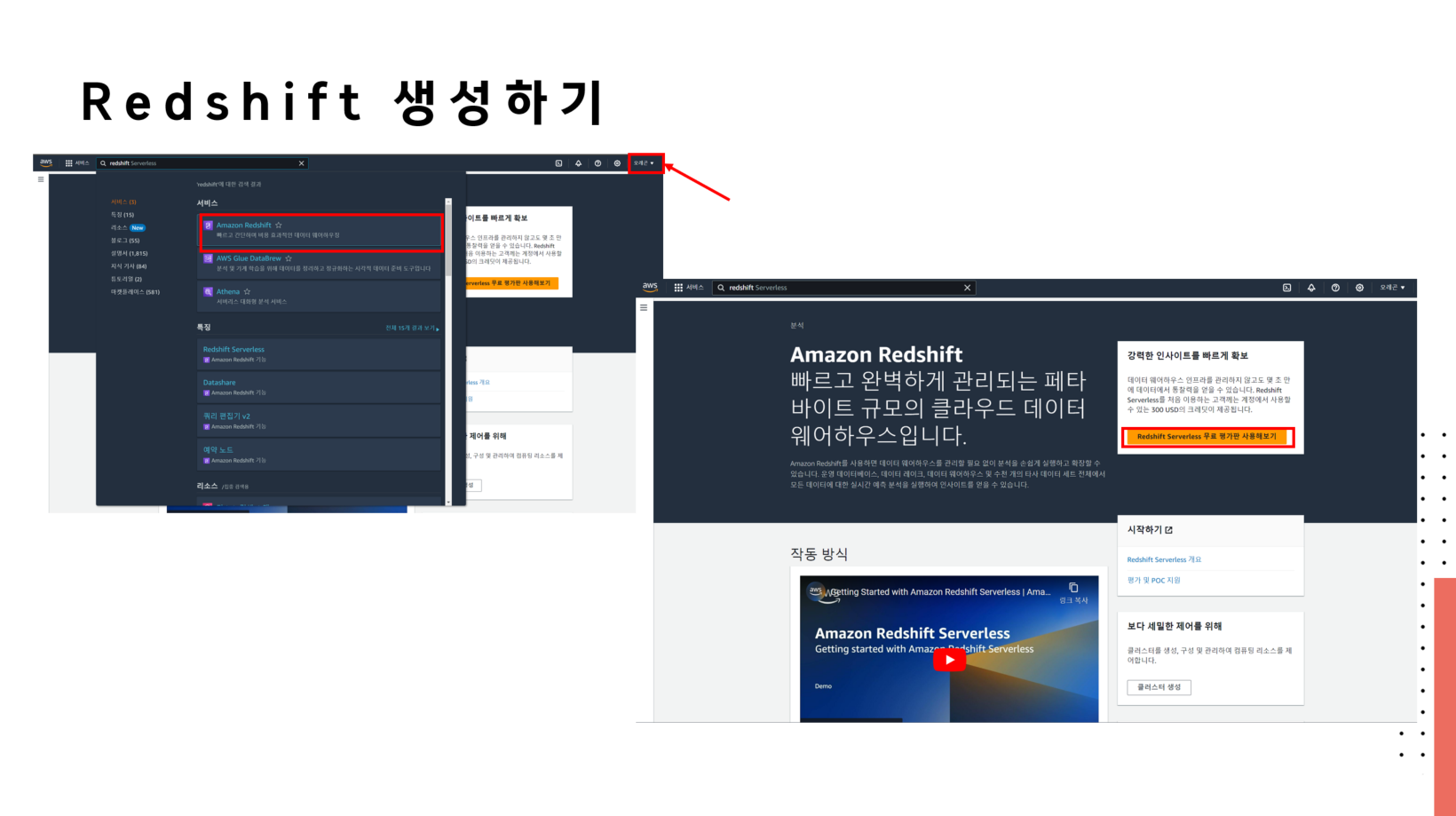
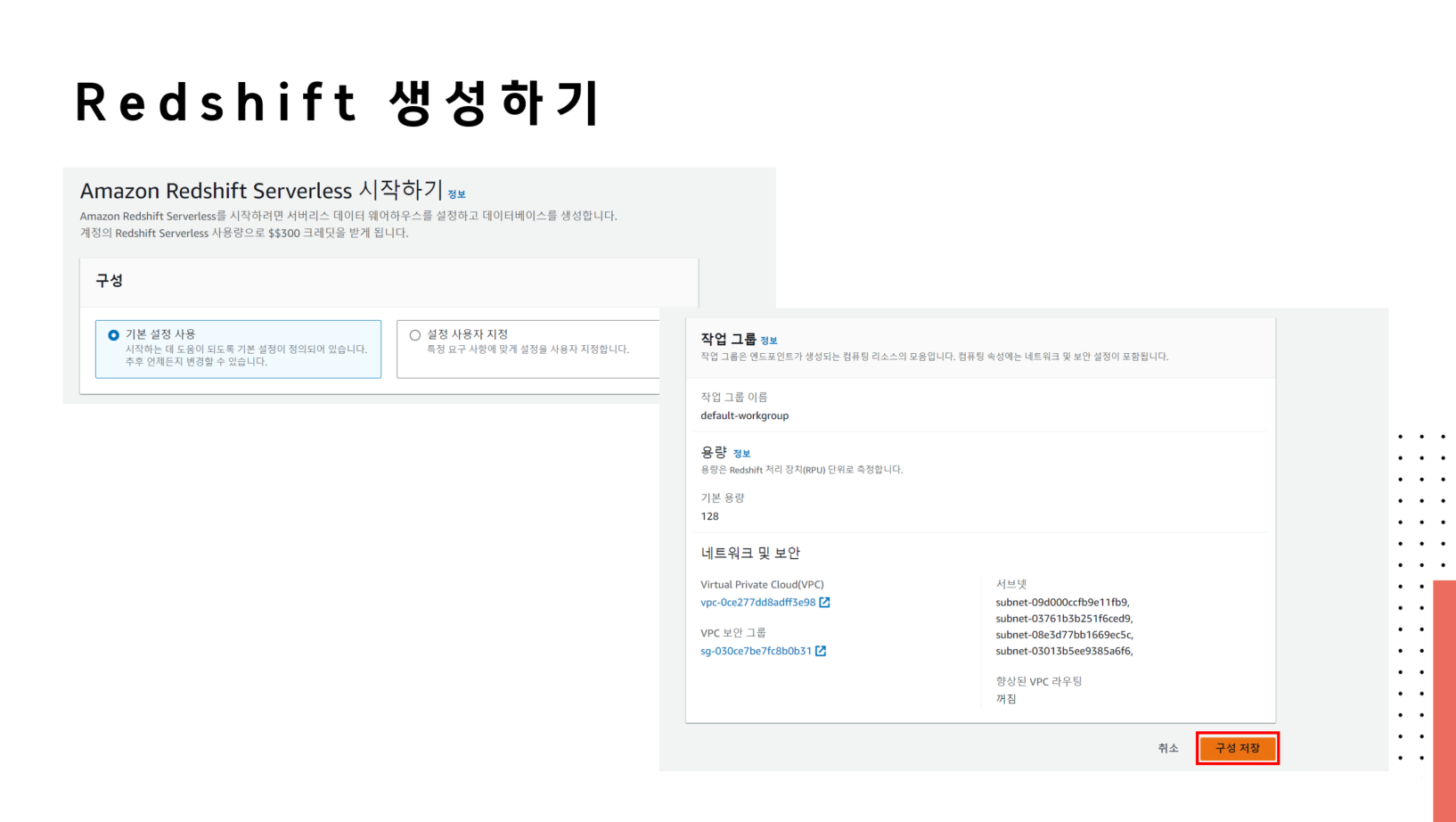
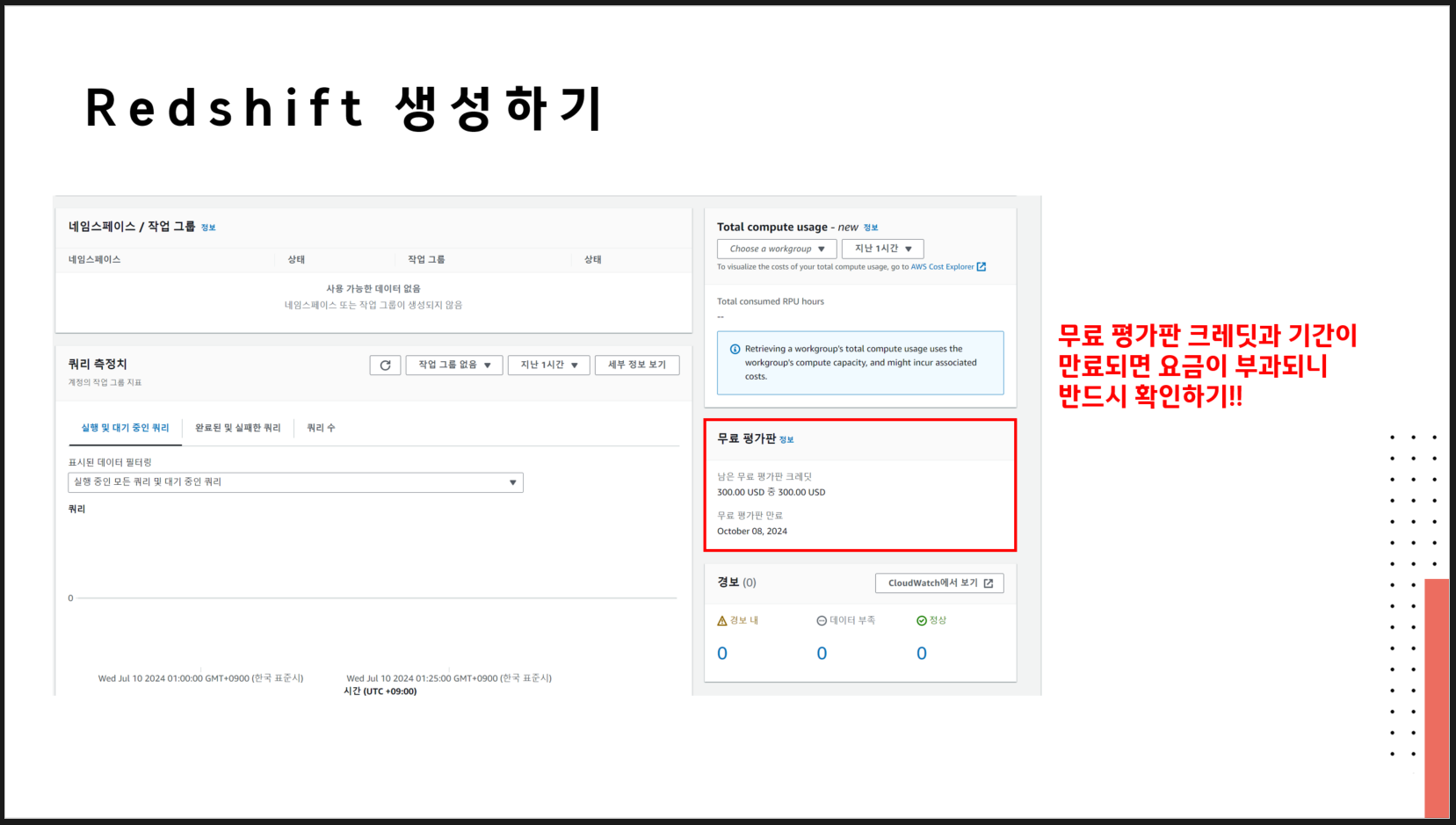
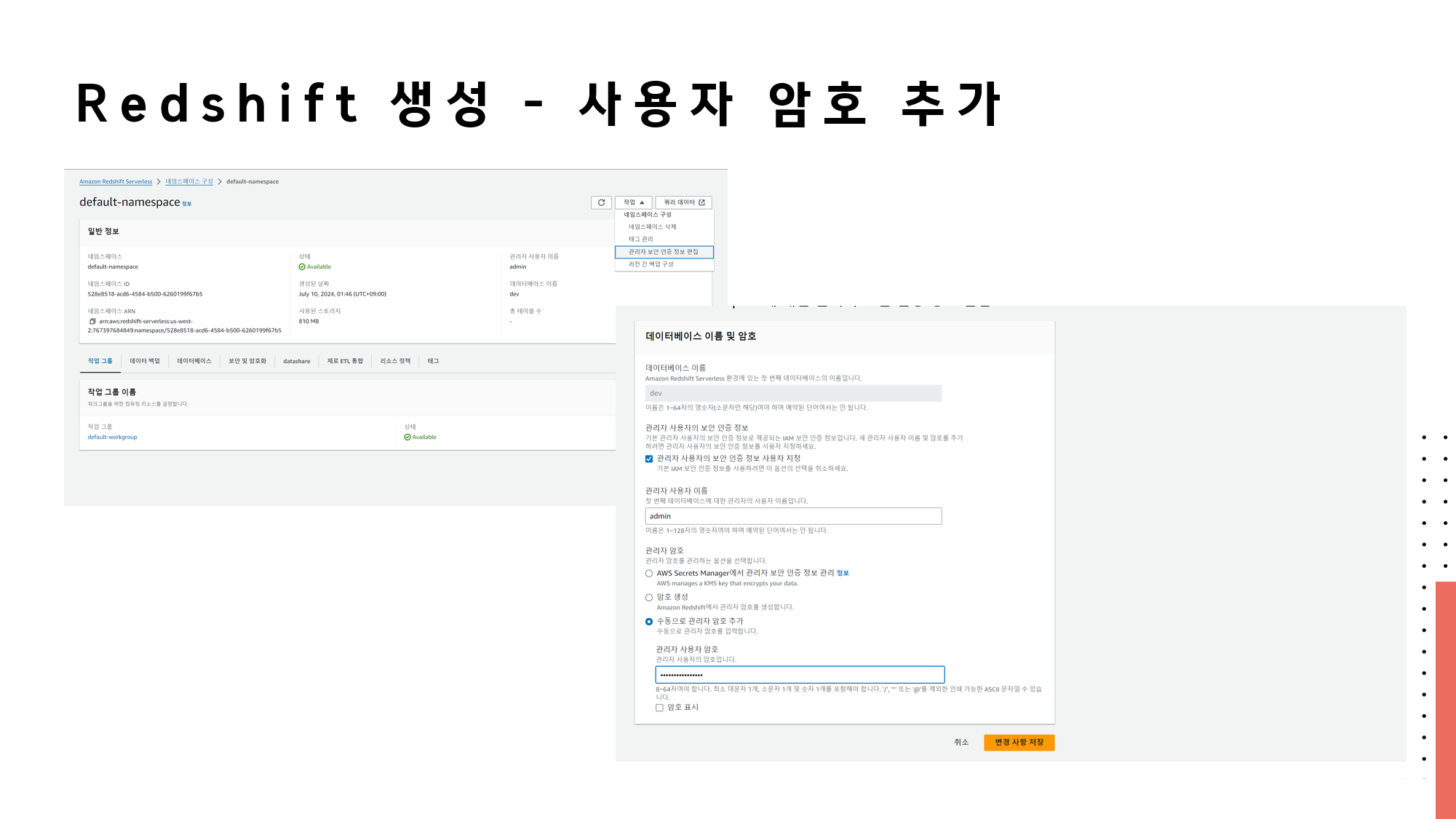
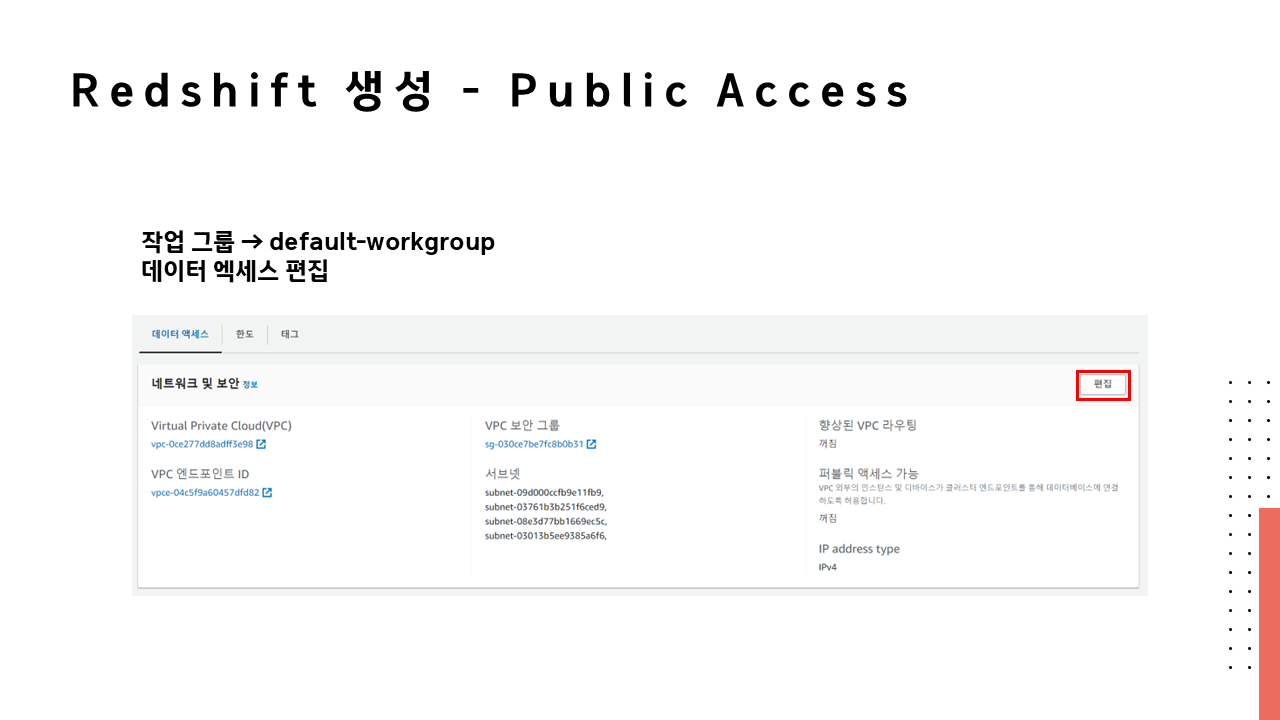
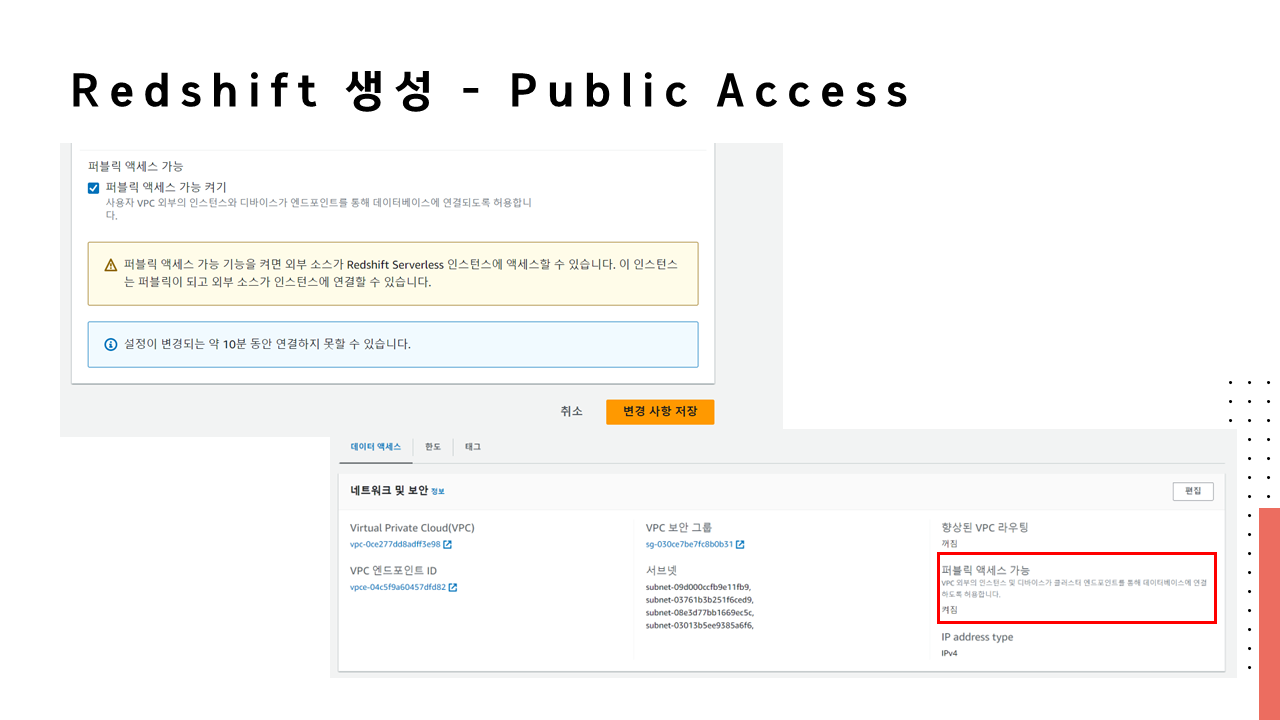
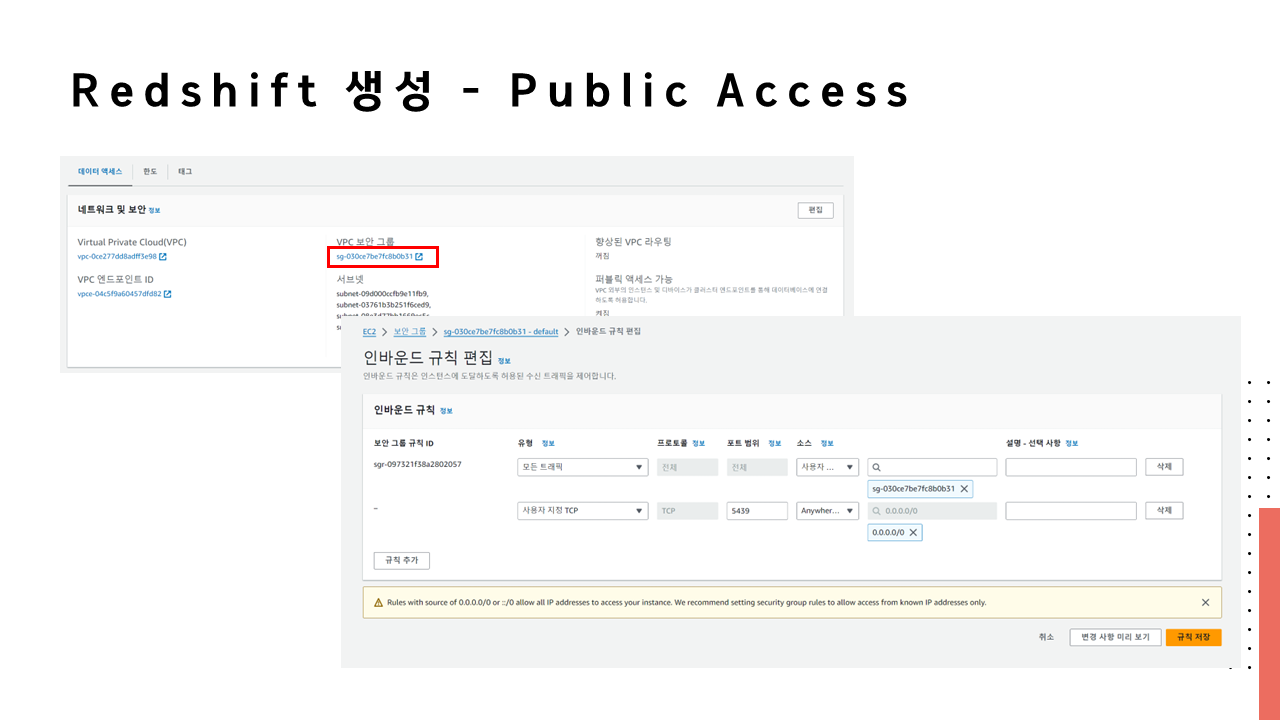
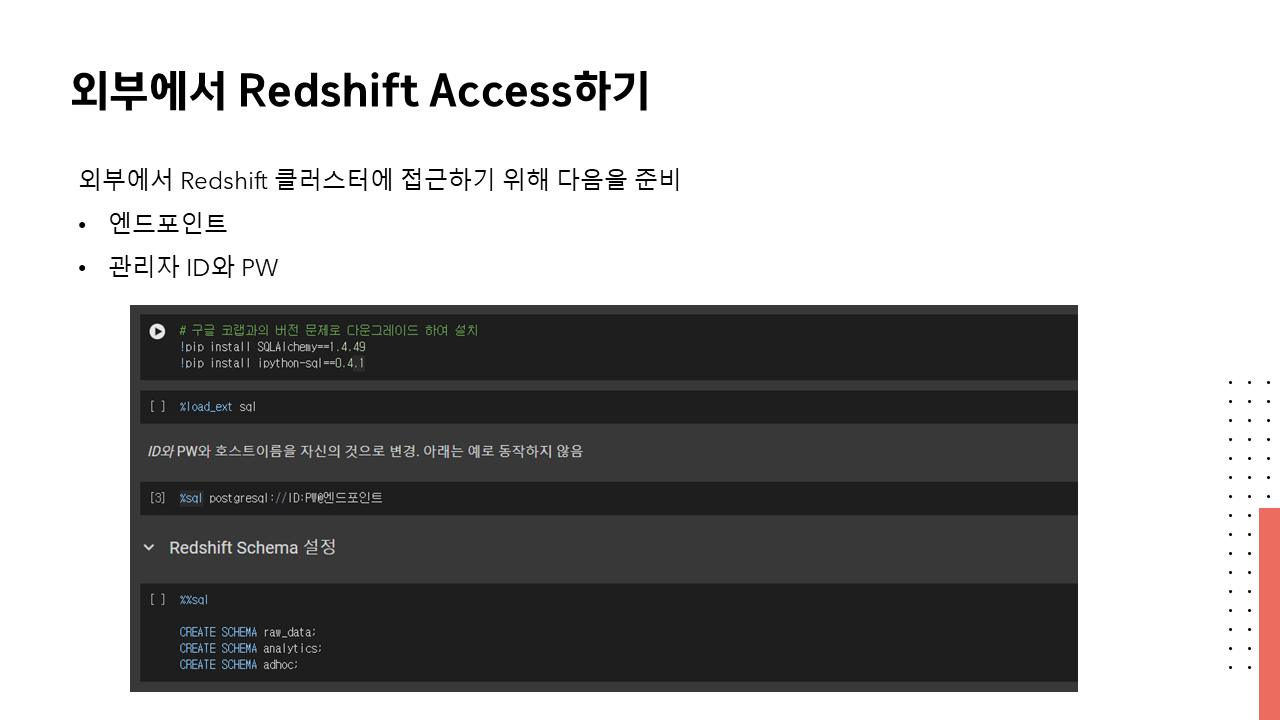
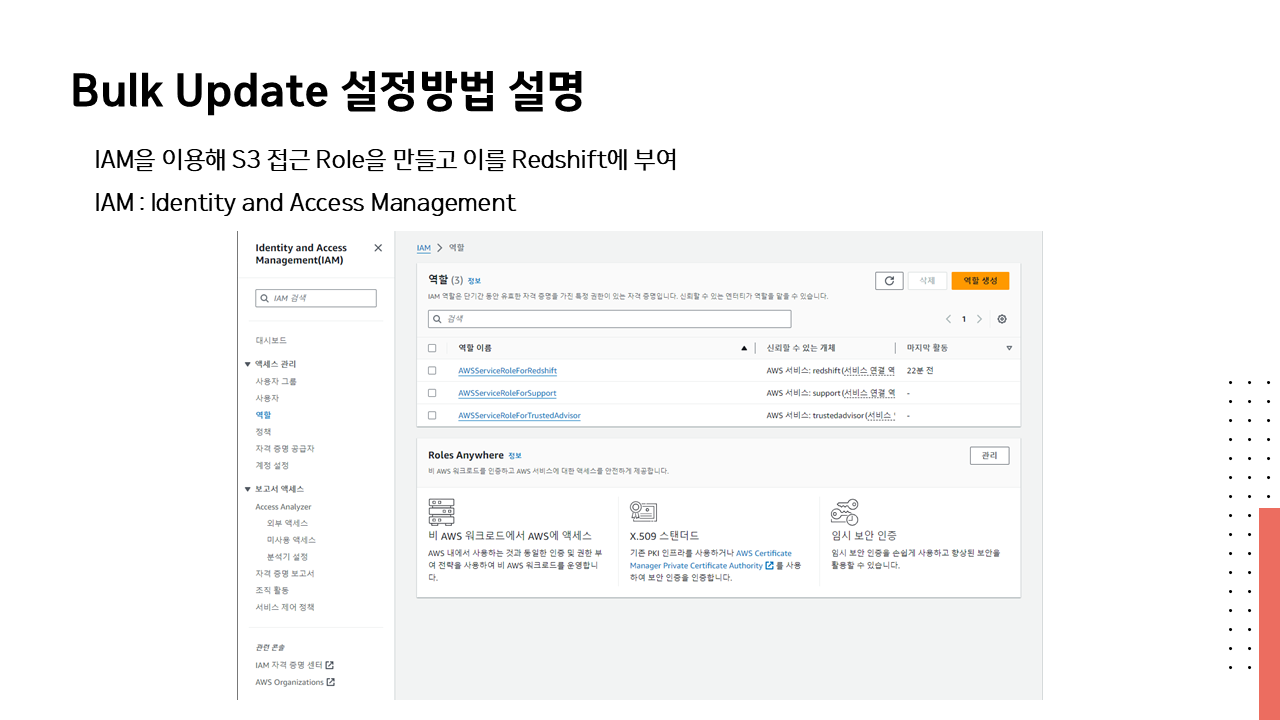
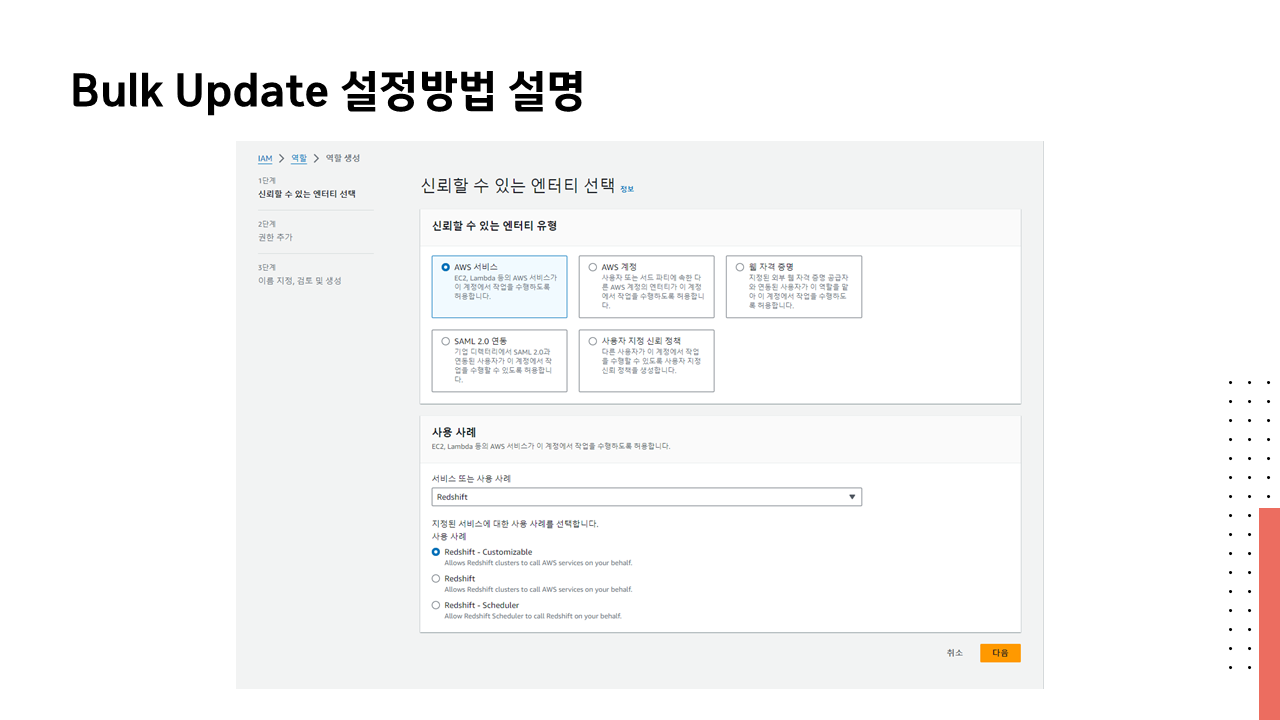
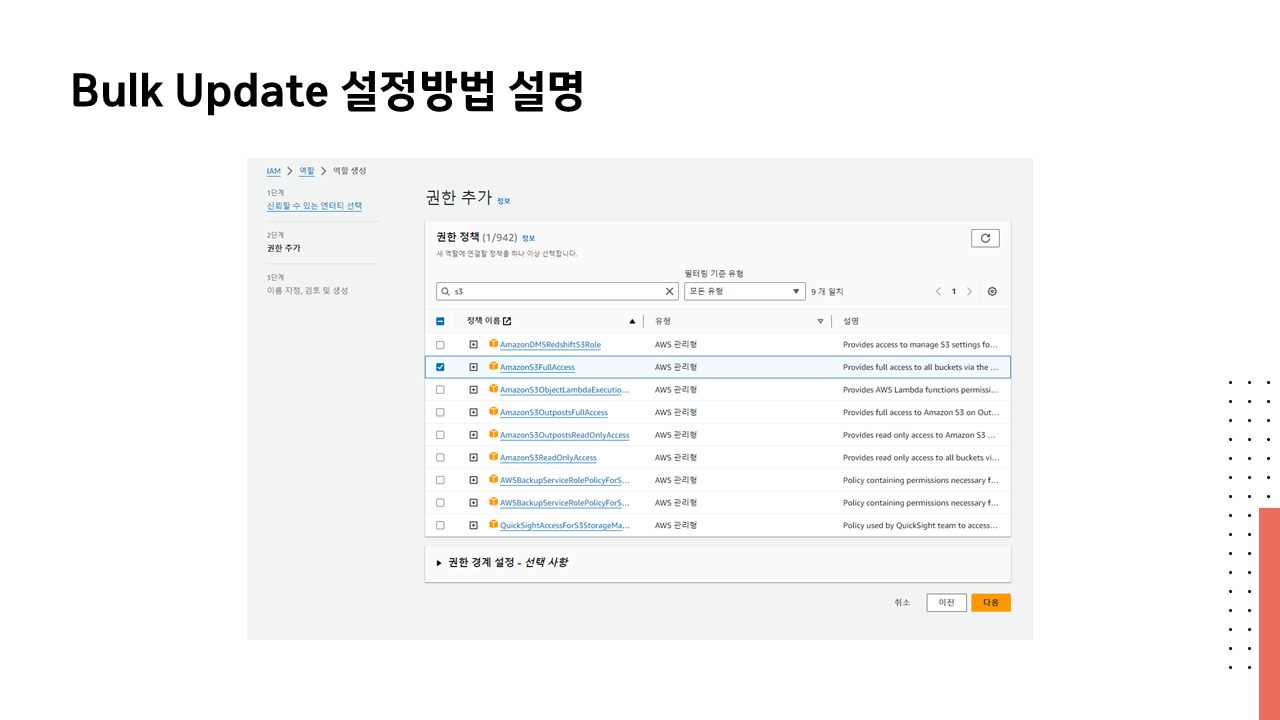

🔗 실습 코드 파일 : https://colab.research.google.com/drive/1RsQ5cmSVCBkXHfy3_Gpw_8EaSr9JZmVk?usp=sharing
💡 알아두면 좋은 SQL 쿼리 활용법
CASE WHEN절
필드 값의 변환을 위해 사용 가능
CASE WHEN
조건THEN참일때 변환 값ELSE거짓일때 변환 값END새로운 필드 이름여러 조건을 사용하여 변환하는 것도 가능
SELECT CASE WHEN channel in ('Facebook', 'Instagram') THEN 'Social_media' WHEN channel in ('Google', 'Naver') THEN 'Search-Engine' ELSE 'Something-Else' END channel_type --channel_type 이름으로 새로운 테이블 생성 FROM raw_data.user_session_channel;
channel 필드 값을 기반으로 channel_type이라는 별칭을 가진 새로운 열을 생성, 조회
--만약 이렇게 만들어진 컬럼을 원래 테이블에 추가하고 싶다면
1. 새로운 컬럼 추가
먼저, raw_data.user_session_channel 테이블에 channel_type이라는 새로운 컬럼을 추가한다.
ALTER TABLE raw_data.user_session_channel
ADD COLUMN channel_type VARCHAR(50);
2. 새로운 컬럼에 값 업데이트
새로 추가된 channel_type 컬럼에 CASE 문을 사용하여 값을 업데이트한다.
UPDATE raw_data.user_session_channel
SET channel_type = CASE
WHEN channel IN ('Facebook', 'Instagram') THEN 'Social_media'
WHEN channel IN ('Google', 'Naver') THEN 'Search-Engine'
ELSE 'Something-Else'
END;
String Functions
LEFT(str, N):
LEFT(channel, 4)channel 필드에서 앞의 4개를 추출
SELECT LEFT(channel, 4) AS short_channel FROM table_name;
REPLACE(str, exp1, exp2):
REPLACE(name, 'John', 'Jane')name 필드에서 'John'을 찾아서 'Jane'으로 바꿔치기
SELECT REPLACE(name, 'John', 'Jane') AS updated_name FROM table_name;
UPPER(str):
UPPER(city)city 필드를 대문자로 변환
SELECT UPPER(city) AS upper_city FROM table_name;
LOWER(str):
LOWER(country)country 필드를 소문자로 변환
SELECT LOWER(country) AS lower_country FROM table_name;
LEN(str):
LEN(description)description 필드의 길이를 반환
SELECT LEN(description) AS description_length FROM table_name;
LPAD(str, N, pad_str):
LPAD(id, 5, '0')문자의 왼쪽에 어떤 스트링을 붙여주는 것, RPAD는 오른쪽
id 필드의 왼쪽을 '0'으로 채워 5자리로 만듦
SELECT LPAD(id, 5, '0') AS padded_id FROM table_name;
RPAD(str, N, pad_str):
RPAD(code, 8, 'X')code 필드의 오른쪽을 'X'로 채워 8자리로 만듦
SELECT RPAD(code, 8, 'X') AS padded_code FROM table_name;
SUBSTRING(str, start, length): SUBSTRING(title, 2, 5)
title 필드에서 2번째 위치부터 5개의 문자를 추출
SELECT SUBSTRING(title, 2, 5) AS substring_title FROM table_name;
Type Casting
1/2의 결과는? 0
- 분자나 분모 중의 하나를 float로 캐스팅해야 0.5가 나옴 (모든 프로그래밍 언어에서도 일반적으로)
:: 오퍼레이터를 사용
- category::float
cast 함수를 사용
- cast(category as float)
월별 유니크한 사용자 수 (MAU)
Active User 집계는 서비스 분석에 굉장히 많이 쓰이는 개념입니다.
MAU : Monthly Active User, 해당 기간 동안 얼마나 다양한 사람들이 방문했나
WAU : Weekly, …
DAU : Daily, …
SELECT
TO_CHAR(A.ts, 'YYYY-MM') AS month,
COUNT(DISTINCT B.userid) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1 --1번째 필드를 의미합니다. 여기서는 TO_CHAR(A.ts, 'YYYY-MM') AS month
ORDER BY 1 DESC;
포인트는 GROUP BY를 month에 건 것과, DISTINCT COUNT!!
CTAS (Create Table AS)
간단하게 새로운 테이블을 만드는 방법
AS 뒤에 오는 서브 쿼리 결과를 테이블로 만든다
자주 JOIN, SELECT 하는 테이블들을 CTAS를 사용해 만들어두면 편리
CREATE TABLE sewook_test AS SELECT B.*, A.ts FROM raw_data.session_timestamp A JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid;
데이터 품질 확인
중복된 레코드들 체크하기
- 다음 두 개의 카운트를 비교
SELECT COUNT(1)
FROM adhoc.sewook_session_summary;
SELECT COUNT(1)
FROM (
SELECT DISTINCT userID, sessionID, ts, channel --이 테이블의 모든 컬럼
FROM adhoc.sewook_session_summary
);
테이블의 모든 필드를 조합하여 고유화시키고 해당 카운트를 일반 카운트와 비교하여 중복된 레코드가 있는지를 확인할 수 있다.
CTE를 사용해서 중복 제거 후 카운트 해보기
CTE (Common Table Expression): 생성 시 권한이 필요 없고, 하나의 쿼리문이 끝날 때까지(; 나올 때 까지)만 지속되는 일회성 테이블
임시 테이블을 재사용 할 수 있어 용이
With ds AS (
SELECT DISTINCT userId, sessionId, ts, channel
FROM adhoc.sewook_session_summary
)
SELECT COUNT(1)
FROM ds;
최근 데이터가 존재하는지 체크하기 (freshness)
- 너무 예전 데이터는 아닌지 timestamp를 기준으로 확인
SELECT MIN(ts), MAX(ts)
FROM adhoc.sewook_session_summary;
Primary Key Uniqueness가 지켜지는지 체크하기
SELECT sessionId, COUNT(1) FROM adhoc.sewook_session_summary GROUP BY 1 ORDER BY 2 DESC LIMIT 1;
1이상의 값이 출력된다면 잘 지켜지고 있지 않은 것
COALESCE (NULL값 처리)
NULL값을 다른 값으로 바꿔주는 함수
COALESCE(exp1, exp2, exp3,...)
exp1부터 인자를 하나씩 살펴서 NULL이 아닌 값이 나오면 그걸 리턴
끝까지 갔는데도 모두 NULL이면 최종적으로 NULL을 리턴
SELECT
value,
COALESCE(value, 0) --value가 NULL이면 0을 리턴
FROM raw_data.count_test;
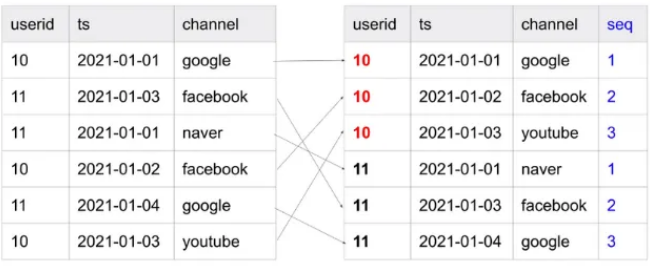
ROW_NUMBER()
ROW_NUMBER : 그룹핑된 각각의 레코드에 일련번호를 부여 (같은 필드값을 갖고 있는 레코드 내에서 정렬기준대로 번호 순서를 부여하는 것)
ROW_NUMBER() OVER(PARTITION BY
field1ORDER BYfield2)nnPARTITION BY : 어떤 필드 값을 기준으로 그룹핑할 것인지
ORDER BY : 어떻게 정렬 기준으로 일련번호를 붙일 것인지
nn : 일련번호 컬럼명
ROW_NUMBER() OVER (PARTITION BY userid ORDER BY ts) seq
Subscribe to my newsletter
Read articles from 정세욱 directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by