Statistical Inference in Data Science (Made Easy!)
 techGyan : smart tech study
techGyan : smart tech study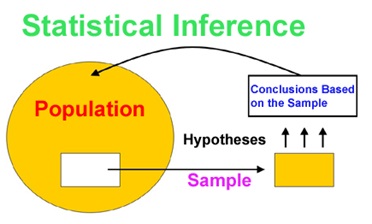
Welcome to TechGyan! Today, let's break down Statistical Inference in a super simple way with easy examples. If you are learning Data Science and Machine Learning, this topic is very important. Let’s dive in!
What is Statistical Inference?
Statistical inference is the process of making predictions or conclusions about a large group (population) based on information from a small group (sample).
Example:
Imagine you want to know the average height of students in your school. Instead of measuring all students, you take a small group (sample) and find their average height. You then use this data to predict the average height of all students in the school. This is statistical inference!
Populations and Samples
Population: The entire group you want to study. (e.g., all students in a school)
Sample: A small part of the population that is actually measured. (e.g., 100 students from different classes)
A good sample should be random and representative of the population to make accurate predictions.
Types of Statistical Modeling
Statistical models help us analyze data and make predictions. There are two main types:
Descriptive Models: These summarize data but do not make predictions.
- Example: Finding the average age of people in a city.
Inferential Models: These use samples to make predictions about the entire population.
- Example: Predicting the future sales of a product based on past data.
Types of Probability Distributions
Probability distributions show how values in a dataset are spread. There are different types:
1. Normal Distribution (Bell Curve)
Most common in real-world data.
Example: Heights of people usually follow a normal distribution.
2. Binomial Distribution
Used for yes/no or success/failure outcomes.
Example: Tossing a coin 10 times and counting how many heads you get.
3. Poisson Distribution
Used for counting rare events.
Example: Number of calls received at a customer service center per hour.
Parametric vs. Non-Parametric Methods
Statistical methods are divided into two categories:
Parametric Methods:
Assume the data follows a specific distribution (like Normal Distribution).
Example: Using the mean and standard deviation of exam scores to predict future performance.
Non-Parametric Methods:
Do not assume any specific distribution.
Example: Median and percentiles are used instead of the mean when data is skewed.
Distance Metrics in Data Science
Distance metrics measure how similar or different two data points are. These are used in clustering and classification.
Common Distance Metrics:
Euclidean Distance
Measures straight-line distance between two points.
Example: Distance between two cities on a map.
Manhattan Distance
Measures distance in a grid-like pattern (like moving in a city with streets).
Example: Walking distance in New York City.
Cosine Similarity
- Measures the angle between two vectors.
Example: Comparing two documents to see how similar they are based on word usage.
Conclusion
Statistical inference is super important in Data Science. It helps us make decisions using samples instead of checking the entire population. Understanding populations, samples, probability distributions, and distance metrics will make you a better data scientist!
📌 Stay tuned to TechGyan for more simple and easy explanations on Data Science & Machine Learning topics. Happy Learning! 🚀
Subscribe to my newsletter
Read articles from techGyan : smart tech study directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
techGyan : smart tech study
techGyan : smart tech study
TechGyan is a YouTube channel dedicated to providing high-quality technical and coding-related content. The channel mainly focuses on Android development, along with other programming tutorials and tech insights to help learners enhance their skills. What TechGyan Offers? ✅ Android Development Tutorials 📱 ✅ Programming & Coding Lessons 💻 ✅ Tech Guides & Tips 🛠️ ✅ Problem-Solving & Debugging Help 🔍 ✅ Latest Trends in Technology 🚀 TechGyan aims to educate and inspire developers by delivering clear, well-structured, and practical coding knowledge for beginners and advanced learners.