Graph RAG의 모든 것
 Jonas Kim
Jonas Kim
1. Graph RAG 정의와 장점
Graph RAG는 기존 검색 증강 생성(Retrieval-Augmented Generation) 기법을 지식 그래프와 결합하여 대규모 언어 모델(LLM)의 응답 품질을 향상시키는 혁신적 접근법입니다. 전통적인 RAG가 벡터 임베딩 기반 문서 검색에 의존한다면, Graph RAG는 개체(노드)와 관계(엣지)로 구성된 지식 그래프의 구조적 정보를 활용합니다. 이를 통해 LLM은 단순한 키워드 매칭이나 벡터 유사도를 넘어, 개념들 간의 복잡한 연결 관계와 맥락을 이해하여 더 정확하고 풍부한 정보를 바탕으로 응답을 생성할 수 있습니다. 특히 다단계 추론이 필요한 복잡한 질의에서 그래프 기반 지식 네트워크가 탁월한 효과를 발휘합니다.
전통적인 RAG의 한계점
마이크로소프트 리서치의 "GraphRAG: Unlocking LLM Discovery on Narrative Private Data" 연구에 따르면, 기존 RAG 접근법은 다음과 같은 중요한 한계를 가지고 있습니다.
정보 연결의 어려움: 기존 RAG는 분산된 정보의 청크를 논리적으로 연결하여 새로운 통합 인사이트를 도출해야 하는 상황에서 어려움을 겪습니다. 특히 여러 문서에 걸친 공유 속성이나 관계를 통합해야 할 때 이러한 한계가 두드러집니다.
대규모 정보의 종합적 이해 부족: 기존 RAG는 대용량 데이터 컬렉션이나 대형 문서에 걸친 의미적 개념을 전체적으로 파악하고 요약하는 작업에서 성능이 저하됩니다.
이러한 한계점들이 Graph RAG의 등장 배경이 되었으며, 그래프 구조를 통해 이러한 문제를 효과적으로 해결하는 방향으로 연구가 진행되고 있습니다.
Graph RAG의 주요 장점
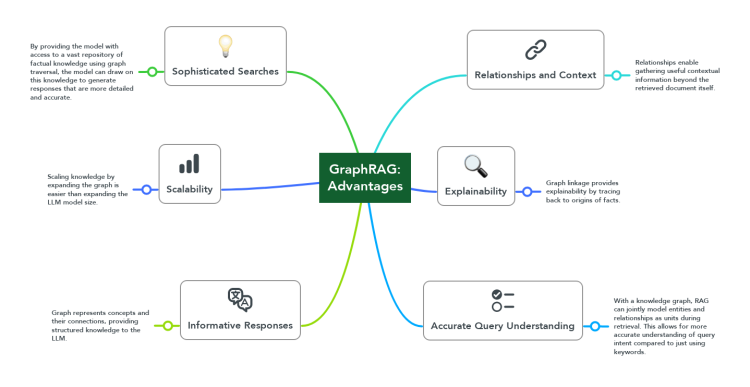
정교한 검색 능력: 그래프 순회(traversal)를 통해 방대한 지식 저장소에서 관련 사실 정보를 효과적으로 찾아내 LLM이 상세하고 정확한 응답을 생성하도록 지원합니다.
맥락적 관계 제공: 지식 그래프의 관계는 문서의 개별 청크 만으로는 파악하기 어려운 유용한 맥락 정보를 제공하여, LLM이 더 넓은 지식 배경을 고려한 응답을 생성할 수 있게 합니다.
질의 의도의 정확한 이해: 그래프 상에서 개체와 관계를 하나의 의미 단위로 모델링함으로써, 단순 키워드 매칭보다 사용자 질의의 의도를 더 정확히 파악할 수 있습니다. 이는 특히 복잡한 질의에 대한 맥락적 정확성을 높입니다.
향상된 설명 가능성: 그래프의 링크를 따라가면 모델이 활용한 사실의 출처를 쉽게 추적할 수 있어, 응답의 근거를 명확히 설명할 수 있습니다. 이는 결과의 신뢰성과 투명성을 크게 높여줍니다.
풍부하고 포괄적인 응답: 그래프는 개념들과 그들 사이의 복잡한 연결을 명시적으로 표현하므로, LLM에 더 구조화된 지식을 제공하여 보다 포괄적이고 깊이 있는 답변 생성을 가능하게 합니다.
효율적인 지식 확장성: 새로운 정보를 그래프에 추가하여 지식을 확장하기가 상대적으로 용이하므로, LLM 자체의 파라미터를 늘리는 것보다 비용 효율적으로 도메인 지식을 확장할 수 있습니다.
다단계 추론 지원: 그래프 구조는 복잡한 추론 체인을 형성하는 데 도움이 되어, 단계적 사고가 필요한 복잡한 질문에 더 정확하게 응답할 수 있습니다.
2. 지식 그래프(Knowledge Graph) 및 그래프 데이터베이스(Graph DB) 개요
Graph RAG를 제대로 활용하기 위해서는 그 기반이 되는 지식 그래프와 그래프 데이터베이스에 대한 이해가 필수적입니다.
2.1. 지식 그래프란?
지식 그래프는 현실 세계의 개체(사람, 장소, 개념 등)들과 그들 간의 관계를 그래프 구조로 표현한 데이터 모델입니다. 이 구조에서는
노드(Node): 개체를 나타냅니다 (예: 사람, 도시, 제품, 개념 등)
엣지(Edge): 개체 간의 관계를 연결합니다 (예: '거주한다', '창업했다', '포함한다' 등)
속성(Properties): 노드와 엣지에 부여되는 추가적인 정보입니다 (예: 이름, 날짜, 가중치 등)
이러한 그래프 구조는 방대한 지식을 의미적 네트워크 형태로 표현하여, 시스템이 데이터 간의 의미 있는 관계를 "이해"하고 추론할 수 있도록 합니다. 결과적으로 지식 그래프는 AI 모델이 연결된 데이터로부터 패턴을 인식하고 새로운 연관성을 유추하는 데 활용되어 검색, 추천, 질의응답 등의 성능을 크게 향상시킬 수 있습니다.
2.2. 그래프 데이터베이스
지식 그래프를 효과적으로 활용하려면 그래프 데이터를 저장하고 질의할 수 있는 그래프 데이터베이스(Graph DB)가 필요합니다. 그래프 DB는 노드와 엣지로 이루어진 그래프 데이터를 저장/관리하며, 관계 중심적인 질의를 효율적으로 처리하도록 특별히 설계된 DBMS입니다.
그래프 데이터베이스의 주요 특징은 다음과 같습니다.
관계 중심 데이터 모델: 데이터 간의 관계가 일급 객체(first-class citizen)로 취급되어 직접적으로 저장 및 질의됩니다.
유연한 스키마: 새로운 노드 유형이나 관계를 필요에 따라 쉽게 추가할 수 있어 변화하는 요구사항에 빠르게 적응할 수 있습니다.
효율적인 그래프 탐색: 연결된 데이터를 빠르게 탐색할 수 있는 최적화된 구조를 가지고 있어, 복잡한 관계 기반 질의를 효율적으로 처리합니다.
직관적인 데이터 모델링: 실제 세계의 관계를 자연스럽게 표현할 수 있어 도메인 전문가도 이해하기 쉬운 데이터 모델을 구축할 수 있습니다.
인덱스 프리 인접성(Index-free adjacency): 많은 그래프 데이터베이스는 노드 간의 연결을 물리적 포인터로 저장하여 관계 조회 성능을 최적화합니다.
관계형 DB (RDB) vs 그래프 DB 비교
| 특성 | 관계형 데이터베이스 (RDB) | 지식 그래프 (Knowledge Graph) |
| 데이터 저장 방식 | 구조화된 테이블 형태 | 개체(노드)와 관계(엣지)로 구성 |
| 스키마 | 정형화된 고정 스키마 | 유연한 스키마 구조 |
| 데이터 조작 | SQL을 통한 조작 | 그래프 질의 언어 사용 (Cypher, SPARQL 등) |
| 관계 표현 | 외래 키를 통한 간접 표현 | 직접적인 관계로 표현 |
| 복잡한 관계 처리 | 여러 조인 필요 (성능 저하) | 직관적인 관계 탐색 (성능 우수) |
| 패턴 발견 | 제한적 | 숨겨진 연결과 패턴 발견 용이 |
| 데이터 통합 | 스키마 변경 어려움 | 다양한 소스의 데이터 통합 용이 |
2.3. 그래프 모델의 종류
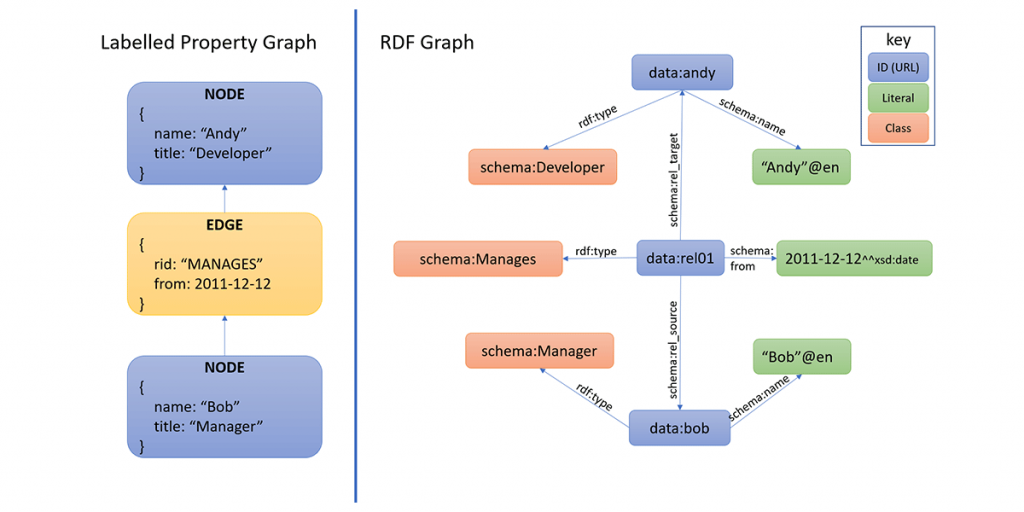
그래프 데이터베이스에서는 크게 두 가지 주요 모델이 사용됩니다.
프로퍼티 그래프(Property Graph) 모델
노드와 엣지에 직접 속성(properties)을 부여할 수 있습니다.
라벨을 통해 노드 및 엣지를 분류합니다.
단일 지식 소스 내에서의 단순성과 직관성을 제공합니다.
Neo4j가 대표적인 구현체이며, 주로 OpenCypher나 Gremlin과 같은 질의 언어를 사용합니다.
RDF(Resource Description Framework) 모델
URI를 통한 표준화된 식별자를 사용합니다.
주어-술어-목적어 형태의 트리플(triple) 구조로 데이터를 표현합니다.
W3C 표준을 기반으로 하며, 여러 지식 소스 간 통합과 표준화를 지원합니다.
주로 SPARQL 질의 언어를 사용합니다.
2.4. 그래프 질의 언어 비교
그래프 데이터베이스에서는 저장된 그래프의 유형에 따라 다양한 질의 언어가 사용됩니다.
Cypher
프로퍼티 그래프 모델을 위한 질의 언어로, Neo4j에서 주로 사용됩니다.
직관적인 시각적 패턴 매칭 구문을 특징으로 합니다.
노드는 괄호
(), 관계는 화살표-->또는 방향이 있는 화살표-[]->로 표현합니다.
예시: 서울에 거주하는 모든 사람의 이름을 찾는 질의
MATCH (p:Person)-[:LIVES_IN]->(c:City)
WHERE c.name = "Seoul"
RETURN p.name
SPARQL
RDF 그래프 모델을 위한 W3C 표준 질의 언어입니다.
트리플 패턴 기반의 질의를 사용하고, URI를 통해 리소스를 명확하게 식별합니다.
여러 데이터셋 간 통합 질의가 가능합니다.
예시: 위와 동일한 질의를 SPARQL로 표현
SELECT ?person
WHERE {
?person rdf:type ex:Person .
?person ex:livesIn ex:Seoul .
}
Gremlin
Apache TinkerPop 프레임워크의 일부로, 프로퍼티 그래프 모델을 위한 명령형 그래프 순회 언어입니다.
다양한 그래프 데이터베이스에서 지원됩니다.
함수형 스타일의 연쇄 호출 방식으로 그래프를 탐색합니다.
예시: 위와 동일한 질의를 Gremlin으로 표현
g.V().hasLabel('Person').
out('LIVES_IN').
has('name', 'Seoul').
in('LIVES_IN').
values('name')
2.5 AWS에서 사용 가능한 Graph DB 비교
| 특성 | Neo4j | Amazon Neptune |
| 제공자 | AWS 마켓플레이스 | AWS 관리형 서비스 |
| 지원 데이터 모델 | 프로퍼티 그래프 | 프로퍼티 그래프, RDF |
| 지원 질의 언어 | Cypher | Gremlin, SPARQL, OpenCypher |
| 관리와 운영 | 사용자 관리 | 완전 관리형 |
| LangChain과의 통합 | 지원 | 지원(Cypher, SPARQL) |
| LlamaIndex와의 통합 | 지원 | 지원 |
3. Graph RAG 디자인 패턴
Graph RAG는 지식 그래프를 RAG 파이프라인에 통합하는 접근법으로, 아직 표준화된 구현 방식이 정립되지 않았습니다. Ben Lorica와 Prashanth Rao의 분석에 따른 주요 디자인 패턴들을 살펴보겠습니다.
3.1. 일반적인 디자인 패턴
지식 그래프와 의미 기반 클러스터링
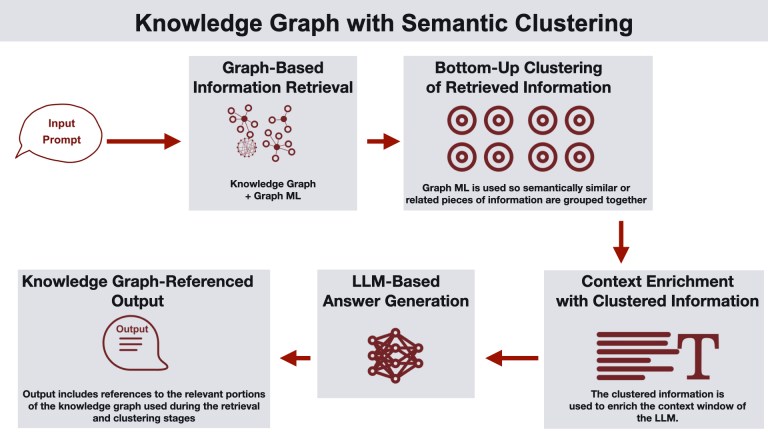
이 패턴은 사용자 질의에 대해 지식 그래프와 그래프 머신러닝을 활용하여 정보를 검색하고, 의미적 클러스터로 조직화합니다.
작동 방식
사용자가 질의를 제출합니다.
시스템은 지식 그래프와 그래프 머신러닝을 사용해 관련 정보를 검색합니다.
검색된 정보는 그래프 기반 클러스터링을 통해 의미적 클러스터로 조직화됩니다.
클러스터링된 정보가 LLM의 컨텍스트를 풍부하게 하여 더 정확한 답변 생성을 돕습니다.
최종 답변에는 지식 그래프에 대한 참조가 포함됩니다.
활용 사례: 데이터 분석, 지식 발견, 연구 분야
지식 그래프와 벡터 데이터베이스 통합
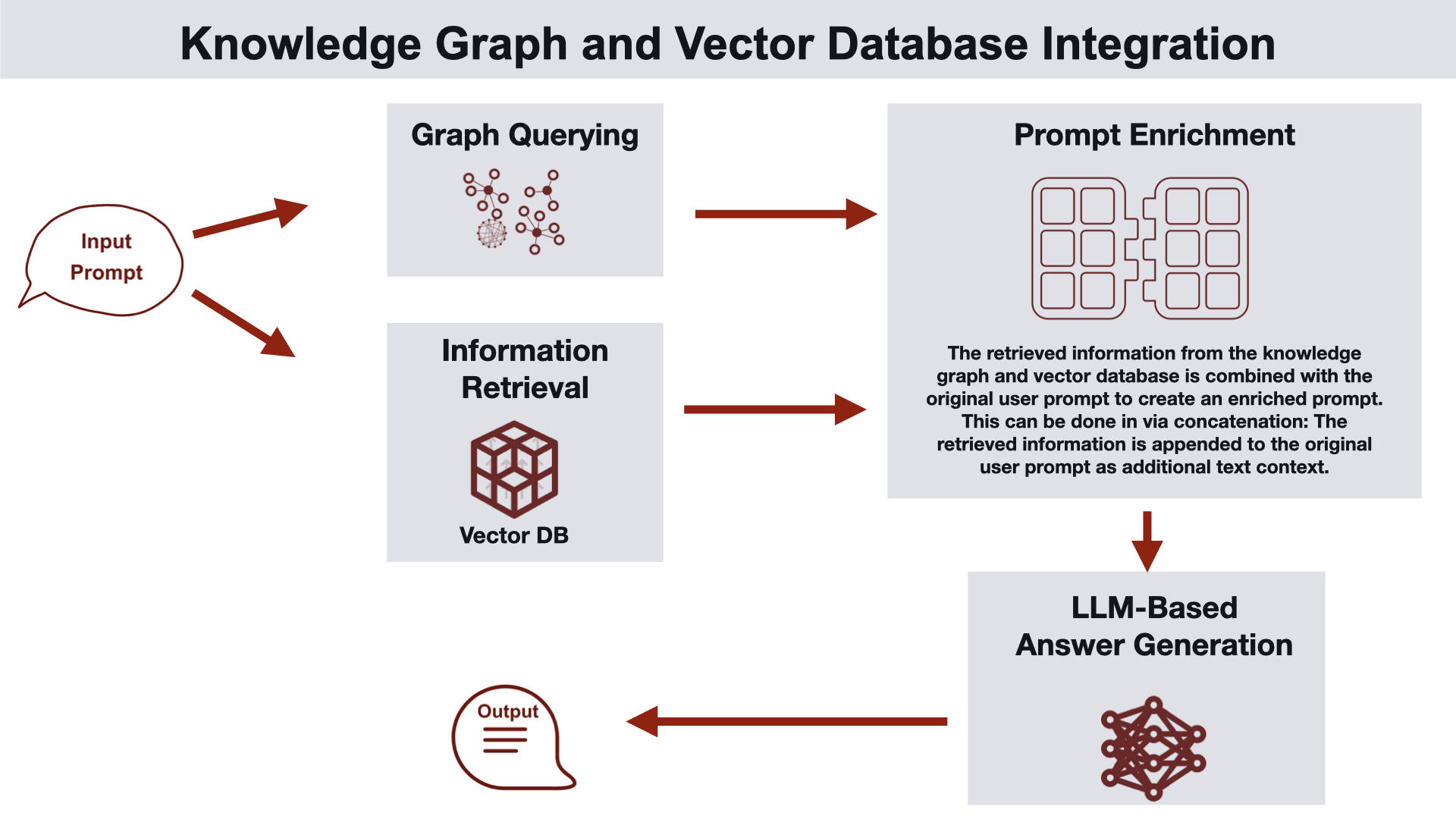
이 접근법은 지식 그래프와 벡터 데이터베이스를 모두 활용하여 관련 정보를 수집합니다.
작동 방식
지식 그래프는 벡터화한 문서 청크 간의 관계(문서 계층 구조 포함)를 캡처합니다.
벡터 검색에서 검색된 청크 주변의 이웃 구조화된 개체 정보를 지식 그래프가 제공하여 프롬프트를 풍부하게 합니다.
강화된 프롬프트가 LLM에 입력되어 응답을 생성합니다.
생성된 답변이 사용자에게 반환됩니다.
활용 사례: 고객 지원, 의미적 검색, 개인화된 추천 시스템
그래프 강화 하이브리드 검색
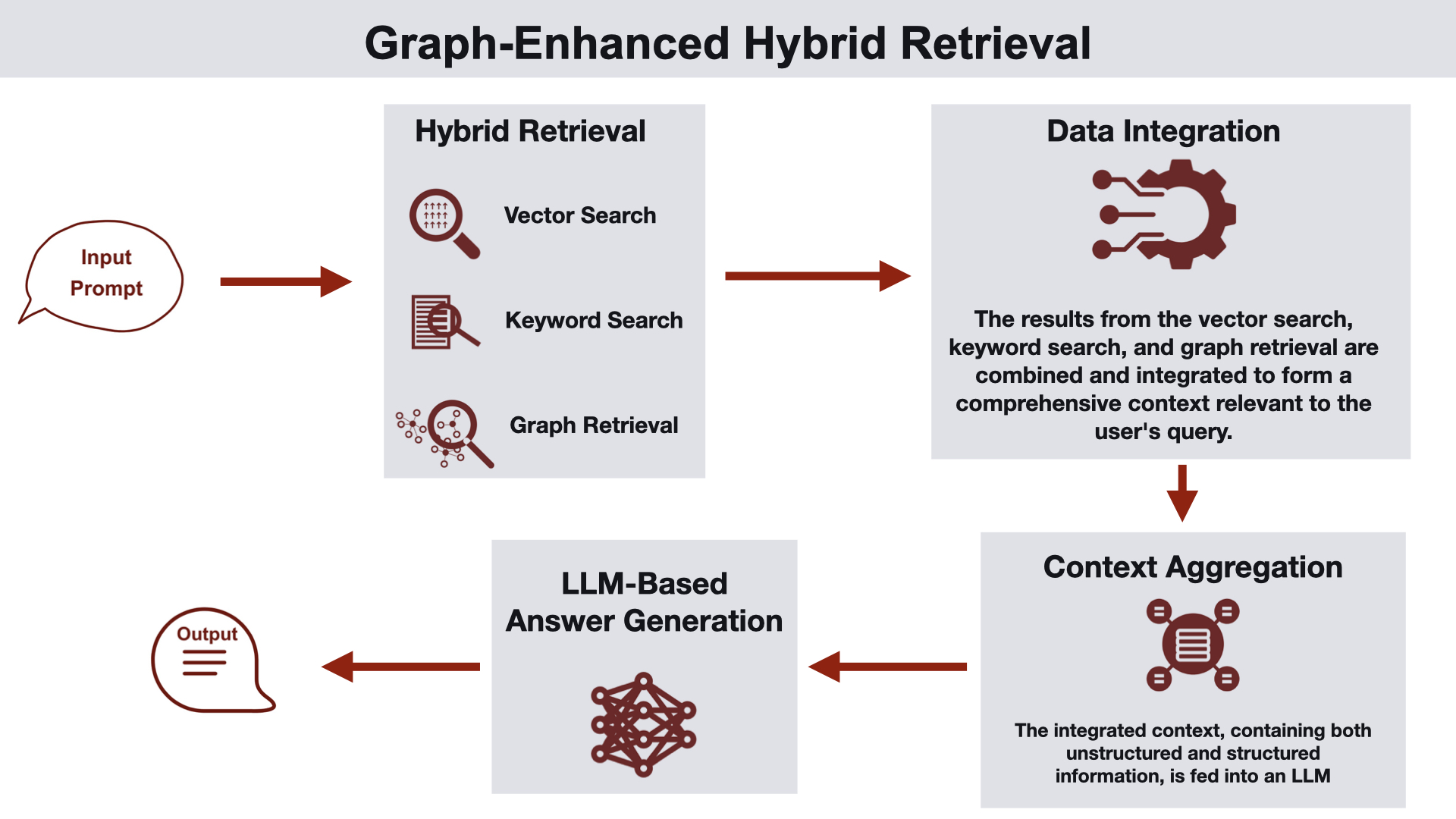
이 아키텍처는 벡터 검색, 키워드 검색, 그래프 특화 질의를 결합한 하이브리드 접근법을 사용합니다.
작동 방식
사용자가 질의를 제출합니다.
비구조화 데이터 검색과 그래프 데이터 검색 결과를 통합하는 하이브리드 검색 프로세스가 진행됩니다.
벡터 및 키워드 인덱스 검색 결과는 리랭킹이나 랭크 퓨전 기법으로 강화될 수 있습니다.
세 가지 검색 형태의 결과를 모두 결합하여 LLM을 위한 컨텍스트를 생성합니다.
LLM이 생성한 응답이 사용자에게 전달됩니다.
활용 사례: 기업 검색, 문서 검색, 지식 발견
지식 그래프 강화 질의응답 파이프라인
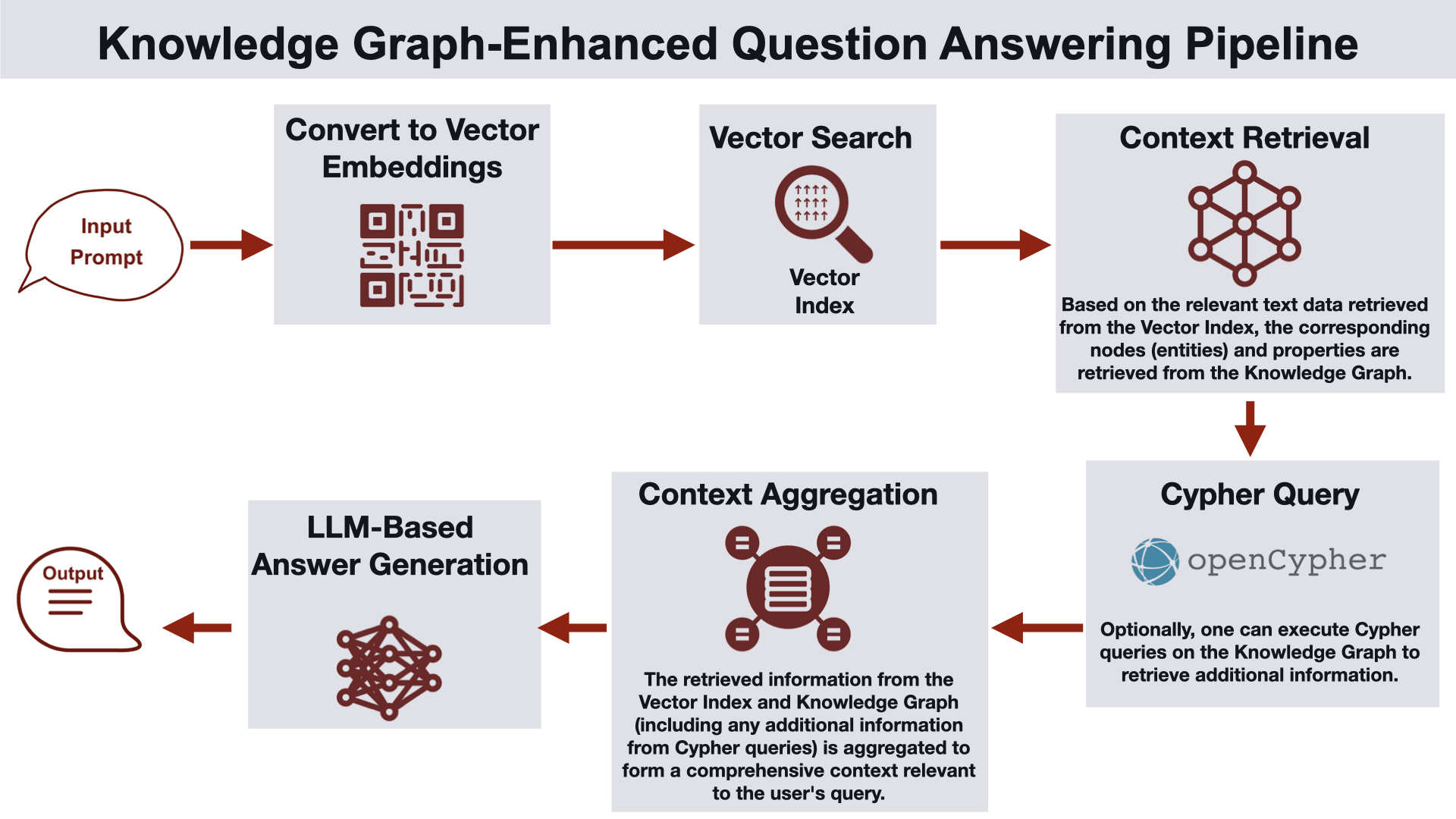
이 아키텍처는 벡터 검색 이후 단계에서 지식 그래프를 활용해 추가적인 사실로 응답을 강화합니다.
작동 방식
사용자가 질의를 제공합니다.
질의 임베딩이 계산됩니다.
벡터 인덱스에서 벡터 유사도 검색을 통해 지식 그래프의 관련 개체를 식별합니다.
그래프 데이터베이스에서 관련 노드와 속성을 검색하고, 발견되면 Cypher 질의를 실행해 추가 정보를 검색합니다.
검색된 정보를 종합하여 포괄적인 컨텍스트를 형성하고, 이를 LLM에 전달하여 응답을 생성합니다.
활용 사례: 의료나 법률과 같이 응답 내 개체에 기반한 표준 정보가 답변과 함께 포함되어야 하는 환경
지식 그래프 기반 질의 확장 및 생성
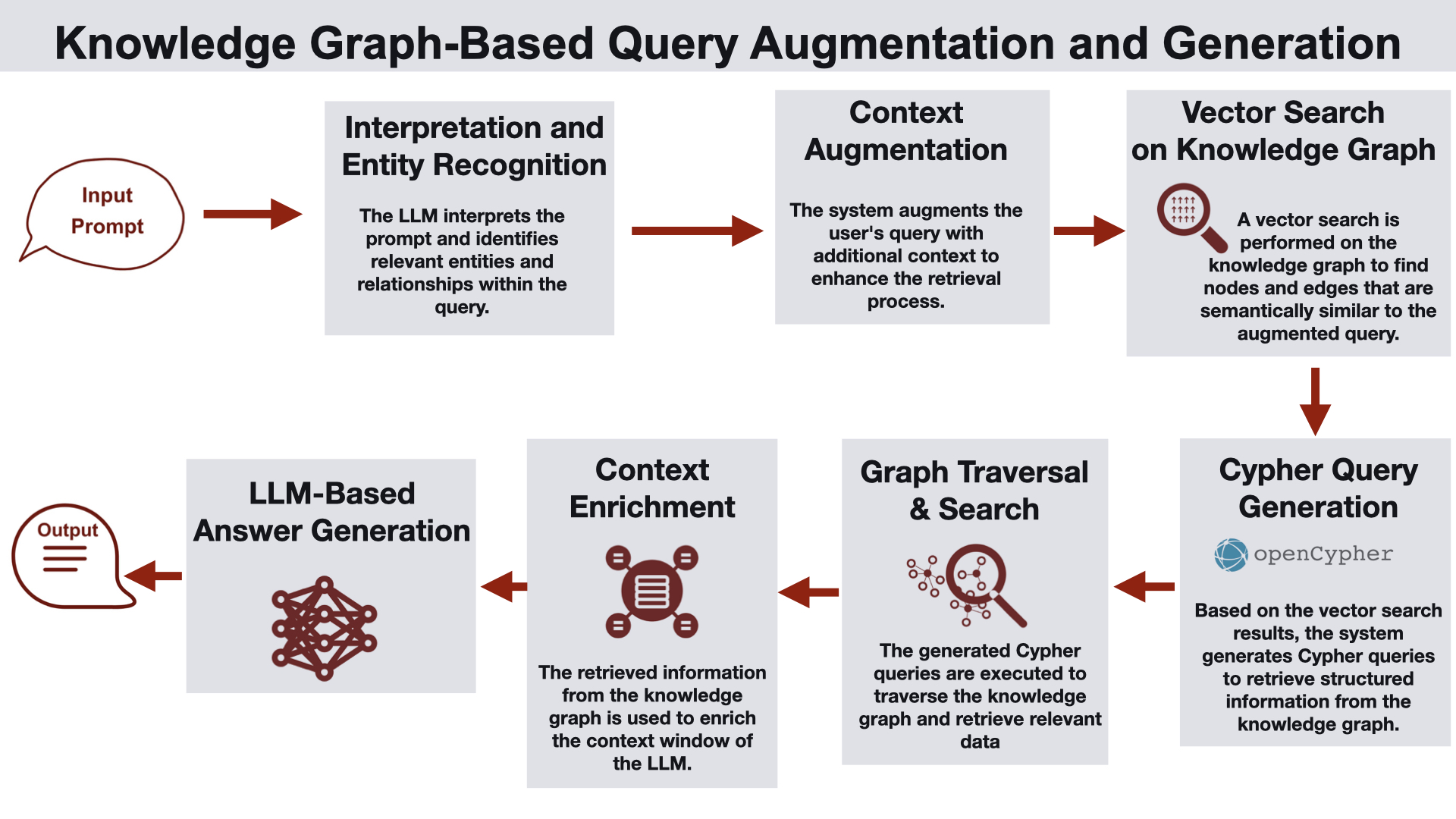
이 아키텍처는 벡터 검색 전에 지식 그래프를 활용해 관련 노드와 엣지를 탐색하여 LLM의 컨텍스트를 풍부하게 합니다.
작동 방식
첫 단계는 질의 확장으로, 사용자 질의가 LLM에 의해 처리되어 핵심 개체와 관계를 추출합니다.
지식 그래프 내 노드 속성에 대해 벡터 검색을 수행하여 관련 노드를 식별합니다.
다음 단계는 질의 재작성으로, 검색된 서브그래프에 대해 Cypher 질의를 생성하여 그래프에서 관련 구조화 정보를 좁힙니다.
그래프 탐색 결과를 LLM의 컨텍스트 창을 풍부하게 하는 데 사용합니다.
LLM은 향상된 컨텍스트를 기반으로 응답을 생성합니다.
활용 사례: 개체 간 관계가 중요한 제품 조회나 금융 보고서 생성
3.2. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval (Stanford Univ, 2024)
RAPTOR는 스탠포드 대학에서 개발한 특별한 RAG 기법으로, 긴 문서를 효과적으로 처리하기 위해 트리 구조의 계층적 색인을 활용합니다. 기존 RAG가 문서를 작은 청크로 나누어 독립적으로 검색하는 반면, RAPTOR는 문서 전체의 구조와 맥락을 보존하는 계층적 요약 트리를 구축합니다.
색인 과정
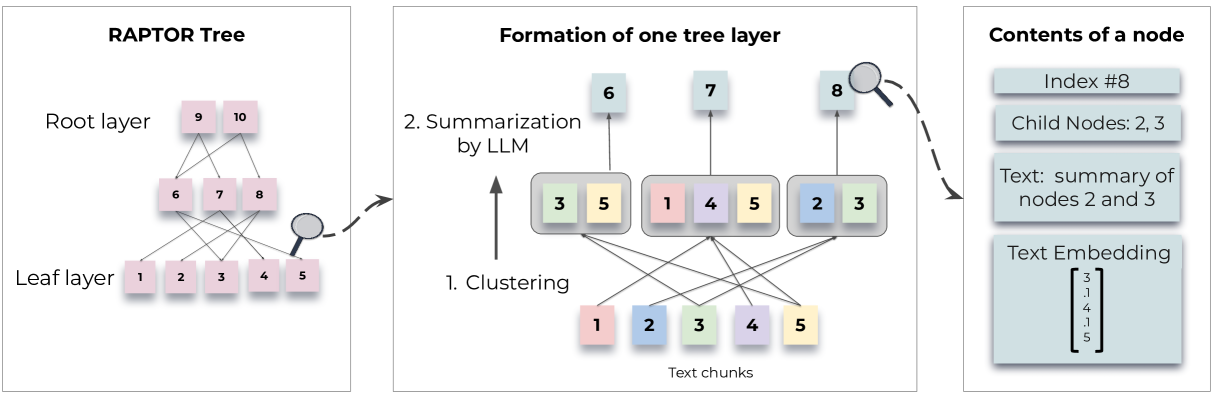
청크 분할
원본 문서를 약 100토큰 크기의 작은 청크로 분할합니다.
문장이 토큰 제한을 초과하면 문장 중간에서 자르지 않고 다음 청크로 이동시켜 의미적 일관성을 유지합니다.
임베딩 및 군집화:
각 청크는 SBERT(BERT 기반 인코더)를 통해 벡터로 임베딩됩니다.
가우시안 혼합 모델(GMM)을 사용해 의미적으로 유사한 청크들을 군집화합니다.
소프트 클러스터링으로 하나의 노드가 여러 군집에 속할 수 있게 합니다.
요약 노드 생성
각 군집의 청크들은 언어 모델(예:
GPT-3.5-turbo)을 통해 요약됩니다.요약 텍스트는 새로운 노드가 되어 다시 벡터로 임베딩됩니다.
재귀적 과정
임베딩-군집화-요약 과정을 더 이상 군집화가 불가능할 때까지 반복하여 다층 트리 구조를 형성합니다.
이 과정은 문서 규모에 따라 선형적인 계산 복잡성을 가집니다.
검색 과정
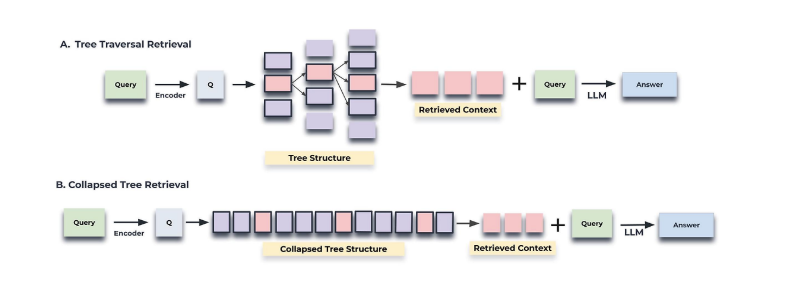
RAPTOR는 두 가지 고유한 검색 전략을 제공합니다.
트리 순회(Tree Traversal) 방식
루트 계층에서 시작하여 질의 임베딩과 해당 계층의 모든 노드 임베딩 간 코사인 유사도를 계산합니다.
유사도 점수가 가장 높은 상위 \(k\) 노드를 선택합니다(집합 \(S_1\)).
\(S_1\) 집합의 원소들의 자식 노드로 진행하여 질의 벡터와의 코사인 유사도를 계산합니다.
유사도 점수가 가장 높은 상위 \(k\)개 자식 노드를 선택합니다(집합 \(S_2\)).
이 과정을 \(d\)개 계층에 대해 반복하여 집합 \(S_1\)부터 \(S_d\)까지 생성합니다.
모든 집합을 연결하여 질의에 관련된 컨텍스트를 구성합니다.
이 방식은 계층 별로 상위 \(k\)개 노드만 고려하기 때문에 각 계층에서 정보의 양이 균일하게 유지됩니다.
축소 트리(Collapsed Tree) 방식
전체 RAPTOR 트리를 단일 계층으로 축소합니다.
질의 임베딩과 축소된 집합의 모든 노드 임베딩 간 코사인 유사도를 계산합니다.
유사도 점수가 가장 높은 노드부터 시작해 사전에 정의된 최대 토큰 수에 도달할 때까지 노드를 결과 집합에 추가합니다.
실험 결과, 축소 트리 방식이 트리 순회 방식보다 일관되게 더 나은 성능을 보였습니다. 이는 축소 트리 방식이 모든 노드를 동시에 고려함으로써 질문에 적합한 수준의 세부 정보를 검색할 수 있는 유연성을 제공하기 때문입니다.
3.3. From Local to Global: A Graph RAG Approach to Query-Focused Summarization (Microsoft Research, 2024)
마이크로소프트 리서치의 GraphRAG는 전통적인 RAG가 특정 질의에 관련된 단편적 정보를 찾는 한계를 넘어, "이 데이터셋의 주요 주제는 무엇인가?"와 같은 전체 데이터셋에 대한 포괄적인 질문에 효과적으로 답하기 위해 설계되었습니다.
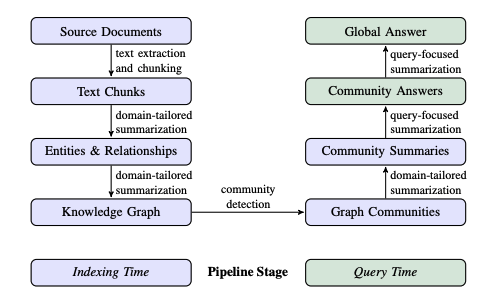
색인 과정
문서 청킹
소스 문서를 분석 가능한 크기로 청킹합니다.
각 청크는 독립적으로 처리되며 이후 그래프 구성에 사용됩니다.
개체 및 관계 추출
LLM을 활용하여 각 청크에서 중요 개체(인물, 장소, 조직, 개념 등)를 식별합니다.
개체 간 의미 있는 관계를 추출하고 짧은 설명을 생성합니다.
도메인 특화 프롬프트가 사용되어 관련성 높은 개체와 관계를 포착합니다.
지식 그래프 구축
추출된 개체와 관계는 노드와 엣지로 변환되어 그래프를 형성합니다.
개체 설명은 집계 및 요약되어 각 노드와 엣지에 첨부됩니다.
중복된 관계는 엣지 가중치로 표현되어 관계의 강도를 나타냅니다.
커뮤니티 탐지 및 요약
Leiden 알고리즘 같은 커뮤니티 탐지 알고리즘으로 그래프를 의미 있는 커뮤니티로 분할합니다.
계층적으로 수행되어 다양한 추상화 수준의 커뮤니티 구조를 형성합니다.
각 커뮤니티에 대해 LLM을 활용하여 보고서 형태의 요약을 생성합니다.
하위 레벨 커뮤니티의 요약은 상위 레벨 커뮤니티 요약 생성에 활용됩니다.
검색 과정
GraphRAG는 여러 검색 모드를 제공하며, 각 모드는 서로 다른 유형의 질의에 최적화되어 있습니다.
정적 글로벌 검색 (Static Global Search)
전체 데이터셋에 대한 종합적인 이해가 필요한 질의를 위한 방식입니다.
사전 정의된 커뮤니티 레벨 활용
지식 그래프의 특정 레벨(예: 레벨 1)에 있는 모든 커뮤니티 보고서를 검색합니다.
이 방식은 단순하지만 많은 토큰을 소비하며, 질의와 무관한 보고서도 모두 포함됩니다.
맵-리듀스(Map-Reduce) 프로세스
맵(Map) 단계: 각 커뮤니티 보고서를 대상으로 질의에 대한 답변과 관련성 점수를 생성합니다.
리듀스(Reduce) 단계: 관련성 점수에 따라 답변을 통합하여 최종 응답을 생성합니다.
동적 글로벌 검색 (Dynamic Global Search)
정적 글로벌 검색의 비효율성을 개선한 접근법입니다.
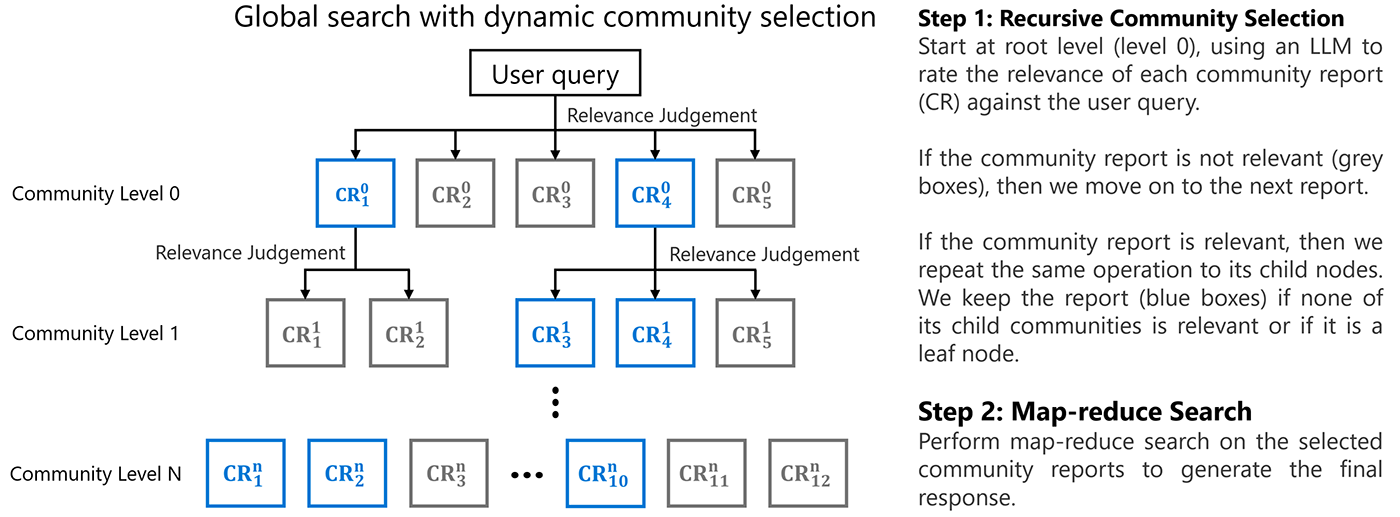
동적 커뮤니티 선택 프로세스
지식 그래프의 루트에서 시작하여 각 커뮤니티 보고서의 관련성을 LLM으로 평가합니다.
관련성이 낮은 보고서와 그 하위 노드는 검색 과정에서 제외됩니다.
관련성이 높은 보고서의 경우 하위 노드로 이동하여 평가를 계속합니다.
DRIFT(Dynamic Reasoning and Inference with Flexible Traversal) 검색
DRIFT 검색은 GraphRAG 환경에서 로컬 검색의 한계를 극복하기 위해 설계된 하이브리드 접근법입니다. 기존 로컬 검색이 단순히 질의와 유사한 텍스트 청크만 검색하는 한계를 넘어, 커뮤니티 정보를 활용해 더 풍부하고 포괄적인 답변을 제공합니다.

최초(Primer) 단계: 고수준 맥락 파악
질의 확장: 사용자 질의를 HyDE(Hypothetical Document Embeddings) 기법으로 확장하여 검색 민감도(recall)를 높입니다. HyDE는 원래 질의에서 가상의 이상적인 문서를 생성한 후, 그 문서를 임베딩하여 검색에 활용하는 기법입니다.
커뮤니티 보고서 검색: 확장된 질의를 임베딩하고, 이를 모든 커뮤니티 보고서와 비교하여 의미적으로 가장 관련성 높은 상위 \(K\)개의 보고서를 선택합니다. 이 보고서들은 GraphRAG의 글로벌 인덱스에서 나온 것으로, 데이터셋의 고수준 개요를 제공합니다.
초기 답변 생성: 선택된 커뮤니티 보고서를 LLM에 제공하여 초기 답변을 생성합니다.
후속 질문 생성: 동시에 LLM은 원래 질의를 기반으로 더 세부적인 후속 질문들을 생성합니다. 이 질문들은 초기 답변에서 누락된 정보나 더 상세한 탐색이 필요한 영역을 대상으로 합니다.
후속(Follow-Up) 단계: 세부 정보 탐색
로컬 검색 실행: 각 후속 질문에 대해 일반적인 로컬 검색 변형을 실행합니다. 이는 원래 텍스트 청크 레벨에서 가장 관련성 높은 내용을 찾는 과정입니다.
중간 답변 생성: 각 후속 질문에 대한 로컬 검색 결과를 바탕으로 중간 답변을 생성합니다.
반복적 정제: 이러한 중간 답변에서 다시 새로운 후속 질문이 생성될 수 있으며, 이는 정보 탐색의 반복적인 루프를 형성합니다. 일반적으로 시스템은 2회 반복 후 종료합니다.
출력 계층 구조(Output Hierarchy) 단계: 결과 통합
계층적 구조화: 모든 질문과 답변이 원래 질의와의 관련성에 따라 순위가 매겨진 계층 구조로 조직됩니다.
맵-리듀스 통합: 벤치마크 테스트에서는 단순한 맵-리듀스 접근법을 사용하여 모든 중간 답변을 동등하게 가중치를 두고 집계했습니다.
최종 응답 생성: 집계된 정보를 바탕으로 사용자의 원래 질의에 대한 최종 응답이 생성됩니다.
이 접근법의 장점은 고수준의 개요에서 시작하여 점진적으로 세부 정보를 탐색하는 방식으로, 단일 검색 과정에서 놓칠 수 있는 중요한 정보를 포착할 수 있다는 것입니다.
자동 튜닝 (Auto-Tuning)
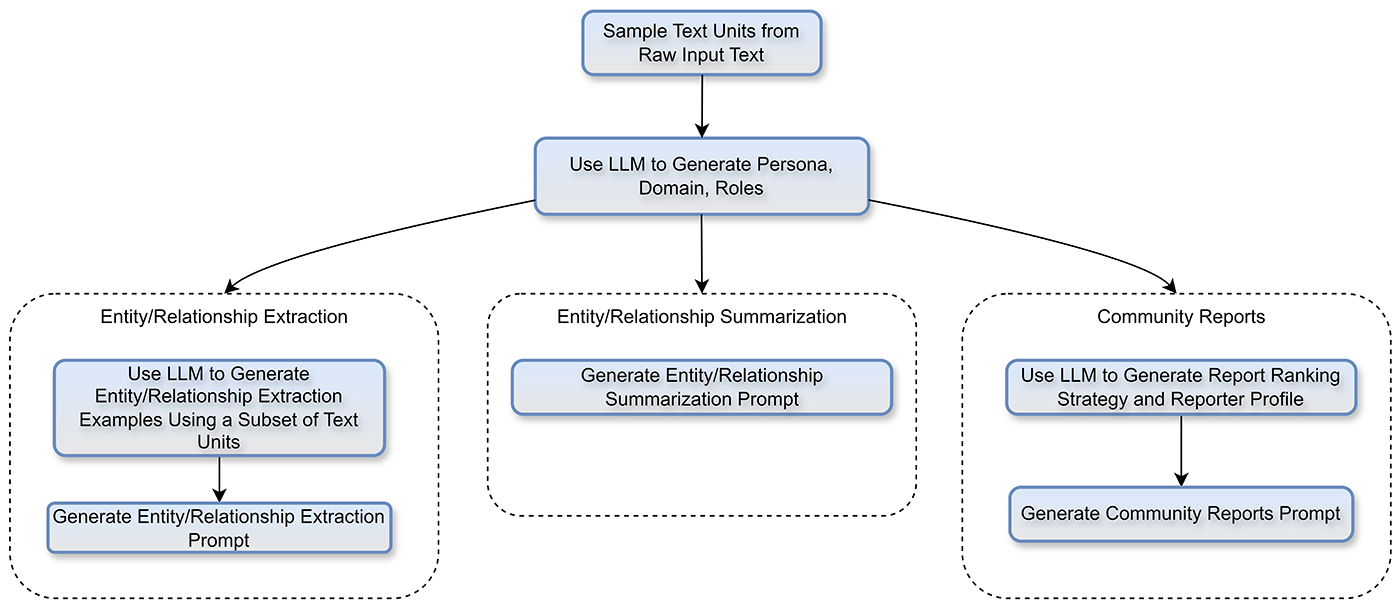
GraphRAG의 강점 중 하나는 새로운 도메인에 빠르게 적응할 수 있는 자동 튜닝 능력입니다.
도메인 및 페르소나 식별
소스 콘텐츠의 샘플(전체 데이터의 약 1%)을 LLM에 전송합니다.
LLM이 도메인을 식별하고 적절한 페르소나를 생성합니다.
이 페르소나는 추출 프로세스를 조정하는 데 사용됩니다.
도메인 특화 프롬프트 생성
도메인과 페르소나가 확립되면, 여러 프로세스가 병렬로 실행되어 맞춤형 색인 프롬프트를 생성합니다.
예시 기반의 프롬프트는 실제 도메인 데이터에 기반하여 생성됩니다.
기본 개체 유형(인물, 조직, 지역 등)을 넘어 도메인 특화 개체(예: 화학의 '분자', '반응')를 식별합니다.
마이크로소프트의 GraphRAG는 기존 요약 기법과 비교하여 포괄성과 다양성 측면에서 월등한 성능을 보이며, 특히 대규모 데이터셋에서 글로벌 질문에 대한 응답 품질이 크게 향상되었습니다. 이 접근법은 로컬 세부 정보와 글로벌 맥락 사이의 균형을 자동으로 찾아내어 다양한 사용 사례에 적용할 수 있는 유연하고 효과적인 솔루션을 제공합니다.
4. AWS GraphRAG Toolkit
AWS GraphRAG 툴킷은 Graph RAG 개념을 AWS 클라우드 환경에서 쉽게 구현할 수 있는 파이썬 기반 오픈소스 프레임워크입니다. LlamaIndex 라이브러리를 활용해 비정형 텍스트로부터 자동으로 그래프를 구축하고 벡터 인덱싱을 수행하며, LLM 질의에 대한 그래프 기반 검색을 지원합니다.
4.1. 그래프 모델 설계
AWS GraphRAG 툴킷은 세 개의 계층으로 구성된 어휘적 그래프 모델을 사용합니다.

1. 계통(Lineage) 계층
소스(Source) 노드
원본 문서의 메타데이터(작성자, URL, 발행일 등)를 저장합니다.
문서 출처를 추적하고 검증하는 데 중요한 역할을 합니다.
청크(Chunk) 노드
실제 텍스트 내용과 해당 텍스트의 임베딩을 저장합니다.
이전/다음, 부모/자식 청크와의 관계를 통해 원본 문서의 구조적 맥락을 유지합니다.
계통 계층은 문서의 원본 구조와 출처를 보존함으로써 정보의 계보를 추적할 수 있게 합니다. 이는 특히 정보의 신뢰성과 검증이 중요한 엔터프라이즈 환경에서 큰 가치를 제공합니다.
2. 개체-관계(Entity-Relationship) 계층
이 계층은 문서 내 주요 개체와 그들 간의 관계를 표현하여 그래프의 핵심 구조를 형성합니다.
개체(Entity) 노드
값(예: 'Amazon')과 분류(예: 'Company')를 포함합니다.
키워드 기반 검색의 진입점 역할을 수행합니다.
사람, 장소, 조직 등 실세계 개체를 표현합니다.
관계(Relation) 엣지
개체 간 관계(예: 'WORKS_FOR', 'LOCATED_IN')를 정의합니다.
선호 개체 분류 목록으로 가이드되어 일관성을 유지합니다.
개체-관계 계층은 문서 내에서 발견된 주요 개체와 그들 간의 관계를 표현합니다. 이는 그래프의 핵심 구조를 형성하며, 특히 키워드 기반의 '상향식'(bottom-up) 검색에서 중요한 시작점 역할을 합니다.
3. 요약(Summarization) 계층
주제(Topic) 노드
특정 소스 문서 내의 주제나 테마를 표현합니다.
단일 소스 내 관련 청크들을 연결하는 지역적 연결점 역할을 합니다.
여러 청크에 걸친 동일 주제를 하나로 묶어 문서 수준의 요약을 제공합니다.
서술(Statement) 노드
독립된 주장이나 서술 단위로, LLM 질의 응답 시 제공되는 주요 컨텍스트 단위입니다.
주제 노드 아래 그룹화되며, 연결 리스트로 순서가 유지됩니다.
사실 노드들과 연결되어 의미 관계를 형성합니다.
질의 응답 시 LLM에 제공되는 기본 컨텍스트 단위입니다.
사실(Fact) 노드
주어-술어-목적어(SPO) 또는 주어-술어-보어(SPC) 형태의 단일 사실 단위입니다.
여러 문서에서 언급된 동일 사실을 단일 노드로 표현해 문서 간 글로벌 연결성을 제공합니다.
서술 노드를 지원(SUPPORTS)하는 관계를 형성합니다.
문서 간 정보를 연결하는 다리 역할을 수행합니다.
요약 계층은 원본 텍스트를 다양한 수준의 추상화로 구조화하여, 질의에 가장 적합한 수준의 정보를 제공할 수 있게 합니다. '주제'는 문서 내 로컬 연결성을, '사실'은 문서 간 글로벌 연결성을 제공하여 강력한 검색 기반을 형성합니다.
4.2. 색인 과정
AWS GraphRAG 툴킷의 색인은 두 개의 주요 단계로 구성됩니다.
1. 추출 단계 (Extract)
문서 청킹 (선택적)
LlamaIndex
SentenceSplitter등을 사용해 문서를 일정 크기의 청크로 분할합니다.기본 설정은 크기 256 토큰, 중복 20 토큰이지만 사용자 지정 가능합니다.
문장의 의미적 일관성을 유지하기 위해 문장 단위로 분할을 수행합니다.
명제(Proposition) 추출 (선택적)
LLM이 각 청크의 내용을 단순화된 명제 형태로 변환합니다.
복잡한 문장을 더 간단한 문장으로 분해하고, 대명사를 구체적인 이름으로 대체합니다.
약어를 가능한 경우 풀어서 표현하여 후속 추출 작업의 품질을 향상시킵니다.
추출된 명제는
aws::graph::propositions메타데이터 키로 저장됩니다.
개체/관계/주제/서술/사실 추출 (필수)
LLM이 이전 단계의 명제(또는 소스 청크)을 분석합니다.
개체와 그 분류(classification)를 추출하고, 개체 간 관계를 식별합니다.
텍스트의 주제에 따라 주제 단위로 내용을 그룹화합니다.
독립적 의미를 가진 서술과 트리플 형태의 사실을 추출합니다.
추출된 모든 정보는
aws::graph::topics메타데이터 키로 저장됩니다.
추출 단계는 비정형 텍스트를 구조화된 그래프 요소로 변환하는 핵심 과정입니다. 특히 LLM을 이용한 명제 추출은 정보의 품질을 향상시키지만, 성능과 비용을 고려하여 선택적으로 적용할 수 있습니다.
2. 구축 단계 (Build)
노드 변환
추출 단계에서 생성된 메타데이터를 소스, 청크, 주제, 서술, 사실 노드로 변환합니다.
각 노드에는
aws::graph::index메타데이터가 포함되어 벡터 인덱싱에 활용됩니다.
그래프 구성
변환된 노드와 관계를 그래프 데이터베이스에 저장합니다.
노드 간 관계(SUPPORTS, NEXT 등)를 설정하여 그래프 구조를 완성합니다.
벡터 인덱싱
청크와 서술 노드의 임베딩을 생성하고 벡터 스토어에 인덱싱합니다.
선택적으로 팩트와 토픽도 임베딩하여 다양한 수준의 검색을 지원할 수 있습니다.
구축 단계는 추출된 정보를 실제 그래프 및 벡터 스토어에 저장하는 과정입니다. 이 과정을 통해 검색 가능한 지식 그래프가 완성됩니다.
3. 연속 적재와 배치 처리
연속 적재
extract_and_build()메소드로 추출과 구축을 동시에 실행합니다.마이크로 배치 처리로 추출 시작 직후 그래프 구축이 시작되어 즉시 사용 가능합니다.
실시간 업데이트가 필요한 시나리오에 적합합니다.
분리 실행
extract()와build()를 별도로 실행하여 처리를 분리합니다.S3BasedDocs나FileBasedDocs를 사용해 중간 결과를 저장하고 재사용할 수 있습니다.대규모 데이터셋이나 다양한 환경(개발/테스트/프로덕션)에서의 활용에 유용합니다.
체크포인트 관리
Checkpoint인스턴스로 처리 상태를 관리하여 중복 처리를 방지합니다.실패 후 재시작 시 이미 성공적으로 처리된 청크를 건너뛰어 효율성을 높입니다.
그래프 구축이 완료된 청크만 체크포인트로 표시하여 일관성을 유지합니다.
배치 처리 최적화
배치 설정(
batch_config)을 통해 대규모 데이터 처리를 최적화합니다.Amazon Bedrock 배치 추론과 통합하여 LLM 호출 비용을 절감할 수 있습니다.
병렬 처리를 위한 작업자(worker) 수와 배치 크기를 조정하여 성능을 최적화합니다.
색인 프로세스는 유연하게 구성할 수 있어 다양한 규모와 요구사항에 맞게 조정이 가능합니다. 특히 체크포인트와 배치 처리는 대규모 데이터셋을 효율적으로 처리하는 데 중요한 역할을 합니다.
4.3. 검색 과정
AWS GraphRAG 툴킷은 두 가지 주요 검색기를 제공하여 다양한 검색 요구에 대응합니다.
1. TraversalBasedRetriever
TraversalBasedRetriever는 그래프 순회를 통한 검색 방식으로, 두 가지 보완적 전략을 활용합니다.
청크 기반 검색: 하향식 (Top-down) 접근법
벡터 유사도를 활용해 질의와 관련성 높은 청크를 식별합니다.
찾은 청크에서 주제로 이동하고, 다시 관련 서술과 사실로 확장합니다.
질의와 직접적인 의미 유사성이 있는 영역에 집중하여 깊이 있는 정보를 제공합니다.
설정 가능한
vss_top_k와vss_diversity_factor매개변수로 결과의 양과 다양성을 조정합니다.
개체 기반 검색: 상향식 (Bottom-up) 접근법
질의에서 키워드(개체명, 약어, 동의어 등)를 추출합니다.
추출된 키워드로 그래프에서 관련 개체를 식별하고, 확장된 개체까지 포함할 수 있습니다.
개체에서 시작해 사실을 거쳐 서술과 주제로 확장합니다.
max_keywords매개변수로 추출할 키워드 수를 제한하여 관련성을 유지합니다.
서술 재순위화
최종 결과 반환 전 서술을 재순위화하여 질의와의 관련성을 높입니다.
TF-IDF 방식(
tfidf)이나 모델 기반 방식(model)을 선택할 수 있습니다.max_statements매개변수로 반환할 서술 개수를 제한하여 컨텍스트 크기를 조절합니다.
복잡 질의 분해
derive_subqueries옵션으로 복잡한 질의를 여러 하위 질의로 분해할 수 있습니다.max_subqueries매개변수로 생성할 하위 질의의 최대 개수를 제한합니다.각 하위 질의에 대한 검색 결과를 통합하여 보다 포괄적인 응답을 생성합니다.
TraversalBasedRetriever는 그래프의 구조적 탐색을 통해 직접적인 의미 유사성뿐만 아니라 관계를 통한 관련 정보도 발견할 수 있어, 복잡한 질의에 대한 포괄적인 답변을 제공할 수 있습니다.
2. SemanticGuidedRetriever
SemanticGuidedRetriever는 벡터 검색과 그래프 순회를 통합한 하이브리드 접근법으로, 세 가지 하위 검색기를 활용합니다.
StatementCosineSimilaritySearch
서술 임베딩과 질의 임베딩 간 코사인 유사도를 계산합니다.
top_k매개변수로 지정된 수의 가장 유사한 서술을 반환합니다.의미적 유사성에 기반한 직접적인 검색 방식으로, 질의와 관련된 정확한 정보를 찾는 데 효과적입니다.
KeywordRankingSearch
질의에서 추출한 키워드와 동의어를 활용한 검색을 수행합니다.
서술 내 키워드 매칭 수에 따라 순위를 결정하며, 더 많은 키워드가 매칭될수록 높은 순위를 받습니다.
max_keywords매개변수로 추출할 키워드 수를 제한하고,top_k로 반환할 결과 수를 제한합니다.직접적인 키워드 매칭을 통해 관련 정보를 찾아내는 데 유용합니다.
SemanticBeamGraphSearch
빔 서치 알고리즘을 활용한 그래프 탐색을 수행합니다.
서술 간의 공유하는 개체를 기반으로 이웃 서술을 탐색합니다.
후보 서술과 질의 간 코사인 유사도를 계산하여 가장 유망한 경로를 따라 탐색합니다.
max_depth로 탐색 깊이를,beam_width로 각 단계에서 유지할 후보 수를 제한합니다.직접적인 유사성이 낮아도 관계를 통해 관련된 정보를 발견할 수 있습니다.
RerankingBeamGraphSearch
SemanticBeamGraphSearch의 변형으로, 코사인 유사도 대신 재순위화 모델을 사용합니다.BGEReranker(GPU 환경) 또는SentenceReranker(CPU 환경)를 활용할 수 있습니다.보다 정교한 관련성 평가를 통해 더 정확한 빔 서치를 수행합니다.
계산 비용이 높지만 더 정확한 결과를 제공할 수 있습니다.
후처리 옵션
BGEReranker/SentenceReranker: 모델 기반 재순위화로 최종 결과 품질을 높입니다.StatementDiversityPostProcessor: TF-IDF 유사도 기반으로 중복 서술을 제거합니다.EnrichSourceDetails: 소스 메타데이터를 추가하여 정보의 출처를 명확히 합니다.StatementEnhancementPostProcessor: LLM을 활용해 서술의 내용을 풍부하게 만듭니다.
SemanticGuidedRetriever는 의미적 유사성과 그래프 구조를 모두 활용하여 질의와 직접적으로 유사하지 않더라도 관련된 정보를 효과적으로 발견할 수 있습니다. 특히 복잡한 질의나 다양한 관점이 필요한 경우에 유용합니다.
4.4. 기타
AWS GraphRAG 툴킷은 그래프 구축과 검색 과정에서 분리된 그래프 스토어와 벡터 스토어를 활용하며, AWS의 기존 보안 메커니즘과 통합됩니다.
이중 스토리지 아키텍처
그래프 스토어: Amazon Neptune, Neptune Analytics 또는 FalkorDB에 개체, 관계, 서술, 사실 등 그래프 요소 저장
벡터 스토어: Amazon OpenSearch Serverless 또는 Neptune Analytics에 청크 및 서술 임베딩 저장
성능 최적화 옵션
배치 추출: Amazon Bedrock 배치 추론을 활용한 대규모 데이터셋 처리
GraphRAGConfig: 작업자 수, 배치 크기, 캐싱 등 시스템 성능 설정응답 캐싱: LLM 호출 결과를 로컬 파일시스템에 저장하여 중복 호출 최소화
AWS GraphRAG 툴킷은 기존 벡터 검색 기반 RAG의 한계를 극복하고, 그래프 구조를 활용해 더 포괄적이고 정확한 정보 검색을 가능하게 합니다. 특히 복잡한 질의, 다단계 추론이 필요한 질의, 또는 문서 간 연결이 중요한 시나리오에서 뛰어난 성능을 발휘합니다.
5. 그래프 RAG 접근법 비교 및 결론
| 접근법 | 인덱싱 단계 | 사전 검색 단계 | 검색 단계 | 사후 검색 단계 |
| 지식 그래프와 의미 기반 클러스터링 | • 지식 그래프 구축 | • 그래프 탐색 | • 의미적 클러스터링 | |
| 지식 그래프와 벡터 DB 통합 | • 문서 벡터화 • 지식 그래프 구축 | • 벡터 검색 • 그래프 탐색 | ||
| 그래프 강화 하이브리드 검색 | • 문서 벡터화 • 키워드 색인 • 지식 그래프 구축 | • 벡터 검색 • 키워드 검색 • 그래프 탐색 | • 리랭킹 또는 랭크 퓨전 | |
| 지식 그래프 강화 Q&A 파이프라인 | • 문서 벡터화 • 지식 그래프 구축 | • (청크에 대한) 벡터 검색 • (개체 및 속성에 대한) 그래프 탐색 | ||
| 지식 그래프 기반 질의 확장/생성 | • 지식 그래프 구축 • 노드 속성 벡터화 | • LLM으로 개체/관계 추출 • 질의 확장 | •(개체 및 관계에 대한) 벡터 검색 • 그래프 탐색 | |
| RAPTOR | • 문서 벡터화 • 클러스터링 • LLM 기반 요약 • 재귀적 구조화 | • 질의 벡터화 | • 트리 순회 방식: 계층별 유사도 기반 노드 선택 • 축소 트리 방식: 전체 트리를 단일 계층으로 축소 후 벡터 검색 | |
| GraphRAG (Microsoft) | • LLM으로 개체/관계 추출 • 지식 그래프 구축 • 커뮤니티 탐지 (Leiden 알고리즘) • 커뮤니티별 요약 생성 | • 질의 확장 (HyDE 기법) • 후속 질문 생성 | • 정적/동적 글로벌 검색: 커뮤니티 보고서 활용 • DRIFT 검색: 글로벌+로컬 하이브리드 접근 | • 맵-리듀스 기반 통합 • 출력 계층 구조화 |
| GraphRAG Toolkit (AWS) | • LLM으로 명제/개체/관계/주제/서술/사실 추출 • 지식 그래프 구축 • 청크 및 서술 벡터화 | • 키워드 추출 • 복잡 질의 분해 | • TraversalBasedRetriever: 하향식/상향식 검색 • SemanticGuidedRetriever: 코사인 유사도, 키워드 랭킹, 빔 서치 | • 서술 재순위화 • 다양성 처리 • 소스 정보 강화 • 서술 내용 강화 |
지금까지 살펴본 그래프 RAG 접근법들은 전통적인 벡터 기반 RAG의 한계를 극복하고 더 풍부하고 정확한 정보 검색을 가능하게 합니다. 핵심 인사이트는 다음과 같습니다.
구조적 이점: 모든 접근법에서 공통적으로 그래프 구조가 문서 간 관계를 보존하고 맥락을 유지하는 데 중요한 역할을 합니다. 이는 단순 벡터 유사도만으로 놓칠 수 있는 연관 정보를 발견하는 데 도움이 됩니다.
복합적 검색 전략: 대부분의 접근법이 벡터 검색, 키워드 검색, 그래프 탐색을 결합한 하이브리드 방식을 채택하고 있습니다. 이러한 복합 전략은 각 방식의 장점을 최대화하여 보다 정확하고 포괄적인 정보 검색을 가능하게 합니다.
계층적 구조화: RAPTOR와 MS GraphRAG, AWS GraphRAG 모두 문서를 다양한 추상화 수준으로 계층화하는 방식을 사용합니다. 이를 통해 질의의 복잡성과 요구에 따라 적절한 상세도의 정보를 제공할 수 있습니다.
LLM 활용: 모든 접근법에서 LLM은 단순한 응답 생성 외에도 개체 추출, 요약 생성, 질의 확장 등 다양한 단계에서 활용됩니다. 이는 그래프 구조의 품질과 검색 효율성을 크게 향상시킵니다.
확장성과 효율성: 특히 AWS GraphRAG와 MS GraphRAG는 대규모 데이터셋 처리를 위한 최적화 기능(배치 처리, 자동 튜닝 등)을 제공하여 기업 환경에서의 실용성을 높입니다.
그래프 RAG는 아직 발전 중인 영역이지만, 이미 복잡한 질의에 대한 처리 능력, 다단계 추론 지원, 문서 간 연결성 활용 등에서 기존 RAG 시스템보다 우수한 성능을 보여주고 있습니다. 앞으로는 그래프 구조 생성의 효율성 개선, 다양한 데이터 타입 지원, 실시간 그래프 업데이트 등의 영역에서 더 많은 발전이 이루어질 것으로 예상됩니다.
참조
논문
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval (Stanford Univ.)
From Local to Global: A Graph RAG Approach to Query-Focused Summarization (Microsoft)
블로그
GraphRAG: Unlocking LLM Discovery on Narrative Private Data (Microsoft)
GraphRAG: New Tool for Complex Data Discovery Now on GitHub (Microsoft)
GraphRAG Auto-Tuning Provides Rapid Adaptation to New Domains (Microsoft)
Introducing DRIFT Search: Combining Global and Local Search Methods to Improve Quality and Efficiency (Microsoft)
GraphRAG: Improving Global Search via Dynamic Community Selection (Microsoft)
LazyGraphRAG: Setting a New Standard for Quality and Cost (Microsoft)
Introducing GraphRAG 1.0 (Microsoft)
Improving Retrieval Augmented Generation Accuracy with GraphRAG (AWS)
Using Knowledge Graphs to Build GraphRAG Applications with Amazon Bedrock and Amazon Neptune (AWS)
코드 리포지토리
Subscribe to my newsletter
Read articles from Jonas Kim directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jonas Kim
Jonas Kim
Sr. Data Scientist at AWS