RAG Framework in Artificial Intelligence: Give LLM your own context
 Aniket Vishwakarma
Aniket Vishwakarma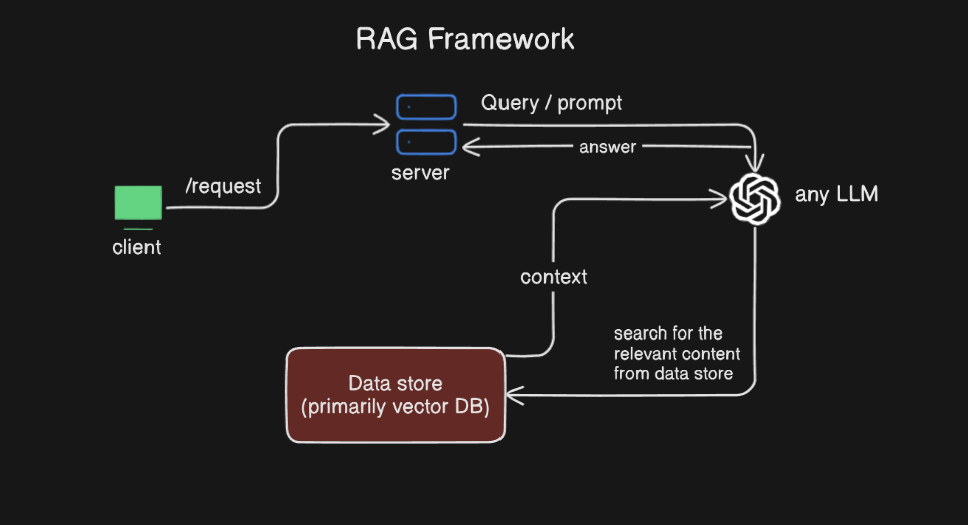
What is RAG (Retrieval Augmented Generation) ?
RAG is a type of technique or strategy to give your own context to LLM to incorporate external knowledge basis and improve relevance of responses.
Lets talk about the Generation part in Retrieval Augmented Generation , this refers to the large language language model that generate text in response to user query , referred to as a prompt .
These models can have a undesirable behavior , lets see an example here , you ask a model give me the country with the most number of population and give me today’s stock market report , now the LLM can be out of context here or there knowledge can be outdated , or they do not have any source to support their answer . They are the LLM challenges .
How to solve these challenges in LLM?
How do you think the LLM would response to our previous query, it will be like this “Ok, I have been trained and from what i know from my parameter during my training, the answer is China is the country with largest population” but the answer is wrong we know that right ? so to fix these problems what if we can give the updated data to the models on what basis they can curate their answers.
That’s where the RAG strategy comes
Retrieval Augmented , what does that mean ? that means now instead of just relying on what the LLM knows we are adding a content store , this can be anything , open like internet , closed like documents, collection of your own data, whatever.
How this whole process works ?
LLM first goes to the content store and says “Hey can you retrieve to me the information which is relevant to the users query was? ” and now the retrieval augmented answer which is not China anymore , it is now India.
What does this look like ? Originally when we were just talking to the generative model, the model is just giving us the answer on the basis of what it knows, but in RAG framework the generative model has a instruction that says “ First, go and retrieve the relevant content and combine them with the users question and only then generate the answer ”
Now with the content store we have the evidence which can support the LLM’s answer “why your response is what it is”. you can see how RAG frameworks helps to overcome the challenges with LLM like : context out of date, no supportive evidence etc.
Out of date challenge solution: With RAG framework instead of retrain your model if new information comes up. All you have to do is to augment your data store with new information, update information. Now the next time the user asks the question, the LLM is ready it can just retrieve the most up to date information.
Source challenge solution: Now with the RAG the large language model is instructed to pay attention to primary source data source before giving its response, now being able to give evidence. Now the model is less likely to hallucinate or leak data because it is less likely to rely only on the information that it has learned during training.
Pros :
It also allows us to get the model to have a behavior that can be very positive, which is knowing when to say, “I don’t know”.
If the user’s question cannot be reliably answered based on your data store, the model should say, “I don’t know,” instead of making up something that is believable and may mislead the user.
Cons :
- This can have a negative effect as well though, because if the retriever is not sufficiently good to give the large language model the best, most high-quality grounding information, then maybe the user’s query that is answerable doesn’t get an answer.
Subscribe to my newsletter
Read articles from Aniket Vishwakarma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aniket Vishwakarma
Aniket Vishwakarma
I am currently a final year grad, grinding, learning and solving problems by leveraging technology and my soft skills