Tenets of Multithreading in GO: Detailed Tutorial
 Siddhartha S
Siddhartha S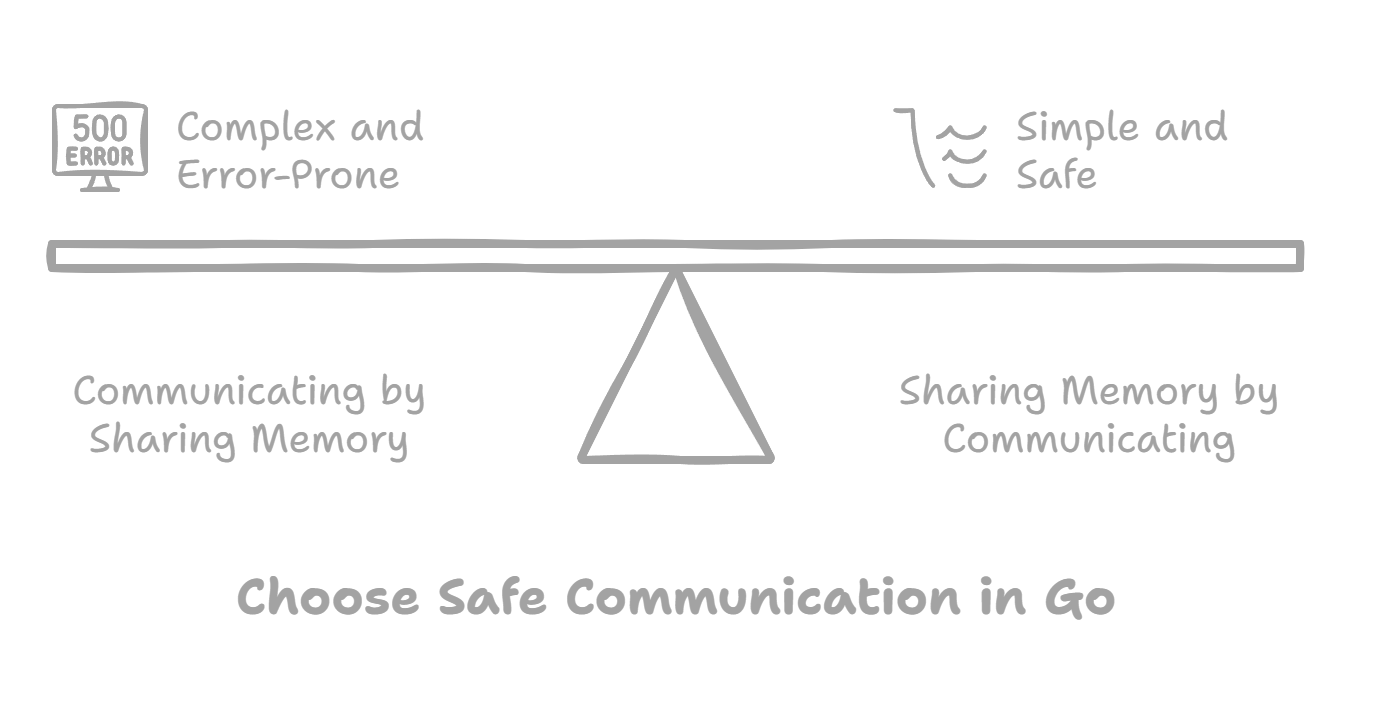
Introduction
Multiprocessing or multithreading is a critical aspect of many compiled languages, and go (often referred to as Golang) is no exception. Go began development around 2007-08, a time when chip manufacturers recognized the benefits of using multiple processors to increase computational power, rather than merely boosting the clock speed of single processors. While multithreading existed before this period, its real advantages became apparent with the advent of multiprocessor computers. In this article, we will review the various tools that Go provides for writing robust multiprocessing code. We will also explore simple code examples to help us grasp the concepts these tenets offer.
Background
Multiprocessing and Multitasking are two distinct concepts, and most languages supporting multithreading conceal the details within their concurrency frameworks. As a programmer, you might not be aware if a new OS thread is being created under the hood. Additionally, system threads differ from managed or green threads that are created by the code.
You may be a seasoned developer who is well-versed in the concepts of multitasking and multiprocessing. However, I strongly recommend reading through this article to clarify any grey areas you may have. This will also ensure that we (you and I) are on the same page as we proceed. Another request is to have access to the Go playground if you wish to try out the code provided in the article. I have endeavored to keep the code extremely simple so it can be tried on the fly without needing to set up a Go development environment.
I am also assuming that you are here specifically for multithreading in go and you are otherwise ok with go syntax.
Goroutines
A Goroutine is a green thread built into the Go language. Green threads (also known as managed threads or user threads) allow thousands of them to run simultaneously in a Go program. The complexities of memory management are handled seamlessly by the Go runtime.
Let’s start with a simple program that does not use a Goroutine.
package main
import (
"fmt"
"time"
)
func main(){
start := time.Now()
doFakeApiCall()
fmt.Println("\nFinished")
elapsed := time.Since(start)
fmt.Printf("\nProcesses took %s", elapsed)
}
func doFakeApiCall(){
time.Sleep(time.Second*2);
fmt.Println("\nAPI call took two seconds!")
}
If you run this code in the Go playground, you will see the following output, which is clear and easy to understand:
API call took two seconds!
Finished
Processes took 2s
Program exited.
However, if we place a go keyword in front of the doFakeApiCall() function, the program will exit before the doFakeApiCall() function completes. As a result, you will get:
Finished
Processes took 0s
Program exited.
This occurs because the doFakeApiCall() function call is now happening asynchronously. The main function does not wait for it to return and proceeds to the next instructions, causing the main function to exit before doFakeApiCall() has completed. Since we cannot predict the duration of asynchronous processing, we need to implement a mechanism in the main function that ensures it waits until the Goroutine returns. We will explore this in the next section.
Wait Group
We concluded the last section with a problem. Below is a Go program similar to the previous one, but now it includes an additional fake database call function.
package main
import (
"fmt"
"sync"
"time"
)
func main(){
start := time.Now()
go doFakeApiCall()
go doFakeDbCall()
fmt.Println("\nFinished")
elapsed := time.Since(start)
fmt.Printf("\nProcesses took %s", elapsed)
}
func doFakeApiCall(){
time.Sleep(time.Second*2);
fmt.Println("\nAPI call took two seconds!")
}
func doFakeDbCall(){
time.Sleep(time.Second*1);
fmt.Println("\nDB call took one second!")
}
As you may have guessed, the program will exit before the doFakeApiCall() and doFakeDbCall() functions complete. Here, WaitGroup from the sync package comes to the rescue. WaitGroup provides several methods that help synchronize the completion of concurrent tasks:
Add(<int>): Sets the number of concurrent tasks to handle.Done(): Decrements the count of concurrent tasks.Wait(): Blocks until the counter reaches zero, allowing the application flow to proceed.
Let’s amend our previous code to make use of WaitGroup.
package main
import (
"fmt"
"sync"
"time"
)
var wg = sync.WaitGroup{}
func main() {
wg.Add(2) //Add two tasks to the waitgroup
start := time.Now()
go doFakeApiCall()
go doFakeDbCall()
wg.Wait() //Wait for all tasks to finish.
fmt.Println("\nFinished")
elapsed := time.Since(start)
fmt.Printf("\nProcesses took %s", elapsed)
}
func doFakeApiCall() {
time.Sleep(time.Second * 2)
fmt.Println("\nAPI call took two seconds!")
wg.Done() //reduce waitgroup counter by 1
}
func doFakeDbCall() {
time.Sleep(time.Second * 1)
fmt.Println("\nDB call took one second!")
wg.Done() //reduce waitgroup counter by 1
}
The output for this program will be as follows:
DB call took one second!
API call took two seconds!
Finished
Processes took 2s
Program exited.
You may have noticed that the DB call finished first, despite being called after the API call. The total time taken for both the doFakeApiCall() and doFakeDbCall() calls is 2 seconds. If these were called synchronously, they would have taken 3 seconds.
While Wait Groups are effective for running independent goroutines, they do not facilitate communication between them. In Golang, channels are constructs used for sharing memory between goroutines. Below are some syntax details for channels:
ch := make(chan <Type>): Creates a channel.ch <- someData: Publishes data to the channel. This call is blocking, meaning control won't proceed until the data is read from the channel.someVar := <-ch: Reads from the channel into a variable. This is also a blocking call, waiting for data to become available.close(ch): Closes a channel.
Building on the example from the last section, let's consider an additional goroutine, doCreateFakeReport, which creates a report from the outputs of doFakeDbCall and doFakeApiCall.
package main
import (
"fmt"
"time"
"sync"
)
func main() {
start := time.Now()
apiCh:=make(chan string)
dbCh:=make(chan string)
var wg sync.WaitGroup
wg.Add(1)
go doFakeApiCall(apiCh)
go doFakeDbCall(dbCh)
go doCreateFakeReport(apiCh,dbCh,&wg)
wg.Wait()
fmt.Println("Finished")
elapsed := time.Since(start)
fmt.Printf("Processes took %s", elapsed)
}
func doFakeApiCall(apiChan chan string) {
time.Sleep(time.Second * 2)
fmt.Println("API call took two seconds!")
apiChan<-"API 123"
}
func doFakeDbCall(dbChan chan string) {
time.Sleep(time.Second * 1)
fmt.Println("DB call took one second!")
dbChan<-"DB 123"
}
func doCreateFakeReport(apiChan chan string,dbChan chan string, wg *sync.WaitGroup){
fmt.Println("Final Report: Api result is", <-apiChan , "Db Result is:", <-dbChan)
wg.Done()
}
In this code, we are:
Creating channels for
doFakeDbCallanddoFakeApiCallto publish their results.Passing these channels to the
doCreateFakeReportfunction to read from them.Using a Wait Group to wait until
doCreateFakeReportfinishes.
The output of this code is as follows:
DB call took one second!
API call took two seconds!
Final Report: Api result is API 123 Db Result is: DB 123
Finished
Processes took 2s
Program exited.
Buffered Channels
Buffered channels allow you to publish a predetermined number of items to the channel before it blocks for reading. Here is an example of a buffered channel:
package main
import (
"fmt"
"time"
)
func main(){
ch:=make(chan int, 3)
for i := 0; i < 3; i++{
go func(){
time.Sleep(time.Second*1)
ch<- i
}()
}
fmt.Println("Channel published: ", <-ch)
fmt.Println("Channel published: ", <-ch)
fmt.Println("Channel published: ", <-ch)
fmt.Printf("Exiting")
}
Output:
Channel published: 0
Channel published: 1
Channel published: 2
Exiting
Program exited.
Using buffered channels is preferred when you know the number of goroutines that will be launched.
Select Pattern for Channels
A common pattern for reading from multiple channels is using a select statement within an infinite loop. Here's an example:
package main
import (
"fmt"
"os"
"time"
)
func main() {
ch1 := make(chan string)
ch4 := make(chan string)
endCh := make(chan int)
go doPublish1(ch1)
go doPublish4(ch4)
go doEndOn10(endCh)
for {
select {
case msg := <-ch1:
fmt.Println(msg)
case msg := <-ch4:
fmt.Println(msg)
case msg := <-endCh:
fmt.Println(msg)
os.Exit(0)
}
}
}
func doPublish1(ch chan string) {
for {
time.Sleep(time.Second * 1)
ch <- "Publishing every 1 second"
}
}
func doPublish4(ch chan string) {
for {
time.Sleep(time.Second * 4)
ch <- "Publishing every 4 seconds"
}
}
func doEndOn10(ch chan int) {
for {
time.Sleep(time.Second * 10)
fmt.Println("Sending end signal")
ch <- 0
}
}
The first goroutine,
doPublish1, publishes to its channel every 1 second.The second goroutine,
doPublish4, publishes to its channel every 4 seconds.The last goroutine waits for 10 seconds before publishing to its channel, and once it does, the program exits.
The output in the Go playground is as follows:
Publishing every 1 second
Publishing every 1 second
Publishing every 1 second
Publishing every 1 second
Publishing every 4 seconds
Publishing every 1 second
Publishing every 1 second
Publishing every 1 second
Publishing every 1 second
Publishing every 4 seconds
Publishing every 1 second
Publishing every 1 second
Sending end signal
0
Synchronization
There may be situations where shared code is accessed by multiple goroutines, which can lead to race conditions. Golang offers several constructs to help with the synchronization of shared code.
For example, the following code demonstrates a clear case of a race condition:
package main
import (
"fmt"
"sync"
)
func main(){
counter:=0
var wg sync.WaitGroup
wg.Add(2)
go func(){ //Increments counter by 30000
for i := 0; i < 30000; i++{
counter++
}
wg.Done()
}()
go func(){ //Decrements counter by 30000
for i := 0; i < 30000; i++{
counter--
}
wg.Done()
}()
wg.Wait()
fmt.Println("Final counter value: ",counter)
}
This code simply increments and decrements a counter using two separate goroutines. The program waits for the goroutines to finish executing and then prints the counter's value. Because the counter is a shared variable between the goroutines, this creates a race condition. Every time you run this code in the Go playground, you may notice different values for the counter, including 0.
In the following sections, we will explore the constructs provided by Go to resolve race conditions arising from shared resources.
Mutexes
A mutex, short for mutual exclusion, helps with code synchronization by ensuring that only one goroutine can access a portion of the code that can lead to a race condition. The previous example can be corrected as shown below:
package main
import (
"fmt"
"sync"
)
func main(){
counter:=0
var wg sync.WaitGroup
var mut sync.Mutex
wg.Add(2)
go func(){ //Increments counter by 30000
for i := 0; i < 30000; i++{
mut.Lock()
counter++
mut.Unlock()
}
wg.Done()
}()
go func(){ //Decrements counter by 30000
for i := 0; i < 30000; i++{
mut.Lock()
counter--
mut.Unlock()
}
wg.Done()
}()
wg.Wait()
fmt.Println("Final counter value: ",counter)
}
Running the above code will consistently yield 0. Note that the code between the lock and unlock statements of the mutex is referred to as the critical section.
Atomic Variables
While mutexes help achieve synchronization, they introduce some boilerplate code. Atomic operations can enhance brevity. The previous example can be rewritten using atomic operations as follows:
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main(){
var counter int32 = 0
var wg sync.WaitGroup
wg.Add(2)
go func(){ //Increments counter by 30000
for i := 0; i < 30000; i++{
atomic.AddInt32(&counter,1)
}
wg.Done()
}()
go func(){ //Decrements counter by 30000
for i := 0; i < 30000; i++{
atomic.AddInt32(&counter,-1)
}
wg.Done()
}()
wg.Wait()
fmt.Println("Final counter value: ",counter)
}
In this example, the following code:
mut.Lock()
counter--
mut.Unlock()
has been replaced with:
atomic.AddInt32(&counter,1)
Condition Variables
In the previous code examples, while synchronization ensures the correct final result, we also need to impose a condition during the intermediate stages. Specifically, in the example from the last section, we want to ensure that the counter never goes below zero at any point during program execution.
Below is the amended code that modifies the mutex example to ensure that the value of the counter never falls below 0:
package main
import (
"fmt"
"sync"
)
func main(){
counter:=0
var wg sync.WaitGroup
var mut sync.Mutex
var counterChecker = sync.NewCond(&mut)
wg.Add(2)
go func(){ //Increments counter by 30000
for i := 0; i < 30000; i++{
mut.Lock()
counter++
fmt.Println(counter)
counterChecker.Signal()
mut.Unlock()
}
wg.Done()
}()
go func(){ //Decrements counter by 30000
for i := 0; i < 30000; i++{
mut.Lock()
if counter-1 < 0{
counterChecker.Wait()
}
counter--
fmt.Println(counter)
mut.Unlock()
}
wg.Done()
}()
wg.Wait()
fmt.Println("Final counter value: ",counter)
}
In this code, the decrement function waits on the conditional variable whenever it is about to decrease the counter into the negative range. Conversely, the increment function sends a signal each time it increments the counter.
This mechanism ensures that the counter's value is maintained above zero throughout the program's execution.
Worker Pool
The worker pool is a fundamental Go concurrency pattern that facilitates the creation of efficient pipelines. In Go, a pipeline is constructed using channels where one set of goroutines feeds data into a channel, while another set processes and offloads it.
The worker pool pattern represents the most basic form of a pipeline. It helps manage computational resources on a machine while leveraging the benefits of multiprocessing. This pattern is particularly useful for controlling the rate of resource consumption and maintaining system stability under heavy loads.
Implementation:
A fixed number of worker goroutines are initialized.
These workers continuously dequeue items from a feed channel.
After processing, workers send results to a results channel.
The results channel can serve as a feed channel for subsequent stages, creating a multi-stage pipeline.
package main
import (
"fmt"
"time"
"strconv"
)
func main() {
numWorkers := 3
numJobs := 10
jobs := make(chan int, numJobs)
results:=make(chan string, numJobs)
// Start worker goroutines
for w := 1; w <= numWorkers; w++ {
go worker(w, jobs, results)
}
// Send jobs to the jobs channel
for j := 1; j <= numJobs; j++ {
jobs <- j
fmt.Println("Produced job", j)
}
close(jobs) // Close the channel to indicate no more jobs will be sent
for r := 1; r<= numJobs; r++{
fmt.Println(<-results)
}
fmt.Println("All jobs have been processed.")
}
// Worker function processes jobs from the jobs channel
func worker(id int, jobs <-chan int, results chan <- string) {
fmt.Println("Waiting in worker")
for job := range jobs {
// Simulate doing some work
fmt.Println("Worker", id, "started job", job)
time.Sleep(time.Millisecond * 1500) // Simulate work duration
results<- "Worker " + strconv.Itoa(id) + " finished job " + strconv.Itoa(job)
}
}
Code Breakdown:
Channel Initialization:
Two buffered channels are created:
jobsfor incoming tasks andresultsfor processed outputs.Buffered channels prevent blocking, allowing for smoother operation.
Worker Goroutine Deployment:
A specified number of worker goroutines are launched.
Each worker function takes the
jobschannel as input and theresultschannel as output.
Job Distribution:
The main function populates the
jobschannel with tasks.After all jobs are queued, the
jobschannel is closed to signal completion.
Job Processing:
Workers continuously pull jobs from the
jobschannel using arangeloop.Each job is processed (simulated with a time delay in this example).
Results are sent to the
resultschannel.
Result Collection:
The main function retrieves and prints results from the
resultschannel.The program exits after processing all results.
This pattern demonstrates effective concurrent processing, load balancing across multiple workers, and controlled resource utilization. It serves as a foundation for more complex concurrent systems and pipelines in Go.
Conclusion
In this article, we explored how goroutines in Go enable concurrent execution and help optimize the use of computational resources. We covered the various concurrency primitives provided by the Go programming language, including wait groups, channels, buffered channels, and mutexes. We also delved into the use of conditional variables and atomic operations.
A key tenet of Go's concurrency philosophy is "communication by sharing memory, not sharing memory by communication." We discussed how this principle guides the design of Go's concurrency features and promotes effective coordination between concurrent entities.
Additionally, we examined the select pattern, which allows for handling multiple channels simultaneously, and the worker pool model, a fundamental concurrent design pattern. The worker pool pattern demonstrates efficient load distribution and resource management, making it a valuable tool in building scalable and high-performance concurrent systems.
Through these discussions, I believe this article has significantly expanded your knowledge of Go's concurrency capabilities and equipped you with a stronger set of tools to leverage the power of concurrent programming in your Go projects.
Subscribe to my newsletter
Read articles from Siddhartha S directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Siddhartha S
Siddhartha S
With over 18 years of experience in IT, I specialize in designing and building powerful, scalable solutions using a wide range of technologies like JavaScript, .NET, C#, React, Next.js, Golang, AWS, Networking, Databases, DevOps, Kubernetes, and Docker. My career has taken me through various industries, including Manufacturing and Media, but for the last 10 years, I’ve focused on delivering cutting-edge solutions in the Finance sector. As an application architect, I combine cloud expertise with a deep understanding of systems to create solutions that are not only built for today but prepared for tomorrow. My diverse technical background allows me to connect development and infrastructure seamlessly, ensuring businesses can innovate and scale effectively. I’m passionate about creating architectures that are secure, resilient, and efficient—solutions that help businesses turn ideas into reality while staying future-ready.