[이어드림스쿨 1주차] IT Literacy (1)
 KiwiChip
KiwiChip컴퓨터의 이해
기계어
기계어는 0/1로 되어 있다.
0은 Off, 1은 On으로 해석된다.
컴퓨터를 위한 번역
- 코드 작성 → 인터프리터/컴파일러 → 기계어 번역 → 컴퓨터 인식
인터프리터/컴파일러의 프로그램 오류: 이 언어는 기계로 번역할 수 없다
Low Level vs High Level Language
기계어와 더 가까울수록 Low Level Language이고, 사람의 언어와 더 가까울수록 High Level Language이다.
Low Level Language일수록 프로그래머가 기계를 직접적으로 컨트롤할 수 있지만, 상대적으로 작업이 어렵고 실수할 확률이 높아진다. 이를 보완하기 위해 나온 것이 High Level Langauge이다.
웹/앱 서비스
클라이언트와 서버 (Front-end와 Back-end)
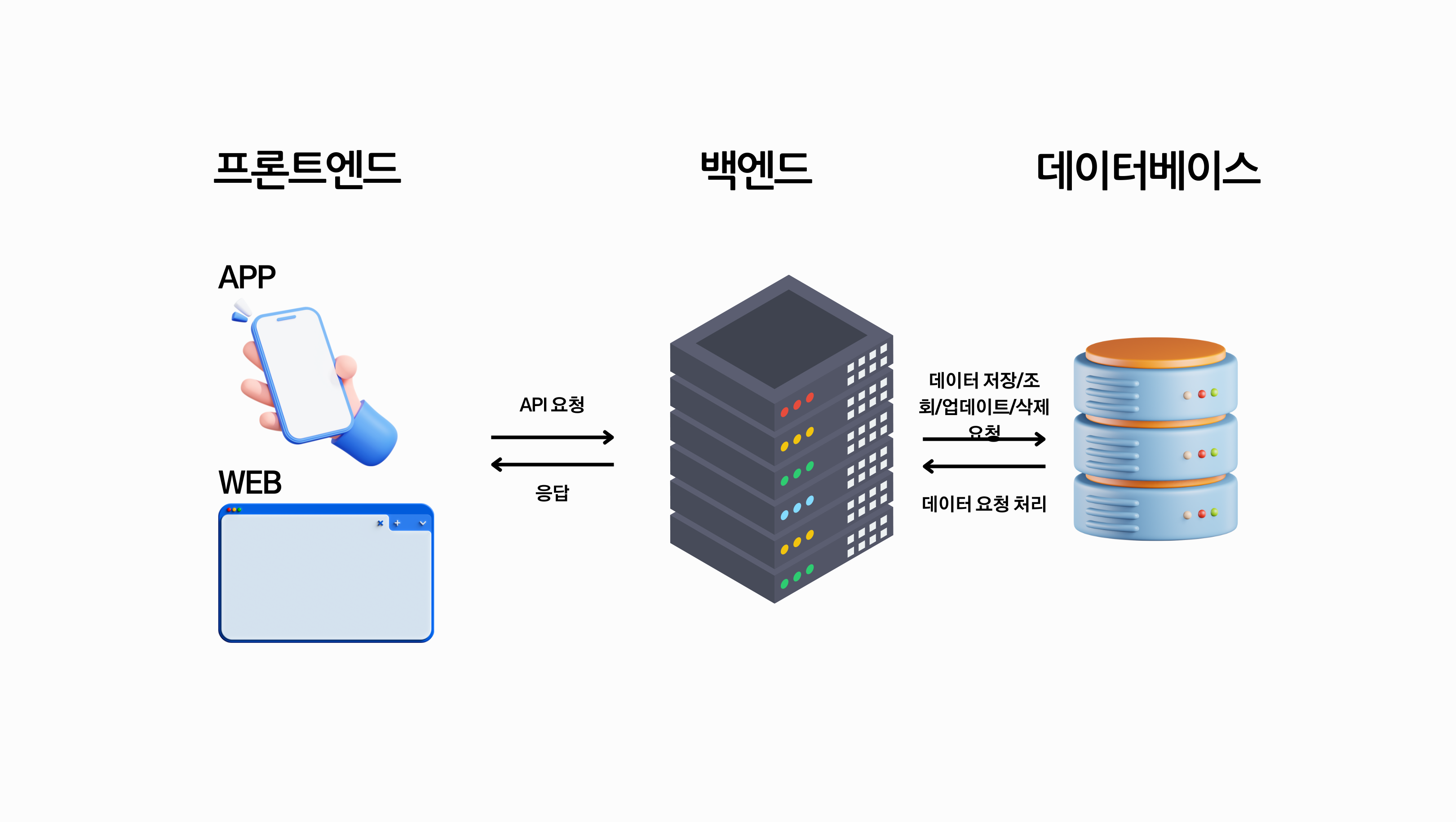
통신
컴퓨터 간의 대화(Coummunication)
기기 간 요청과 응답으로 이루어짐
1 요청, 1 응답 원칙
HTTP(Hyper Text Transform Protocol)
기기, 운영체제, 웹 브라우저에 상관없이 문자로 통신 가능
프로토콜(Protocol): 약속된 통신 방식
파싱(Parsing): 필요에 따라 문자를 특정한 형태로 잘라 사용하는 것
엔드 포인트(Endpoint): 웹 서버 구조를 가리키는 문자. 즉, URL이 Endpoint이다.
HTTP 통신 함수
GET: 기존의 저장된 정보, 페이지를 읽어옴
POST: 정보 저장 및 전달을 위해 서버에 전달하는 역할
PUT, PATCH: 이미 저장된 정보를 수정
- PUT의 보안적 이슈를 보완해서 나온 것이 PATCH 함수이다.
DELETE: 저장된 정보 삭제
프론트엔드
서버의 기능과 관계없는 독립적 기능들의 모음(ex. 카메라 촬영)
UI/UX
UI(User Interface): 사용자 사용 편의성을 위한 것, 디자인, 사용자에게 가장 가까운 화면, 보여지는 화면에 집중
- GUI(Graphics User Interface), CLI(Command Line Interface)
UX(User Experience): 사용자 경험을 고려해서 사용자에게 편리한 경험을 제공하는 것.
서버에 요청하기 위한 통신 기능
사용자 패턴 분석을 위한 Analytics 구현
반응형 화면
- 그리드 시스템: 반응형을 위해 일관된 규칙성 적용
백엔드
사용자에게 보이지 않는 서버 측 시스템으로, 비즈니스 로직을 처리하고 데이터베이스와 상호작용하는 역할
사용자의 요청을 받아 데이터를 생성, 조회, 수정, 저장하며, 보안적인 이유로 클라이언트에서 직접 접근할 수 없도록 보호됨
로그인, 결제, 데이터 저장 등의 핵심 기능이 백엔드에서 실행된다.
비즈니스 로직: 프로그램이 수행해야 하는 핵심 규칙과 처리 과정을 의미. 즉, 데이터를 생성, 조회, 변경, 삭제(CRUD)하는 모든 작업과, 특정 조건에 따라 수행되는 계산, 검증, 권한 확인 등의 로직이 포함된다.
REST API
약속된 지정된 주소(URI)를 갖고 있고, 각 주소에 기능(함수)를 가지고 있는 형태
URI vs URL: URI가 URL보다 더 큰 개념
URI: 서버에서의 특정 리소스 식별자 지칭
URL: 웹사이트 주소
프론트엔드와 백엔드 통신
- 프론트가 GET으로 요청을 하면, 백엔드도 반드시 GET으로 호응해야 한다.
동기(Synchronous)와 비동기(Asynchronous)
동기:
요청을 보낸 후 응답이 도착할 때까지 대기하는 방식
순차적으로 실행되며, 이전 작업이 끝나야 다음 작업이 진행됨
주로 요청과 응답의 순서가 중요한 경우 사용됨
동기 방식이 적절한 경우:
강의 목록에서 상세 페이지로 이동
강의 목록에서 특정 강의를 클릭하면 상세 정보를 보여주는 페이지로 이동해야 함
강의 정보가 불러와지기 전에는 이동하는 것이 의미가 없기 때문에, 데이터를 받아온 후 페이지 이동을 수행
저장된 명함 정보를 가져오는 페이지
사용자가 명함 정보를 요청하면 해당 데이터를 서버에서 가져와서 화면에 표시해야 함
데이터가 로드되기 전에 화면을 표시하면 정보가 없는 상태가 되므로, 데이터를 다 가져온 후 UI를 렌더링해야 함
일반적인 웹 페이지 이동
한 페이지에서 다른 페이지로 이동할 때, 브라우저가 요청을 보내고 서버에서 응답을 받아야 정상적으로 이동할 수 있음
페이지가 완전히 로드된 후에야 사용자 인터랙션이 가능하므로, 동기적인 방식이 적절함
정보와 함께 제공되어져야 하는 화면
사용자 요청 시, 필요한 정보와 함께 화면을 구성해야 하는 경우
예를 들어, 로그인 후 유저 정보를 기반으로 맞춤형 콘텐츠를 표시하는 대시보드
데이터가 먼저 로드되지 않으면 화면이 정상적으로 표시되지 않으므로 동기적인 흐름이 필요
비동기:
요청을 보낸 후 응답을 기다리지 않고 다른 작업을 수행하는 방식
UI가 멈추지 않고 사용자 경험(UX)을 개선할 수 있음
일반적으로 네트워크 요청, 데이터 로드, 사용자 인터랙션 등의 비차단(non-blocking) 작업에 사용됨
비동기 방식이 적절한 경우:
페이지 이동이 없는 댓글 달기
사용자가 댓글을 입력하고 제출하면, 페이지를 새로고침하지 않고 댓글이 추가됨
서버에 요청을 보내는 동안 사용자는 계속 다른 작업을 수행할 수 있어야 함
AJAX 또는 Fetch API를 사용하여 비동기적으로 댓글을 추가하고 화면을 업데이트
SNS 피드백
페이스북, 트위터, 인스타그램 등에서 새로운 피드가 자동으로 추가되는 경우
사용자가 새로고침하지 않아도 새로운 게시물이 나타나야 하므로, 비동기 방식으로 서버에서 데이터를 주기적으로 가져옴
동기와 비동기 방식은 각각의 장점과 단점이 있으며, 상황에 따라 적절한 방식을 선택해야 한다.
사용자가 즉시 데이터를 받아야 하는 경우(예: 상세 페이지 이동) → 동기 방식
백그라운드에서 데이터를 가져오면서 사용자 경험을 개선해야 하는 경우(예: SNS 피드 업데이트) → 비동기 방식
API (Application Programing Interface)
프로그램(Code)끼리 대화(응답과 요청)하도록 도와주는 일
네트워크를 통한 분리된 기기 사이의 통신
라이브러리 VS API:
라이브러리: 내부 코드에서 직접 활용하는 도구, 특정 기능을 쉽게 사용할 수 있도록 제공되는 코드 모음
API: 프로그램 간 상호작용을 위한 규칙과 인터페이스, 외부 시스템과 통신하는 인터페이스
Endpoint와 API:
API (Application Programming Interface)
소프트웨어 간의 상호작용을 위한 인터페이스
특정 기능을 수행하는 명령어, 규칙, 데이터 포맷을 정의
Endpoint
API의 특정 기능을 호출할 수 있는 URL 또는 URI
API 서버에서 요청을 받을 수 있는 고유한 경로
Open API:
누구나 사용할 수 있도록 공개된 API
특정 서비스나 플랫폼에서 제공하는 API를 개발자들이 자유롭게 활용할 수 있도록 개방한 것
- Google Maps API, Twitter API, GitHub API, Public Data API(공공 데이터 API) 등
데이터 베이스
데이터베이스
데이터를 체계적으로 저장하고 관리하는 시스템.
통장의 입/출금 기록
도서관에서의 도서 검색
온라인 쇼핑몰(예: 신발 재고 관리)
스마트폰 앱의 사용자 정보 저장
DBMS(Database Management System):
데이터베이스 운영 관리를 위한 소프트웨어
데이터 베이스 종류: 관계형 VS NoSQL
관계형: Primary Key라는 고유값을 활용해 연결에 유리함
ex. B 신발을 구매한 A 고객(B 신발 데이터 + A 고객 데이터)
장점:
데이터 간 연결이 용이 (Primary Key, Foreign Key 활용)
ACID(원자성, 일관성, 고립성, 지속성) 보장으로 데이터 무결성 유지
복잡한 쿼리 및 트랜잭션 처리에 강함 (JOIN, GROUP BY, 트랜잭션 지원)
데이터 모델이 명확하고 구조적 (스키마 기반)
단점:
수직 확장(Scale-up)이 어려움 (고성능 서버 필요)
데이터 구조가 엄격(스키마 변경이 어렵고 유연성이 낮음)
대량의 데이터 처리 성능이 낮음 (NoSQL보다 느릴 수 있음)
분산 처리가 어려움 (한 서버에서 실행되는 경우가 많음)`
NoSQL: 기록이 단순하고 대용량 처리에 유리
장점:
수평 확장(Scale-out)이 용이 → 클러스터링으로 서버 추가 가능
스키마가 유연 → 데이터 구조 변경이 쉬움
대량의 데이터 처리 속도 빠름 → 로그, SNS 데이터, IoT 등 실시간 데이터 처리에 강함
다양한 데이터 모델 지원 → 문서형(DB), 키-값 저장소, 그래프 DB 등 선택 가능
단점:
데이터 일관성(Consistency)이 약함 → 즉각적인 업데이트 반영이 어려울 수 있음
JOIN이 어려움 → 관계형 DB처럼 테이블 간 관계를 설정하기 어려움
ACID 트랜잭션 지원이 제한적 → 금융, ERP 같은 정밀한 데이터 관리에는 부적합
데이터 모델이 다양하여 학습 비용이 높음
관계형 DB vs NoSQL, 언제 사용해야 할까?
| 사용 사례 | 적합한 데이터베이스 |
| 데이터 정합성(무결성)이 중요한 경우 | 관계형 DB (예: 은행, 결제 시스템) |
| 데이터 연결이 중요한 경우 | 관계형 DB (예: 고객-상품-주문 관계) |
| 대량의 데이터를 빠르게 처리해야 하는 경우 | NoSQL (예: SNS, 실시간 로그 처리) |
| 자주 변경되는 데이터 구조가 필요한 경우 | NoSQL (예: 유저 프로필, JSON 기반 데이터) |
| 분산 환경에서 확장성이 필요한 경우 | NoSQL (예: 글로벌 서비스, 빅데이터) |
데이터베이스의 기본 기능(CRUD)
데이터베이스는 기본적으로 데이터를 저장(INSERT), 검색(SELECT), 수정(UPDATE), 삭제(DELETE)하는 기능을 제공한다.
저장(INSERT)
사람이 분류하기 쉽게 저장하는 것이 중요
서비스를 어떻게 운영할 것인가가 핵심 요소
검색(SELECT, FIND)
신상품 입고 목록 갱신
Query, Query문(데이터베이스 명령어)
데이터 베이스 정렬
- 특정한 값을 기준으로 데이터를 정렬할 수 있음
DB가 우리에게 오기까지:
웹 브라우저/스마트폰 → 서버 조회 요청 → DB 쿼리 조회 → 조회 결과 전달
사용자가 웹사이트에서 "운동화" 검색
서버가
SELECT * FROM 상품목록 WHERE 카테고리='운동화'쿼리를 실행데이터베이스가 운동화 목록을 반환
서버가 사용자에게 결과를 보여줌
수정(UPDATE)
- 기존 데이터를 수정하는 것
삭제(DELETE)
저장된 내용을 삭제하는 것
논리 삭제(Logical Delete) vs 물리 삭제(Physical Delete):
논리 삭제 (Logical Delete)
데이터를 실제로 삭제하는 것이 아니라, 삭제된 것으로 표시(
is_deleted = 1등)하여 유지데이터 복구가 가능하며, 기록을 남길 수 있음
예: 고객이 탈퇴 요청을 하면, 계정을 완전히 삭제하는 것이 아니라
status = 'inactive'로 변경
물리 삭제 (Physical Delete)
데이터를 데이터베이스에서 완전히 삭제하는 방식
삭제된 데이터는 복구할 수 없음
예: 관리자만 접근할 수 있는 데이터에서 오래된 로그를 완전히 삭제
데이터 베이스 설계
데이터베이스를 효과적으로 사용하려면 초기에 구조를 잘 설계하는 것이 중요
잘못된 설계는 성능 저하, 데이터 중복, 관리 어려움 등의 문제를 초래할 수 있음
예를 들어, 관계형 데이터베이스에서는 **정규화(Normalization)**를 통해 데이터 중복을 줄이고 일관성을 유지할 수 있음
✅ 설계 시 고려할 요소
어떤 데이터를 저장할 것인가?
데이터의 관계(예: 사용자와 주문 정보)는 어떻게 설정할 것인가?
데이터 검색이 빠르게 이루어지도록 인덱스를 설정할 것인가?
Subscribe to my newsletter
Read articles from KiwiChip directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
KiwiChip
KiwiChip
I'm currently learning Python and studying RAG (Retrieval-Augmented Generation).