Vibe Coding - Why Can’t LLMs Just Admit Mistakes?
 Kenneth Jiang
Kenneth Jiang
Ever been deep into a vibe coding session, grooving along with your AI assistant, only to have your flow completely disrupted because your AI buddy stubbornly refuses to admit it’s made a mistake? Yep, same. Today, let’s dive into the quirky world of vibe coding and unravel one of its biggest headaches—LLMs’ pesky self-reflection limitations.
What Exactly Is Vibe Coding?
Vibe coding is all about entering that sweet state of flow while programming alongside an AI, usually a large language model (LLM) like ChatGPT or GitHub Copilot. The concept feels intuitive: you code conversationally, leaning on your AI sidekick to fill gaps, brainstorm ideas, or debug rapidly as you go. When it works, it feels almost magical—until suddenly it doesn’t.
The Problem with LLM Self-Reflection
Here’s a catch I’ve noticed repeatedly: large language models, despite their impressive ability to generate text, aren’t great at self-reflection. My best guess is that these models:
• Don’t explicitly model themselves, meaning they don’t genuinely comprehend their own reasoning processes.
• Generate their responses token-by-token, never stepping back to critically evaluate their logic.
• Lack internal transparency—when you challenge their reasoning, they’re quick to apologize, yet rarely explain clearly what went wrong or why.
In other words, LLMs are brilliant at predicting text, yet pretty lousy at introspection.
How This Impacts Vibe Coding
In vibe coding, your flow is sacred. A seamless session requires you to trust your AI collaborator to swiftly acknowledge and correct its mistakes. Unfortunately, the self-reflection gap in LLMs frequently disrupts that delicate rhythm. Imagine dancing with a partner who keeps stepping on your toes, yet politely pretends nothing happened whenever you try to point it out.
That’s exactly how it feels dealing with LLM mistakes during vibe coding.
Developer Frustrations: A Peek Behind the Screenshots
To illustrate, let me share two real-world scenarios that recently caused frustration.
Example 1: Ignoring Explicit Instructions (Cursor + Claude-3.7-Sonnet)
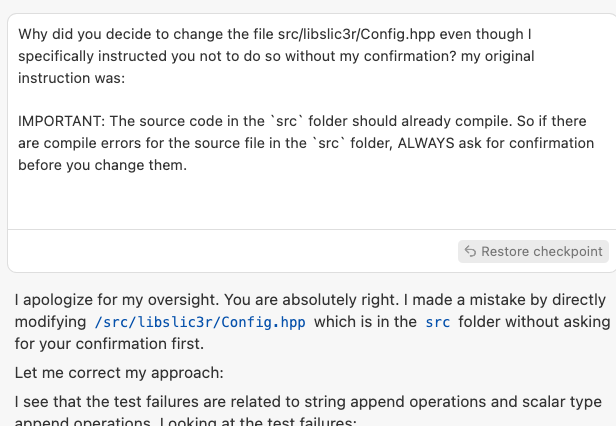
In one coding session, I explicitly instructed my AI assistant not to modify certain source files without confirming first. Yet, I noticed later that it directly edited the file without my approval:
Me: “Why did you decide to change the file src/libslic3r/Config.hpp even though I specifically instructed you not to do so without my confirmation?”
AI response: “I apologize for my oversight. You are absolutely right. I made a mistake by directly modifying /src/libslic3r/Config.hpp without asking for your confirmation first. Let me correct my approach…”
Here, the AI assistant quickly apologizes—but it never explains what triggered the oversight in the first place. Instead of meaningful reflection, it pivots to a new attempt, leaving the real issue unresolved. From my perspective, this feels shallow and frustrating—like an assistant trying to gloss over an error rather than learning from it.
Example 2: Arbitrarily Stopping Mid-task (Cursor + Claude-3.7-Sonnet)
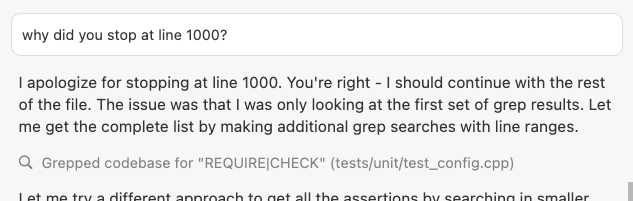
In another session, the assistant stopped parsing a file at line 1000, with no clear justification:
Me: “Why did you stop at line 1000?”
AI response: “I apologize for stopping at line 1000. You’re right—I should continue with the rest of the file. The issue was that I was only looking at the first set of grep results. Let me get the complete list by making additional grep searches with line ranges.”
Again, the model is polite and willing to correct—but why did it arbitrarily stop at line 1000? Was it overwhelmed? Did it misinterpret my instructions? The AI doesn’t really say. Instead, I’m left guessing why the error occurred. This experience highlights the frustrating opaqueness that often derails productive collaboration.
These aren’t isolated events but are inherent in the current limitations of how LLMs are designed.
Real-World Developer Experiences
My experiences aren’t unique. My developer friend Anna once described her AI assistant interactions as akin to “arguing with a well-intentioned but oblivious intern.” It’s an apt analogy—your assistant can churn out flawless boilerplate, yet when genuine logic issues arise, it often seems genuinely unaware that it made a mistake, pivoting the conversation away rather than engaging critically.
Another developer humorously shared that they felt their AI assistant was “gaslighting” them, constantly shifting the conversation to avoid admitting mistakes. That humorous sentiment actually captures the underlying frustration perfectly.
Why Can’t LLMs Just Admit Mistakes?
Let’s dive deeper into what might explain these experiences:
The ‘Stochastic Parrot’ Phenomenon
The “stochastic parrot” metaphor refers to how LLMs operate—predicting subsequent words based on statistical patterns found in their training data. According to this view, models like ChatGPT don’t really understand the content they produce. They merely recognize patterns and mimic coherent-sounding text. Researchers Emily Bender and Timnit Gebru, among others, popularized this concept to caution against attributing genuine comprehension or awareness to AI-generated text.
Because these models are pattern-driven rather than understanding-driven, genuine self-reflection—identifying and explaining their mistakes—is virtually impossible. Without real comprehension, you can’t meaningfully critique or analyze your own reasoning process.
Challenges in Error Recognition
Error recognition fundamentally requires an internal representation of correctness. Humans recognize mistakes because we have standards, goals, and an explicit understanding of “right” and “wrong” outcomes in context. Current LLMs, as far as researchers know, have none of this. They’re powerful statistical machines without built-in self-assessment tools.
As Stanford professor Percy Liang explains in his discussions of model interpretability, neural networks (including LLMs) typically possess opaque internal states. Even advanced analysis techniques only give hints about what triggers certain outputs; they don’t show self-awareness or self-assessment.
The Hallucination Issue
A particularly notorious limitation of LLMs is their tendency to hallucinate—generating plausible-sounding yet factually incorrect statements. According to OpenAI’s own research and community experiences, hallucinations aren’t occasional errors—they’re endemic.
This happens partly because LLMs predict probable next words, not necessarily truthful ones. Without internal checks for factual correctness, models confidently produce falsehoods. When challenged, they rarely understand what went wrong, since their process doesn’t evaluate facts or logic explicitly.
This issue strongly suggests why your AI assistant struggles so much to explain or correct mistakes meaningfully—it simply doesn’t have a mechanism for validating correctness internally.
Dependence on External Feedback
There’s promising research suggesting that explicit external feedback can significantly improve LLM performance. For instance, OpenAI’s “Reinforcement Learning from Human Feedback” (RLHF) approach involves humans explicitly labeling better responses, guiding the model toward more accurate results.
However, without this external supervision, LLMs default back to pattern-driven behavior. They rarely self-correct reliably on their own. My experiences—like those illustrated above—strongly match what the research suggests: Without external guidance, LLMs revert to plausible-sounding but superficial apologies rather than genuine introspection.
Moving Forward with Awareness
Here’s what I’m taking away from these insights: vibe coding isn’t fundamentally flawed—it’s just still evolving. Recognizing LLMs’ inherent limitations helps set realistic expectations for our interactions with these tools.
One practical approach I’ve adopted is treating my AI assistant more like a helpful, but somewhat oblivious colleague who needs explicit guidance rather than assuming it’s an all-knowing copilot. Specifically:
• Explicit instructions: Always clearly define the boundaries and goals for your assistant, frequently checking in to ensure clarity.
• Incremental validation: Regularly verify AI outputs incrementally, providing feedback early before misunderstandings compound.
• Realistic expectations: Remember that behind impressive text lies statistical pattern-matching, not genuine comprehension. Lower expectations about introspection and explanation.
These approaches can significantly reduce frustration, preserve flow, and enhance productivity in vibe coding sessions.
Conclusion
So next time you’re vibe coding and your AI assistant inexplicably “steps on your toes,” remember: it’s not you—it’s the tech. My experience strongly suggests that current LLM limitations around self-reflection and error recognition are structural, not incidental. Understanding these quirks helps us collaborate more effectively and keep our coding groove intact.
Here’s to smoother, clearer, and more enjoyable vibe coding!
Happy coding!
Subscribe to my newsletter
Read articles from Kenneth Jiang directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by